

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
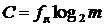 ,
,
при которой невозможно передать всю необходимую информацию об изображении.
При увеличении fд и m происходит вначале улучшение качества оцифрованного изображения, а затем рост качества изображения прекращается, несмотря на увеличение скорости C передачи цифровых данных. В последнем случае, очевидно, рост битовой скорости источника не приводит к увеличению объёма передаваемой информации. А отсюда следует, что объём цифровых данных и количество информации, содержащихся в этих данных, не одно и то же. Если объём цифровых данных существенно превышает количество информации, то говорят об избыточности цифровых данных.
Сокращение объёма цифровых данных при сохранении информационной компоненты на заданном уровне называется сжатием (компрессией). Компрессия данных является актуальной процедурой, так как позволяет адаптировать сигналы цифрового телевидения к доступным системам сбора, хранения и передачи информации. Коэффициент компрессии (сжатия) данных Cсж вычисляется по формуле:
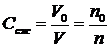 , (2.23)
, (2.23)
где введены следующие обозначения:
V0 – объём несжатых данных;
V – объём сжатых данных;
n0 – средняя длина кода для несжатых данных;
n – средняя длина кода для сжатых данных.
Средняя длина кода выражается числом битов цифрового кода, приходящихся на 1 символ (бит/симв). При сжатии изображения под символом понимают обычно минимальный фрагмент изображения – пиксель, хотя возможен и другой подход.
С величиной коэффициента компрессии Cсж однозначно связана величина:
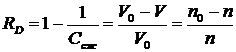 , (2.24)
, (2.24)
которая характеризует избыточность несжатых данных объёмом V0 по сравнению со сжатыми данными объёмом V, или, по другому, избыточность кода со средней длиной n0, используемого для представления несжатых данных, по отношению к коду со средней длиной ![]() , с помощью которого производится сжатие. Сравнение выражений (2.23) и (2.24) показывает, что сжатие возможно только для избыточных данных или, другими словами, сжатие достигается за счёт сокращения или устранения избыточности RD цифровых данных.
, с помощью которого производится сжатие. Сравнение выражений (2.23) и (2.24) показывает, что сжатие возможно только для избыточных данных или, другими словами, сжатие достигается за счёт сокращения или устранения избыточности RD цифровых данных.
2.3.2. Структура кодера/декодера источника
Ранее (раздел 2.1) было показано, что модели цифровой ТВ системы за процедуры компрессии и декомпрессии цифровых данных отвечают соответственно кодер источника и декодер источника.
Структурная схема кодера источника приведена на рис. 2.14. Рассмотрим работу кодера на примере сжатия цифрового видео. Телевизионное сжатие достигается за счёт сокращения следующих видов избыточности цифровых данных: кодовая, пространственная, временная и визуальная. За сокращение кодовой избыточности отвечает энтропийный кодер. Входной узел кодера источника преобразует в некий «не визуальный» формат, обеспечивающий пространственную и временную декорреляцию изображения, уменьшение энтропии источника и, следовательно, увеличение степени сжатия цифровых данных на выходе энтропийного кодера.
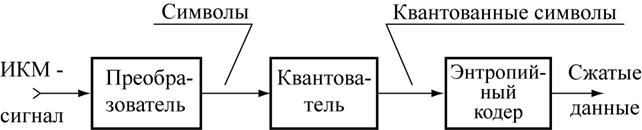
Рис. 2.14. Кодирование источника
Сочетание преобразователя и энтропийного кодера соответствует сжатию без потерь. Коэффициент компрессии при этом невелик и изменяется в пределах от 2 до 10 [2.9]. Введение квантователя позволяет увеличить коэффициент сжатия до 30-40 и более за счёт обнуления большинства квантованных символов на выходе энтропийного кодера. Поскольку операция квантования является необратимой, в восстановленном изображении возникают искажения, связанные с частичной потерей зрительной информации. До тех пор, пока эти искажения не заметны при визуальном наблюдении, считается, что эффект сжатия достигнут за счёт уменьшении визуальной избыточности.
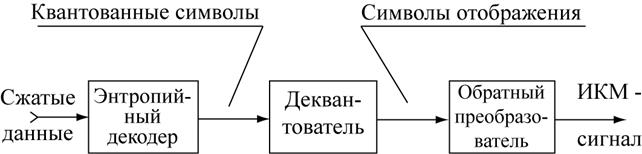
Рис. 2.15. Декодер источника
Восстановление изображения за счёт компрессированных данных производится по схеме, приведённой на рис. 2.15. Энтропийный кодер производит декомпрессию сжатых данных и восстанавливает квантовые символы. Деквантователь восстанавливает исходный масштаб символов отображения; при этом утраченная в процессе квантования зрительная информация не восстанавливается.
2.3.3. Энтропийное кодирование
При энтропийном кодировании количество битов сжатого потока, приходящихся в среднем на один символ, стремиться к энтропии источника. Под энтропией источника X понимают величину H(X), вычисляемую по формуле (в битах)
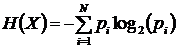 , (2.25)
, (2.25)
где источник X имеет алфавит ![]() , состоящий из N символов с соответствующими вероятностями появления символов
, состоящий из N символов с соответствующими вероятностями появления символов 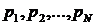 , причём выполняется условие
, причём выполняется условие
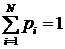 .
.
Энтропия или неопределённость источника определяет генерируемое источником среднее количество информации, приходящееся на один символ. Выражение (2.25) относится к простейшему источнику без памяти, когда символы источника статистически независимы. В частном случае, когда символы равновероятны (т. е. ![]() ), выражение (2.25) приводится к виду
), выражение (2.25) приводится к виду
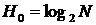 , (2.26)
, (2.26)
где введено обозначение H0 – максимальное значение энтропии для источника, содержащего N символов.
Очевидно, что при ![]() сжатие данных невозможно. Для источника с энтропией
сжатие данных невозможно. Для источника с энтропией ![]() максимальный коэффициент компрессии, достигаемый при энтропийном кодировании, вычисляется по формуле, аналогичной выражению (2.23)
максимальный коэффициент компрессии, достигаемый при энтропийном кодировании, вычисляется по формуле, аналогичной выражению (2.23)
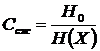 . (2.27)
. (2.27)
По аналогии с выражением (2.24) производится расчёт избыточности источника
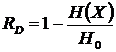 . (2.28)
. (2.28)
2.3.4. Кодирование Хаффмана
Энтропийное сжатие достигается за счёт использования кодов переменной длины, когда наиболее вероятными символами алфавита присваиваются короткие коды и наоборот. Таким кодом, например, является код Морзе. В 1952 г. Д. Хаффман предложил оптимальный префиксный код с минимальной средней длиной кодового слова. Рассмотрим процедуру построения кода Хаффмана для источника, содержащего N=8 символов. Вероятности символов приведены в табл. 2.7.
Таблица 2.7
Параметры источника
Символы | Вероятности | Информация на |
a | 0,04 | 4,644 бит |
b | 0,5 | 1 бит |
c | 0,1 | 3,322 бит |
d | 0,03 | 5,055 бит |
e | 0,01 | 6,644 бит |
f | 0,25 | 2 бит |
g | 0,05 | 4,322 бит |
h | 0,02 | 5,644 бит |
Для данного источника вычисляются следующие величины:
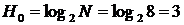 ,
,
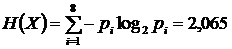 ,
,
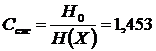 ,
,
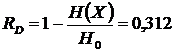 .
.
Вычисление кодов Хаффмана производится в несколько этапов, как это показано на рис. 2.16. Вначале символы выстраиваются в порядке убывания их вероятностей. Затем источник редуцируется путём объединения на каждом шаге двух символов, имеющих минимальные вероятности. После каждого объединения образуется узел, который на рисунке обозначен жирной точкой. Правый верхний узел называется корнем кодового дерева.

Рис. 2.16. Кодирование Хаффмана
Кодовое дерево образовано совокупностью узлов и рёбер – линий, соединяющих узлы между собой и с таблицей символов источника. Рёбра, отходящие от узла вверх обозначим цифрой 0, а вниз – цифрой 1. Теперь можно записать коды Хаффмана для каждого символа.
Строка «b» таблицы символов источника соединена с корнем кодового дерева ребром, которое обозначено цифрой 0; поэтому код Хаффмана для символа «b» равен 0. Строка символа «g» соединена с корнем дерева цепочкой рёбер, обозначенных цифрами 11100 (отсчёт ведём от корня). Таким образом, число 11100 является кодом Хаффмана для остальных символов и заполняется левый столбец таблицы на рис. 2.16.
Из этой таблицы видно, что длина ni кода (разрядность) меняется от 1 до 6. Вычисление средней длины nср кода приводит к следующему результату:
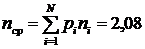 бит,
бит,
что достаточно близко к энтропии источника H(X) = 2,065. При этом эффективность кода составила
2.3.5 Арифметическое кодирование
В отличие от кодирования Хаффмана, создающего для каждого символа индивидуальный код, арифметический кодер превращает последовательность символов (сообщение) в единственное действительное число, которое позволяет сжать сообщение до некоторого оптимального уровня, приближающегося с увеличением длины сообщения к теоретическому пределу [2.2, 2.6, 2.9, 2.10]. Если считать сообщение входным файлом арифметического кодера, то сформированное на выходе кодера действительное число является сжатым файлом. Кодер последовательно обрабатывает поступающие на вход символы сообщения и добавляет биты в сжатый файл.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
