

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рассмотрим процедуру арифметического кодирования сообщения, представляющего собой последовательность символов, генерируемых источником, статические параметры которого приведены на рис. 2.17.
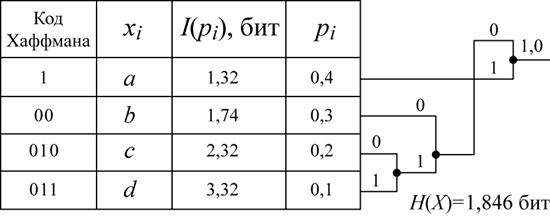
Рис. 2.17. Параметры кодируемого источника
Здесь же приведены коды Хаффмана для того, чтобы в дальнейшем можно было сравнить эффективность арифметического кодера с кодером Хаффмана.
На рис. 2.18 показан процесс арифметического кодирования пятисимвольного сообщения abcad. Процедура разбита на пять (по числу символов в сообщении) однотипных шагов. На первом шаге исходный интервал [0;1] разбивается на подинтервалы в соответствии с алфавитом кодируемого источника (см. табл. на рис. 2.17). В рассматриваемом примере таких подинтервалов четыре, а их величины равны вероятностям символов. Затем вычисляются границы подинтервалов: для символа a – [0; 0,4], для символа b – [0,4; 0,7], для символа c – [0,7; 0,9] и для символа d – [0,9; 1]. Первый шаг кодирования заканчивается выбором подинтервала [0; 0,4], соответствующего первому символу сообщения, т. е. a. Затем кодер переходит ко второму этапу кодирования.

Рис.2.18. Арифметическое кодирование сообщения abcad
На втором этапе выбранный подинтервал [0; 0,4] становится интервалом, который вновь разбивается на подинтервалы, ширина которых теперь пропорциональна вероятностям символов источника. Затем вычисляются границы подинтервалов и выбирается подинтервал [0,16; 0,28], соответствующий второму символу сообщения, т. е. b.
Аналогичным образом выполняются следующие шаги кодирования и на пятом шаге вычисляется подинтервал [0,25264; 0,2536]. Любое число внутри этого интервала является арифметическим кодом сообщения abcad. Выбираем самое короткое из них – 0,253. Информативным являются только цифры после запятой. Переводим десятичное число в двоичное: 253 → 11111100.
Таким образом, сообщение в арифметическом коде, составило 8 бит, т. е. 1,6 бит/симв. То же сообщение, сжатое по Хаффману, имеем вид 1000101011, т. е. требует 10 бит или 2 бит/симв.
Преимущество арифметического кодирования заключается в том, что не требуется, подобно кодированию Хаффмана, затрачивать целое число бит на любой из символов.
Декодер арифметического кода работает в обратном порядке. Вначале, на интервале [0; 1] находится подинтервал, где расположено число 0,253: это подинтервал [0; 0,4], т. е. первый символ сообщения a. Затем находим подинтервал, в котором расположено число 0,253, в интервале [0; 0,4] и т. д.
2.4. Помехоустойчивое кодирование цифровых телевизионных сигналов
2.4.1. Простейшие методы помехоустойчивого кодирования
Ценность каждого бита в компрессированном сигнале многократно увеличена, что приводит к необходимости защищать безизбыточную информацию от воздействия шумов и помех канала связи. Помехоустойчивое кодирование, позволяющее обнаруживать и исправлять появившиеся при передаче по каналу связи ошибки, основано на преднамеренном вводе некоторой избыточной информации в передаваемый цифровой сигнал.
Все помехоустойчивые коды можно разделить на два больших класса: блоковые и древовидные (или сверточные). В телевидении из-за больших скоростей передачи сигналов большое значение приобрели блоковые систематические коды, которые не изменяют исходные информационные символы кодовой комбинации. Эти коды основаны на перекодировании k информационных символов исходной кодовой комбинации в кодовую комбинацию с n символами (n > k) так, что дополнительные проверочные символы (n – k) формируются из информационных по соответствующим правилам кодирования. Характерной особенностью этих кодов является то, что (n – k) проверочных символов формируются в рамках только одного кодового слова (блока).
Простейшим случаем блочного кодирования является добавление к информационным разрядам кодового слова дополнительного проверочного разряда, т. н. бита четности, который добавляет число единиц в передаваемом коде до четного, т. е. содержит единицу, если оно нечетное. В табл. 2.8 приведены правила формирования содержимого бита четности для 3-разрядного кода. Формула для вычисления бита чётности D записывается следующим образом:
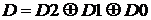 , (2.29)
, (2.29)
где знаком ![]() обозначается процедура суммирования по модулю 2. Формула (2.29) может быть распространена на любое число слагаемых; порядок суммирования произволен. Фактически в таблице содержатся разрешенные для приема 4-разрядные коды (включая бит четности). Несовпадение принятого кода с табл. 2.8 указывает на ошибку в принятом слове. Недостаток способа состоит в том, что ошибка только обнаруживается, но исправлена быть не может, поскольку неизвестно, какой бит подвергся искажению. Кроме того, не обнаруживаются ошибки сразу в двух (или четырех, или шести и т. д.) разрядах.
обозначается процедура суммирования по модулю 2. Формула (2.29) может быть распространена на любое число слагаемых; порядок суммирования произволен. Фактически в таблице содержатся разрешенные для приема 4-разрядные коды (включая бит четности). Несовпадение принятого кода с табл. 2.8 указывает на ошибку в принятом слове. Недостаток способа состоит в том, что ошибка только обнаруживается, но исправлена быть не может, поскольку неизвестно, какой бит подвергся искажению. Кроме того, не обнаруживаются ошибки сразу в двух (или четырех, или шести и т. д.) разрядах.
Таблица 2.8
Вычисление бита четности D
Информационные биты | Бит четности D | ||
D2 | D1 | D0 | |
0 0 0 0 1 1 1 1 | 0 0 1 1 0 0 1 1 | 0 1 0 1 0 1 0 1 | 0 1 1 0 1 0 0 1 |
Для обнаружения ошибок с указанием искаженного бита (или битов) используются более сложные системы кодирования. Возможно, в частности, формирование блока данных в виде двухмерного массива, в котором в каждую строку и в каждый столбец вводится бит четности (рис. 2.20). На приемной стороне проверяется четность каждого столбца и каждой строки. При наличии в блоке одиночной ошибки местоположение ошибочного бита определяется на пересечении строки и столбца, для которых не выполняется правило четности. В приведенном на рис. 2.20 примере ошибочный бит выделен жирной рамкой. Он находится на пересечении третьей строки и четвертого столбца, которые содержат нечетное число единиц. Для исправления ошибки содержимое указанного бита инвертируется.

Рис. 2.20. Блок данных с проверкой на четность по строкам и столбцам
Рассмотренные способы удовлетворительно работают с одиночными ошибками и дают сбои при наличии пакетных ошибок, когда в блоке может быть искажено несколько бит. В ряде случаев удается обнаружить лишь ошибочную кодовую комбинацию (слово), а испорченный бит неизвестен.
Практически в цифровом телевизионном вещании используются более сложные помехоустойчивые коды и их сочетания. Так, например, в системах DVB первого пополнения используется каскадное кодирование кодами Рида-Соломона (внешнее кодирование) и сверточным кодом (внешнее кодирование). В стандарте DVB-T2 для повышения помехозащищённости на 3 дБ используется [2.11] помехоустойчивый код с низкой плотностью проверок на чётность LDPS (Low Density Parity Check Codes) в сочетании с коротким кодом Боуза-Чоудхури-Хоквенгема BCH (Bose-Chaudhuri-Hocquenghem).
2.4.2. Двоичные циклические коды
Большинство практически используемых блоков помехоустойчивых кодов относится к семейству циклических кодов. Формат кода записывается как (n, k), где n – общее число битов в кодовом слове; тогда p=n-k – число битов чётности в кодовом слове.
Обычно кодирование производится в систематической форме, когда k старших битов кода формируются информационными символами, а p младших битов являются битами чётности.
Процедуры кодирования и декодирования основаны на полиномиальном делении полинома кодового слова U(X) на генераторный полином g (X). Компоненты кодового слова 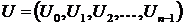 можно рассматривать как коэффициенты полинома
можно рассматривать как коэффициенты полинома
![]() (2.30)
(2.30)
Так, например, для кодового слова в формате (7,4)
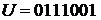 (2.31)
(2.31)
полином ![]() имеет вид
имеет вид
![]() , (2.32)
, (2.32)
где некоторые слагаемые отсутствуют, так как соответствующие компоненты кодового слова равны 0.
В приведённом выше кодовом слове ![]() четыре старших быта 1001 это информационные бит (сообщение), а три младшие бита 011 – биты чётности, вычисленные на основе информационных битов. Если биты чётности вычислены верно, то полином кодового слова
четыре старших быта 1001 это информационные бит (сообщение), а три младшие бита 011 – биты чётности, вычисленные на основе информационных битов. Если биты чётности вычислены верно, то полином кодового слова ![]() должен делиться без остатка на генераторный полином
должен делиться без остатка на генераторный полином ![]() , который для циклического кода (7,4) имеет вид
, который для циклического кода (7,4) имеет вид
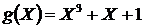 (2.33)
(2.33)
Для вычисления битов чётности используется следующий приём. Вначале формируется «заготовка» для кодового слова ![]() , где разряды, отведённые для битов чётности, заполняются нулями. Затем вычисляется полином
, где разряды, отведённые для битов чётности, заполняются нулями. Затем вычисляется полином 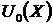
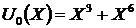 ,
,
остаток ![]() от деления на
от деления на ![]() , после чего вычисляется полином кодового слова по формуле
, после чего вычисляется полином кодового слова по формуле

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
