Более сложный вариант, предполагающий создание настоящего хранилища данных в DEDUCTOR (в формате СУБД FireBird) требует создания отдельных текстовых файлов для таблицы фактов (Продажи) и для всех измерений (Типы, Товары, Аптеки и пр.) Рассмотрим обе эти возможности.
Примеры реализации:
1) Выгрузим подготовленную таблицу с детальной информацией о продажах и льготной реализации в текстовый файл. Для этого снова обратимся к программе массовой загрузки bcp (bulk copy procedure).
Вспомним, что эта команда запускается из командной строки Windows (Пуск – Выполнить – cmd –OK ). В нашем случае формат команды следующий:
bcp drugstores.dbo.fullRealization out fullRealization.txt -T -w -S HOME\SQLEXPRESS -C 1251 -t; -r\n
Рассмотрим параметры этой команды, которые не встречались нам раньше.
out – направление потока данных: из SQL server наружу;
-w – выполняет операцию массового копирования, используя символы Юникода. При использовании этого параметра не запрашивается тип данных каждого поля, для хранения данных используется тип nchar, отсутствуют префиксы, в качестве разделителя полей используется символ табуляции \t, а в качестве признака конца строки — символ новой строки \n.
-r\n – задается разделитель конца строки – символ ‘\n’.
Получим файл с таким содержимым:
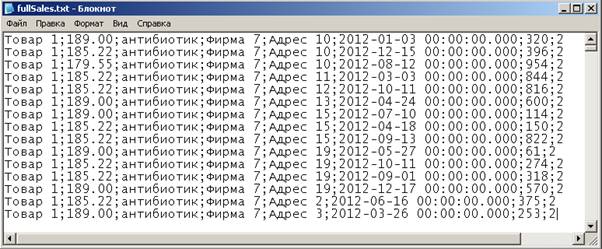
Для того чтобы формат нашего файла соответствовал программе DEDUCTOR, откроем полученный файл в «Блокноте», добавим в качестве первой строки заголовки столбцов:
Товар; Цена; Тип; Фирма; Аптека; Дата; Чек; Количество
а затем сохраним его в формате ANSI:
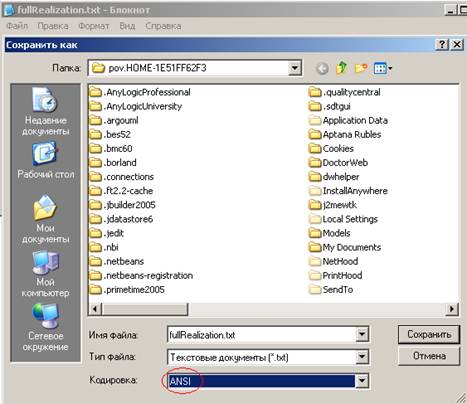
Примечание: в выгруженном файле имеются даты, которые в своем составе содержат миллисекунды в виде.000. Эти миллисекунды в дальнейшем вызовут большие проблемы при загрузке в Deductor Studio, поэтому от них следует избавиться. Самый простой способ – открыть файл в текстовом редакторе и произвести автоматическую замену, например, заменить строку «.000;» на строку «;». Программа «Блокнот» для этой операции может быть слишком медленной, лучше использовать, например, MS Word:

2) Теперь рассмотрим выгрузку данных в несколько текстовых файлов – отдельно для таблицы фактов и отдельно для всех измерений. (Выгружаем только продажи, льготную реализацию для упрощения работы брать не будем.)
Типы лекарств:
bcp drugstores. dbo. Type out types. txt - T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Фирмы-производители:
bcp drugstores. dbo. Firm out firms. txt - T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Чеки:
bcp drugstores. dbo. Bill out bills. txt - T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Продажи:
bcp drugstores. dbo. Sale out sales. txt - T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Из таблицы «Аптеки» возьмем только номер и адрес, для этого придется написать SELECT и указать, что тип операции – не “out”, а “queryout”:
bcp "SELECT NumDrug, Address FROM drugstores. dbo. drugstore" queryout drugstores. txt -T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Из таблицы «Товары» тоже возьмем только некоторые столбцы, для этого придется написать SELECT и указать, что тип операции – не “out”, а “queryout”:
bcp "SELECT NumArticle, NameArticle, NumType, NumFirm FROM drugstores. dbo. article" queryout articles. txt -T - w - S HOME\SQLEXPRESS - C 1251 - t; - r\n
Задание 5. Выгрузите подготовленные данные в один или несколько текстовых файлов. Задайте в этих файлах заголовки столбцов. Не забудьте сохранить файлы в формате ANSI. В тех файлах, где используется тип дата+время, избавьтесь от миллисекунд. (Итого 5 баллов).
Работа в программе Deductor Studio
Программа Deductor Studio поставляется в нескольких вариантах. Для целей обучения имеется бесплатная версия Deductor Studio Academic. Основное ограничение этой версии заключается в том, что для хранилищ данных можно использовать только СУБД FireBird (входит в поставку программы), а загружать данные извне можно только из текстовых файлов.
Перед тем как начинать работу в Deductor Studio, настоятельно рекомендуется прочитать руководство «Базовые навыки работы в Deductor Studio. pdf».
 Этап 6а: Загрузка данных в Deductor Studio из текстовых файлов, создание хранилища данных в СУБД FireBird.
Этап 6а: Загрузка данных в Deductor Studio из текстовых файлов, создание хранилища данных в СУБД FireBird.
Как уже упоминалось в 5 задании, можно выбрать один из двух вариантов загрузки данных в Deductor Studio.
Первый вариант (простой) предполагает загрузку данных из одного текстового файла, созданного на предыдущем этапе и представляющего собой многомерную таблицу. Настоящее хранилище данных не создается. За этот вариант можно получить максимум 3 балла.
Второй вариант (сложный) предполагает создание настоящего хранилища данных и загрузку информации из нескольких текстовых файлов, соответствующих таблицам SQL server. Этот вариант оценивается максимум в 10 баллов.
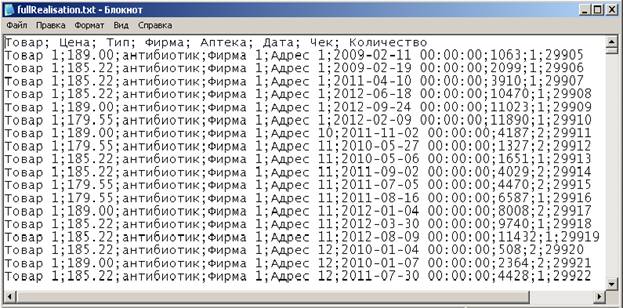
Рассмотрим сначала первый вариант. У нас есть текстовый файл fullRealisation.txt, полученный на 5 этапе и представляющий собой общую информацию о продажах в аптеках и о бесплатной реализации лекарств льготникам. Этот файл содержит многомерные данные и выглядит примерно следующим образом:
Запускаем Deductor Studio, при этом автоматически создается пустой проект, в котором есть единственная строка «Сценарии». Теперь можно щелкнуть правой кнопкой мыши по этой строке и из контекстного меню выбрать пункт «Мастер импорта», либо щелкнуть по кнопке «Мастер импорта» ![]() и выбрать в качестве источника текстовые файлы.
и выбрать в качестве источника текстовые файлы.
На 2-м шаге выбираем наш файл:
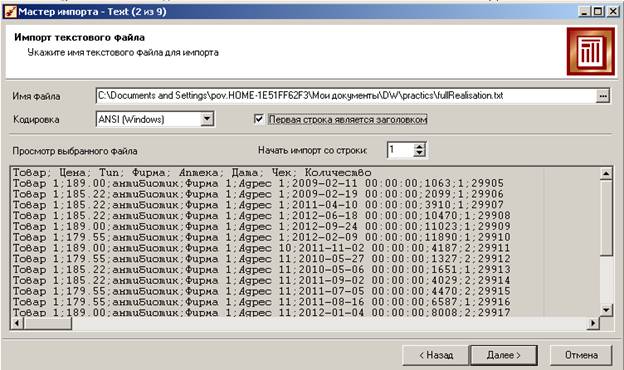
После выбора файла первые несколько строк отобразятся в окне.
Обратите внимание на флажок «Первая строка является заголовком».
На 3-м шаге можно установить некоторые параметры форматирования. В качестве разделителя целой и дробной части числа следует указать точку (по умолчанию – запятая). Формат даты, в принципе, можно не менять.
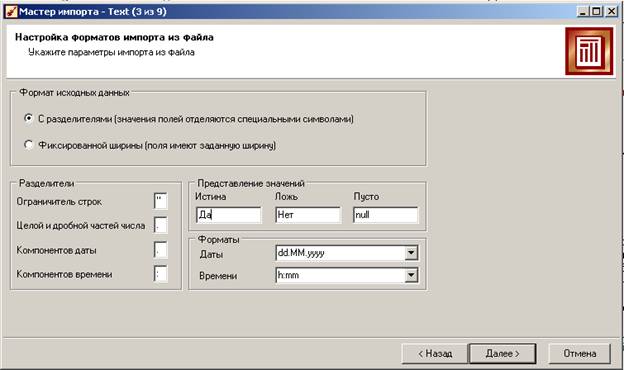
На 4-м шаге обязательно нужно указать верный формат разделителя полей (у нас – точка с запятой).
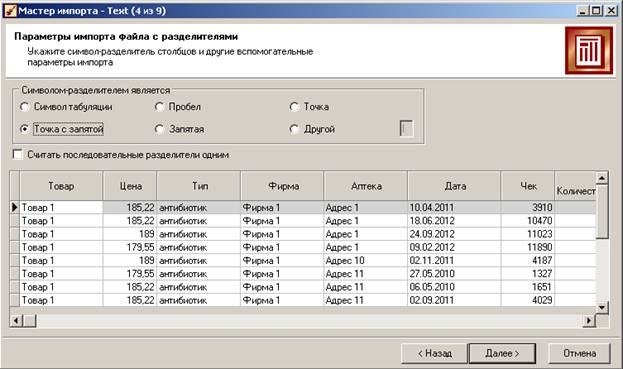
Данные из файла отображаются в таблице. Сразу можно увидеть, правильно ли воспринимаются числа (они выравниваются по правому краю) и даты.
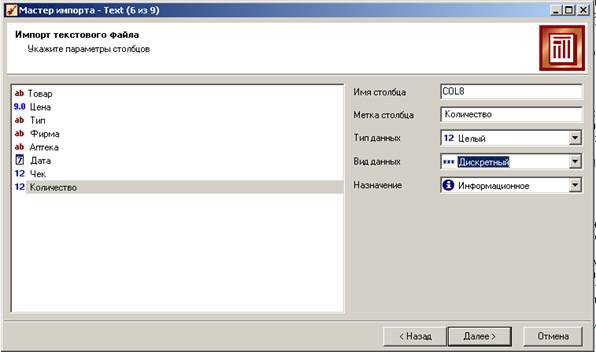
На 6-м шаге (5-го шага не было?) следует задать типы столбцов таблицы. Здесь (в основном) можно оставить предлагаемые значения. Единственное замечание – все числовые типы по умолчанию предлагаются вещественными. Имеет смысл поменять тип на «Целый» и вид на «Дискретный» для столбцов, которые действительно содержат только целочисленные значения. В нашем случае это Чек и Количество. Назначение у всех столбцов пока «Информационное», отнести столбцы к измерениям и фактам можно будет потом.
На следующем шаге нажимаем на кнопку «Пуск»:
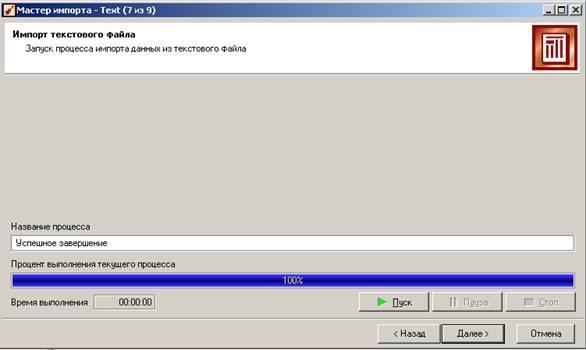
Импорт данных успешно выполнен.
Далее выбираем способ отображения информации. Оставим пока только способ «Таблица», остальные визуализаторы рассмотрим позже.
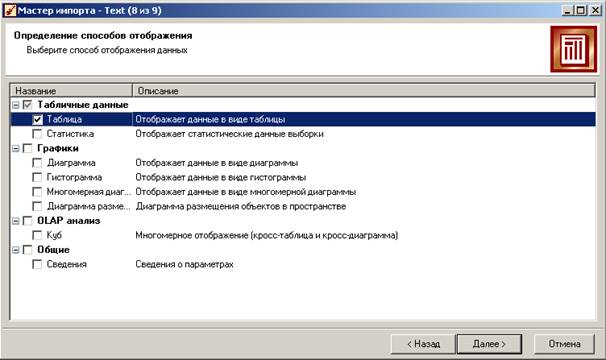
На следующей странице можем задать содержательное имя для нашего сценария импорта:
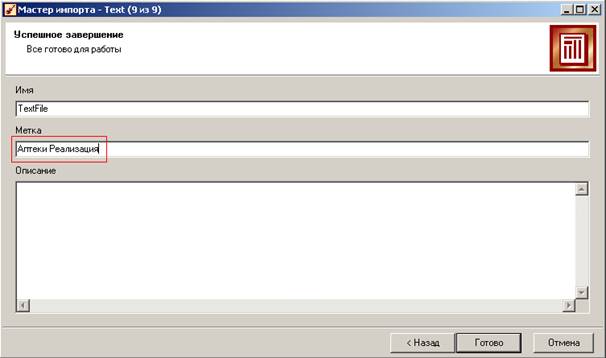
Сценарий выполнен, его результаты можно увидеть на экране в форме таблицы. Сценарии отображаются в виде иерархии слева в окне проекта Deductor Studio (у проектов тип файла ded).
Теперь рассмотрим более сложный вариант работы. Будем создавать хранилище данных в СУБД FireBird. Но предварительно загрузим данные из текстовых файлов.
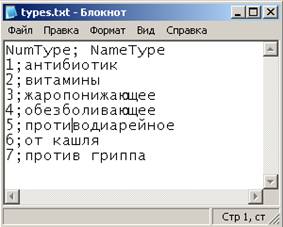
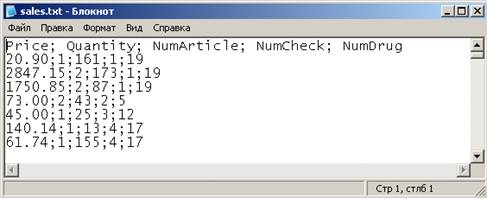
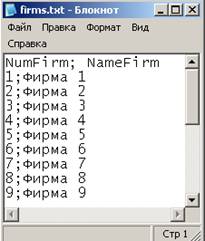 Во всех текстовых файлах нужно задать строку заголовков. Поскольку данные будут загружаться в СУБД FireBird, а русские буквы в названиях столбцов использовать не следует, названия столбцов напишем латинскими буквами:
Во всех текстовых файлах нужно задать строку заголовков. Поскольку данные будут загружаться в СУБД FireBird, а русские буквы в названиях столбцов использовать не следует, названия столбцов напишем латинскими буквами:
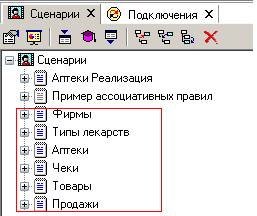 Итак, создадим 6 сценариев загрузки из текстовых файлов:
Итак, создадим 6 сценариев загрузки из текстовых файлов:
для типов лекарств,
фирм,
аптек,
товаров,
чеков
и продаж:
Теперь будем создавать хранилище данных. На вкладке «Подключения» ![]() создадим новое хранилище данных с помощью мастера подключений. (Тип файлов у хранилищ данных gdb.)
создадим новое хранилище данных с помощью мастера подключений. (Тип файлов у хранилищ данных gdb.)
На 3-м шаге мастера нужно задать любое имя файла для хранилища данных (посмотрите, в каком каталоге будет создаваться файл хранилища). Кроме того, можно включить флажок «Спрашивать логин/пароль при подключении». По умолчанию в СУБД FireBird есть логин администратора sysdba и пароль masterkey.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)