Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Вид плотности стандартного нормального распределения ![]() вытекает из математической теории, которую не имеем возможности здесь рассматривать, равно как и доказательство ЦПТ.
вытекает из математической теории, которую не имеем возможности здесь рассматривать, равно как и доказательство ЦПТ.
Для иллюстрации приводим небольшие таблицы функции распределения Ф(х) (табл.2) и ее квантилей (табл.3). Функция Ф(х) симметрична относительно 0, что отражается в табл.2-3.
Если случайная величина Х имеет функцию распределения Ф(х), то М(Х) = 0, D(X) = 1. Это утверждение доказывается в теории вероятностей, исходя из вида плотности вероятностей ![]() . Оно согласуется с аналогичным утверждением для характеристик приведенной случайной величины Un, что вполне естественно, поскольку ЦПТ утверждает, что при безграничном возрастании числа слагаемых функция распределения Un стремится к функции стандартного нормального распределения Ф(х), причем этот предельный переход справедлив для любого числа х.
. Оно согласуется с аналогичным утверждением для характеристик приведенной случайной величины Un, что вполне естественно, поскольку ЦПТ утверждает, что при безграничном возрастании числа слагаемых функция распределения Un стремится к функции стандартного нормального распределения Ф(х), причем этот предельный переход справедлив для любого числа х.
Таблица 2.
Функция стандартного нормального распределения.
х | Ф(х) | х | Ф(х) | х | Ф(х) |
-5,0 | 0,00000029 | -1,0 | 0,158655 | 2,0 | 0,9772499 |
-4,0 | 0,00003167 | -0,5 | 0,308538 | 2,5 | 0,99379033 |
-3,0 | 0,00134990 | 0,0 | 0,500000 | 3,0 | 0,99865010 |
-2,5 | 0,00620967 | 0,5 | 0,691462 | 4,0 | 0,99996833 |
-2,0 | 0,0227501 | 1,0 | 0,841345 | 5,0 | 0,99999971 |
-1,5 | 0,0668072 | 1,5 | 0,9331928 |
Таблица 3.
Квантили стандартного нормального распределения.
р | Квантиль порядка р | р | Квантиль порядка р |
0,01 | -2,326348 | 0,60 | 0,253347 |
0,025 | -1,959964 | 0,70 | 0,524401 |
0,05 | -1,644854 | 0,80 | 0,841621 |
0,10 | -1,281552 | 0,90 | 1,281552 |
0,30 | -0,524401 | 0,95 | 1,644854 |
0,40 | -0,253347 | 0,975 | 1,959964 |
0,50 | 0,000000 | 0,99 | 2,326348 |
Семейство нормальных распределений. Введем понятие семейства нормальных распределений. По определению нормальным распределением называется распределение случайной величины Х, для которой распределение приведенной случайной величины есть Ф(х). Как следует из общих свойств масштабно-сдвиговых семейств распределений (см. выше), нормальное распределение – это распределение случайной величины
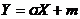 ,
,
где Х – случайная величина с распределением Ф(Х), причем m = M(Y), ![]() = D(Y). Нормальное распределение с параметрами сдвига m и масштаба
= D(Y). Нормальное распределение с параметрами сдвига m и масштаба ![]() обычно обозначается N(m,
обычно обозначается N(m, ![]() ) (иногда используется обозначение N(m,
) (иногда используется обозначение N(m, ![]() )).
)).
Как следует из (8), плотность вероятности нормального распределения N(m, ![]() ) есть
) есть
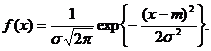
Нормальные распределения образуют масштабно-сдвиговое семейство. При этом параметром масштаба является d = 1/![]() , а параметром сдвига c = - m/
, а параметром сдвига c = - m/![]() .
.
Для центральных моментов третьего и четвертого порядка нормального распределения справедливы равенства
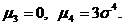
Эти равенства лежат в основе классических методов проверки того, что результаты наблюдений подчиняются нормальному распределению. В настоящее время нормальность обычно рекомендуется проверять по критерию W Шапиро – Уилка. Проблема проверки нормальности обсуждается ниже.
Если случайные величины Х1 и Х2 имеют функции распределения N(m1, ![]() 1) и N(m2,
1) и N(m2, ![]() 2) соответственно, то Х1 + Х2 имеет распределение
2) соответственно, то Х1 + Х2 имеет распределение ![]() Следовательно, если случайные величины X1, X2,…, Xn независимы и имеют одно и тоже распределение N(m,
Следовательно, если случайные величины X1, X2,…, Xn независимы и имеют одно и тоже распределение N(m, ![]() ), то их среднее арифметическое
), то их среднее арифметическое
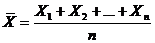
имеет распределение N(m, ![]() ). Эти свойства нормального распределения постоянно используются в различных вероятностно-статистических методах принятия решений, в частности, при статистическом регулировании технологических процессов и в статистическом приемочном контроле по количественному признаку.
). Эти свойства нормального распределения постоянно используются в различных вероятностно-статистических методах принятия решений, в частности, при статистическом регулировании технологических процессов и в статистическом приемочном контроле по количественному признаку.
Распределения Пирсона (хи – квадрат), Стьюдента и Фишера. С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных. В дальнейших разделах книги много раз встречаются эти распределения.
Распределение Пирсона ![]() (хи - квадрат) – распределение случайной величины
(хи - квадрат) – распределение случайной величины
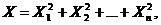
где случайные величины X1, X2,…, Xn независимы и имеют одно и тоже распределение N(0,1). При этом число слагаемых, т. е. n, называется «числом степеней свободы» распределения хи – квадрат.
Распределение хи-квадрат используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости, прежде всего для качественных (категоризованных) переменных, принимающих конечное число значений, и во многих других задачах статистического анализа данных [8, 9, 11, 16].
Распределение t Стьюдента – это распределение случайной величины
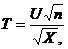
где случайные величины U и X независимы, U имеет распределение стандартное нормальное распределение N(0,1), а X – распределение хи – квадрат с n степенями свободы. При этом n называется «числом степеней свободы» распределения Стьюдента.
Распределение Стьюдента было введено в 1908 г. английским статистиком В. Госсетом, работавшем на фабрике, выпускающей пиво. Вероятностно-статистические методы использовались для принятия экономических и технических решений на этой фабрике, поэтому ее руководство запрещало В. Госсету публиковать научные статьи под своим именем. Таким способом охранялась коммерческая тайна, «ноу-хау» в виде вероятностно-статистических методов, разработанных В. Госсетом. Однако он имел возможность публиковаться под псевдонимом «Стьюдент». История Госсета - Стьюдента показывает, что еще сто лет назад менеджерам Великобритании была очевидна большая экономическая эффективность вероятностно-статистических методов.
В настоящее время распределение Стьюдента – одно из наиболее известных распределений среди используемых при анализе реальных данных. Его применяют при оценивании математического ожидания, прогнозного значения и других характеристик с помощью доверительных интервалов, по проверке гипотез о значениях математических ожиданий, коэффициентов регрессионной зависимости, гипотез однородности выборок и т. д. [8, 9, 11, 16].
Распределение Фишера – это распределение случайной величины
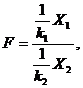
где случайные величины Х1 и Х2 независимы и имеют распределения хи – квадрат с числом степеней свободы k1 и k2 соответственно. При этом пара (k1, k2) – пара «чисел степеней свободы» распределения Фишера, а именно, k1 – число степеней свободы числителя, а k2 – число степеней свободы знаменателя. Распределение случайной величины F названо в честь великого английского статистика Р. Фишера (1890-1962), активно использовавшего его в своих работах.
Распределение Фишера используют при проверке гипотез об адекватности модели в регрессионном анализе, о равенстве дисперсий и в других задачах прикладной статистики [8, 9, 11, 16].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
 Основные порталы (построено редакторами)
Основные порталы (построено редакторами)