


А 8;
Б 3;
В 5.
8. База данных GenBank:
А содержит общие обзоры по заболеваниям и конкретным генам, а также ссылки на базы данных ENTREZ;
Б содержит данные генетических последовательностей, поддерживается NIH (Национальный Институт Здоровья США), аннотированная база известных последовательностей ДНК, РНК и белков, с литературными ссылками на первоисточники и информацией биологического характера;
В содержит данные нуклеотидных последовательностей Европейской Молекулярно-Биологической Лаборатории пополняется большей частью непосредственно авторами, определившими первичную структуру фрагмента ДНК или РНК и, кроме последовательности нуклеотидов, содержит разнообразную информацию о каждом фрагменте, включая литературные ссылки, перекрестные ссылки на документы других баз данных, таблицы особенностей и др.;
Г содержит информацию обо всех опубликованных повреждениях генов, приводящих к наследственным заболеваниям у человека;
Д попытка компьютеризировать все современное знание в молекулярной и клеточной биологии в терминах информационных путей. Это база знаний по систематическому анализу функций генов. Создается институтом химических исследований (Kyoto University, Japan) в рамках японской программы по геному человека.
9. Назовите первую стадию в жизненном цикле записи в базе данных
А Стандарт;
Б Предварительная;
В Неаннотированная;
Г Непроверенная.
10. ENTREZ относится к:
А Архивным базам данных;
Б Курируемым базам данных;
В автоматическим базам данных;
Г Интегрированным базам данных.
Вариант 11
1. Неполярные аминокислоты:
А глицин;
Б цистеин;
В тирозин.
2. Что в себе содержат архивные банки данных?
А анализ первичной биологической информации;
Б первичную биологическую информацию;
В взаимосвязи белков.
3. SINE:
А короткие распределенные генетические элементы;
Б длинные распределенные генетические элементы.
4. PSI-BLAST –
А ищет гомологичные белки, удовлетворяющие заданному паттерну;
Б поиск удаленных белковых гомологов с использованием PSSM.
5. Протеомика – это:
А раздел молекулярной генетики, посвящённый изучению генома и генов живых организмов;
Б исследование белковых молекул, их аминокислотной последовательности, пространственной структуры, посттрансляционных модификаций;
В это «систематическое изучение уникальных химических „отпечатков пальцев“ специфичных для процессов, протекающих в живых клетках» — конкретнее, изучение их низкомолекулярных метаболических профилей.
6. Генетическая изменчивость между особями, условия возникновения которой ограничены одной начальной парой, в которой может возникнуть замена, вставка или делеция
А горизонтальный перенос генов;
Б однонуклеотидный полиморфизм;
В дивергенция.
7. PDB – это:
А большая коллекция белковых семейств;
Б коллекция 3D–структур биологических макромолекул экспериментально определенных с помощью рентгеноструктурного, ядерно–магнитнорезонансного и др. методов;
В база данных белковых семейств, доменов и функциональных сайтов, найденные в известных белках.
8. База данных OMIM:
А содержит общие обзоры по заболеваниям и конкретным генам, а также ссылки на базы данных ENTREZ;
Б содержит данные генетических последовательностей, поддерживается NIH (Национальный Институт Здоровья США), аннотированная база известных последовательностей ДНК, РНК и белков, с литературными ссылками на первоисточники и информацией биологического характера;
В содержит данные нуклеотидных последовательностей Европейской Молекулярно-Биологической Лаборатории пополняется большей частью непосредственно авторами, определившими первичную структуру фрагмента ДНК или РНК и, кроме последовательности нуклеотидов, содержит разнообразную информацию о каждом фрагменте, включая литературные ссылки, перекрестные ссылки на документы других баз данных, таблицы особенностей и др.;
Г содержит информацию обо всех опубликованных повреждениях генов, приводящих к наследственным заболеваниям у человека;
Д попытка компьютеризировать все современное знание в молекулярной и клеточной биологии в терминах информационных путей. Это база знаний по систематическому анализу функций генов. Создается институтом химических исследований (Kyoto University, Japan) в рамках японской программы по геному человека.
9. Назовите вторую стадию в жизненном цикле записи в базе данных
А Стандарт;
Б Предварительная;
В Неаннотированная;
Г Непроверенная.
10. Наиболее важная база данных о трехмерной структуре макромолекул:
А Swiss-Prot;
Б DDBJ;
В PDB;
Г SCOP.
Вариант 12
1. Заряженные аминокислоты:
А глутамин и валин;
Б лизин и аргинин;
В аргинин и валин.
2. Определяет ли последовательность аминокислот в белке его трехмерную структуру?
А да;
Б нет.
3. LINE:
А короткие распределенные генетические элементы;
Б длинные распределенные генетические элементы.
4. Паралоги —
А последовательности, возникшие из одного общего предшественника в результате дупликации одного гена в одном организме
Б последовательности, возникшие из одного общего предшественника в процессе видообразования
5. Сколько основных функциональных классов белков?
А 3;
Б 4;
В 5.
6. Участок ДНК, сохраняемый в зрелой информационной РНК, которую рибосом транслирует в белок
А экзон;
Б интрон.
7. Что такое PubMed?
А Библиографическая база данных об аминокислотах и их последовательностях;
Б База данных производного типа;
В Библиографическая база, бесплатная версия MEDLINE.
8. База данных KEGG:
А содержит общие обзоры по заболеваниям и конкретным генам, а также ссылки на базы данных ENTREZ;
Б содержит данные генетических последовательностей, поддерживается NIH (Национальный Институт Здоровья США), аннотированная база известных последовательностей ДНК, РНК и белков, с литературными ссылками на первоисточники и информацией биологического характера;
В содержит данные нуклеотидных последовательностей Европейской Молекулярно-Биологической Лаборатории пополняется большей частью непосредственно авторами, определившими первичную структуру фрагмента ДНК или РНК и, кроме последовательности нуклеотидов, содержит разнообразную информацию о каждом фрагменте, включая литературные ссылки, перекрестные ссылки на документы других баз данных, таблицы особенностей и др.;
Г содержит информацию обо всех опубликованных повреждениях генов, приводящих к наследственным заболеваниям у человека;
Д попытка компьютеризировать все современное знание в молекулярной и клеточной биологии в терминах информационных путей. Это база знаний по систематическому анализу функций генов. Создается институтом химических исследований (Kyoto University, Japan) в рамках японской программы по геному человека.
9. Назовите четвертую стадию в жизненном цикле записи в базе данных
А Стандарт;
Б Предварительная;
В Неаннотированная;
Г Непроверенная.
10. PIR относится к:
А Архивным базам данных;
Б Курируемым базам данных;
В автоматическим базам данных;
Г Интегрированным базам данных.
Вариант 13
1. Выберите программу, которая сравнивает аминокислотные последовательности
А) BLASTP
Б) BLASTX
В) TBLASTX
2. Метод измерения расстояния между двумя последовательностями по Левенштайну заключается в определении:
А) максимального числа операций редактирования, необходимых для того, чтобы превратить одну строку в другую
Б) количества несовпадающих позиций между двумя последовательностями одинаковой длины
В) минимального числа операций редактирования, необходимых для того, чтобы превратить одну строку в другую
Г) количества совпадающих позиций между двумя последовательностями одинаковой длины
3. Выберите аминокислоты, которые относятся к типу отрицательно заряженные остатки
А) Gly, Ala, Ser, Thr
Б) Cys, Val, Ile, Leu, Pro, Phe, Tyr, Met, Trp
В) Asn, Gln, His
Г) Asp, Glu
Д) Lys, Arg
4. Выберите ортогональную упаковку листов
А) 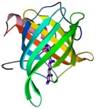 Б)
Б) 
5. Метод Смита–Ватермана не влияет на:
А) инициализацию матрицы
Б) заполнение матрицы
В) счет и путь выравнивания
Г) минимизацию редакционного расстояния
6. Выберите программу, которая сравнивает аминокислотные последовательности
А) BLASTX
Б) PSI–BLAST
В) TBLASTX
7. Попарное выравнивание применяется для:
А) нахождения консервативных участков в наборе гомологичных последовательностей.
Б) нахождения сходных участков
В) нахождения и сопоставления участков, одинаково уложенных в пространстве
8. Скрытые марковские модели (HMM) – это метод, в котором
А) подбираются данные для последовательностей, аналогичных запрошенной
Б) осуществляется описание тонких различий, существующих между семействами гомологичных последовательностей
В) выделяют наборы признаков, наблюдаемых в однородной выборке многих последовательностей
9. Какое количество методов реализовано в программе IT Microcosm
А) 3 Б) 4 В) 5
10. База данных, в которой представлена классификация укладок, основанная на выравнивании структур
А) SCOP
Б) CATH
В) FSSP
Г) DDD
Вариант 14
1. Связный граф – это:
А) абстрактная структура, содержащая вершины и ребра
Б) группа последовательно соединенных ребер
В) структура, содержащая хотя бы один путь между вершинами
Г) структура, содержащая один и только один путь между любыми двумя точками
2. Выберите аминокислоты, которые относятся к типу маленькие неполярные остатки
А) Gly, Ala, Ser, Thr
Б) Cys, Val, Ile, Leu, Pro, Phe, Tyr, Met, Trp
В) Asn, Gln, His
Г) Asp, Glu
Д) Lys, Arg
3. Выберите продольную упаковку листов
А) Б)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
