

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Если бы в ЦВМ были параллельная (S+1)-модульная ОП, то выигрыш достиг бы »100 раз.
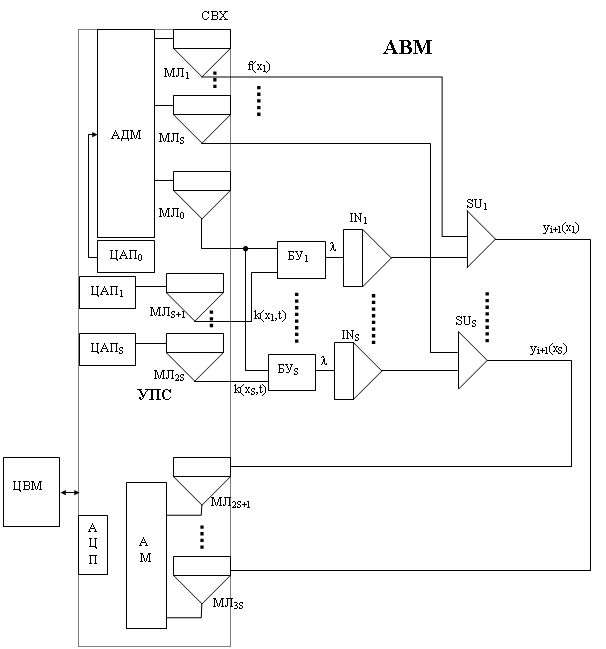 Схема аналого-цифровой модели интегрального уравнения:
Схема аналого-цифровой модели интегрального уравнения:
Для организации параллельной обработки в АВМ одновременно S выражений (1) для нескольких разных к-х шагов : к=jS…(j+1)S, j=0…l-1 требуется параллельный ввод в АВМ (S+1)-й функций одной переменной yi(t), k(x1,t),…,k(xS, t).
Поэтому в УПС для повышения производительности АЦВК вводится избыток интегральных схем ЦАП и СВХ (МЛ), например в данном случае – это ЦАП1…ЦАПS и МЛS+1…МЛ2S, или 2S БИС: ЦАП и СВХ.
Ординаты всех (m+3) квантованных функций одной переменной: семейство ядра:{K(xk, t)}1m, функция первого приближения f(x), искомые функции в двух соседних итерациях yi(x) и yi+1(x), хранятся в ОЗУ ЦВМ. Функция следующего приближения yi+1(x) вычисляется поординатно на основании функции предыдущего приближения yi(x) за l=m/S циклов работы АЦВК. Широкое применение в УПС схем аналоговой памяти МЛ(СВХ) существенно упрощает организацию чередования режимов работы АВМ, УПС и ЦВМ, которая в данном случае близка к таблице 2-го класса аналого-цифровых вычислений:
Цикл | j (j=0…l-1) | J+1 | ||
Фаза | А (m(S+1) тактов) | В (2S тактов) | А | В |
АВМ | Вычисление, в конце запись ординат yi+1(x1)…yi+1(xS) в МЛ2S+1…МЛ3S | Исходное положение | – /// – | – /// – |
УПС | АДМ в положении 0, передача в АВМ через ЦАП0, ЦАП1…ЦАПS поординатно (S+1)-й функции каждую за m тактов | Взаимная передача за 2S тактов в АВМ ординаты f(x1)…f(xS) и в ЦВМ yi+1(x1)…yi+1(xS) | – /// – | – /// – |
ЦВМ | Прерывание, работает КПДП и выгружает в канал вв/выв ординаты функций yi(tk), {K(x, tk)} | Вычисление по ф.(2,3), подготовка буферов вывода : yi+1(t), k(x(j+1)S, t)… k(x(j+1)S, t) | – /// – | – /// – |
Требования к взаимной синхронизации АВМ и ЦВМ невысокие :
1) В фазе В она вообще не нужна;
2) В фазе А работа КПДП и канала вв/выв ЦВМ синхронизуется с УУ АВМ так, чтобы совместить «пуск» АВМ с началом передачи в АВМ m(S+1)-й ординат функций yi(t) и {k(xk, t)}k=1k=S, а окончание их передачи – со стробом записи результирующих ординат yi+1(x1)…yi+1(xS) из АВМ в МЛ2S+1…МЛ3S в УПС и последующим возвратом АВМ в режим «исходное положение» для подготовки к фазе В.
Масштаб времени в АВМ и длительность фазы А определяется скоростью работы КПДП и канала вв/выв ЦВМ.
АЦВК рассмотренных принципов организации применяются при проектировании и отладке цифровых САУ сложных объектов: тепловозов, электровозов, самолетов, космических ракет, реакторов: тепловых, химических и ядерных; роботов и т. п.
Недостатки АЦВК очевидны:
Ø Возрастание погрешности решения из-за АВМ;
Ø Необходимость разворачивания производства АВМ и УПС с более сложной и дорогой технологией производства и метрологией, чем ЦВМ;
Ø Существенное усложнение системного ПО по сравнению с базовым ПО ЦВМ;
Ø Ограниченный класс математических задач, ускорение решения которых возможно в АЦВК при значительных дополнительных затратах.
Поэтому интенсивно ищутся способы организации ВМ, которые позволили бы добиться такого же или более существенного повышения скорости решения сложных задач путем чисто цифрового моделирования и на типовой универсальной цифровой элементной базе и схемотехнике. Основная тенденция развития этой новой организации ЦВМ – массовый параллелизм процессоров в аппаратно избыточных системах с потоковым или алгоритмическим программированием элементарных машин и программированием перестратваемой структуры сложной вычислительной сети элементарных вычислительных машин. Типичный представитель такой организации средств ИВТ – это транспьютерная сеть, где транспьютер – элементарная однокристальная машина, снабженная локальной ОП и не менее, чем четырьмя последовательными портами вв/выв (линками) для передачи команд и данных соседним транспьютерам. На их базе уже создаются командно-алгоритмически (или потоково) и структурно программируемые микропроцессорные платформы (суперкристаллы, большие пластины, ультрабольшие ИС), интегрирующие до 10…100 млн. транзисторов, на которых размещается 256…1000 транспьютеров.
В США уже 10…20 лет в научных и проектных центрах эксплуатируются несуперинтегральные гиперкубовые суперЭВМ типа СМ – 1,2,3 (Connection Machine – соединительная машина), содержащие 65536 элементарных последовательных машин (одноразрядных процессоров), размещенных в 212 кластерных СБИС, каждая из которых содержит 16 элементарных машин и по гиперкубовому принципу соединяется 12-ю линками с 12-ю непосредственными соседями. Опыт их эксплуатации показал, что такие суперЭВМ, организованные по принципу массового параллелизма, могут превзойти по возможностям рассмотренные АЦВК. Например, на СМ – 1 удалось построить цифровую модель всех переходных процессов проектируемой БИС, содержащей до 8000 транзисторов.
Поэтому остальную часть данной дисциплины мы посвятим изучению основ архитектуры параллельных ЦВМ, а завершим её рассмотрение в следующей дисциплине «Специализированные процессоры, машины и сети».
3. Основы архитектуры параллельных
ЭВМ и систем.
3.1 Типы параллелизма в задачах обработки
информации и принципы их использования
для повышения производительности ВС.
Параллельная обработка информации, наряду с повышением быстродействия элементной базы, является эффективным методом увеличения производительности ЦВМ. Правительства всех развитых стран мира рассматривают высокопроизводительные параллельные вычисления в ЦВМ как стратегически важнейшую задачу, решение которой обеспечивает не только техническое лидерство в области ВТ, но и конкурентноспособность экономики страны на мировом рынке XXI века. В программы создания параллельных ВС вкладываются миллиарды долларов с тем, чтобы к 2000 году достичь производительности 104 Гфлопс (млрд. операций с плавающей запятой в секунду).
Применяются следующие способы организации параллельной обработки информации:
1) Совмещение во времени различных этапов обработки разных задач (псевдопараллелизм на основе мультипрограммирования и разделения времени процессора);
2) Одновременное решение разных задач или параллельных частей одной и той же сложной задачи на нескольких процессорах или ЭВМ;
3) Конвеерная обработка как наиболее важный вид обработки по второму способу.
Вся история развития современных однопроцессорных ЭВМ и микропроцессорных систем – это постепенное введение и усовершенствование методов параллельной обработки:
1) Параллельные многоразрядные сумматоры и АЛУ;
2) Многомодульные параллельные многопортовые ОЗУ;
3) Конвеерные АЛУ и конвеевные блоки управления процессоров с блоками опережающей выборки команд;
4) Кэш-память;
5) Сверхпараллельная аппаратно избыточная арифметика (матричные однотактные сдвигатели, блоки умножения и деления);
6) Псевдопараллелизм на уровне устройств ЭВМ на основе мультипрограммной обработки и обработкив режиме разделения времени центрального процессора.
Дальнейшая тенденция введения параллелизма – это организация параллельной одновременной работы нескольких процессоров и прочих устройств ЭВМ: модулей ОЗУ, процессоров (каналов) ввода-вывода, периферийных устройств. С целью экономии расхода технических средств в настоящее время структурную и функциональную организацию параллельной ВС приспосабливают под определенный наиболее распространенный вид параллелизма, встречающийся в задачах обработки информации, с тем, чтобы получить максимальный выигрыш в повышении скорости решения определенного класса задач при минимальных затратах. Строятся параллельные ВС, проблемно-ориентированные на какой-либо достаточно широкий класс задач, но являющиеся машинами широкого назначения в своем классе задач.
В будущем при переходе на новую многопроцессорную ультрабольшую интегральную элементную базу (например, большие пластины транспьютерных сетей), т. е. после перехода к «мелкозернистым» ВС станет экономически выгодным крупносерийное производство универсальных параллельных ВС. Однако в любом случае тип параллелизма решаемой задачи оказывает существенное влияние на способ организации паралелльной ВС и на основные элементы её архитектуры: техническое, программное и информационное обеспечение.
Поэтому очень важно понять как тип параллелизма решаемой задачи влияет на способ оргпнизации параллельной ЭВМ.
3.1.1 Естественный параллелизм
независимых задач.
Он наблюдается, если в ВС поток не связанных между собой задач. В этом случае повышение производительности сравнительно легко достигается путем введения в «крупнозернистую» ВС ансамбля независимо функционирующих процессоров, подключенных к интерфейсам многомодульной ОП и инициализации процессоров ввода/вывода (ПВВ).
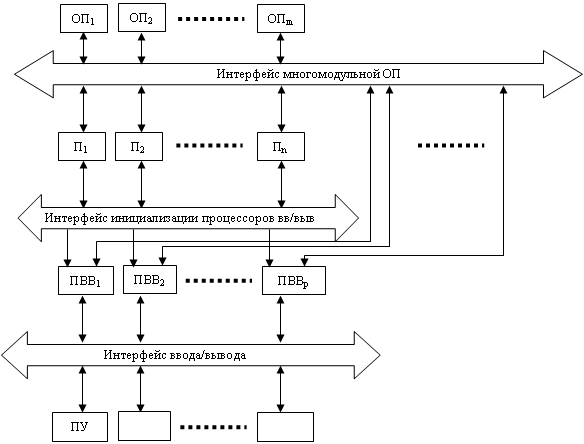
Число модулей ОП m>n+p c тем, чтобы обеспечить возможность параллельного обращения в памятьвсех обрабатывающих процессоров и всех ПВВ и повысить отказоустойчивость ВС. Резервные (m-n-p) модули ОП необходимы для быстрого восстановления при отказе рабочего модуля и для хранения в них ССП процессоров и процессов в контрольных точках программ, необходимых для рестарта при отказе процессора или модуля ОП.
Создается возможность под каждую из решаемых задач временно объединять пару: Пi+ОПj как автономно функционирующую ЭВМ. Предварительно этот же модуль ОП работал в паре: ПВВк+ОПj, и в ОПj в буфер ввода была занесена программа и данные. По окончании обработки в ОПj организуется и заполняется буфер вывода, а затем модуль ОПj вводится в пару ОПj+ПВВr для обмена с периферийным устройством.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
