

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Основная задача организации вычислительных процессов, решаемая системной программой «диспетчер», – оптимальное распределение задач между параллельными процессорами по критерию максимальной их загрузки, или минимизации времени их простоев. В этом смысле оптимальным является асинхронный принцип загрузкм задач в процессоры, не ожидая, пока закончится обработка задач в других занятых процессорах.
Если пакет входных задач, накопленный за определенный интервал времени, хранится в ВЗУ, проблема оптимальной асинхронной диспетчирезации сводится к составлению оптимального расписания моментов запуска задач на разных процессорах. Основные исходные данные, требуемые для этого, – множество известных ожидаемых времен счета, процессорной обработки всех задач накопленного пакета, которые обычно указываются в управляющих картах их заданий.
Несмотря на независимый характер задач в совокупности их асинхронных вычислительных процессов возможны конфликты между ними за общие ресурсы ВС:
1) Услуги общей мультисистемной ОС, например обработка прерываний по вводу-выводу, или обращений к общей ОС надежности при отказах и рестартах;
2) Обращения в общую базу данных (базу знаний), хранящуюся на одном ВЗУ большой ёмкости.
Конфликты разрешаются с помощью механизмов МОС:
1) Приоритетных очередей;
2) Синхропримитивов синхронизации асинхронных процессов, например семафоров (см.[3])
Программы МОС обычно выполняются одной ведущей парой: П1+ОП1, которая называется ведущим процессором. Такой принцип организации МОС называется «ведущий-ведомый».
С целью повышения производительности в критические интервалы конфликтов многих ведомых процессов за услуги МОС обработка одинаковых и разных запросов к МОС может распараллеливаться также, как и по прикладным программам. Для этого МОС из копий своих управляющих модулей создаёт комплект независимых задач максимального уровня приоритетов, которые на время обработки обращений к МОС временно вытесняют из обрабатывающих процессов П1…Пn наименее приоритетные прикладные задачи.
3.1.2. Естественный параллелизм операций
в одной задаче.
Данный тип параллелизма характерен для обработки векторной, матричной, текстовой и графической многомерной информации. Классический пример – приближенное решение дифференциальных уравнений в частных производных методом сеток (конечных разностей).
Плоская задача Пуассона:
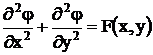
с заданными граничными условиями:
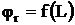 , где
, где ![]() – уравнение контура границы области определения, по методу сеток сводится к системе линейных алгебраических уравнений высокого порядка:
– уравнение контура границы области определения, по методу сеток сводится к системе линейных алгебраических уравнений высокого порядка:
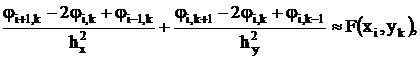
i=0…n, k=0…m,
где hx, hy – шаги декартовой сетки квантования непрерывной области определения по осям х и у соответственно;
i, k – номер узла двумерной сетки квантования;
ji, k – дискретные значения искомой функции j(x, y), определяемые только в узлах сетки;
N£(n+1)(m+1) – порядок аппроксимирующей системы алгебраических уравнений.
Требуется решать систему уравнений достаточно высокого порядка. Например, для достижения принципиальной погрешности dn£3%:
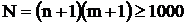
Так как уравнения всех N узлов сетки ik-х одинаковы, можно организовать параллельно-последовательный итеративный процесс решения таких систем высокого порядка по следующему вычислительному алгоритму. Поставим в соответствие каждому ik-му узлу одинаковые параллельно работающие вычислители, определяющие искомое значение jik(j) в данном j-м шаге итераций по известным значениям j(j-1) предыдущего (j-1)-го шага итерации в четырех соседних узлах:
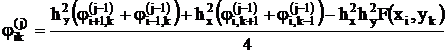
при условии сходимости итеративного процесса:
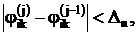 i=0…n; k=0…m,
i=0…n; k=0…m,
где Dn – абсолютная допустимая и методически достижимая погрешность решения.
Каждый j-й шаг итерации начинается с передачи в каждый ik-й вычислитель из четырех соседних вычислителей значений j(j-1). Затем в каждом из них одновременно выполняется одинаковая операция, вычисляется jik(j) и проверяется условие сходимости. Признаки его выполнения со всех узловых вычислителей передаются в общее устройство управления (в ведущую ЭВМ). Если хотя бы в одном из N узлов сетки условие сходимости не выполняется, во всех N узловых вычислителях инициализируется аналогичный следующий шаг итерации и и. д. до выполнения условия сходимости во всех N вычислителях.
Таким образом возникла необходимость матричной организации структуры множества однотипных обрабатывающих устройств с близкодействующими связями только с ближайшими соседями:
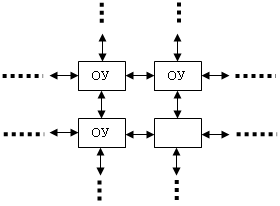 |
Для подобных рассмотренной выше задач в каждом командном цикле все ОУ выполняют одну и ту же команду или макрокоманду. В качестве ОУ могут быть применены типовые микропроцессоры с сокращенным набором команд. Промышленно производятся такие параллельные матричные ВС с общим управлением. В России к ним относятся параллельные системы ПС-2000, ПС-3000, которые нашли экономически выгодное применение для оперативной обработки информации при разведке полезных ископаемых. По результатам космической и сейсмической (взрывной) разведки оперативно решается объёмная задача Пуассона (трехмерная) и в результате оперативно определяется конфигурация и объем подземного пласта залегания.
Матричная организация с близкодействующими связями позволяет существенно ускорить выполнение операций над матрицами высокого порядка. Например, умножение двух квадратных матриц nxn:
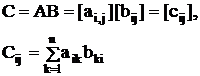
в параллельной матричной ВС выполняется n2 шагов, или n одинаковых циклов по n шагов каждый умножения одного столбца на n строк другой матрицы. В каждом шаге все n2 требуемых параллельных ОУ выполняют одинаковую команду:
1) В первом шаге цикла элементы столбца одновременно умножаются на элементы всех строк другой матрицы;
2) Затем за (n-1) шагов осуществляется в каждой из строк промежуточных произведений образование n-местной их суммы путем последовательной свертки с передачей промежуточных парных сумм ближайшему соседу.
Во второй фазе этого цикла вычисления выполняются (одинаковые) только в одном из столбцов ОУ, накапливая сумму двух слагаемых: элементов данного столбца и предыдущего. Поэтому в каждом из (n-1)-го шагов второй фазы цикла, к сожалению, простаивают n(n-1) ОУ. Для преодоления этого недостатка требуется особый ненакопительный принцип организации вычисления многоместной суммы, который мы рассмотрим позже.
Естественный параллелизм операций характерен не только для названных многомерных задач. Он встречается в большинстве математических задач, например в решении квадратного уравнения:
Естественный параллелизм операций характерен не только для названных многомерных задач. Он встречается в большинстве математических задач, например в решении квадратного уравнения:
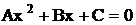
Для анализа параллелизма операций применяют построение специального графического документа, который называется граф операндов, или граф передачи данных (ГПД), вершины которого соответствуют обозначениям необходимых операций, а направленные дуги – направлениям передачи операндов (данных) между операциями. Для квадратного уравнения с учетом знака дискриминанта D=B2-4AC граф операндов имеет следующий вид:
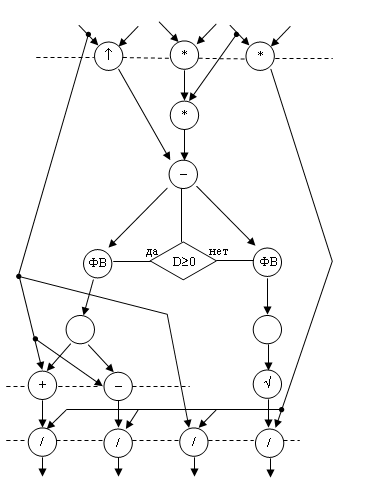 |
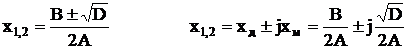
ФВ – флаговый вентиль;
(О–) – ®О-Д – изменение знака D.
При операции в I слое и по две операции во II и III слоях могли бы выполняться параллельно, если бы в составе АЛУ имелся соответствующий избыток операционных блоков.
Рассмотренный выше параллелизм операций в решении дифференциальных уравнений и при обработке матриц относится к классу регулярного, так как там одна и та же операция многократно повторяется над разными данными. Последний пример квадратного уравнения имеет нерегулярный параллелизм операций, когда над разными данными возможно одновременное выполнение разных типов операций.
Как показано выше, для использования регулярного параллелизма операций при повышении производительности подходит матричная организация ВС с общим управлением.
В общем случае нерегулярного параллелизма операций более подходящим способом повышения производительности считается потоковая организация ЭВМ и ВС. В потоковых ВС вместо традиционного фон Неймановского программного управления вычислительным процессом в соответствии с порядком следования команд, определяемого алгоритмом, применяется обратный принцип программного управления по степени готовности операндов, или потоком данных (потоком операндов), определяемой не алгоритмом, а графом операндов (графом передачи данных).
Если в параллельном процессоре имеется достаточный избыток обрабатывающих устройств, или в ВС – ансамбль избыточных микропроцессоров, то естественно и автоматически (без специальной диспетчирезации и составления расписания запуска) будут одновременно выполняться те параллельные операции, операнды которых подготовлены предыдущими вычислениями.
Вычислительный процесс начинается с тех операций, операндами которых являются исходные данные, как, например, в I слое ГПД квадратного уравнения одновременно выполняются три операции, а далее он развивается по мере готовности операндов. Послеэтого вызывается команда умножения, затем вычитания и проверки логического условия, потом макрооператор(Ö) и лишь после этого – одновременно две команды: сложения и вычитания, а после них – две одинаковых команды деления.
Техническая реализация потоковой организации ВС возможна тремя путями:
1) Созданием особых потоковых микропроцессоров, которые относятся к классу специализированных и будут рассмотрены в следующем семестре;
2) Специальной организацией вычислительного процесса и модификацией машинного языка низкого уровня в мультимикропроцессорных ансамблевых ВС, построенных на типовых микропроцессорах фон Неймана;
3) Созданием процессоров с избытком однотипных операционных блокови дополнением операционных систем потоковым способом организации вычислительного процесса (реализовано в отечественных потоковом процессоре ЕС2703 и суперЭВМ Эльбрус-2).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
