

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В диссертационной работе приведена классификация речевых единиц: фонемы и аллофоны, слоги, целые слова и фразы. Сделан вывод, что минимальную эталонную речевую единицу следует выбирать в зависимости от назначения СРР.
Представлена общая модель функционирования системы распознавания речевых команд. Выделено два этапа работы системы (рис 2).
Рис. 2. Общая схема системы распознавания речевых команд
Глава 2 посвящена анализу модели расчета ЛСК и методике использования их в качестве первичных признаков РС.
Метод расчета признаков речевого сигнала – ЛСК
Речевой сигнал описывается в терминах линейных дискретных систем с переменными параметрами и передаточной функцией в частотной области вида
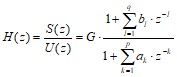 . (1)
. (1)
Наиболее широко для описания РС применяется полюсная модель линейного предсказания, представляемая в виде
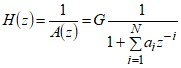 , (2)
, (2)
где N – порядок модели.
Параметрами такой модели являются коэффициенты линейного предсказания {а}, вычисляемые на каждом кадре речевого сигнала, или эквивалентные им параметры – ЛСК, предложенные Итакурой.
Корни в общем случае могут быть получены в результате решения двух уравнений:
![]() при
при ![]() , (3)
, (3)
где ![]() .
.
При этом на основании новой теории ЛСК, предложенной , корни могут рассчитываться по-разному в зависимости от параметра R. В рамках этой теории выделено несколько частных случаев расчета ЛСК.
Модель расчета ЛСК для R = N
В настоящей работе рассматривается случай, когда R = N = 10. Достаточно решить только одно уравнение порядка N, чтобы по его корням найти все коэффициенты исходного многочлена.
Задается порядок модели (степень аппроксимирующего полинома) ORD. На вход поступает отрезок сигнала (кадр) длительности FRM:
![]() . (4)
. (4)
Для устранения граничных эффектов производится сглаживание весовой функцией Хэмминга:
![]() , (5)
, (5)
где ![]()
Выполняется расчет коэффициентов передаточной функции с помощью метода наименьших квадратов и алгоритма Левинсона-Дарбина.
Первичная инициализация:
![]() . (6)
. (6)
В цикле от 1 до ORD производятся следующие вычисления.
- Вычисление коэффициента автокорреляции:
![]() . (7)
. (7)
- Вычисление коэффициента отражения:
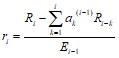 . (8)
. (8)
- Задание первоначального приближения:
![]() . (9)
. (9)
- Уточнение значений коэффициентов:
![]() , (10)
, (10)
где ![]() .
.
- Вычисление текущей ошибки предсказания:
![]() . (11)
. (11)
- На последнем шаге цикла получается окончательное решение:
![]() , где
, где ![]() . (12)
. (12)
Далее расчет коэффициентов отражения по формулам кратных дуг:
![]() . (13)
. (13)
Поиск корней полинома методом Ньютона:
![]() . (14)
. (14)
Расчет набора ЛСК:
![]() , (15)
, (15)
где ![]() .
.
Использование ЛСК в качестве информативных признаков РС
При расчете ЛСК на продолжительном РС (рис. 3), производится его разбиение на кадры с перекрытием. В результате расчетов получается набор значений ЛСК (рис. 4).
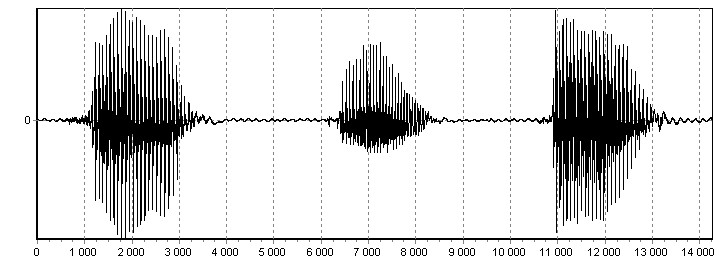

Рис. 3. Временная диаграмма гласных фонем «а», «и», «о»
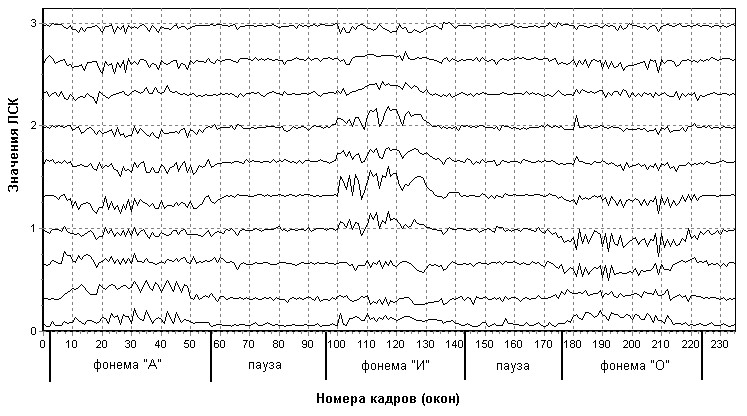

Рис. 4. Набор ЛСК для трех фонем (порядок модели – 10 корней)
На рис. 4 наблюдается возбуждение определенных корней при произнесении фонем. Это обусловлено тем, что ЛСК несут в себе спектральную информацию о РС. Возбуждение корней происходит в области формантных частот гласных звуков.
Значение каждого ЛСК используется в качестве координаты в N-мерном пространстве признаков. На рис. 5 и 6 показаны образы трех фонем в двухмерном и трехмерном подпространствах. Соединительные линии между точками отображают последовательность кадров РС. Для некоторых комбинаций ЛСК наблюдается уверенное разделение фонем – точки группируются в пределах одной области. Это свойство позволяет использовать ЛСК в качестве информативных признаков в СРР.
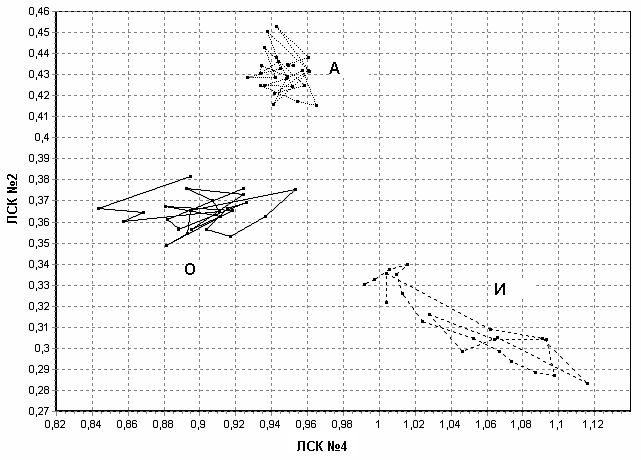
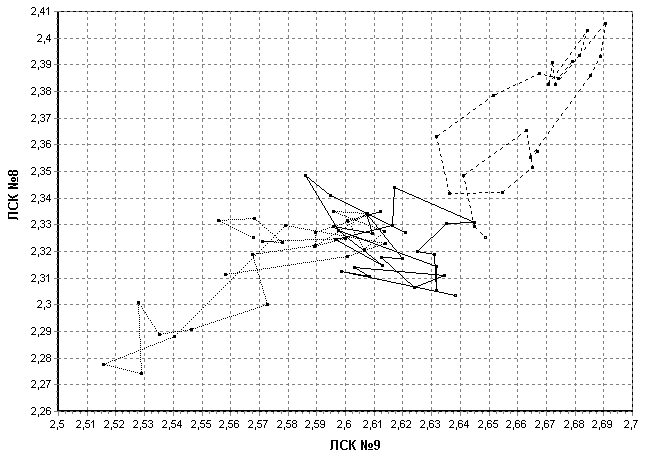
Рис. 5. Образы фонем в двухмерном подпространстве признаков ЛСК
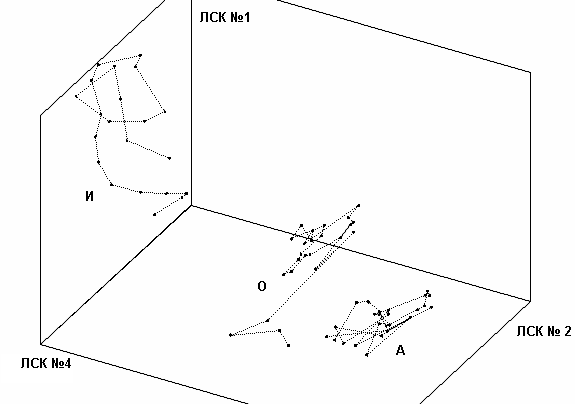
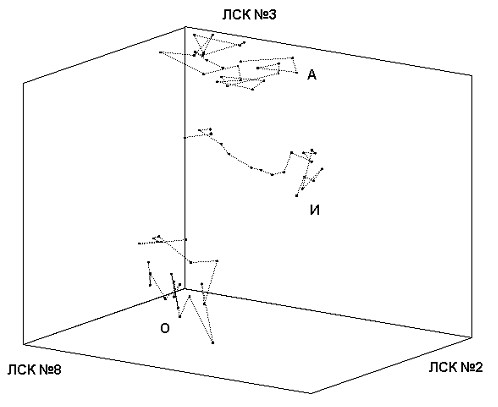

Рис. 6. Образы фонем в трехмерном подпространстве признаков ЛСК
В главе 3 рассматриваются модели построения словарей эталонов, методики поиска по ним, проводится критерий для оценки достоверности распознавания речевой команды.
Выбор методики формирования словаря эталонов
Распознавание речи путем выделения отдельных фонем на практике не принесло существенных результатов. Если вернуться к проблеме восприятия речи человеком, то оказывается, что даже опытные фонетисты с трудом справляются с задачей расчленения слитной речи на короткие сегменты. Зачастую чтобы распознать отдельную фонему, слушателю необходимо услышать слово целиком или даже несколько рядом стоящих слов.
Известно, что чем продолжительнее речевая единица, тем лучше она воспринимается на слух. Исходя из этого, для системы распознавания речевых команд в качестве эталонов наиболее целесообразно использовать целые слова.
На рис. 7 и 8 показаны два слова, записанные от разных дикторов. Слова представлены в виде точек в подпространстве двух ЛСК. Очевидно, что отдельные фонемы достаточно трудно выделить из целого слова. Соединительные линии (траектории точек ЛСК) отображают перестроение голосового тракта человека в процессе произнесения звуков. Для одних и тех же слов траектории визуально схожи. Это свойство позволяет использовать наборы векторов ЛСК, с учетом их временной последовательности, в качестве элементов обучающих словарей.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
