

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таблица 2
Эталон | Мера близости | После нормировки |
Сообщение | 1,74 | 1,00 |
Память | 3,01 | 1,73 |
Настройки | 3,06 | 1,75 |
Часы | 3,45 | 1,98 |
Офис | 3,53 | 2,03 |
Режимы | 3,68 | 2,11 |
Средства | 4,06 | 2,33 |
Контакты | 4,13 | 2,37 |
Темы | 4,15 | 2,38 |
Журнал | 4,25 | 2,44 |
Связь | 4,58 | 2,63 |
Календарь | 4,70 | 2,70 |
Оценка влияния параметров модели ЛП на достоверность распознавания
В ходе опытов, на словаре из 42 командных слов от 4 дикторов, варьировался размер кадров РС и степень аппроксимирующего полинома (порядок модели). На рис. 16 и 17 приведены графики соответствующих зависимостей. Наилучшая достоверность распознавания достигается, когда размер окна совпадает с периодами основного тона РС. При изменении порядка модели, максимум достигается на 10 корнях, далее наблюдается пологий график кривой.
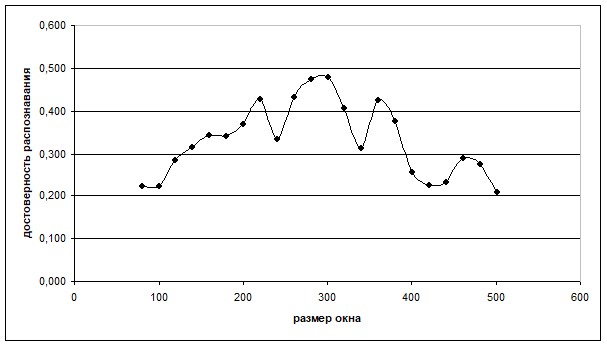
Рис. 16. Влияние размера окна на достоверность распознавания
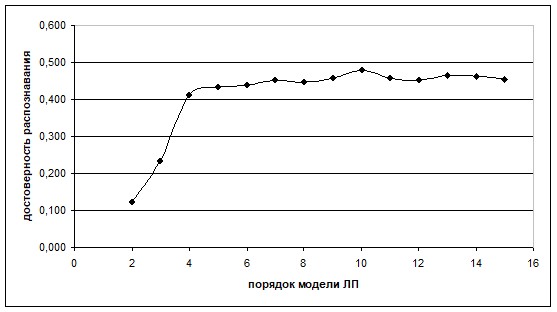
Рис. 17. Влияние порядка модели на достоверность распознавания
Результаты исследований согласуются с общеизвестными оценками оптимальных параметров модели ЛП. Что подтверждает адекватность предложенного критерия оценки достоверности распознавания речевых команд.
Оценка качества сформированного словаря эталонов
При использовании системы распознавания речевых команд в условиях повышенной зашумленности или на узкополосных каналах связи, даже на словарях малых объемов (до 50 слов) возможно большое количество ошибок. Для увеличения надежности предложено использовать коррекцию словаря эталонов.
После формирования словаря производится анализ того, насколько элементы отличаются друг от друга (табл. 3). Подсчитывается среднее значение (в данном примере 3,04). Если некоторые элементы словаря слишком похожи друг на друга (мера близости меньше порога, равного 2), то предлагается заменить один из эталонов, например, синонимом. После этого производится повторный анализ словаря.
В данном примере (табл. 3), после замены одного из похожей пары слов «темы» или «режимы», процент правильно распознанных команд увеличился на 9,8%.
Таблица 3
Эталоны | Календарь | Контакты | Настройки | Офис | Память | Режимы | Связь | Сообщение | Средства | Темы | Часы |
Журнал | 2,64 | 2,59 | 3,11 | 2,45 | 3,47 | 2,73 | 3,34 | 4,73 | 2,8 | 2,39 | 3,54 |
Календарь | 2,54 | 3 | 2,78 | 2,96 | 2,4 | 2,72 | 4,24 | 3,15 | 2,28 | 3,47 | |
Контакты | 2,77 | 2,87 | 3,32 | 3,09 | 3,17 | 4,35 | 3,1 | 2,52 | 3,49 | ||
Настройки | 2,24 | 2,53 | 3,15 | 3,41 | 3,07 | 3,46 | 2,82 | 3,33 | |||
Офис | 2,36 | 2,71 | 2,59 | 3,48 | 3,31 | 2,46 | 3,2 | ||||
Память | 3,51 | 2,66 | 2,6 | 4 | 3,06 | 3,7 | |||||
Режимы | 2,59 | 3,44 | 2,72 | 1,95 | 3,23 | ||||||
Связь | 4,29 | 3,01 | 2,4 | 2,98 | |||||||
Сообщение | 4,16 | 3,9 | 3,23 | ||||||||
Средства | 2,4 | 3,2 | |||||||||
Темы | 2,88 | ||||||||||
Среднее | 2,83 | 3,07 | 2,99 | 2,77 | 3,11 | 2,87 | 3,01 | 3,77 | 3,21 | 2,64 | 3,30 |
В главе 4 приводится подробное описание разработанного программного комплекса для анализа речевых сигналов. Представлена алгоритмическая модель системы распознавания речевых команд. Приведены результаты тестирования данной системы.
В программном комплексе реализованы основные функции:
- расчет массива линейных спектральных корней с возможностью настройки параметров модели; расчет статистических признаков различных порядков; cравнение сигналов методом динамического программирования; оценка достоверности распознавания команд по словарю; анализ влияния параметров расчета ЛСК на качество распознавания; использование произвольных речевых единиц в качестве эталонов; кластеризация словарей различными методами; хранение словарей эталонов в базе данных; графический и табличный вывод полученных результатов.
На базе модулей программного комплекса построена опытная система распознавания речевых команд. Система выполняет все операции, начиная с записи входного сигнала с микрофона и заканчивая выдачей распознанной команды в виде текстового сообщения на экране ПК.
Представлена алгоритмическая модель системы, на основании которой в любой современной среде разработки возможно построение программного комплекса, использующего процедуру распознавания команд. Кроме того, отдельные модули системы готовы к реализации на базе программируемых аппаратных средств (DSP-процессоры, ПЛИСы и т. д.) с возможностью распараллеливания вычислительных операций.
В работе проведено тестирование модели распознавания речевых команд. Выполнен сравнительный анализ ЛСК и других распространенных методов получения первичных признаков речевых сигналов. Сравнение проводилось на одних и тех же тестовых образцах.
В качестве эталонной базы использовались 42 командных слова, надиктованных четырьмя дикторами. На вход подавались сигналы от этих же дикторов, по одному варианту произнесения каждой команды. Оценивался процент ошибок и средняя достоверность распознавания. Если была допущена ошибка, то текущая команда не участвовала в подсчете среднего. Также было подсчитано среднее время расчета набора первичных признаков для одного командного слова.
В табл. 4 показаны результаты распознавания для четырех вариантов первичных признаков:
- LSP – линейные спектральные корни (пары) LPC – коэффициенты линейного предсказания PLP – коэффициенты перцептивного предсказания MFCC – мел-кепстральные коэффициенты
Наборы признаков PLP и MFCC подсчитаны с помощью соответсвующих модулей системы распознавания Sphinx4 (бесплатная разработка с открытым кодом на Java от американского университета Карнеги-Меллон).
Таблица 4.
Дикторы | Время расчета, мс | Достоверность | % ошибок | |||||||||
LSP | LPC | PLP | MFCC | LSP | LPC | PLP | MFCC | LSP | LPC | PLP | MFCC | |
Мужчина1 | 9,05 | 3,05 | 13,09 | 13,02 | 1,91 | 1,30 | 1,49 | 1,13 | 0,00 | 4,76 | 2,38 | 2,38 |
Мужчина2 | 8,45 | 2,85 | 11,91 | 12,30 | 0,78 | 0,41 | 0,78 | 0,69 | 4,76 | 23,80 | 23,80 | 19,05 |
Женщина1 | 8,31 | 2,24 | 12,20 | 11,50 | 1,46 | 0,90 | 1,07 | 1,06 | 3,84 | 19,23 | 7,69 | 7,69 |
Женщина2 | 7,95 | 2,15 | 10,30 | 10,23 | 1,35 | 0,75 | 0,99 | 0,95 | 2,86 | 8,57 | 5,71 | 5,71 |
Среднее | 8,44 | 2,57 | 11,88 | 11,76 | 1,38 | 0,84 | 1,08 | 0,96 | 2,87 | 14,09 | 9,90 | 8,71 |
Видно, что для ЛСК наблюдается минимальный процент ошибок 2,87% и максимальная степень достоверности 1,38. При этом время расчета сопоставимо с остальными методами. Что позволяет говорить о возможности успешного применения данных признаков в более сложных системах распознавания речи.
В заключении перечисляются основные результаты диссертационной работы.
ОСНОВНЫЕ РЕЗУЛЬТАТЫ РАБОТЫ
Произведен анализ современных систем распознавания речи. Выявлены основные недостатки алгоритмов распознавания речевых команд – недостаточная надежность и большой объем обучающей выборки. Выполнено исследование линейных спектральных корней в качестве информативных первичных признаков речевых сигналов, приведено обоснование их алгоритма расчета. Выбран принцип формирования словарей эталонов речевых команд и обосновано использование метода нелинейного временного выравнивания (динамического программирования) для поиска по словарям. Уточнена алгоритмическая модель системы распознавания командных слов, готовая к реализации в программной или аппаратной среде. Определен критерий для оценки достоверности распознавания речевой команды, позволяющий отсеивать ложные срабатывания алгоритма распознавания. Предложена методика оценки качества сформированного словаря эталонов, позволяющая выявить похожие по звучанию речевые команды. Показано решение задачи поиска различных речевых единиц (ключевых слов, слогов или пауз) в непрерывном речевом потоке на базе используемых методов распознавания. Разработан программный комплекс, позволяющий анализировать речевые сигналы, работать с базами данных словарей, производить различные математические расчеты и получать табличное и графическое представление результатов исследований. Проверена работа системы распознавания в сравнении с другими методами получения первичных признаков на одинаковых наборах эталонных и тестовых данных. Для ЛСК получен наименьший процент ошибок 2.87%, что позволяет говорить о возможности успешного использования данных признаков в более сложных системах распознавания речи.
СПИСОК ОПУБЛИКОВАННЫХ РАБОТ
Гладышев, комплекс для исследований в задачах распознавания речи на основе аппарата линейного предсказания [Электронный ресурс] / // Научная конференция «Вычислительные и информационные технологии в науке, технике и образовании»: тез. докл. / ПГУ. – Павлодар (Казахстан), 2006. – Режим доступа: http://www. nsc. ru/ws/show_abstract. dhtml? ru+148+10143. Гладышев, основных физических параметров речи на качество ее распознавания / . 2007. СПбГУТ. 9 с. Деп. в ВИНИТИ 26.06.07. – 2007. Свидетельство об официальной регистрации программы для ЭВМ 2007614250 РФ. Программа распознавания речевых информационных сигналов / и др. // Информационный бюллетень официальной регистрации РосАПО. 2007. Гладышев, русской речи на основе аппарата линейного предсказания / // Научная сессия «IX Невские чтения»: тез. докл. / НИЯК. – СПб, 2007. – С. 230. Гладышев, выбора эталонной единицы при распознавании речи / // Журнал научных публикаций аспирантов и докторантов. – 2008. – № 9. – С.244–247 (входит в перечень ВАК). Гладышев, поиска ключевых слов в непрерывном речевом потоке / // Естественные и технические науки. – 2009. – № 1. – С. 242–244 (входит в перечень ВАК). Гладышев, автоматического распознавания речевых команд / , // Известия высших учебных заведений. Приборостроение. – 2009. – № 3. – С. 17–21 (входит в перечень ВАК). Гладышев, отдельных слов в разговорной речи [Электронный ресурс] / // VI Всероссийская межвузовская конференция молодых ученых: тез. докл. / ИТМО – СПб, 2009. – Режим доступа: http://fppo. ifmo. ru/kmu/kmu6/ВЫПУСК_6/Ready_инф_техн/52_Gladyshev_K_K. pdf.Подписано к печати 09.09.2010
Объем 1 печ. л. Тир. 80 экз., заказ №27
Отпечатано в СПбГУТ. 191186 СПб, наб. р. Мойки, 61

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
