

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
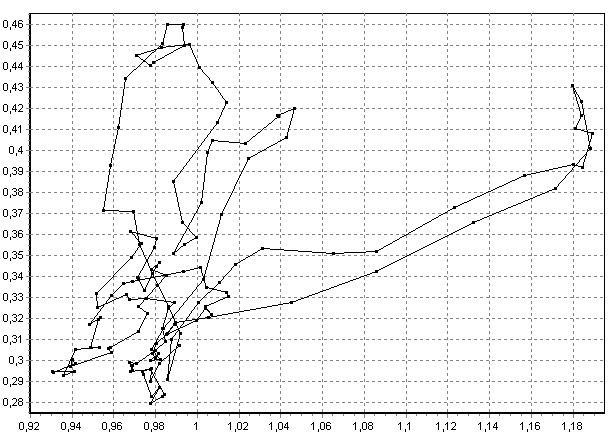

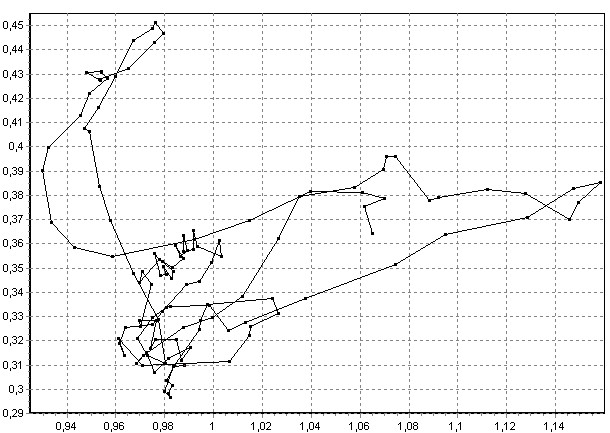

Рис. 7. Образы слова «сообщение» для двух разных дикторов
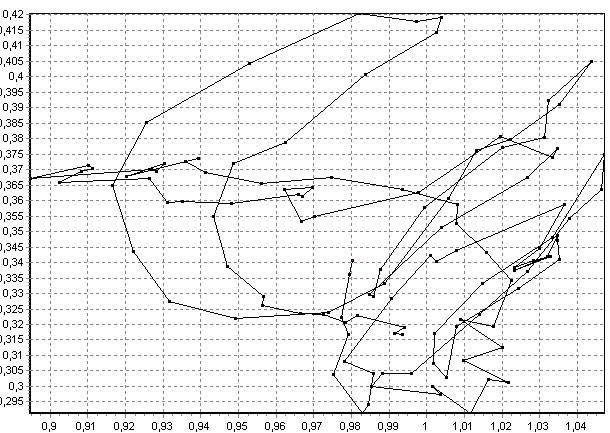

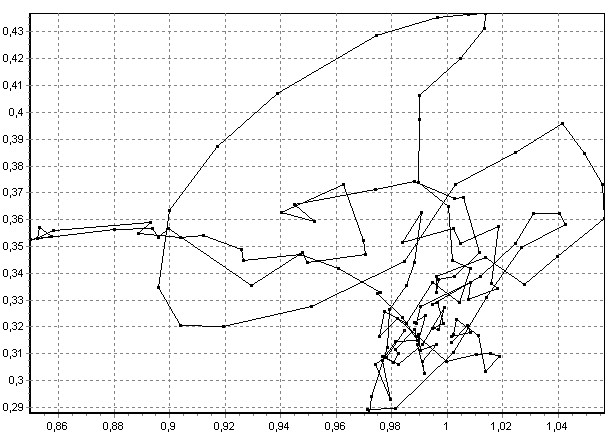

Рис. 8. Образы слова «настройки» для двух разных дикторов
Оценка меры близости между входным РС и эталоном производится с помощью метода нелинейного временного выравнивания (динамического программирования). Это один из наиболее мощных и широко известных математических методов современной теории управления, был предложен в конце 50-х годов американским математиком Р. Беллманом для решения оптимизационных задач. Метод позволяет сравнивать разные по длительности образцы. Применимо к речевым сигналам это означает, что сравнение с эталонами возможно практически независимо от темпа речи.
Пусть сравнивается два образца сигналов, представленных в виде массива векторов (для РС это наборы ЛСК):
![]() и
и ![]() . (16)
. (16)
Различие между векторами двух образов определяется последовательностью состояний ![]() и обозначается:
и обозначается:
![]() , (17)
, (17)
где ![]() и
и ![]() – начальное и конечные состояния,
– начальное и конечные состояния, ![]() функция временного выравнивания, которая проецирует временную область одного образа на временную область другого образа.
функция временного выравнивания, которая проецирует временную область одного образа на временную область другого образа.
Метод ДП заключается в том, что ищется такая функция ![]() , при которой путь из состояния
, при которой путь из состояния ![]() в состояние
в состояние ![]() , является оптимальным, т. е. будет получено минимальное накопленное расстояние между двумя образами.
, является оптимальным, т. е. будет получено минимальное накопленное расстояние между двумя образами.
При построении оптимального пути, на каждом шаге алгоритма используется основная формула ДП:
 , где
, где ![]() . (18)
. (18)
В качестве расстояния между векторами используется взвешенная евклидова метрика:
![]() , (19)
, (19)
где N_SEC – размерность векторов признаков.
На выходе процедуры сравнения получается некоторое число (мера близости), представляющее собой величину, обратную степени близости между сигналами.
Процедура поиска по словарю заключается в последовательном сравнении входного сигнала с каждым из эталонов речевых команд. В табл. 1 показан результат поиска команды «сообщение» в словаре из четырех командных слов. В результате входной сигнал правильно распознан системой. На рис. 9 отображаются траектории кратчайших переходов по кадрам от эталонных сигналов к распознаваемому. Данные по оси ординат нормированы по длительности эталонных сигналов. По оси абсцисс идут номера кадров входного сигнала. Участки с крутыми переходами между точками отображают автоматическое временное масштабирование сигналов. Это происходит, например, если при произнесении диктором растягивается гласный звук.
Таблица 1
Эталон командного слова | Мера близости |
Сообщение | 1,85 |
Журнал | 5,13 |
Диспетчер | 6,82 |
Календарь | 4,33 |
Идеальный случай, когда распознаваемый сигнал совпадает с эталонным, представляет собой диагональную ступенчатую траекторию из левого нижнего угла в верхний правый. На рис. 9 для эталонов «журнал» и «календарь» наблюдается существенное отклонение от диагонали, что может являться дополнительным критерием для принятия решения при распознавании слов.
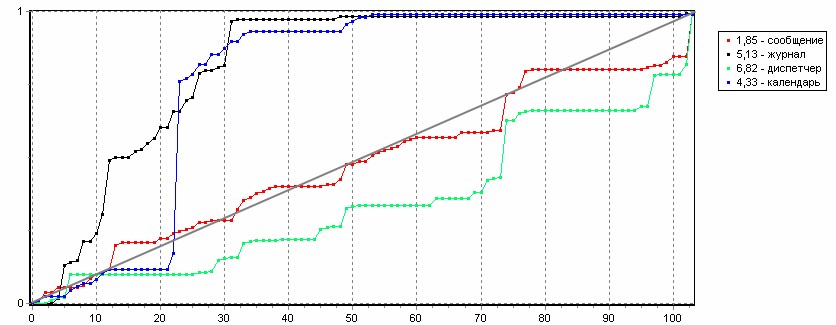

Рис. 9. Оптимальные траектории при сравнении с эталонами
До того как будет распознано целое командное слово, на базе предложенной модели возможно распознавание более мелких речевых единиц. Это позволит сократить область поиска в словаре и повысить точность алгоритма. На рис. 11 представлен результат распознавания целого слова «режимы» на словаре, состоящем из набора слогов. В качестве одного из элементов словаря используется «эталон тишины» (обозначен как «_»), что позволяет без применения дополнительных алгоритмов выделять паузы в речевых сигналах.
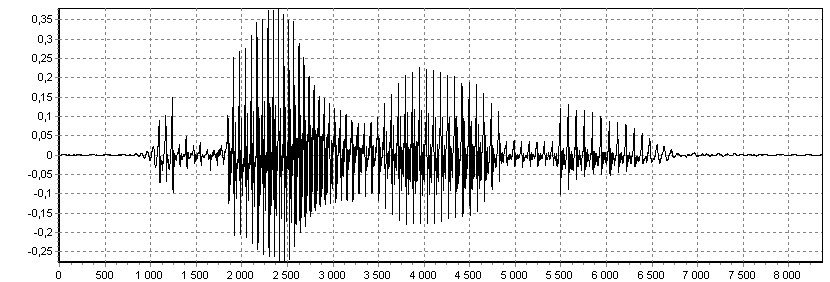

Рис. 10. Временная диаграмма слова «ре-жи-мы»
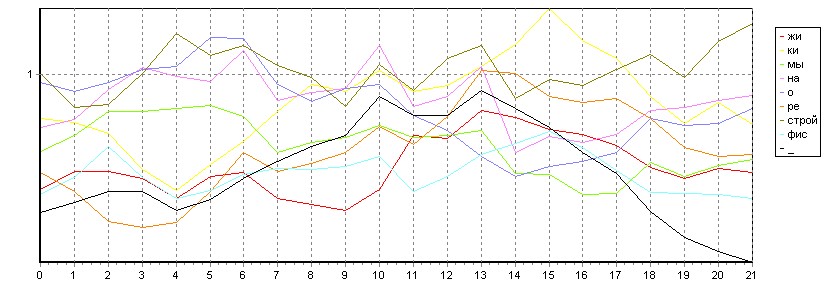

Рис. 11. Результат поиска слогов: «__ререре__жижижижи_мымыомымы____»
Входной сигнал разбивается на кадры по средней длине эталонов. На графике показаны диаграммы меры близости до каждого из эталонов для всех кадров речевого сигнала. В результате получаем последовательность распознанных слогов. Путем свертки и дальнейшей семантической обработки возможно получение целого слова. Данная методика может использоваться для построения СРР на словарях больших объемов.
Предложено решение задача поиска слов в непрерывном речевом потоке. В качестве элементов словаря используются целые слова. На вход системы подается продолжительный участок речевого сигнала. В данном примере, фраза: «Черная тойота номер три два один в сторону Питера» (рис. 12).
Поиск идет без предварительной сегментации фразы на отдельные слова. На рис. 12 и 13 наблюдаются локальные минимумы в области искомых эталонных единиц. На рис. 15 ярко выраженного минимума нет, так как искомое слово («зеленая») не было произнесено в предложении. Соотношение значения средней меры близости по всем кадрам РС и значения меры близости на локальном минимуме является критерием, позволяющим автоматически определять, присутствует ли вообще искомое слово в анализируемой фразе.
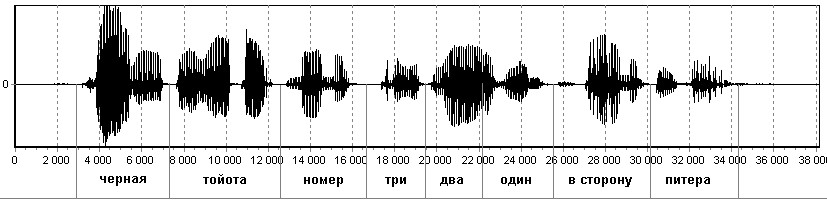

Рис. 12. Временная диаграмма целой фразы
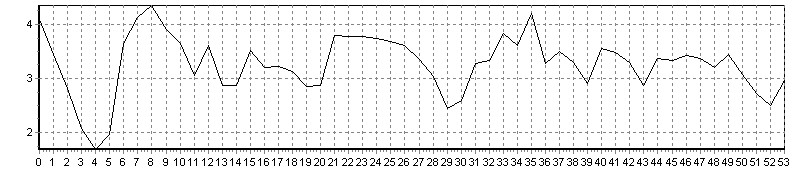

Рис. 13. Поиск слова «черная» (соотношение меры близости = 0,5)
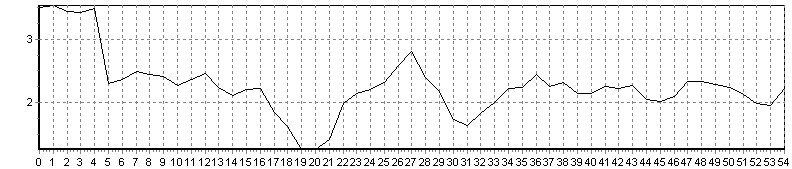

Рис. 14. Поиск слова «номер» (соотношение меры близости = 0,5)
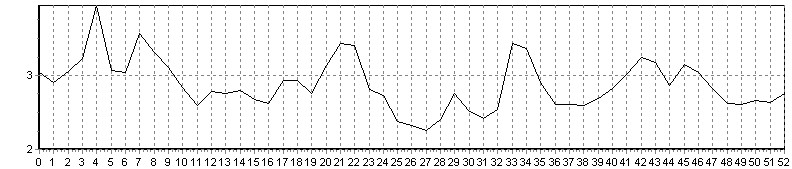

Рис. 15. Поиск слова «зеленая» (соотношение меры близости = 0,8)
Критерий для оценки достоверности распознавания слов
При распознавании речевых команд на базе словаря из набора целых слов, получается таблица со значениями меры близости до элементов словаря. Эталон с минимальным значением является искомым – распознанным. Даже если на вход системы будет подано слово, не входящее в словарь, в любом случае будет получен результат – один из эталонов. Что приведет к ошибке распознавания.
Предложено решение задачи автоматического отсеивания ложных срабатываний системы. Таблица результатов распознавания нормируется (табл. 2). Далее подсчитывается разница в значении меры близости между первым и вторым эталоном. В данном примере это 0,73. Если эта разница не превышает пороговое значение 0,5, то слово будет считаться нераспознанным и системой будет выдан запрос на повторный ввод команды. Предложенный критерий позволяет оценивать достоверность распознавания текущего слова.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
