


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Рассмотрим задачу PageRanking для такого графа. PageRanking - один из алгоритмов ссылочного ранжирования. Алгоритм применяется к коллекции документов, связанных гиперссылками (таких, как веб-страницы), и назначает каждому из них некоторое численное значение, измеряющее его вес или ранг среди остальных документов. Алгоритм может применяться не только к веб-страницам, но и к любому набору объектов, связанных между собой взаимными ссылками, то есть к любому графу. [4]
Рисунок 1 - Реализация алгоритма PageRanking с помощью технологии MapReduce.
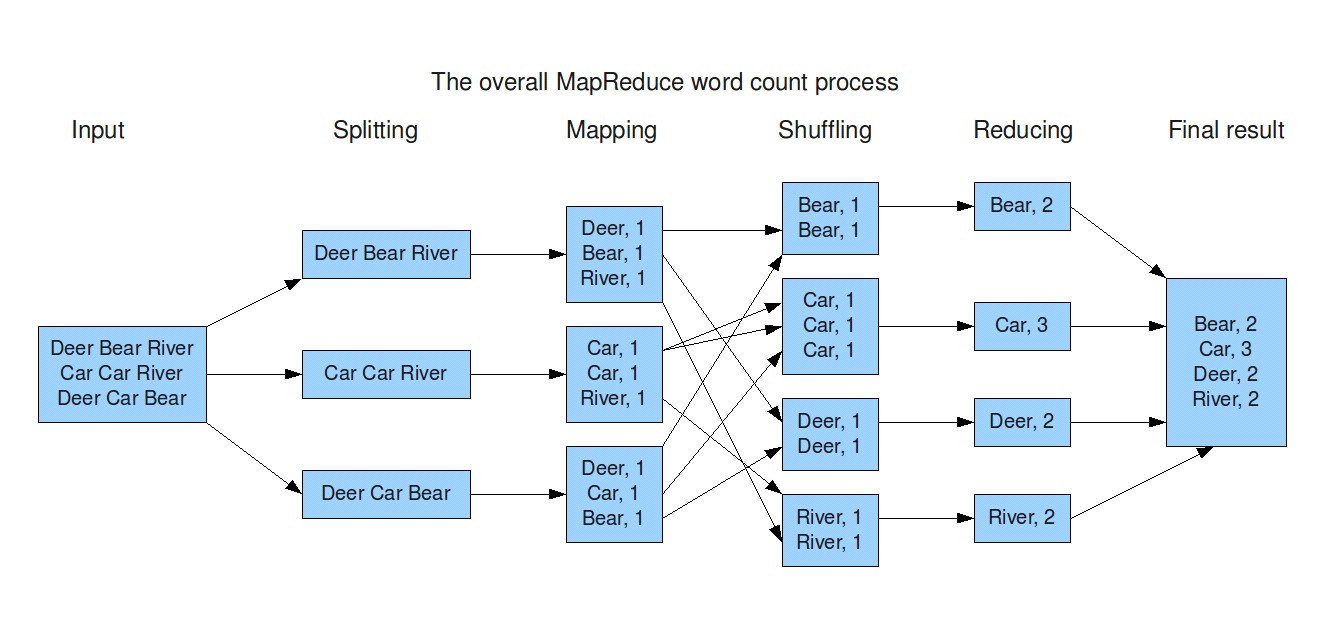
Алгоритм можно реализовать в фреймворке MapReduce, цепочкой последовательных применений map и reduce: map передаёт данные о текущей важности узла его соседям, reduce — находит новое значение по приведённой выше формуле. Вычисления заканчиваются после достижения достаточной сходимости, или выполнения заранее заданного количества итераций. Ключом для пар (ключ, значение) является идентификатор вершины (числовое значение). В связи с тем, что стандартная реализация MapReduce использует hash функцию для разделения промежуточных данных на блоки, соседние узлы с малой вероятностью попадут в один блок, что существенно замедляет работу программы. Для решения этой проблем можно успешно использовать, регулируемые механизмы MapReduce. Например описав свой метод разбивки данных (partitioner) – определяет какому редуктору послать пару (ключ, список), или комбинатора данных (combiner) – механизм локальной редукции.
Наглядно этот алгоритм можно рассмотреть на рисунке 1.
Рассмотрим потоки данных MapReduce. MapReduce задание(job) - единицы работы, езультат которой хочет получить клиент: она состоит из входных данных, MapReduce программы и конфигураций. Hadoop выполняет задание, разделив его на задачи(task), которые бывают двух типов: map-задачи и reduce-задачи.
Есть два типа узлов, которые управляют процессом выполнения задания: JobTracker и некоторое количетсво TaskTracker. JobTracker координирует всю работу выполняющуюся в системе планирую задачи для TaskTracker-ов. Tasktrackers выполненяют задачи и отправляют данные о ходе выполнения JobTracker-у, который ведет учет общего прогресса каждого задания. Если выполнение задачи не удается, JobTracker может перенести его на другой TaskTracker. [8]
Hadoop делит входные данные MapReduce на части фиксированного размера, называемые расщепления (split, альтернативные переводы принимаются). Hadoop создает одну map задачу для каждого расщепления. Задача, в свою очередь, запускает пользователескую (описанную нами в программе) map-функцию для каждой записи расщепления.
При наличии большого количества расщеплений, время, затраченное на обработку каждого расщепления будет достаточно мало по сравнению со времени, затраченным на обработку всего ввода. Таким образом, если мы обрабатываем расщепления параллельно, вычислительная нагрузка будет лучше сбалансированна, если расщепления малы, так как более быстрая машина сможет обработать пропорционально больше расщеплений в течение задания, чем медленнее машина. Даже если машины одинаковые, проваленные задачи или посторонние задания выполняемые на машине делают балансировку нагрузки желательной, и качество балансировки нагрузки возрастает по мере уменьшения расщеплений.
С другой стороны, если расщепления слишком малы, то накладные расходы на управление ими и время затрачиваемое на создание map-задач начинает доминировать над общим временем выполнения задания. Для большинства заданий, лучший размер расщепления, равен размеру HDFS блока (64 Мб по умолчанию, может быть изменено в настройках кластера (для всех вновь создаваемых файлов), или указано при создании отдельного файла). Hadoop делает всё возможное, чтобы запустить map-задачу на узле, на котором находятся данные в HDFS. Это называется локализацией вычислений (data locality optimization). Теперь должно быть понятно, почему оптимальный размер расщепления равен размеру блока: это самый крупный размер данных, который гарантированно будет храниться на одном узле. Допустим расщепление охватывает два блока: маловероятно, что любой узел HDFS хранит оба необходимых блока, поэтому некоторые из расщеплений должны быть переданы по сети на узел, где работает map-задача, что наверняка менее эффективно, чем выполнение map-задачи используя локальных данных.
Map-задача записывают обработанные данные на локальный диск, а не HDFS. Почему это происходит? Выходные данные map — это промежуточный результат: они обрабатываются reduce, для получения конгечного результата и после этого могут быть удалены. Поэтому хранение этих данных в HDFS, с репликацией, будет излишним. Если произошла ошибка в узде выполняющем map-задачу, до того как данные были использованы reduce, Hadoop автоматически перезапустит map на другом узле, чтобы воссоздать данные заново.
Reduce-задачи не имеют преимущества локальности данных, так как используют результат полученный от многих map-задач. Допустим есть одна reduce-задача, тогда на её вход подаются результаты всех map. Отсортированые результаты map-задач должны быть переданы по сети на узел, где задача выполняется reduce. Там они сливаются (пары с одинаковым ключом сливаются в 1 список), и передаются на вход пользовательской функции reduce (выполнений будет столько, сколько различных ключей). Выход reduce-задач как правило для надежности хранится в HDFS. Для каждого блока выхода редукции: первая реплика хранится на локальном узле, вторая в той же стойке, другом узле, третья — в узле из другой стойки. То есть запись выходных данных reduce потребляет пропускную способность сети так же как обычная запись блока данных в HDFS.
Каркас MapReduce не позволяет задавать в качестве типа произвольный класс. В MapReduce определен некий способ сериализации пар (ключ, значение) для передачи их через границы машин в кластере, и только классы поддерживающие эту сериализацию, могут выступать в роли типов ключей и значений. Точнее классы реализующие интерфэйс Writable, могут быть типами значений, а классы реализующие WritableComparable типами ключей или значений. Требование сравнимости ключа выдвигается потому, что на этапе редукции они сортируются, тогда как значения просто передаются наприямую.
В состав Hadoop входят ряд готовых классов реализующих WritableComparable, например BooleanWritable, ByteWritable, DoubleWritable, FloatWritable, IntWritable, LongWritable, Text. NullWritable (заглушка для случвая когда ключи или значения не нужны1). Можно самостоятельно описать тип, реализовав интерфейс Writable или WritableComparable. Способ разбиения входного файла на порции определяется реализацией интерфейса InputFormat. По умолчанию используется TextInputFormat — каждая текстовая строка считается записью, ключ — номер строки в файле. Другие популярные классы: KeyValueTextInputFormat — каждая строка в текстовом файле считается записью, при этом ключом считается содержимое строки до разделителя (разделитель по умолчанию — символ табуляции); SequenceFileInputFormat<K, V> - для чтения специфичных файлов последовательностей, NlineInputFormat — то же что TextInputFormat, но каждая порция гарантированно состоит из N строк.
Отметим также, что Apache Hadoop поддерживают работу со сжатыми типами данных. (Классы CompressedCombineFileInputFormat, CompressedCombineFileRecordReader, CompressedCombineFileWritable)
Выходной формат данных также можно настраивать, с помощью интерфейса OutputFormat. По умолчанию используется — KeyValueTextInputFormat. Другие классы: NullOutputFormat, SequenceFileOutputFormat<K, V> (предпочтителен для создания цепочек задач MapReduce)
1.2 Фреимворк Apache Hadoop
Hadoop — проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и программный каркас для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Язык реализации — Java.
Hadoop состоит из 4 подпроектов:
Hadoop Common (связующее программное обеспечение — набор инфраструктурных программных библиотек и утилит, используемых для других подпроектов и родственных проектов), HDFS (распределённая файловая система) Hadoop YARN: Фреимворк для управления ресурсами кластера Hadoop MapReduceРазработка была инициирована в начале 2005 года Дугом Каттингом с целью построения программной инфраструктуры распределённых вычислений для проекта Nutch — свободной программной поисковой машины на Java, её идейной основой стала публикация сотрудников GoogleДжеффри Дина и Санжая Гемавата о вычислительной концепции MapReduce.
В апреле 2010 года корпорация Google предоставила Apache Software Foundation права на использование технологии MapReduce, через три месяца после её защиты в патентном бюро США, тем самым избавив организацию от возможных патентных претензий.
Начиная с 2010 года Hadoop неоднократно характеризуется как ключевая технология «больших данных», прогнозируется его широкое распространение для массово-параллельной обработки данных, и, наряду с Cloudera, появилась серия технологических стартапов, целиком ориентированных на коммерциализацию Hadoop.
Среди пользователей Hadoop можно отметить: Facebook, Yahoo, , intuit, apple, eBay, Google, IBM, MicroSoft, The New York Times, Twitter.
В Hadoop Common входят библиотеки управления файловыми системами, поддерживаемыми Hadoop и сценарии создания необходимой инфраструктуры и управления распределённой обработкой, для удобства выполнения которых создан специализированный упрощённый интерпретатор командной строки (FS shell, filesystem shell), запускаемый из оболочки операционной системы командой вида:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
