


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Emit(Match2.Propose:Match2.PatternPose, Match2)
}
Здесь Pattern — глобальная переменная; под операцией « : » понимается операция конкатенации строк; Prolength - длина строки (предполагается что строки имеют одинаковую длину); объект Match имеет следующие поля: Begin, End — принимает значение TRUE если найденое совпадение содержит первый/последний символ паттерна соотвтественно, Propose, Pronumber — содержат номер строки и позицию в строке в которой найдено совпадение, PatternPose — позиция в шаблоне, с которой начинается совпадение, Status – принимает одно из возможных значений Request или Is, Complited — принмает значение TRUE если шаблон найден целиком, Lastpronum — принимает значение номера последней строки в которой найден шаблон; функция FindPattern(S, Pattern) — последовательный алгоритм поиска совпадения строки с шаблоном.
Словесное описание алгоритма:
Входной протокол разбивается на последовательности, длины ![]() , считываемые Map. Map ищет все совпадения между отрезками паттерна и входными последовательностями (так как паттерн в общем случае имеет длину больше
, считываемые Map. Map ищет все совпадения между отрезками паттерна и входными последовательностями (так как паттерн в общем случае имеет длину больше ![]() ). Для каждого найденного совпадения, если только оно не содержит конец шаблона, Map возвращает 2 пары значений. Первая пара в качестве ключа содержит данные о позиции, в которой найдено совпадение, и в качестве значения – объект со статусом Is. Вторая пара содержит объект со статусом request и в качестве ключа имеет данные об позиции шаблона и номере последовательности в которой предположительно должно быть продолжение шаблона. Таким образом, получим на входе Reduce список из 1 или 2 объектов. Если объектов 2, это означает, что мы нашли 2 соседние последовательности содержащие шаблон. Далее Reduce повторяет выполнение до тех пор, пока не найден весь шаблон или не превышен лимит на количество итераций.
). Для каждого найденного совпадения, если только оно не содержит конец шаблона, Map возвращает 2 пары значений. Первая пара в качестве ключа содержит данные о позиции, в которой найдено совпадение, и в качестве значения – объект со статусом Is. Вторая пара содержит объект со статусом request и в качестве ключа имеет данные об позиции шаблона и номере последовательности в которой предположительно должно быть продолжение шаблона. Таким образом, получим на входе Reduce список из 1 или 2 объектов. Если объектов 2, это означает, что мы нашли 2 соседние последовательности содержащие шаблон. Далее Reduce повторяет выполнение до тех пор, пока не найден весь шаблон или не превышен лимит на количество итераций.
Если шаблон помещается в 8 строк исходной последовательности, вывод map будет выглядеть как показано на рисунке 3.
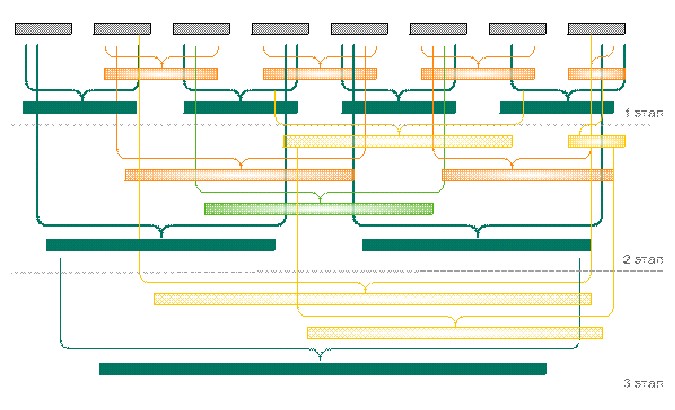
Рисунок 3 - Вывод Reduce при поиске частного шаблона.
Для того чтобы полностью обнаружить шаблон потребовалось 3 этапа. На первом этапе формируются последовательности длины ![]() На втором шаге получаем 5 последовательности длины
На втором шаге получаем 5 последовательности длины ![]() , 1 последовательность длины
, 1 последовательность длины ![]() , и последовательность длины
, и последовательность длины ![]() , содержащую конец шаблона. Необходимость всегда возвращать информацию о совпадении, содержащую конец отрезка в неизменном виде необходима для случая, когда паттерн делится на нечетное количество последовательностей. Как видно, Reduce имеет здесь избыточный выход, однако на последнем шаге гарантированно будет только 1 объект, содержащий информацию о всём шаблоне. Кроме того выполняемый в reduce код имеет константную оценку сложности. Самая сложная часть алгоритма выполняется в функции Map над последовательностями незначительной длины и может быть перенесена на сторону данных. Оценка сложности всего алгоритма
, содержащую конец шаблона. Необходимость всегда возвращать информацию о совпадении, содержащую конец отрезка в неизменном виде необходима для случая, когда паттерн делится на нечетное количество последовательностей. Как видно, Reduce имеет здесь избыточный выход, однако на последнем шаге гарантированно будет только 1 объект, содержащий информацию о всём шаблоне. Кроме того выполняемый в reduce код имеет константную оценку сложности. Самая сложная часть алгоритма выполняется в функции Map над последовательностями незначительной длины и может быть перенесена на сторону данных. Оценка сложности всего алгоритма
![]() (2)
(2)
где ![]() - количество параллельно выполняющихся map функций,
- количество параллельно выполняющихся map функций, ![]() - количество параллельно выполняющихся reduce функций,
- количество параллельно выполняющихся reduce функций, ![]() – длина протоколов,
– длина протоколов, ![]() – длина считываемой Map строки, настраиваемый параметр,
– длина считываемой Map строки, настраиваемый параметр, ![]() – длина шаблона,
– длина шаблона, ![]() – константы,
– константы, ![]() – количество повторений шаблона в протоколе. В этой формуле
– количество повторений шаблона в протоколе. В этой формуле ![]() - оценка сложности функции FindPattern();
- оценка сложности функции FindPattern(); ![]() – количество выполняемых последовательно функций map,
– количество выполняемых последовательно функций map, ![]() – количество этапов за которые в reduce попадёт полный шаблон,
– количество этапов за которые в reduce попадёт полный шаблон, ![]() – грубая оценка количества reduce выполняемых последовательно на каждом шаге.
– грубая оценка количества reduce выполняемых последовательно на каждом шаге.
ЗАКЛЮЧЕНИЕ
Изучена проблема больших данных имитационного моделирования и обработки больших строковых последовательностей.
Освоена технология программирования для фреимворка MapReduce и свободно распространяемый инструмент для его реализации — Hadoop.
Разработаны алгоритмы для поиска частного паттерна и вычисления расстояния Хемминга в режиме offline над длинными строковыми последовательностями генерируемыми и накапливаемыми в ходе имитационного моделирования. Проведена оценка алгоритмов.
Из приведенных оценок видно, что их производительность для больших последовательностей многократно превосходит последовательные.
Важно так же отметить, что использование технологии MapReduce не противоречит проблеме хранения больших данных, так как Apache Hadoop позволяет работать непосредственно со сжатыми данными.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
етоды и алгоритмы вычислений на строках // М.: , - 2006, - 496 стр , Моспан обработка паттернов в больших данных имитационного моделирования. // ТРИС-2013: материалы конференции. Том 1, - Таганрог: Издательство Технологического института ЮФУ, - 2013, - С. 24-28; , Моспан обработка паттернов в больших данных имитационного моделирования. // Информатизация и связь, - 2013, - №2, - С. 141-143; , Моспан больших данных с помощью MapReduce. // Материалы конференции. Краснодар, 2013 Компьютерные технологии и вычислительная математика,- С. 13 - 14 , Замятина средства имитационного моделирования для анализа бизнес-процессов и управления рисками. // Информатизация и связь, — 2011, - № 3, - C. 14 – 16. , Миков средства системы имитации для обеспечения ее адаптируемости и открытости. // Информатизация и связь, - 2012, - №5, - C. 130 – 133. , Воробьев агентов с деонтической логикой, функционирующих в распределенных системах. // Информатизация и связь, — 2012, - № 5, — C. 82 – 85. Tom W. Hadoop: The Definitive Guide. // O'Reilli, — 2011, - 504. Jeffrey D., Sanjay G. MapReduce: Simplified Data Processing on Large Clusters. [электронный ресурс] URL: http://static. /media/research. /ru//archive/mapreduce-osdi04.pdf дата обращения: 25.10.2013 Lin J., Schatz M. Design Patterns for Efficient Graph Algorithms in MapReduce. [электронный ресурс] URL: https://cs. wmich. edu/gupta/teaching/cs5950/sumII10cloudComputing/graphAlgo%20in%20mapReduce%20paper%20p78-lin. pdf дата обращения: 12.08.2013 Lammel R. Google’s MapReduce programming model — Revisited. // Science of Computer Programming, – 2008, – page 1 - 30 Bressan S., Cuzzocrea A., Karras P., Lu X., Heyrani Nobari S. An effective and efficient parallel approach for random graph. // Journal of Parallel and Distributed Computing, - 2013, – page 303 - 316 ольшие Данные — новая теория и практика // Открытые системы. СУБД, - 2011, — № 10. Моррисон, Алан. Большие Данные: как извлечь из них информацию. // Технологический прогноз, - 2010, - № 3. Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data. Gartner. [электронный ресурс] URL: http://www. /newsroom/id/1731916 дата обращения: 12.12.2013 Manyika, James. Big data: The next frontier for innovation, competition, and productivity. McKinsey Global Institute [электронный ресурс] URL: http://www. /insights/business_technology/big_data_the_next_frontier_for_innovation дата обращения: 6.12.2013 лава 18. Имитационное моделирование // Введение в исследование операций — М.:«Вильямс», - 2007, - №7, — С. 697-737. , Толкачева моделирование. // МГТУ им. Баумана, - 2008, — С. 697-737. Hellerstein, Joe. Parallel Programming in the Age of Big Data. [электронный ресурс] URL: http:///2008/11/09/mapreduce-leads-the-way-for-parallel-programming/ дата обращения: 01.12.2013 Segaran T., Hammerbacher J. Beautiful Data: The Stories Behind Elegant Data Solutions// O'Reilly Media, - 2012, - p. 257. Oracle and FSN, "Mastering Big Data: CFO Strategies to Transform Insight into Opportunity" [электронный ресурс] URL: http://www. fsn. co. uk/channel_bi_bpm_cpm/mastering_big_data_cfo_strategies_to_transform_insight_into_opportunity дата обращения: 10.11.2013 Jacobs, A. The Pathologies of Big Data. [электронный ресурс] URL: http://queue. acm. org/detail. cfm? id=1563874 дата обращения: 21.11.2013 Magoulas R., Lorica B. Introduction to Big Data. Release [электронный ресурс] URL: http://radar. /r2/release2-0-11.html дата обращения: 23.12.2013 Snijders, C., Matzat, U. ‘Big Data’: Big gaps of knowledge in the field of Internet. // International Journal of Internet Science, - №7, - page 1-5. Beyer, Mark. Gartner Says Solving 'Big Data' Challenge Involves More Than Just Managing Volumes of Data. Gartner. [электронный ресурс] URL: http://www. /newsroom/id/1731916 дата обращения: 5.11.2013 "What is Big Data?". Villanova University. [электронный ресурс] URL: http://www. /university-online-programs/what-is-big-data/ дата обращения: 23.10.2013

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
