


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
ЗАДАНИЕ И МЕТОДИЧЕСКИЕ УКАЗАНИЯ
К ВЫПОЛНЕНИЮ ЗАДАНИЯ ПО ДИСЦИПЛИНЕ
«ТЕОРИЯ ВЕРОЯТНОСТЕЙ И МАТЕМАТИЧЕСКАЯ СТАТИСТИКА»
Внимание! Данное задание необходимо выполнить и отправить на проверку преподавателю
Задание. Данное задание должно быть выполнено с использованием MS EXCEL. В результате выборочного обследования торговых предприятий получены следующие данные о значениях их дневного товарооборота (в тысячах рублей)
6,00 | 6,04 | 6,39 | 10,97 | 7,86 | 7,25 | 8,03 | 5,07 | 6,46 | 2,81 |
7,99 | 6,45 | 3,02 | 5,78 | 5,84 | 7,00 | 7,25 | 6,76 | 5,03 | 8,24 |
1,99 | 3,43 | 4,34 | 5,37 | 7,27 | 6,50 | 5,74 | 3,28 | 7,42 | 6,86 |
4,57 | 5,85 | 4,42 | 5,01 | 5,95 | 5,11 | 5,19 | 8,49 | 4,87 | 5,97 |
3,54 | 7,90 | 4,55 | 7,00 | 6,55 | 4,13 | ||||
Методические указания к выполнению задания.
Введите числовой массив выборочных данных.
В качестве примера задание будет выполнено для следующих выборочных данных признака Х (дневной товарооборот торговых предприятий в тыс. р.):
2,56 | 1,28 | 5,53 | 7,66 | 4,72 | 3,99 | 3,26 | 1,13 | 4,25 | 5,04 |
2,87 | 2,24 | 2,00 | 2,25 | 7,35 | 4,92 | 4,98 | 2,41 | 3,44 | 8,46 |
3,39 | 8,30 | 6,66 | 5,21 | 6,98 | 7,26 | 5,13 | 7,27 | 3,97 | 4,09 |
6,45 | 4,95 | 1,91 | 5,46 | 4,31 | 3,01 | 4,86 | 5,83 | 2,99 | 5,78 |
7,74 | 1,92 | 1,96 | 4,07 | 1,87 | 2,97 | 4,43 | 5,85 | 6,33 |
1. С помощью встроенной функции СЧЕТ из категории Статистические подсчитайте объём выборки n. В появившемся окне для функции СЧЕТ в поле Значение 1 выделите все ячейки введенного массива данных. В нашем примере количество вариант n = 49.
Наименьшее значение варианты находится с помощью встроенной функции МИН из категории Статистические, В нашем примере ![]()
![]()
Аналогично найдите наибольшее значение варианты среди приведенных выборочных данных с помощью функции МАКС. В примере ![]()
![]()
Все варианты массива данных находятся в некотором промежутке [a; b]. Рекомендуется в качестве концов промежутка a и b выбрать целые значения, ближайшие к ![]()
![]() и
и ![]()
![]() таким образом, чтобы взятый промежуток включал весь диапазон выборочных данных. В нашем примере это промежуток [1; 9].
таким образом, чтобы взятый промежуток включал весь диапазон выборочных данных. В нашем примере это промежуток [1; 9].
Разбейте данный промежуток на 10 равных частей (n = 10). Шаг разбиения равен
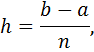
в нашем примере h = 0.8.
2. Постройте интервальный вариационный ряд, оформив табл. 1. В первый столбец табл. 1 поместите номера частичных интервалов. Во второй и третий столбцы табл.1 поместите левые и правые границы частичных интервалов, которые получаются путем последовательного добавления шага h. Здесь и в дальнейшем используйте операцию Автозаполнение.
Для заполнения четвертого столбца табл.1 подсчитайте, сколько значений признака Х попадает в каждый частичный интервал с помощью функции ЧАСТОТА из категории Статистические. Выделите соседний (четвертый) столбец из 10 пустых ячеек и в окне функции ЧАСТОТА в позиции Массив данных выделите исходный массив данных. В позиции Массив интервалов укажите адрес столбца правых концов частичных интервалов. Для завершения команды ЧАСТОТА нажмите одновременно клавиши [Shift]+[Ctrl] + [Enter]. В выделенном столбце ячеек появятся значения абсолютных частот ![]()
![]() , которые показывают, сколько вариант из массива данных попало в каждый частичный интервал. Убедитесь, что сумма частот равна объему выборки n, найденному ранее.
, которые показывают, сколько вариант из массива данных попало в каждый частичный интервал. Убедитесь, что сумма частот равна объему выборки n, найденному ранее.
В дискретном распределении в качестве значений вариант xi берут середины частичных интервалов:
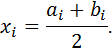
3. Для построения гистограммы, полигона относительных частот и полигона накопленных относительных частот заполните последние два столбца табл. 1.
Относительные частоты значений признака Wi находят по формуле
![]()
Найдите сумму значений этого столбца, которая должна быть равна 1.
Далее вычислите накопленные частоты ![]()
![]() . Накопленная относительная частота для каждого интервала находится как сумма частот всех предыдущих интервалов, включая данный:
. Накопленная относительная частота для каждого интервала находится как сумма частот всех предыдущих интервалов, включая данный:
![]()
В последнем десятом интервале появится сумма всех относительных частот, которая должна быть равной 1.
Таблица 1
№ |
|
|
|
|
|
|
1 | 1,0 | 1,8 | 2 | 1,4 | 0,0408 | 0,0408 |
2 | 1,8 | 2,6 | 9 | 2,2 | 0,1837 | 0,2245 |
3 | 2,6 | 3,4 | 6 | 3,0 | 0,1224 | 0,3469 |
4 | 3,4 | 4,2 | 5 | 3,8 | 0,102 | 0,449 |
5 | 4,2 | 5,0 | 8 | 4,6 | 0,1633 | 0,6122 |
6 | 5,0 | 5,8 | 6 | 5,4 | 0,1224 | 0,7347 |
7 | 5,8 | 6,6 | 4 | 6,2 | 0,0816 | 0,8163 |
8 | 6,6 | 7,4 | 5 | 7,0 | 0,102 | 0,9184 |
9 | 7,4 | 8,2 | 2 | 7,8 | 0,0408 | 0,9592 |
10 | 8,2 | 9,0 | 2 | 8,6 | 0,0408 | 1 |
| 49 | 1 |
Далее найдите основные выборочные характеристики, полученного статистического распределения. К ним относятся выборочная средняя, выборочная дисперсия и выборочное среднее квадратическое отклонение. Расчетные формулы для их вычисления имеют вид:
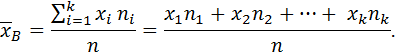
- среднее выборочное значение, это значение признака Х, вокруг которого группируются наблюдаемые значения xi;
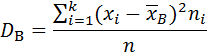
- выборочная дисперсия, характеризует «разброс» значений xi признака Х от среднего выборочного значения ![]()
![]() .
.
![]()
![]() .
.
- выборочное среднее квадратическое отклонение, это та же характеристика «разброса», но в единицах признака Х.
Все дальнейшие вычисления поместите в расчетную табл. 2.
В первом столбце таблицы выписаны порядковые номера частичных интервалов. Во второй столбец занесены значения признака xi – это середины соответствующих частичных интервалов.
В третий столбец внесены абсолютные частоты ni для каждого частичного интервала из табл. 1. Найдите сумму всех абсолютных частот n = ? ni (в примере n = 49).
Таблица 2
№ |
|
|
|
|
1 | 1,4 | 2 | 2,8 | 19,47 |
2 | 2,2 | 9 | 19,8 | 48,47 |
3 | 3,0 | 6 | 18,0 | 13,86 |
4 | 3,8 | 5 | 19,0 | 2,59 |
5 | 4,6 | 8 | 36,8 | 0,05 |
6 | 5,4 | 6 | 32,4 | 4,65 |
7 | 6,2 | 4 | 24,8 | 11,29 |
8 | 7,0 | 5 | 35,0 | 30,75 |
9 | 7,8 | 2 | 15,6 | 21,52 |
10 | 8,6 | 2 | 17,2 | 33,29 |
? | - | 49 | 221,4 | 185,91 |
В столбец, озаглавленный ![]()
![]() , введите соответствующие величины и в ячейку итоговой строки поместите сумму всех чисел этого столбца. В примере эта сумма равна 221,4. Вычислите среднее выборочное значение, которое в нашем примере
, введите соответствующие величины и в ячейку итоговой строки поместите сумму всех чисел этого столбца. В примере эта сумма равна 221,4. Вычислите среднее выборочное значение, которое в нашем примере ![]()
![]() На основе результатов, помещенных в последнем столбце (
На основе результатов, помещенных в последнем столбце (![]()
![]() , получите величину выборочной дисперсии. Для рассматриваемого примера
, получите величину выборочной дисперсии. Для рассматриваемого примера ![]()
![]()
Пусть генеральная средняя ![]()
![]() неизвестна и требуется оценить ее по данным выборки. В качестве оценки генеральной средней принимают выборочную среднюю:
неизвестна и требуется оценить ее по данным выборки. В качестве оценки генеральной средней принимают выборочную среднюю:
![]()
Можно показать, что оценка ![]()
![]() является несмещенной и состоятельной оценкой генеральной средней
является несмещенной и состоятельной оценкой генеральной средней ![]()
![]()
Выборочная дисперсия ![]()
![]() является смещенной оценкой генеральной дисперсии
является смещенной оценкой генеральной дисперсии ![]()
![]() , поэтому выборочную дисперсию «исправляют», умножая ее на множитель
, поэтому выборочную дисперсию «исправляют», умножая ее на множитель ![]()
![]() . В результате получают так называемую исправленную выборочную дисперсию
. В результате получают так называемую исправленную выборочную дисперсию
![]()
которая является несмещенной, состоятельной и эффективной оценкой генеральной дисперсии ![]()
![]()
![]()
![]()
Для нашего примера точечные оценки генеральных характеристик:
![]()
Полученные результаты сохраните на листе 1. В итоге на первом листе Вы должны сохранить:
- массив исходных данных; итоги вычислений:
![]()
![]()
- расчетные табл. 1 и 2; гистограмму и полигон относительных частот; график комуляты распределения основные характеристики выборочного распределения:
![]()
- точечные оценки генеральных характеристик:
![]()
