
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2. Х-МР/48 (Texas Instruments) – мультиканальная система (двух - или четырёхпроцессорная конфигурация). Быстродействие растёт над 64-разрядными словами с плавающей запятой. Объём ОЗУ каждого процессора до 8 ГБ. Используется для расчётов аэрокосмических объектов и прогноза погоды.
Системы из векторных процессоров (ВП)
Векторный процессор (матричный) говорит о проблемной ориентации процессоров на классе решаемых задач.
ВП подключается к вычислительному устройству как ВУ, снабжённого каналом прямого доступа к памяти. Поэтому их иногда называют периферийными. Эти процессоры имеют свою память для хранения массива данных и результатов вычисления.
 ВП выполняет свои функции параллельно ВМ и независимо от её работы.
ВП выполняет свои функции параллельно ВМ и независимо от её работы.
 |
а)
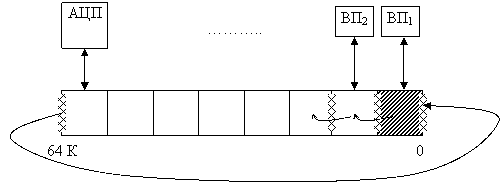 б) Двухпортовое ОЗУ – т. е. позволяет читать и писать в обоих направлениях.
б) Двухпортовое ОЗУ – т. е. позволяет читать и писать в обоих направлениях.
Mars-432. Обеспечивает 108 операций в секунду над 32-разрядными словами с плавающей запятой.
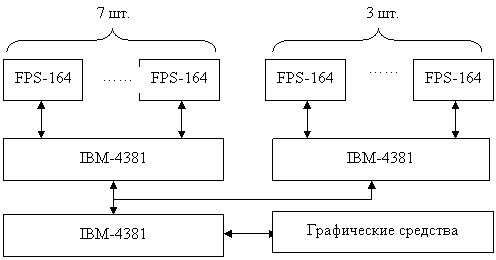 FPS-164. 15*106 оп/сек над 64-разрядными словами с плавающей запятой.
FPS-164. 15*106 оп/сек над 64-разрядными словами с плавающей запятой.
В этой системе 7 векторных процессоров (ВП) используются для вычислительной работы уже отложенного ПО. А 3 ВП используются для отработки программы. Каждый ВП снабжён 16 МВ ОЗУ. Каналы связи обеспечивают пропускную способность до 16 МВ/сек.
Анализ конвейерных вычислительных систем (КВС)
КВС имеют уровень быстродействия до 1012 оп/сек. Это быстродействие достигается за счёт конвейеризации на всех уровнях обработки информации как на микроуровне выполнение микрокоманд, на макроуровне выполнение команд и на более высоком уровне – предсказатели при ветвлении программного обеспечения.
Для КВС характерна идентичность модулей, из которых состоит вся система.
Возможность КВС ограничены по следующим причинам:
1. Число КП в системе определяется алгоритмическими возможностями решения задач, надёжностью управляющего устройства и технико-экономическими показателями.
2. Число модулей в одном КП не может быть произвольно большим, что следует из алгоритма решения сложных задач и неабсолютной надёжности электрических компонентов.
3. Число секций в любом модуле ограничивается алгоритмами выполнения арифметических операций.
4. Трудности распараллеливания задач и потенциально низкая надёжность электрических компонентов.
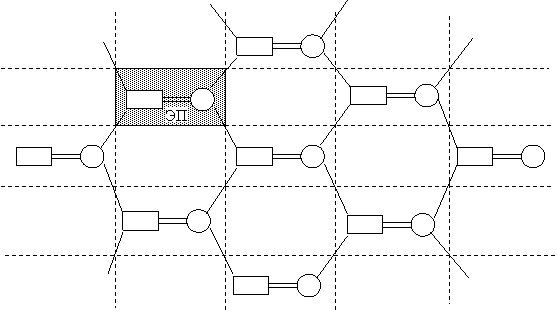
Матричные ВС
Каноническая структура (МП) матричного процессора
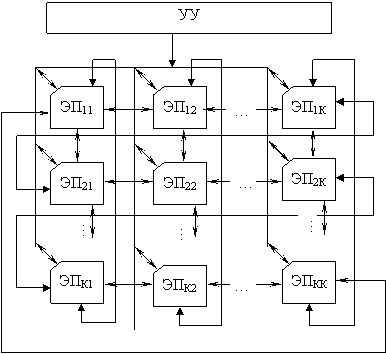 МП представляет собой композицию УУ и матрицы связанных элементарных процессоров.
МП представляет собой композицию УУ и матрицы связанных элементарных процессоров.
УУ предназначено для формирования единого потока команд на все процессоры матрицы. Все ЭП (элементарные процессоры) идентичны и включают в себя АЛУ и память (минимальная конфигурация). Сеть межпроцессорных связей регулярна и формируется таким образом, чтобы каждый элементарный процессор имел непосредственную связь не менее чем с четырьмя элементарными процессорами. Это позволяет осуществить обмен между памятью ЭП (в некоторых случаях используется режим ПДП).
 Состояние каждого ЭП и обмен информацией между ними программируется УУ перед запуском очередной программы.
Состояние каждого ЭП и обмен информацией между ними программируется УУ перед запуском очередной программы.
Система ДАР (Англия). Предназначена для выполнения функций ОС, включая программу данных. Преобразование команды данных в форму, пригодную для МП; управление работой МП; для в/в информации в МП. Каждый МП представляет собой одноразрядное АЛУ и 1 Кбит памяти. Матрица процессоров представляет собой 16´16=256 МП. Быстродействие 25*106 оп/сек.
Connection (США). Быстродействие 109 оп/сек. Ёмкость памяти 32 МБ. Число процессоров 65536. Скорость обмена между процессорами 32 МБ/сек.
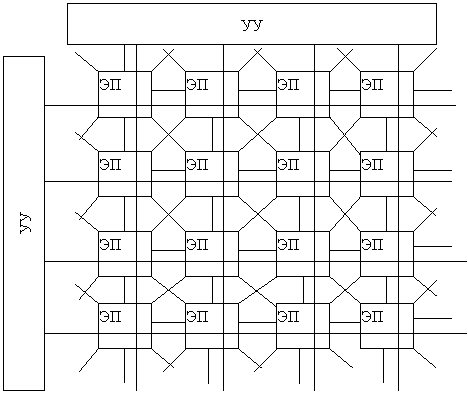 Eddy. Структура:
Eddy. Структура:
Каждый процессор этой системы имеет связь с 8 ближними и связан с двумя УУ по широковещательным шинам. Связь между соседними процессорами в одном варианте этой системы осуществляется по последовательным каналом типа RS-232.
Широковещательная шина представляет собой 32-разрядную магистраль. В качестве ЭП используется процессор Z-8000-1. В качестве УУ используется тот же самый процессор. В настоящее время используются матрицы из 128 процессоров и 256.
В матрице 128 осуществляется связь между соседними процессорами через двухпортовое ОЗУ, а 256 – режим ПДП (пересекающиеся области памяти).
Разработчики ориентируются обеспечить передачу информации между ЭП, минуя УУ.
ВС для задачи вычисления функции
 |
 |
К достоинствам относятся дешевизна и надёжность.
В качестве процессора используется сдвоенный процессор 286/287. В состав ЭП входит 16 К 16-разрядных слов. Быстродействие оценивается 4*109 оп/сек над 16-разрядными словами с плавающей запятой.
Анализ МВС
Матричный процессор (МП) не имеет ограничений в наращивании эффективности. В МП число параллельно выполненных операций достигает 106, это позволяет достичь быстродействия оп/сек. благодаря конвейерности внутри ЭП.
К МВС применим принцип программируемости структуры, т. е. адаптация структуры ВС к решаемой задаче. Это достигается с помощью формирования (настройки) связей между ЭП.
Основным недостатком этих систем является единственное УУ, от которого зависит надёжность всей системы в целом. Этим самым объясняется ограниченность МВС. От пропускной способности УУ зависит производительность всей системы.
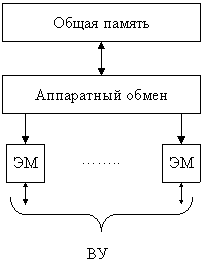
Магистральные системы (МС)
Каноническая структура МС
МС представляет собой средство обработки информации, в которой имеется множество процессоров, взаимодействующих между собой через единый ресурс. В качестве единого ресурса могут быть использованы: 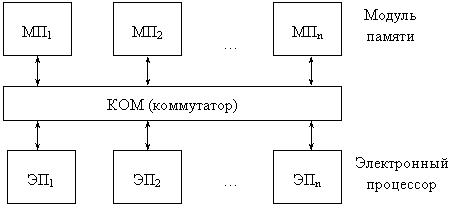 машины-посредники, внешние ОЗУ, общие шины, коммутаторы и т. п.
машины-посредники, внешние ОЗУ, общие шины, коммутаторы и т. п.
МС – это композиция, в которой имеется множество ЭП, подмножество МП и коммутатор (КОМ), который обеспечивает связь между любыми ЭП и любыми МП. Подмножество МП иногда называют общей памятью для всех элементарных процессоров. Взаимодействие между ЭП осуществляется не через КОМ, а через общую память. Все МП, как правило, идентичны.
Примеры МС:
1. C. mmp (институт Карнеги-Меллана)
Требования:
1) Достижение высокой производительности (большой полосой пропускания канала процессор-память).
2) Обеспечение и измерение показателя надёжности, в том числе и перемежающихся отказов.
3) Максимальное использование серийно выпускаемой аппаратуры:
- позволяет свести работу системы к работам по созданию лишь системных компонентов;
- использование наработанного программного обеспечения (особенно программ тестируемых структур);
- достижение более высокой надёжности.
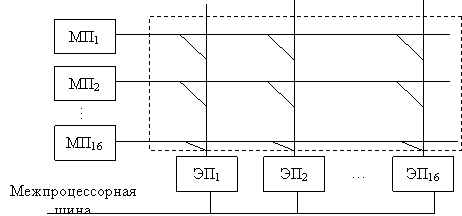 |
Эта структура используется для распознавания образа (звук, видео). Система состоит из 16 ЭП фирмы DAR, процессор PDP 11/40.
МП – объёмом 64 К, микропроцессорная шина обеспечивает связь с внешними устройствами, в числе которых накопители большой ёмкости (винт) и ОЗУ большой ёмкости.
Принципиальным недостатком является наличие единого КОМ, выход из строя которого приводит к полной неработоспособности системы.
C. vmpТребования:
1) Сохранение работоспособности в условиях всех видов отказов (вода, пожар).
2) Независимость программного обеспечения с точки зрения пользователя от механизма отказоустойчивости системы.
3) Способность системы работать в реальном масштабе времени (аппаратура ВС должна позволять быстро обнаруживать и устранять отказы).
4) Модульные построения ВС с целью сокращения времени простоя (система должна позволять функционировать части системы при отключенной другой для проведения профилактических работ).
5) Применение серийных компонентов при построении ВС (для сокращения объёма вновь разрабатываемой аппаратуры; использование компонентов, выпускаемых серийно; преемственность…).
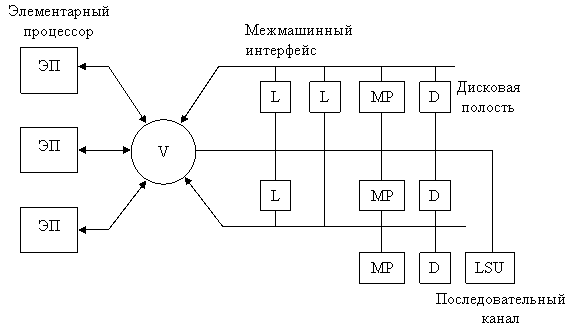 Структура:
Структура:
|
В этой структуре реализован принцип голосования (мажорирования) 2 из 3 в этом случае.
Конфигурации:
Все три процессора работают по идентичным программам и с одинаковым массивом данных. При этом V обеспечивает приём трёх слов информации, их сравнения и выдачу наиболее достоверного кода на соответствующие шины. Голосование обеспечивается как при передачи от процессора к памяти, так и в обратном направлении. Этот режим обеспечивает максимальную отказоустойчивость. Максимальная производительность. Все три процессора работают со своими задачами, которые могут отличаться друг от друга. Схема V тогда представляет собой простой коммутатор, обеспечивающий связь элементарных процессоров с общей памятью. В этом режиме каждый ЭП может быть связан с любым МП. При структуре максимальной производительности и использование межмашинного интерфейса L эту структуру можно представить в виде конвейерного процессора.Анализ МС
Достоинства:
- высокая производительность (достигается благодаря параллелизму решения задач);
- программируемость структуры и адаптируемость её под структуры и параметры реализуемых алгоритмов (достигается средствами коммутации). Эти средства позволяют задать маршруты движения информации при взаимодействии основных элементов МС.
Недостатки:
- наличие единого ресурса резко снимает надёжность вычислительной системы;
- требуется при создании ресурса большое количество выводов (контактов).
ВС с программируемой структурой
 Эти системы базируются на МС (мультипроцессоры) с распределённой памятью.
Эти системы базируются на МС (мультипроцессоры) с распределённой памятью.
В этом варианте в качестве единого ресурса выступает коммутатор, который обеспечивает в совокупности с локальным коммутатором практически всё многообразие связей между элементами ВС. Эта система позволяет практически неограниченное наращивание производительности.
Эта система может быть распределённой, т. е. элементы вычислительной системы могут находиться в непосредственной близости от исполнительных устройств или датчиков. Объединение их в единую систему возможно через их единый ресурс.
Пример: Cm* (Карнеги-Меллана).
При построении вычислительной системы использованы процессоры LSI-11 (ADP-11)
 a)
a)
 b)
b)
A. 1)
 |
 B. 1)
B. 1)
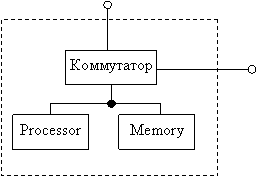
Эти структуры позволяют иерархическое развитие ВС. Процессор Р и модуль памяти М через интеллектуальный коммутатор К связываются через межпроцессорные сигналы с любым процессорным элементом ВС. Этот коммутатор обеспечивает полный протокол обмена информацией между процессорными элементами: это может быть режим ПДП или процессор ввода-вывода.
Этот модуль А) может служить как отдельная вычислительная машина или как элемент ВС.
Рис. А. 1) – каноническая структура Cm*
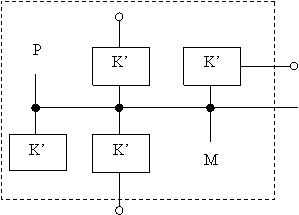
Вариант В) включает в свой состав процессор Р и модуль памяти М и 4 коммутатора К’. Он обеспечивает формирование двухмерной вычислительной структуры.
Рис. В. 1) – двумерная вычислительная структура.
Характеристики:
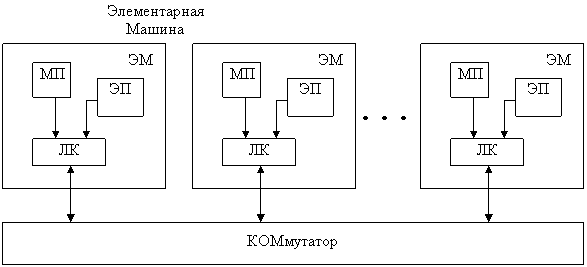
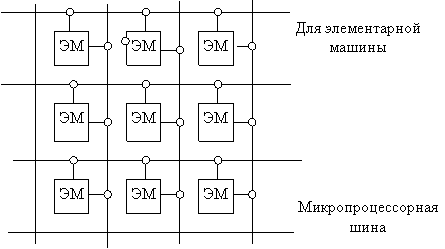
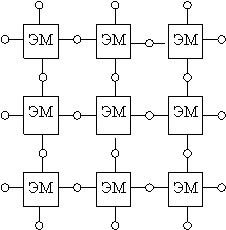
1. Наращиваемость. В системе нет принципиальных ограничений на число ЭМ и число связей между ними. Состав системы и структуру сетей связи можно формировать в соответствии с конкретными требованиями.
2. Общедоступность и распределённость памяти. Память в этой системе состоит из общей и локальной памяти. Общая память подключена к микропроцессорной шине, а локальная – входит в состав ЭМ.
Пример 2: Flex /32
Эта структура сформирована на применении ВМ на базе Моторола. ЭМ=20.180. Производит 105-108 над 32-разрядными словами.
Ограничение быстродействия в этой системы обусловлено динамическими характеристиками аппаратуры обмена.
Все вычислительные машины 32-разрядного интерфейса представляют собой шину VME.
1. Эта система позволяет задание конфигурации как многомашинной, так и многопроцессорной.
2. Использование ЭМ для выполнения независимых программ.
3. Формирование нескольких подсистем с разделёнными ресурсами для реализации нескольких параллельных программ.
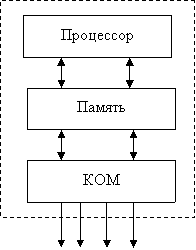
Перспективные архитектурные решения в области мультипроцессорных (МУП) вычислительных систем (ВС)
1. TRAC (Вашингтон)
Обладает возможностью реконфигурации. МУП представляет собой систему из трёх уровней:
- ЭП;
- КОМмутаторы;
- Память.
Связи между процессорами – динамические, обеспечивающие в случае необходимости реконфигурацию ВС для выполнения микрокоманды, макрокоманды и оператора высокого уровня в соответствии с требованиями решаемых задач.
2. Blue Chip.
 |
Каждый ЭП обладает своей памятью. Планируется, что эта система будет реализована на одной пластине.
Транспьютерные ВС
Коммутатор обеспечивает связь с четырьмя соседними транспьютерами (Т). Т Т-424 – это 32-разрядная машина, 8 Мб памяти, 107 операций над 32-разрядными словами.
На пластине – 256 Т (16´16), соединённых между собой.
RISC – процессоры
Основные характеристики:
1. Ограниченный набор или сокращённый набор команд.
2. Использование аппаратных средств или компиляторов для достижения максимальной нагрузки внутренних регистров для того, чтобы свести к минимуму число обращений к основной памяти.
3. Структура, как правило, конвейерного типа.
В настоящее время создаётся сильное различие между операторами языка высокого уровня и системой микрокоманд микропроцессора (МП). Одна из основных проблем – создание эффективных компиляторов, которые обеспечивали бы оптимальный вариант перевода из языка высокого уровня в машинные коды. На сегодняшний день наиболее известные компиляторы обеспечивают увеличение длины программы (относительно программы, которую бы писал программист на Ассемблере) от 1,2 раза до 2-х. При этом имеются недостатки:
- неэффективное использование команд;
- чрезмерный объём памяти;
- высокая сложность компилятора.
Поэтому имеются следующие направления:
1. Создание вычислительных машин, процессоры которых имеют систему команд близкую к языкам высокого уровня (CISC – процессор).
2. МП с ограниченным набором команд (RISC)
Это взаимодополняющие структуры.
CISC:
1. Облегчить разработку компиляторов (для чего использование сложных команд для процессора вплоть до аппаратной реализации некоторых команд).
2. Повысить эффективность выполнения команд (сложные команды реализуются на микрокомандном уровне со всеми его достоинствами).
3. Обеспечить возможность применения гораздо более сложных языков высокого уровня.
Паскаль Научная работа | Фортран Учебная программа | Паскаль Системная программа | Си Системная программа | SAL Системная программа | ||
Assign | 74 | 65 | 45 | 38 | 45 | Присвоение |
Loop | 4 | 3 | 5 | 3 | 4 | Ветвление |
Call | 1 | 3 | 15 | 12 | 12 | Вызов к/пр |
If | 20 | 11 | 29 | 43 | 36 | Условие |
Goto | 2 | 9 | - | 3 | - | Безусловный переход |
Другие | - | 7 | 6 | 1 | 6 |
Данные таблицы получены в процессе динамических испытаний, т. е. реальные работы программ, а не по тексту программы. Эта таблица показывает, что 60% и более занимает оператор присвоения, второе место – оператор условного перехода.
В процессе выполнения команд наиболее часто встречается оператор обработки скалярного перемножения (70% от общего количества).
Из эквивалентных таблиц получено, что каждая команда в среднем считывает из памяти 0,5 операнда, а из РОН – 1,4 операнда, т. е. необходимо создавать архитектуру, в которой имеется очень быстрый доступ к РОН.
Вызов процедур
Средняя длина процедуры определяется количеством вложений. Вложение (В) – это единица, эквивалентная одной машинной команде.
Статистика показывает, что до 3-х вложений – это 70 % всех операторов, до 5 вложений – 30%, до 7 – 20%.
Выводы:
1. RISC архитектура. В процессе её проектирования требует большого количества регистров и разработки алгоритмов оптимизации распределения этих регистров между операторами для хранения операндов.
2. Ориентация на конвейер команд (присутствие большого числа команд условного перехода и ветвление вызывают то, что конвейер будет работать неэффективно, т. е. существенная часть команд не будет исполняться).
Оптимальное использование регистров RG
Т. к. самым распространённым является оператор присвоения, то наиболее целесообразно используемые операнды хранить в непосредственной близости к процессорному элементу. В качестве ЗУ для этих операндов целесообразно использовать РОН, которые обладают максимальным быстродействием, т. к. по сравнению с кэш-памятью не требуется полноразрядная адресация, дешифрация полного адреса и использование УУ памятью, которое необходимо для определения в какую область памяти необходимо обращаться (кэш-память, основная память, РОН и долговременная память), те. При использовании РОН получается максимальное быстродействие. Для максимального использования РОН требуется рационально распределить регистры между операндами. Эта задача в RISC процессоре решается либо программно, либо аппаратно. Программный вариант основан на использовании компилятора, который обеспечивает программную загрузку регистра теми переменными, которые в течение определённого периода времени будут использоваться максимально чисто. Программный вариант подразумевает наличие довольно сложных программ с прогнозом – какие операторы будут использованы наиболее часто или “самодублирующихся программ”, которые производят анализ в процессе выполнения программы реального состояния РОН и выбирают наиболее часто встречающуюся комбинацию операндов в РОН, чтобы при повторном запуске использовать наиболее рациональное распределение операндов по регистрам.
Аппаратный – простое наращивание РОН для того, чтобы поместить них наибольшее количество операндов.
Требования, предъявляемые к операндам в центральном процессоре:
1. Выборка команд: ЦП (центральный процессор) должен считать команду из памяти и разместить её в действующем регистре.
2. Интерпретация команд – разложение её на последовательность микрокоманд.
3. Выборка данных – считывание данных и размещение их в соответствующих регистрах.
4. Внешние команды (выполнение микропрограммы).
5. Размещение результата.
Для выполнения вышеуказанных операций используются программно доступные RG и RG флагов (RG управления и состояния).
RG состояния – используют УУ для организации работы ЦП, а также
управление программами или ОС (операционной системой).
РОН подразделяются на:
- Универсальные (для хранения адреса и данных и могут быть использованы для вычисления в процессе выполнения кода операции);
- адреса;
- RG данных;
- RG флагов.
При использовании RG в коде операции должно быть обязательно указано какому типу RG относится конкретное обращение.
Выбор необходимого количества а) RG, а также RG б) и в) связано с архитектурой вычислительной машины (ВМ) и ориентацией ВМ на конкретном классе задач, на которые она предназначена. Длина RG на сегодняшний день от 8 (RG составляющих) до 32 разрядов. Увеличение RG обеспечивает снижение количества обращения к памяти. Длина RG определена адресным словом (не всегда).
Аппаратный подход к построению РОН
Большинство операций требуют обращения к операнду, который представляет собой скалярную переменную. Хранение этих операндов в РОН позволяет значительно повысить динамические характеристики вычислительной системы.
При каждом вызове процедуры необходимо обеспечить РОН соответствующими данными. При этом необходимо для следующей процедуры свои данные плюс результаты процедуры, а при возврате необходимо восстановить данные в регистрах.
Решение этой задачи основано на:
1. Глубина инициализации процедуры колеблется в сравнительно незначительных пределах (от 3 до 8).
2. Типичные процедуры используются в течение своего выполнения как скалярные, так и глобальные переменные.
Для решения этой задачи в RISC процессоре (RISC1 и RISC2) используются несколько регистров, распределёнными между соседними процессорами. Вызов одной процедуры автоматически переключает центральный процессор на другое регистровое окно, вместо того, чтобы сохранять информацию в памяти. Окна для соседних процессоров пересекаются, что позволяет передавать данные от одной процедуры к другой.
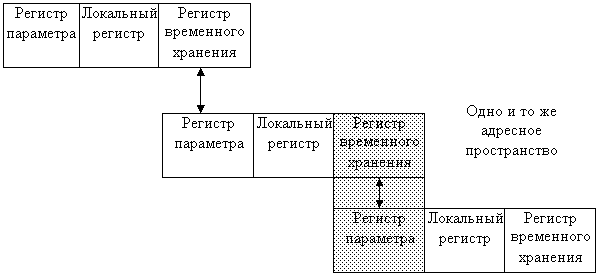
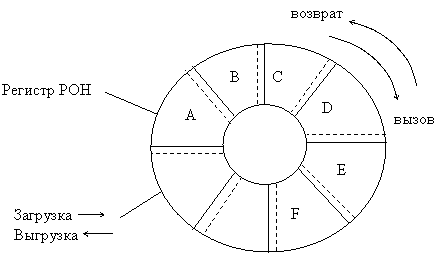
В любой момент времени доступно лишь окно регистров, для передачи из одного окна в другое имеются зоны, которые доступны процессору при выполнении соседних процедур.
Достоинства: минимальное количество циклов обращения к памяти, т. к. результаты операций как предыдущей, так и последующей хранятся в РОН.
Недостатки: дополнительные аппаратные затраты.
Следует отметить, что в данном случае в процессоре обязательно отводится RG, который указывает адрес заполненного окна и указывает адрес окна, в которое записывается в данный момент информация.
По статистике только 1% обращений требует сохранения информации в стековой области памяти.
Эта структура особенно эффективна в тех случаях, когда используются в основном скалярные переменные и резко снижаются в том случае, если используются глобальные переменные (т. е. переменные, используемые более чем в двух процедурах).
Для решения этого вопроса используется 2 варианта:
1. Переменные, которые являются глобальными, распределяются компилятором между ячейками памяти и процессоров в каждый … Это направление требует меньших аппаратных затрат, но считается неэффективным, т. к. требует дополнительного обращения к памяти.
2. В состав процессора вводятся дополнительные регистры для хранения глобальных переменных. Эти регистры доступны для всех процедур.
Применение регистровых окон позволяет сократить время выполнения программ, т. к. все необходимые данные хранятся в регистровом файле.
КЭШ-память в отличие от данных окон требует полноразмерную адресацию, т. е. эквивалентную адресацию к общей памяти.
Программный подход распределения регистрового файла
Суть задачи состоит в том, чтобы для каждого участка программы решить какие переменные должны быть распределены между RG, при этом количество RG определяется структурой микропроцессора, а количество переменных – оператором языка высокого уровня. Эта программа основывается на топологическом методе “раскрашивания” графа.
Архитектура систем с сокращённым набором команд (СНК)
Стояло 2 задачи при построении этих систем:
1. Необходимость упрощения компиляторов.
2. Повышение быстродействия.
При разработке компиляторов необходимо сформировать последовательность машинных команд, соответствующих каждому оператору языка высокого уровня (ЯВУ) в тех случаях, когда оказывается, что оператор ЯВУ похож или полностью идентичен команде, то данная машина относится к CISC процессорам, а задача создания компиляторов упрощается.
При создании вычислительной машины с сокращённым набором команд предполагается, что длина программы будет уменьшаться за счёт элементарных команд RISC процессора.
Характерные особенности архитектуры с СНК.
1. Машинная команда выполняется за один машинный цикл (МЦ). МЦ – это интервал, затрачиваемый на выборку двух операндов, выполнение операции в АЛУ и запоминание результата оператором.
2. В машинах с СНК большинство операций это регистр-регистр, а для доступа к памяти реализованы очень простые команды загрузки и запоминания.
3. В машинах с СНК используются только простые способы адресации (как правило регистровое, регистр-адрес со смещением и менее 1% - косвенные).
4. Использование только простых форматов команд. Команда имеет фиксированную длину. Расположение элементов команд – фиксировано.
Достоинства:
- фиксированные поля позволяют упростить дешифратор кода операции и обращение к регистровому файлу;
- использование упрощённого формата команды позволяет упростить (в некоторых случаях свети к минимуму) устройство управления. УУ в СНК процессорах занимает не более 7-8% от площади кристалла, в то время как в CISC процессоре УУ занимает 70-80% площади кристалла.
Всё вышеперечисленное позволяет:
1) Повысить быстродействие по следующим причинам:
1.1) Большинство команд, которые формируются компилятором очень просты (в RISC процессоре, как правило, отсутствует микропрограммное управления микропрограмм).
1.2) Используется конвейерный режим выполнения команд (т. к. команды просты, содержат одинаковое количество тактов).
1.3) Эти компьютеры имеют минимальное время реакции на прерывание, т. к. все команды очень короткие.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
