

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
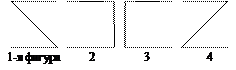
Рис. 11. Фигуры силлогизма
В каждом силлогизме должно быть 3 термина: меньший (субъект – S), больший (предикат – P) и средний (термин, присутствующий в посылках, но отсутствующий в заключении – M). В зависимости от положения среднего термина различают 4 фигуры силлогизма.
Модусами силлогизма называются разновидности фигур, отличающиеся характером посылок и заключения. Всего возможно 4 ´ 65 = 256 различных сочетаний посылок и заключений (4 фигуры, по 64 модуса в каждой фигуре). Силлогизмы как и все дедуктивные умозаключения делятся на правильные и неправильные. Из всех возможных модусов силлогизма только 24 модуса правильные, по 6 в каждой фигуре. Из этих 24-х пять являются ослабленными – заключениями в них являются частноутвердительные или частноотрицательные высказывания, хотя в других модусах эти же посылки дают общеупотребительные или общеотрицательные заключения, если отбросить ослабленные модусы остается 19 правильных модусов силлогизма.
1.9. Алгоритмические модели
Существует несколько формальных моделей алгоритмов:
1) машина Тьюринга;
2) модель рекурсивных функций;
3) канонические системы Поста;
4) нормальные алгоритмы Маркова;
5) язык блок схем.
1.9.1. Машина Тьюринга
Машина Тьюринга (МТ) состоит из:
1. Управляющего устройства, которое может находиться в одном из состояний, образующих конечное множество – внутренний алфавит состояний Q{q1, … qn}.
2. Ленты, разбитой на ячейки, в каждой из которых может быть записан один из символов внешнего алфавита данных A{a1, … an}. Лента может быть сколь угодно длинной.
3. Считывающей и записывающей головки, которая может записать символ или стереть, после чего может переместиться вправо – R, влево – L или остаться на месте – E.
4. Процесс реализации любого алгоритма на МТ разбивается на элементарные действия qiaj ® qkald, называемые командами. Такая команда определяет элементарное действие, совершаемое головкой в активной, обозреваемой ячейке. Команда означает, что если текущее состояние машины qi и символ в ячейке aj, то необходимо произвести перевод машины в состояние qk, изменить данные aj на al и сдвинуться влево при d = L, вправо при d = R, или остаться на месте при d = E.
Тем самым система команд – элементарных шагов, позволяет машине производить процесс реализации алгоритма, приводя исходные данные в результат.
Система команд однозначно определяет смысл выполняемых над данными ленты действий. В процессе изучения модели МТ потребуется записывать некоторые системы команд. Существует несколько способов их записи.
Можно просто перечислить их построчно, можно записать команды в виде матрицы М, при этом запись Mij = qkald, обозначает команду: qiai ® qkald. Тогда следующий шаг МТ, попавшей в состояние qiai, определяется содержимым элемента матрицы Mij.
Другой способ – диаграмма переходов, способствует пониманию сути конкретного алгоритма. Согласно методу, система команд представляется в виде графа, узлами которого являются состояния, а ребрами соответствующие команде изменения данных и положения головки (рис. 12).
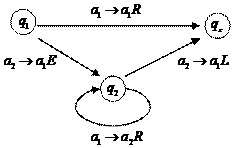
Рис. 12. Диаграмма переходов
Из рис. 12 видно, что состояния qi – это по сути стадии решения задачи. А команды – это варианты развития событий при тех или иных данных.
1.9.2. Модель рекурсивных функций (РФ)
Модель РФ исходит из существования элементарных вычислимых функций, так называемых базовых примитивно-рекурсивных функций (ПРФ). Эти функции – аксиомы формальной теории РФ. Из них формальными правилами, так называемыми примитивными рекурсивными операторами (ПРО) получают теоремы – новые ПРФ, которые также вычислимы и имеют право называться вычислимыми функциями – алгоритмами.
Базовыми ПРФ являются следующие элементарные функции:
1) константа 0(x); x – исходные данные, 0 – данные результата;
2) инкремент x`(x); x`(x) = x + 1;
3) проецирующая функция Iin(x1, … xi, … xn) = xi, результатом является значение i-го аргумента из n аргументов.
Таким образом, модель РФ как бы содержит три МТ, три системы команд.
Элементарные правила вывода модели РФ – это два оператора:
1. Оператор подстановки Snm(h,g1, … gm), это значит, что в функцию h(y1, … ym) вместо каждого аргумента yi подставляется функция g(x1, … xn). То есть Snm(h, g1, … gm) = f(x1, … xn). Это правило соответствует композиции МТ.
2. Оператор примитивной рекурсии Rn(f, g, h). Действие оператора можно описать системой двух уравнений:
f(x1, … xn, y + 1) = h(x1, … xn, y, f(x1, … xn, y));
f(x1, … xn, 0) = g(x1, … xn).
В первом уравнении происходит так называемый шаг элементарной рекурсии. Значение функции f в точке y + 1, вычисляется через значение в y. Второе уравнение описывает элементарный случай y = 0 и соответствует последнему шагу рекурсии.
1.9.3. Особенности языка Рефал
Рассмотрим кратко особенности модели нормальных алгоритмов Маркова на примере языка Рефал.
Вся информация в этом языке представляется в виде правил конкретизации. Каждое правило записывается в виде предложения, они отделяются друг от друга знаком §.
Каждое правило конкретизации определяет раскрытие смысла некоторого понятия через более элементарные. Операцию конкретизации можно также определить как переход от имени к значению.
Выполнение конкретизации объявляется единственной операцией в языке Рефал и есть указание для замены одного объекта на другой. Машина просматривает предложения в том порядке, в котором они расположены в Рефал-программе, и применяет первое из них, которое окажется подходящим.
Поле зрения может содержать сколько угодно конкретизационных скобок, причем они могут быть как угодно вложены друг в друга. В этом случае Рефал-машина начинает процесс конкретизации с первого из знаков k, в области действия которого (то есть в последовательности знаков до парной скобки ^) нет ни одного знака k. Выражение, находящееся в области этого знака k, последовательно сравнивается с левыми частями предложений Рефал-программы. Найдя подходящее предложение, машина выполняет в поле зрения необходимую замену и переходит к следующему шагу конкретизации.
1.9.4. Пример Рефал-программы
Пусть Рефал-программа имеет вид:
kX^à137
kX^à274
kY^à2
k137+2^à139,
а поле зрения содержит выражение:
kkX^ + kY^^.
На первом шаге замене подлежит подвыражение kX^ – получим в поле зрения kl37 + kY^^. Теперь в первую очередь конкретизируется kY^, получим в результате применения третьего предложения k137 + 2^ и на последнем шаге получим 139, не содержащее символов k. Разумеется для реального сложения используются соответствующие встроенные функции, а этот пример лишь простейшая иллюстрация принципов работы машины.
2. ЭЛЕМЕНТЫ ТЕОРИИ РАСПОЗНАВАНИЯ ОБРАЗОВ
В последнее время внимание инженеров привлекает задача построения машин или программного обеспечения для распознавания образов в различных прикладных областях. Уже первые результаты оказались очень обнадеживающими. Были сделаны успешные попытки разработки устройств и создания программного обеспечения для чтения типографских и машинописных букв, идентификации банковских чеков, платежных поручений, классификации электрокардиограмм, распознавания слов в речи и сортировки фотографий. Можно назвать еще ряд других применений распознавания образов: распознавание рукописных букв или слов, медицинский диагноз, диагностика неисправностей в системах, классификация сейсмических волн, обнаружение цели, прогноз погоды, криминалистика и т. д.
2.1. Основные понятия теории распознавания образов
2.1.1. Понятия класса, объекта, признака
Для построения теории распознавания необходимо сформировать определенную модель процесса распознавания, применительно к которой будут развиваться все теоретические положения.
Существует три основных понятия теории распознавания:
− класс или образ;
− объект или реализация;
− признак класса.
Класс (или образ) – совокупность входных объектов или явлений, обладающих некоторыми общими свойствами.
Обычно для каждого класса указывается некоторое множество его представителей (эталонов).
Классы могут определяться заранее (например, множество букв «А») или выделяться в процессе анализа входных объектов. Для изображения, воспроизводящего некую сцену, классы могут задаваться понятиями типа «круглые объекты», «многоэтажный дом», «машина» и т. п. Требования, определяющие классификацию, могут быть различными, так как в различных ситуациях возникает необходимость в различных типах классификаций. Например, при распознавании английских букв образуется 26 классов образов. Однако чтобы отличить при распознавании английские буквы от китайских иероглифов, нужны лишь два класса образов.
Часто при решении задач распознавания изображений два различных входных объекта следует отнести к общему классу, даже если они отличаются положением, ориентацией, размерами и т. д., поскольку каждый из них может быть получен из другого с помощью простых операций над элементами изображения (пикселями). В этом случае говорят, что классы инвариантны к преобразованиям определенных типов (параллельный перенос, изменение масштаба, поворот относительно осей, отражение относительно плоскостей).
Однако не всегда удается провести такую классификацию. Например, знаки запятой и апострофа отличаются лишь положением, а буквы bud – только ориентацией.
Итак, как правило, имеется набор классов, который называется алфавитом классов. Алфавит записывается как перечень входящих в него классов:
A = {A1, A2, ..., Ai, ..., A },
где Ai – отдельный i-й класс;
m – количество классов.
Если m = 1, то никакого распознавания нет. Очень часто рассматривается задача отнесения объекта к одному из двух классов (m = 2). Такая задача называется задачей дихотомии. Случай m = ¥ является практически нереальным.
При постановке любой задачи распознавания предполагается, что число классов не меньше двух.
Объектами являются некоторые предметы и явления, которые в совокупности своей образуют класс. Объект записывается в виде:
B = {b1, b2, ..., bj, ..., bT},
где bj – отдельная реализация объекта;
T – количество реализаций данного объекта.
В большинстве задач T конечно и T > m. Если же значения признака меняются непрерывно, то T будет бесконечным числом.
Признак класса – это количественное значение, характеризующее объект. Для простоты считают, что все классы характеризуются одним и тем же количеством признаков N. Вектор признаков – это набор N существенных характеристик (признаков) входного объекта, используемых для описания этого объекта. Совокупность всевозможных векторов признаков образует N-мерное пространство признаков WX.
В качестве признаков изображения могут быть выбраны независимые характеристики изображения, вычисляемые по его яркостным свойствам, границам и формам поверхностей объектов на нем:
1) геометрические признаки определяются по геометрии объекта на изображении и не зависят от его яркости;
2) текстурные признаки – признаки, вычисляемые по степени повторяемости деталей изображения, скажем, по наличию «зерен» или линейных фрагментов, имеющих примерно одинаковые направления.
Совокупность признаков обозначается:
X = {x1, ..., xk, ..., xN}.
Практически числовые значения признаков изменяются в некоторых пределах. При дискретном рассмотрении, которое необходимо при использовании цифровых вычислительных машин, каждый признак xk может принимать одно значение из совокупности
x = {x, x, ..., x }.
Каждая конкретная реализация (объект) bj задается совокупностью значений признаков
bj = {x, ..., x, ..., x }.
2.1.2. Геометрические признаки
В теории распознавания приемлема геометрическая интерпретация объектов. В этом случае объект изображается в виде точки или вектора в N-мерном пространстве WX. Размерность пространства зависит от числа признаков, описывающих объект. Для случая N = 2 и трех градаций числовых значений признаков пространство признаков будет иметь вид, показанный на рис. 13.
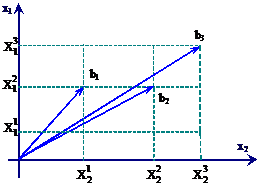
Рис. 13. Пространство признаков для N = 2
 b1 = {X
b1 = {X![]() , X
, X![]() }, b2 = {X
}, b2 = {X![]() , X
, X![]() }, b3 = {X
}, b3 = {X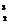 , X
, X![]() }.
}.
Количество возможных реализаций при N признаках и R градациях может быть определено по формуле: T = RN.
2.1.3. Задача распознавания
Задачу распознавания можно трактовать как разбиение N-мерного пространства признаков WX на взаимно непересекающиеся области, каждая из которых соответствует некоторому классу. Это означает, что каждый из входных объектов должен быть отнесен к одному из имеющихся классов по его вектору признаков в соответствии с выбранным решающим правилом.
Решающее правило – это правило, по которому входной объект зачисляется в тот класс, с эталонами которого он имеет наибольшее «сходство» (или согласованность) в выбранном пространстве признаков. В простейшем случае в качестве меры подобия может быть выбрано обобщенное расстояние между векторами признаков входного объекта и эталонов каждого класса.
Один из простых подходов к распознаванию образов, по-видимому, заключается в сопоставлении с эталонами. В этом случае некоторое множество образов, по одному из каждого класса образов, хранится в памяти машины. Входной (распознаваемый) образ (неизвестного класса) сравнивается с эталоном каждого класса. Классификация основывается на заранее выбранном критерии соответствия или критерии подобия. Другими словами, если входной образ лучше соответствует эталону i-го класса образов, чем любому другому эталону, то входной образ классифицируется как принадлежащий i-му классу образов. Такой подход использован в ряде уже осуществленных устройств для чтения печатных букв и банковских чеков. Недостаток этого подхода, то есть сопоставления с эталоном, заключается в том, что в ряде случаев трудно выбрать подходящий эталон из каждого класса образов и установить необходимый критерий соответствия. Эти трудности особенно существенны, когда образы, принадлежащие одному классу, могут значительно изменяться и искажаться. Типичным примером этого является распознавание рукописных букв.
Более совершенный подход заключается в том, что вместо сравнения входного образа с эталонами, классификация основывается на некотором множестве отобранных признаков (замеров, производимых на входных образах). Признаки предполагаются инвариантными или малочувствительными по отношению к обычно встречающимся изменениям и искажениям и обладающими небольшой избыточностью. В этом случае распознавание образов состоит из двух задач.
Первая задача заключается в определении того, какие измерения должны быть сделаны на входном образе. Обычно решение задачи о том, что измерять, является в известной степени субъективным, а также зависящим от практических обстоятельств (например, от возможности осуществления этих измерений, их стоимости и т. п.). К сожалению, в настоящее время очень мало сделано в построении общей теории выбора измеряемых признаков. Однако есть несколько исследований, посвященных выбору подмножества признаков и их упорядочению в заданном множестве измерений. Критерий отбора признаков или упорядочения основывается на важности этих признаков для характеристики образов или на влиянии данных признаков на качество распознавания (то есть на точность распознавания).
Вторая задача распознавания образов заключается в классификации (то есть в принятии решения о принадлежности входного образа тому или иному классу), которая основывается на измерениях отобранных признаков. Прибор или машину, которая получает замеры признаков входных образов, будем называть входным устройством. Прибор или машину, выполняющую функцию классификации, называют классификатором.
Упрощенная блок-схема системы распознавания образов показана на рис. 14. Таким образом, подход, заключающийся в сопоставлении с эталоном, можно рассматривать как частный случай второго подхода – подхода «измерения признаков», при котором эталоны хранятся в виде измеренных признаков и в классификаторе используется специальный критерий классификации (сопоставление) – решающее правило.
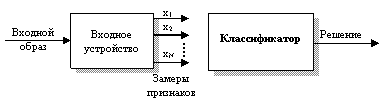

Рис. 14. Система распознавания образов
В большинстве случаев для решения задачи распознавания необходимо выполнить два этапа:
1. Обучение распознаванию на заданном количестве эталонных образов, принадлежность которых к определенному классу известна. В процессе этого распознающая система накапливает знания об объектах.
2. Процесс распознавания, когда системе предъявляется объект с неизвестной принадлежностью и она относит его к одному из классов. Степень правильности распознавания зависит от полноты процесса обучения.
Для распознавания образов часто используется распознающая машина, под которой понимается некоторая система, получающая на вход сведения об объектах и реализующая некоторый заложенный в нее алгоритм классификации. Распознающая машина может быть универсальной или специализированной ЭВМ.
2.2. Классификация методов распознавания символов
Сегодня известны три подхода к распознаванию символов –
шаблонный, структурный и последовательный. Но принципу целостности отвечают лишь первые два.
2.2.1. Шаблонные системы
Такие системы преобразуют изображение отдельного символа в растровое, сравнивают его со всеми шаблонами, имеющимися в базе, и выбирают шаблон с наименьшим количеством точек, отличных от входного изображения. Шаблонные системы довольно устойчивы к дефектам изображения и имеют высокую скорость обработки входных данных, но надежно распознают только те шрифты, шаблоны которых им «известны». И если распознаваемый шрифт, хотя бы немного отличается от эталонного, то шаблонные системы могут дать ошибки даже при обработке очень качественных изображений.
2.2.2. Структурные системы
В таких системах объект описывается как граф, узлами которого являются элементы входного объекта, а дугами – пространственные отношения между ними. Системы, реализующие подобный подход, обычно работают с векторными изображениями.
Структурными элементами являются составляющие символ линии. Так, для буквы «р» – это вертикальный отрезок и дуга.
К недостаткам структурных систем следует отнести их высокую чувствительность к дефектам изображения, нарушающим составляющие элементы. Да и векторизация может добавить дополнительные дефекты. Кроме того, для этих систем, в отличие от шаблонных и последовательных, до сих пор не созданы эффективные автоматизированные процедуры обучения.
2.2.3. Последовательные (признаковые) системы
В них усредненное изображение каждого символа представляется как объект в N-мерном пространстве признаков. Здесь выбирается алфавит признаков, значения которых вычисляются при распознавании входного изображения. Полученный N-мерный вектор сравнивается с эталонным, и изображение относится к наиболее подходящему из них.
Признаковые системы не отвечают принципу целостности. Необходимое, но не достаточное условие целостности описания класса объектов (в нашем случае это класс изображений, представляющих один символ) состоит в том, что описанию должны удовлетворять все объекты данного класса и ни один из объектов других классов. Но поскольку при вычислении признаков теряется существенная часть информации, трудно гарантировать, что к данному классу удастся отнести только «родные» объекты.
2.2.4. Другие методы распознавания
Кроме того, в теории распознавания образов для осуществления процессов обучения и распознавания могут быть использованы следующие методы:
− геометрические методы, служат в основном для интерпретации других методов;
− методы статистических решений, осуществляют оценку принадлежности образа к классу на основе вычисляемых вероятностей;
− методы дискриминантных функций или решающих функций, позволяют аппроксимировать многомерные законы вероятностей простыми функциями;
− приближенные методы, используются для минимизации ошибки распознающей машины.
2.3. Методы детерминистской классификации
2.3.1. Разделяющие функции
Концепцию классификации образов можно выразить на языке разбиения пространства признаков или отображения пространства признаков в пространство решений. В этом случае задача классификации заключается в распределении всех возможных векторов или точек в пространстве признаков по соответствующим классам образов. Это можно трактовать как разбиение пространства признаков на взаимно непересекающиеся области, каждая из которых соответствует некоторому классу образов.
Математически задача классификации может быть сформулирована с помощью разделяющей функции. Пусть А1, А2, ... , А m обозначают т возможных классов образов, подлежащих распознаванию, и пусть
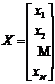 (1)
(1)
есть вектор замеров признаков, где xi представляет собой i-й замер. Тогда разделяющая функция Dj(X), относящаяся к классу образов Аj, j = 1, ... , m, такова, что если входной образ, представленный вектором признаков X, принадлежит классу Аi, то величина Di(Х) должна быть наибольшей. Пусть Х ~ Аi обозначает, что вектор признаков Х входного образа принадлежит классу Аi. Тогда можно записать, что для всех Х ~ Аi.
Di(X) > Dj(X), i, j = 1, ... , m, i ¹ j. (2)
Таким образом, в пространстве признаков граница разбиений, называемая решающей границей, между областями, относящимися соответственно к классу Аi и классу Аj, выражается следующим уравнением:
Di(X) – Dj(X) =
Если для классов удается построить уравнение вида (3), то говорят, что они разделимы. На рис. 15 множества точек двух классов отделены друг от друга ломаной, соответствующей (3), которую в дальнейшем будем называть разделяющей поверхностью или границей (гиперплоскостью). Эти множества точек, на которые разделяющая поверхность делит пространство признаков WX, и которые соответствуют одному из m классов, будем называть областями решений.
Всего таких уравнений, а значит гиперплоскостей Si,j будет
m(m – 1) (так как i ¹ j), и граница Si,j областей Ri и Rj совпадает с границей Sij областей Rj и Ri.
Таким образом, разделяющими поверхностями линейной машины являются сегменты не более чем m(m – 1) гиперплоскостей. Во многих случаях некоторые из гиперплоскостей вида (3) в действительности не используются как разделяющие поверхности. Гиперплоскости Si, j не применяются, если области Ri и Rj не соприкасаются. Такие гиперплоскости называются лишними (рис. 15).
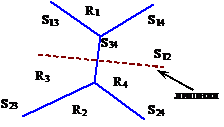
Рис. 15. Лишняя гиперплоскость
2.3.2. Схема классификатора
Общая схема классификатора, использующего критерий (2), и типичный двумерный пример приведены соответственно на рис. 16 и 17. Можно выбрать много различных форм для Di(X), удовлетворяющих условию (3). Некоторые важные разделяющие функции будут рассмотрены ниже.
Основная задача классификаторов, состоящих из некоторого количества дискриминаторов (вычислителей разделяющих функций) заключается в нахождении значений разделяющих функций D1, ... , Dm при
m > 2 или дискриминантной функции D(X) = Di(X) – Dj(X) при m = 2.
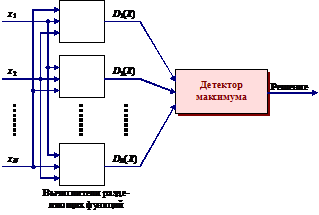
Рис. 16. Упрощенная модель классификатора
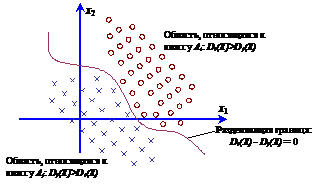
Рис. 17. Пример разбиения в двумерном пространстве признаков
2.3.3. Линейные разделяющие (дискриминантные) функции
В этом случае в качестве Di(X) берется линейная комбинация измеренных признаков x1, х2, ..., xN, то есть
![]() (4)
(4)
Решающая граница между областями Аi и Аj в пространстве признаков WX имеет вид:
![]() (5)
(5)
где
wk = wik - wjk
и
wN+1 = wi,N+1 - wj,N+1.
Уравнение (5) представляет собой уравнение гиперплоскости в пространстве признаков WX. Общая схема вычислителя линейной разделяющей функции представлена на рис. 18.
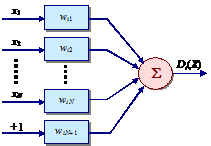
Рис. 18. Вычислитель линейной разделяющей функции
Классифицирующую машину на основе линейных дискриминантных функций можно построить на блоках взвешивания и суммирования, из которых собираются дискриминаторы. Блоком взвешивания называется блок умножения на константу.
Если m = 2, то, согласно (5), i, j = 1, 2 (i ¹ j), и в качестве классификатора, использующего линейную разделяющую функцию, можно применить пороговый логический элемент, как показано на рис. 19. Полагая D(X) = D1(X) – D2(X), из рис. 19 получим, что
![]()
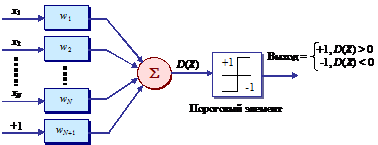
Рис. 19. Линейный классификатор двух классов
Когда число классов образов больше двух, т > 2, можно применить параллельное соединение нескольких пороговых логических элементов (рис. 20). При этом комбинации выходных сигналов М пороговых логических элементов достаточны для различия т классов при 2M > т. Иначе говоря, остаются справедливыми общие схемы (рис. 16 и 18).
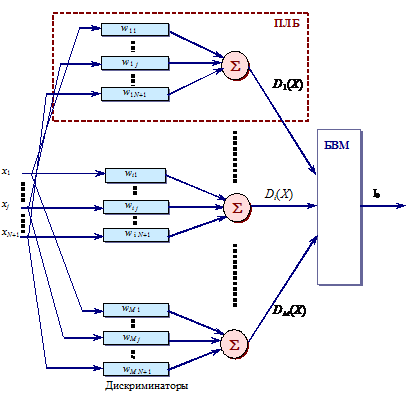
Рис. 20. Линейная распознающая машина:
ПЛБ – пороговый логический блок;
БВМ – блок выбора максимума (детектор максимума);
I0 – выход линейной распознающий машины (номер класса, к которому относится входной объект).
2.3.4. Свойства порогового логического блока:
1) пороговый логический блок осуществляет классификацию объектов при помощи разделяющей плоскости в пространстве признаков WX;
2) ориентация гиперплоскости задается величинами весов w1, ... , wN ;
3) положение гиперплоскости относительно начала координат пропорционально wN+1;
4) расстояние от произвольной точки X до плоскости пропорционально величине дискриминантной (разделяющей) функции D(X);
5) пороговые логические блоки используются как элементный блок во многих классифицирующих машинах.
2.3.5. Классификатор по минимальному расстоянию
Важный класс составляют линейные классификаторы, в которых в качестве критерия классификации используется расстояние между входным образом и множеством опорных векторов или эталонных точек в пространстве признаков. Предположим, что задано m опорных векторов R1, R2, ... , Rm, где Rj соответствует классу образов Аj. При классификации по минимальному расстоянию относительно R1, R2, ... , Rm входной сигнал Х предполагается принадлежащим Аi, т. е.
X ~ Аi, если ôХ – Riôминимально, (7)
где ôХ – Riô есть расстояние между Х и Ri.
Расстояние ôХ – Riô можно вычислить, например, следующим образом:
![]() (8)
(8)
где индекс Т определяет операцию транспонирования вектора.
Из (8) следует, что
![]() (9)
(9)
Так как XTX не зависит от i, то соответствующая разделяющая функция для классификатора по минимальному расстоянию имеет вид:
![]() (10)
(10)
Это линейная функция. Следовательно, классификатор по минимальному расстоянию также является линейным классификатором. Свойства классификатора по минимальному расстоянию, конечно, зависят от того, как выбраны опорные векторы.
Нужно также отметить, что для классификации расстояние между классами должно обладать двумя основными свойствами:
1) компактностью (это свойство выражается в том, что точки, представляющие объекты одного класса, расположены друг к другу ближе, чем к точкам, представляющим объекты других классов);
2) разделимостью (это свойство отражает тот факт, что классы ограничены и не пересекаются между собой).
2.3.6. Кусочно-линейная разделяющая функция
Пусть R1, R2, ... , Rm обозначают m множеств опорных векторов, относящихся соответственно к классам А1, А2, ..., Аm, и пусть опорные векторы в Rj обозначены через ![]() т. е.
т. е.
![]()
где uj – число опорных векторов множества Rj.
Определим расстояние между вектором входных признаков Х и Rj следующим образом:
![]() (11)
(11)
To есть расстояние между Х и Rj равно наименьшему из расстояний между Х и каждым вектором в Rj. Такой классификатор будет относить входной сигнал к классу образов, которому соответствует ближайшее множество векторов. Если расстояние ôХ - ![]() ôмежду Х и
ôмежду Х и ![]() определить согласно (8), то разделяющая функция в данном случае имеет вид
определить согласно (8), то разделяющая функция в данном случае имеет вид
![]() (12)
(12)
Пусть
![]() (13)
(13)
тогда
![]() (14)
(14)
Следует отметить, что ![]() является линейной комбинацией признаков. Поэтому классификаторы, использующие (12) или (14), часто называют кусочно-линейными классификаторами. Примером кусочно-линейного классификатора является a-перцептрон, показанный на рис. 21.
является линейной комбинацией признаков. Поэтому классификаторы, использующие (12) или (14), часто называют кусочно-линейными классификаторами. Примером кусочно-линейного классификатора является a-перцептрон, показанный на рис. 21.
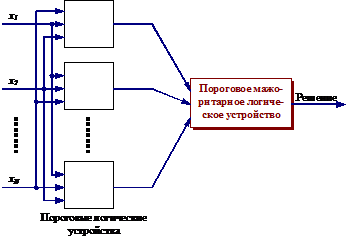
Рис. 21. a-перцептрон
2.3.7. Структура кусочно-линейной распознающей машины
Структура представлена на рис. 22. Здесь вспомогательные дискриминаторы объединены в m блоков.
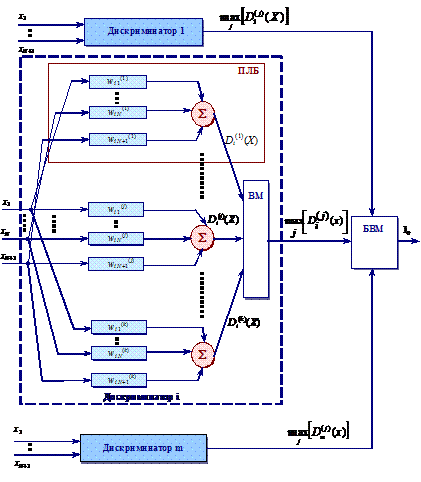
Рис. 22. Кусочно-линейная распознающая машина
Разделяющие поверхности кусочно-линейной машины состоят из частей плоскостей, так же как и в случае линейных машин. Однако в случае кусочно-линейных машин области решения могут быть невыпуклыми (рис. 23).
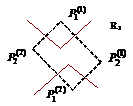
Рис. 23. Невыпуклые области решения
2.3.8. Полиномиальные разделяющие функции
Полиномиальная разделяющая функция r-й степени (иногда называют Ф-функцией) может быть представлена в следующем виде:
![]() (15)
(15)
где fi(x) является формой
![]()
Решающая граница между двумя классами также имеет форму полинома r-й степени. В частности, если r = 2, разделяющая функция называется квадратичной. В этом случае
![]() при k1, k2 = 1, …, N; n1, n2 = 0 и
при k1, k2 = 1, …, N; n1, n2 = 0 и
Разделяющая функция будет иметь следующий вид:
![]() (18)
(18)
где
![]() (19)
(19)

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
