

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
3. Составить программу, реализующую однослойную, двухслойную нейронную сеть и сеть встречного распространения для задачи распознавания. Обучить нейронные сети.
4. Программное обеспечение должно позволять просматривать эталоны (классы) изображений, а также распознаваемые изображения; записывать эталоны изображений в библиотеку на диск, записывать входной образ на диск; позволять редактировать входной образ, сохранять веса нейронов при обучении сети.
5. Испытать программное обеспечение для различных входных данных.
6. Произвести оценку качества распознавания для различных случаев, систематизировав полученные результаты в таблицы. Построить графики выявленных зависимостей, сделать выводы.
7. Результаты работы оформить в виде отчета в текстовом редакторе.
3.4.2. Рекомендации по созданию программного обеспечения
После изучения теоретического материала и выбора исходных изображений, системы признаков необходимо определить количество нейронов в слоях. Максимальное количество нейронов первого слоя может совпадать с количеством признаков, хотя теоретически избыточность допускается, но не является рациональным подходом. Желательно при создании программного обеспечения использовать объектно-ориентиро-ванный язык, чтобы была возможность динамически варьировать количество нейронов в слоях – порождать соответствующее количество экземпляров класса и количество слоев.
3.4.3. Рекомендации по исследованиям
При исследовании искусственных нейронных сетей необходимо проделать эксперименты по выявлению качества распознавания.
Эксперимент № 1. Исследование влияния отклонения изображения от эталона (в разных точках изображения) на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов и подправляется таким образом, чтобы отсутствовал один, два и т. д. пикселей в изображении эталона. Эксперимент проводится для нескольких случаев (отсутствие пикселей в разных участках изображения) для всех эталонов. При этом сравниваются различные нейронные сети.
Эксперимент № 2. Исследование влияния отклонений в виде шума одного, двух, трех и т. д. пикселей в изображении на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов и добавляется один или несколько пикселей шума. Эксперимент проводится для различного расположения шума и для различных эталонов. В ходе эксперимента также сравниваются различные нейронные сети.
Эксперимент № 3. Исследование влияния наличия шума и отклонений в изображении в виде одного, двух, трех и т. д. пикселей в изображении на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов. В изображение распознаваемого образа вносится шум в виде нескольких пикселей и удаляется несколько пикселей в изображении символа. Эксперимент повторяется для различного расположения шума и отклонений и для разных эталонов на различных типах нейронных сетей. Данный эксперимент является комбинацией первых двух.
Эксперимент № 4. Исследование влияния наличия черной строки или столбца в изображении (как помеха в образе) на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов. В изображение вносится черная строка или столбец. Эксперимент повторяется для различного положения строки или столбца в изображении и для различных эталонов. В ходе эксперимента сравниваются различные нейронные сети.
Эксперимент № 5. Исследование влияния наличия белой строки или столбца в изображении (как помеха в образе) на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов. В изображение вносится белая строка или столбец. Эксперимент повторяется для различного положения строки или столбца в изображении и для различных эталонов на различных нейронных сетях.
Эксперимент № 6. Исследование влияния количества нейронов в слоях на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов. Количество нейронов в слое варьируется от двух до равного числу признаков (для двухслойных сетей слои варьируются последовательно). Эксперимент повторяется на различных нейронных сетях.
Эксперимент № 7. Исследование влияния количества нейронов в слоях и количества эталонов на скорость обучения сети. В ходе проведения эксперимента количество нейронов в слое варьируется от двух до равного числу признаков (для двухслойных сетей слои варьируются последовательно), также варьируется количество эталонов (в пределах выбранных по согласованию с преподавателем). В каждом случае фиксируется число итераций и время обучения. Эксперимент повторяется на различных нейронных сетях.
Эксперимент № 8. Исследование влияния начертания входных образов на качество распознавания. В качестве исходного распознаваемого образа берется один из эталонов. Эталон модифицируется (делается жирное, наклонное или подчеркнутое начертание). Эксперимент повторяется на различных нейронных сетях для различных видоизменений.
Примечание. При использовании цвета в изображении эксперименты № 4 и № 5 следует проводить для цвета фона и цвета образа. В эксперименте № 4 вместо черной строки или столбца берется столбец или строка цвета образа. В эксперименте № 5 вместо белой строки или столбца берется строка или столбец фонового цвета.
3.4.4. Оформление результатов
Результаты экспериментов следует оформить в виде таблиц и графиков с пояснениями и подписями. На графиках следует показать зависимость ошибки распознавания для различных нейронных сетей от количества и вида помех, вносимых в изображение, а также от варьируемых параметров.
В качестве таблицы значений можно использовать таблицу следующего вида (табл. 4).
Таблица 4
Численные значения экспериментов
Изображение входного образа | Значение СКО | Нейронная сеть | ||
Однослойная | Двухслойная | Кохонена-Гроссберга | ||
Заполняйте две копии этой таблицы – одну для эталонов, другую для предъявляемых изображений, записывая в колонки значения выхода нейронной сети.
В отчете также следует привести данные об обучении нейронной сети: количество итераций, первоначальные и конечные значения весов.
4. ГЕНЕТИЧЕСКИЕ АЛГОРИТМЫ
Эволюционные вычисления – это область исследований на стыке информатики, биологии и искусственного интеллекта, предназначенная для решения двух задач:
1) вероятностно-детерминированный подход к оптимизации целевой функции (ЦФ);
2) изучение динамики процесса эволюции и свойств популяций в условиях изменения внешней среды.
Первая задача связана с использованием рекомбинаций, селективных стратегий и других механизмов биологической эволюции для поиска оптимальных решений. Вторая – с процессами адаптации в эволюционных алгоритмах.
Специфика решаемых задач оптимизации ЦФ привела к формированию нескольких направлений эволюционных вычислений:
1. Эволюционные стратегии – ориентированы на оптимизацию непрерывных функций с использованием рекомбинации популяции решений.
2. Эволюционное программирование – ориентировано на оптимизацию непрерывных функций без использования рекомбинации.
3. Генетический алгоритм (Дж. Холланд) – предназначен для оптимизации функций в дискретном пространстве и акцентирует внимание на рекомбинацию.
4. Генетическое программирование (Дж. Коза) – введено с целью оптимизации компьютерных программ с использованием принципов эволюции.
Базовые же модели самоорганизации следует искать в рамках второй задачи эволюционных вычислений (изучение динамики процесса эволюции и свойств популяций в условиях изменения внешней среды). Данная задача связана с использованием синергетических принципов построения алгоритмов развития и оптимизации:
- гибридизация,
- комбинированный поиск,
- иерархическая организация архитектур,
- организация макроэволюции,
- организация обратной связи с внешней средой.
Первые три принципа предполагают неоднородную архитектуру генетического алгоритма (ГА), где наряду с операторами ГА применяют и другие, часто не имеющие отношения к эволюции Дарвина.
4.1. Генетические операторы
4.1.1. Основные понятия генетических алгоритмов
Генетический алгоритм является алгоритмом для нахождения глобального экстремума многоэкстремальной функции. ГА применяется для подстройки весов синапсов при обучении нейронных сетей. ГА устроен по аналогии с принципами эволюции живых организмов.
Пусть требуется определить максимум функции многих переменных:
![]()
Каждая переменная представляется в виде гена. Набор значений переменных ![]() , представляющий произвольное решение задачи оптимизации функции f, представляется хромосомой или особью.
, представляющий произвольное решение задачи оптимизации функции f, представляется хромосомой или особью.
Для работы ГА на начальном этапе необходимо сгенерировать популяцию P из n особей (набор произвольных решений задачи оптимизации функции f).
![]() .
.
Гены каждой особи обычно заполняют случайными значениями.
Далее производится итерация.
На каждой итерации необходимо выполнить:
− генетический оператор кроссинговера,
− генетический оператор мутации,
− генетический оператор селекции.
4.1.2. Генетический оператор кроссинговера
Кроссинговер является наиболее важным генетическим оператором. Он генерирует новую хромосому, объединяя генетический материал двух родительских (рис. 38).
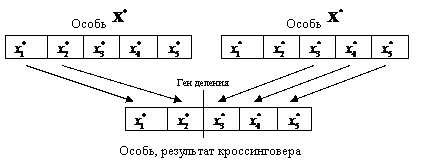

Рис. 38. Одноточечный генетический оператор кроссинговера
Существует несколько вариантов кроссинговера. Наиболее простым является одноточечный. В этом варианте берутся две хромосомы и «перерезаются» в случайно выбранной точке. Результирующая хромосома получается из начала одной и конца другой родительских хромосом.
Алгоритм одноточечного кроссинговера следующий.
Для каждой из a порождаемых особей выполнять:
1) генерацию псевдослучайного числа ![]()
![]() – номер гена деления хромосом порождающих особей на две части,
– номер гена деления хромосом порождающих особей на две части,
2) копирование значений генов ![]() первой порождающей особи в соответствующие гены порождаемой особи,
первой порождающей особи в соответствующие гены порождаемой особи,
3) копирование значений генов ![]() второй порождающей особи в соответствующие гены порождаемой особи.
второй порождающей особи в соответствующие гены порождаемой особи.
4.1.3. Генетический оператор мутации
Мутация представляет собой случайное изменение хромосомы (обычно простым изменением состояния одного из битов на противоположное). Данный оператор позволяет более быстро находить ГА локальные экстремумы и «перескочить» на другой локальный экстремум.
Инверсия инвертирует (изменяет) порядок бит в хромосоме путем циклической перестановки (случайное количество раз). Многие модификации ГА обходятся без данного генетического оператора.
Так как в результате применения операторов кроссинговера, мутации, инверсии популяция пополняется новыми особями, для окончания итерации нужно вернуть популяции прежний объем – n. Для этих целей используется оператор селекции.
Алгоритм одноточечного кроссинговера следующий.
Для каждой из a особей-мутантов выполнять:
1) генерацию псевдослучайного числа ![]()
![]() – номер гена-мутанта,
– номер гена-мутанта,
2) генерацию псевдослучайного числа ![]()
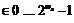 – значение гена, получаемое в результате мутации (
– значение гена, получаемое в результате мутации (![]() – количество разрядов, используемых при кодировании значений гена),
– количество разрядов, используемых при кодировании значений гена),
3) копирование значения d в ген ![]() особи-мутанта,
особи-мутанта,
4) копирование значений остальных генов 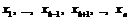 из порождающей особи в соответствующие гены особи-мутанта.
из порождающей особи в соответствующие гены особи-мутанта.
4.1.4. Генетический оператор селекции
Данный оператор выполняется в два этапа. Сначала для всех особей рассчитывается значение функции пригодности. Для расчета необходимо для каждой особи вычислить значение ![]() Особь тем пригоднее, чем больше значение
Особь тем пригоднее, чем больше значение ![]() (в случае задачи минимизации – чем меньше значение
(в случае задачи минимизации – чем меньше значение ![]() . Далее в соответствии с выбранной селективной стратегией из всех особей отбираются n штук, которые и составят собой популяцию следующего поколения.
. Далее в соответствии с выбранной селективной стратегией из всех особей отбираются n штук, которые и составят собой популяцию следующего поколения.
Существуют следующие селективные стратегии:
1. Элитный отбор – выбираются лучшие особи.
2. Пропорциональный отбор – количество особей с данным генотипом, выбираемое в новое поколение, пропорционально значению функции пригодности для данного генотипа.
3. Вероятностный отбор – вероятность попадания особи в новое поколение пропорциональна значению функции пригодности. Отличие от пропорционального отбора состоит в том, что особь может и не попасть в новое поколение, так как высокая вероятность все же не дает 100 %-ную гарантию.
4. Случайный отбор – особи в новое поколение выбираются случайно. Такая стратегия может использоваться, если отбор пригодности учитывается на ранней стадии – в момент скрещивания или мутации. Например, скрещиванию подлежат лишь лучшие особи.
5. Турнирный отбор может быть описан следующим образом: из популяции, содержащей N строк, выбирается случайным образом t строк и лучшая строка записывается в промежуточный массив (между выбранными строками проводится турнир). Эта операция повторяется N раз. Строки в полученном промежуточном массиве затем используются для скрещивания (также случайным образом). Размер группы строк, отбираемых для турнира, часто равен 2. В этом случае говорят о двоичном/парном турнире (binary tournament). Вообще же t называется численностью турнира (tournament size).
6. Отбор усечением (Truncation selection). Данная стратегия использует отсортированную по возрастанию популяцию. Число особей для скрещивания выбирается в соответствии с порогом T![]() [0; 1]. Порог определяет, какая доля особей, начиная с самой первой (самой приспособленной) будет принимать участие в отборе. Среди особей, попавших «под порог», случайным образом N раз выбирается самая везучая и записывается в промежуточный массив, из которого затем выбираются особи непосредственно для скрещивания.
[0; 1]. Порог определяет, какая доля особей, начиная с самой первой (самой приспособленной) будет принимать участие в отборе. Среди особей, попавших «под порог», случайным образом N раз выбирается самая везучая и записывается в промежуточный массив, из которого затем выбираются особи непосредственно для скрещивания.
4.2. Модели генетических алгоритмов
Существуют ряд типовых архитектур ГА.
4.2.1. Модель канонического ГА имеет следующие характеристики:
− фиксированный размер популяции,
− фиксированная разрядность генов,
− пропорциональный отбор,
− особи для скрещивания выбираются случайным образом,
− одноточечный кроссовер и одноточечная мутация,
− следующее поколение формируется из потомков текущего поколения без «элитизма», потомки занимают места своих родителей.
4.2.2. Модель Genitor (D. Whitley)
В данной модели используется специфичная стратегия отбора. Вначале, как и полагается, популяция инициализируется и её особи оцениваются. Затем выбираются случайным образом две особи, скрещиваются, причем получается только один потомок, который оценивается и занимает место наименее приспособленной особи. После этого снова случайным образом выбираются 2 особи и их потомок занимает место особи с самой низкой приспособленностью. Таким образом, на каждом шаге в популяции обновляется только одна особь.
4.2.3. Архитектуры с комбинированным поиском предполагают использование нескольких популяций, каждая из которых развивается по одной из схем эволюций: Дарвина, Ламарка, Фризе и др. Кроме того, возможно включение схем развития, использующих принципы адаптации, такие как автоматы Цетлина, а также популяции с генотипом, подверженным случайным флуктуациям. При этом в архитектуру встраивается управляющий блок, фильтрующий решения популяций.
4.2.4. Модель Hybrid algorithm (L. "Dave" Davis)
Использование гибридного алгоритма позволяет объединить преимущества ГА с преимуществами классических методов. Дело в том, что ГА являются робастными алгоритмами, т. е. они позволяют находить хорошее решение, но нахождение оптимального решения зачастую оказывается намного более трудной задачей в силу стохастичности принципов работы алгоритма. Поэтому возникла идея использовать ГА на начальном этапе для эффективного сужения пространства поиска вокруг глобального экстремума, а затем, взяв лучшую особь, применить один из "классических" методов оптимизации.
4.2.5. CHC (Eshelman) – Cross-population selection, Heterogenous recombination and Cataclysmic mutation
Данный алгоритм довольно быстро сходится из-за того, что в нем нет мутаций, используются популяции небольшого размера и отбор особей в следующее поколение ведется и между родительскими особями, и между их потомками. В силу этого после нахождения некоторого решения алгоритм перезапускается, причем, лучшая особь копируется в новую популяцию, а оставшиеся особи являются сильной мутацией (мутирует примерно треть битов в хромосоме) существующих и поиск повторяется. Ещё одной специфичной чертой является стратегия скрещивания: все особи разбиваются на пары, причем скрещиваются только те пары, в которых хромосомы особей существенно различны (хэммингово расстояние больше некоторого порогового, плюс возможны ограничения на минимальное расстояние между крайними различающимися битами). При скрещивании используется так называемый HUX-оператор (Half Uniform Crossover) – это разновидность однородного кроссинговера, но в нем к каждому потомку попадает ровно половина битов хромосомы от каждого родителя.
4.2.6. Иерархические архитектуры предполагают существование надстройки управляющей работой ГА. Эта надстройка может использовать экспертную систему, знания которой пополняются в процессе функционирования ГА. При этом нижележащий ГА может состоять из нескольких популяций, каждая из которых решает промежуточные задачи и может использовать оригинальную схему эволюции.
4.2.7. К однородным архитектурам генетического поиска относят ГА с использованием макроэволюции, когда создается не одна популяция, а некоторое множество популяций. Генетический поиск здесь осуществляется путем объединения родителей из различных популяций. Так предлагает архитектуру генетического поиска с миграцией и искусственной селекцией (рис. 39).
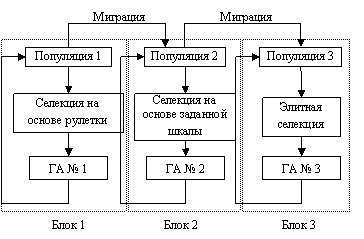

Рис. 39. Архитектура параллельного ГА с различными вариантами селекции
Здесь блоки 1–3 представляют собой ПГА (простой генетический алгоритм) или модифицированный ПГА. В каждом блоке выполняется своя искусственная селекция. В первом блоке селекция на основе рулетки. Во втором блоке используется селекция на основе заданной шкалы. В третьем блоке – элитная селекция. В блок миграции каждый раз отправляется лучший представитель из популяции. Связь между блоками 1–3 осуществляется путем последовательной цепочки 1–2, 2–3. Последний блок собирает лучшие решения, может закончить работу алгоритма или продолжить генетическую оптимизацию. Такая схема, по мнению , позволяет во многих случаях выходить из локальных оптимумов.
В рамках параллельного ГА применяются различные топологии. Так, возможно использование топологии «кольцо», где каждая популяция (остров) поставляет особей лишь в одну популяцию; полный граф, где каждый остров обменивается особями с каждым; Платоновы графы, в которых острова и их связи образуют правильные геометрические формы.
4.3. Алгоритм работы генетического алгоритма
4.3.1. Работу ПГА иллюстрирует схема на рис. 40.
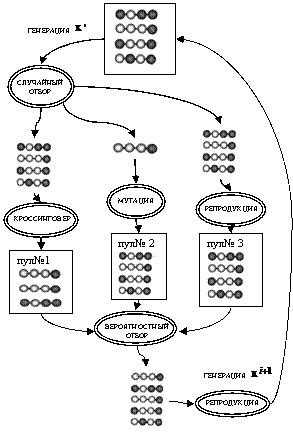

Рис. 40. Схема одного шага простого ГА
i-й шаг простого ГА:
1. Для популяции ![]() численностью l:
численностью l:
− произвести случайный отбор ![]() порождающих особей, применив к порождающим особям кроссинговер, сформировать пул № 1,
порождающих особей, применив к порождающим особям кроссинговер, сформировать пул № 1,
− произвести случайный отбор ![]() порождающих особей, применив к порождающим особям мутацию, сформировать пул № 2,
порождающих особей, применив к порождающим особям мутацию, сформировать пул № 2,
− произвести случайный отбор ![]() порождающих особей, применив к порождающим особям репродукцию, сформировать пул № 3.
порождающих особей, применив к порождающим особям репродукцию, сформировать пул № 3.
2. Для объединения пулов № 1, № 2 и № 3 общей численностью 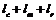 :
:
− произвести вероятностный отбор ![]() порождающих особей,
порождающих особей,
− применив к порождающим особям репродукцию, сформировать популяцию ![]() .
.
4.3.2. Работу островного ГА иллюстрирует схема на рис. 41
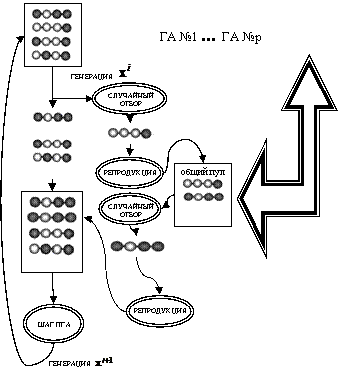

Рис. 41. Схема одного шага островного ГА
i-й шаг островного ГА:
1. Для каждого из ![]() параллельно функционирующих простых ГА:
параллельно функционирующих простых ГА:
− произвести итерацию согласно алгоритму ПГА,
− произвести случайный отбор ![]() порождающих особей, используя репродукцию (копирование), добавить отобранные особи в общий пул.
порождающих особей, используя репродукцию (копирование), добавить отобранные особи в общий пул.
2. Для каждого из ![]() параллельно функционирующих простых ГА:
параллельно функционирующих простых ГА:
− произвести случайный отбор ![]() порождающих особей из общего пула,
порождающих особей из общего пула,
− используя репродукцию (копирование), поместить отобранные особи на места особей, отобранных в п. 1.
4.3.3. Работу перезапускаемого ГА иллюстрирует схема на рис. 42.
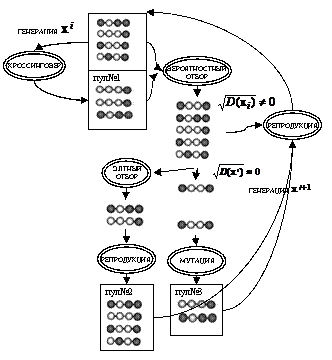

Рис. 42. Схема одного шага островного ГА
i-й шаг перезапускаемого ГА:
1. Пока ![]() внутривидовое разнообразие (
внутривидовое разнообразие (![]() ) выполнять:
) выполнять:
− для популяции ![]() численностью l, произведя кроссинговер, сформировать пул № 1,
численностью l, произведя кроссинговер, сформировать пул № 1,
− для объединения популяции ![]() с пулом № 1 общей численностью 2l произвести вероятностный отбор l порождающих особей, применив к порождающим особям репродукцию, сформировать популяцию
с пулом № 1 общей численностью 2l произвести вероятностный отбор l порождающих особей, применив к порождающим особям репродукцию, сформировать популяцию ![]()
2. Для популяции ![]() численностью l:
численностью l:
− произвести элитный отбор ![]() порождающих особей, применив к порождающим особям репродукцию, сформировать пул № 2,
порождающих особей, применив к порождающим особям репродукцию, сформировать пул № 2,
− применив мутацию трети генов ![]() особей, не вошедших в элиту, сформировать пул № 3.
особей, не вошедших в элиту, сформировать пул № 3.
3. Для объединения пула № 2 с пулом № 3 общей численностью l:
− применив репродукцию (копирование), сформировать популяцию ![]() .
.
4.4. Сходимость генетического алгоритма
4.4.1. Способы улучшения сходимости ГА
Проанализированные архитектуры самоорганизации эволюционных вычислений позволяют ГА адаптироваться к условиям внешней среды. До сих пор речь шла о реализации механизмов адаптации за счет выбора оптимальной структуры алгоритмов, содержащих ПГА в качестве блока. В рамках эволюционных вычислений имеются работы, посвященные также и параметрической адаптации. В этом случае ПГА и его модификации используют автономно. В качестве внешней среды в задаче оптимизации выступает целевая функция, а основной задачей адаптации ПГА является борьба с предварительной сходимостью, преодоление «локальных ям».
Для решения данной задачи в исследованиях применяют:
− улучшение структуры генетических операторов (ГО),
− адаптацию кодировки и ГО под решаемую задачу,
− управление параметрами ГО в процессе сходимости ГА,
− управление размером популяции,
− вероятностные стратегии с использованием обратных связей.
Анализ работ в области параметрической адаптации ПГА выявил две основные цели модификаций ГА:
− управление уровнем генетического разнообразия,
− управление направленностью генетического разнообразия.
Одной из основных причин предварительной сходимости ПГА (отсутствия «живучести» ПГА как оптимизационного средства) является потеря генетического разнообразия популяции. В критической ситуации «ската в локальную яму» в популяции имеются лишь строительные блоки, характерные для узкого подпространства поиска, соответствующего положению «локальной ямы». Такая ситуация может возникнуть вследствие неправильного отбора особей в новое поколение – несовершенства селективной стратегии. Необходимые строительные блоки могут отсутствовать в популяции и по причине недостаточного ее размера.
Проблема несовершенства селективных стратегий рассматривалась в ряде работ, например, предлагается подвергать скрещиванию лишь особи со значением функции пригодности (ФП) выше среднего по популяции. Отбор с вытеснением, когда из популяции удаляются похожие особи, используется в работах с соавторами.
Одним из способов усовершенствования пропорционального отбора является масштабирование ФП, позволяющее уменьшать влияние хромосом с лучшей ФП на начальном этапе и увеличивать на заключительном.
Другим естественным способом управления генетическим разнообразием является варьирование размера популяции. При выборе размера популяции нет точных принципов – большая популяция дает потери хромосом, малая – большую возможность попасть в «локальную яму». Критика идеи об увеличении численности популяции при улучшении сходимости и уменьшении при ухудшении сходимости высказывается в ряде работ. Существует также адаптивный подход к установлению численности популяции: для каждой особи вводится время жизни в популяции, пропорциональное значению ФП данной особи. Такой подход приводит к непрерывной динамике численности популяции. Имеются также решения, позволяющие отказаться от удаления особей за счет хранения в популяции не их генотипов, а лишь ссылок на генотипы, при этом экономятся ресурсы и вычислительные затраты.
Имеются и другие способы повышения генетического разнообразия, например введение генотипа переменной длины, когда в искусственной селекции задействуется лишь часть генов, остальные же (рецессивные гены) временно не используются. За использование или сокрытие гена отвечает битовая маска, которая модифицируется в случае риска предварительной сходимости. Генетическим разнообразием управляют также по принципу прерывистого равновесия, когда в отдельные моменты функционирования ГА производится «встряска» генотипов за счет мутаций или перемешивания генов разных особей.
Наиболее простым способом управления направленностью поиска является адаптация ГО к решаемой задаче. Например, часто используется жадный оператор кроссинговера; в этом случае адаптация производится уже на уровне хромосом (решается задача оптимизации скрещивания). Часто в работах применяют специфические операторы (оператор транслокации) или оригинальные модификации кроссинговера: равномерный (с сохранением битов со значением единица), кольцевой, с варьированием количества полов и т. п.
Другой способ управления направленностью поиска связан с использованием вероятностных подходов и эвристик. Так, предлагается применять нечеткий контроллер, управляющий параметрами ГА для улучшения процесса сходимости.
Часто отмечается необходимость уменьшения вероятности мутаций при приближении к оптимуму: случайные мутации с равной вероятностью могут привести как к увеличению значений функции пригодности, так и к ее уменьшению, целесообразно динамически управлять вероятностью случайной мутации.
Аналогичные действия предполагает использование принципа моделирования отжига, где проводятся аналогии с процессом закалки металлов и предлагается уменьшать вероятности применения операторов при приближении к экстремуму.
Часть исследователей предлагает не уменьшать вероятности применения ГО, а динамически управлять очередностью их выполнения. При этом вероятность выбора операторов может формироваться в соответствии со значениями ЦФ, которые они давали в истории процесса сходимости. Направление поиска также можно корректировать, создавая новые генотипы не операторами кроссинговера и мутаций, а напрямую заполняя гены, исходя из вероятности выбора того или иного значения в гене. Вероятность увеличивается в случае успеха особи с данным генотипом и уменьшается при получении низкого значения пригодности особи.
Ряд исследователей предлагает искать оптимальные параметры и структуру ГА на программном комплексе под конкретную задачу, например, посредством перебора всех возможных вариантов.
4.4.2. Оценка процесса сходимости и качества решения
Существуют задачи, для которых известен явный признак необходимости остановки алгоритма. К таким задачам относятся задачи оптимизации с критериями, построенными на минимизации ошибок (регрессия, идентификация), где присутствие в популяции особи со значением ФП, близким к нулю, ведет к остановке алгоритма и выдаче решения в виде генотипа данной особи. В таких задачах необходим лишь поиск оптимального генотипа ![]() . В этом случае при проведении экспериментов по исследованию сходимости того или иного ГА на тестовых функциях исследователи сравнивали алгоритмы по числу генераций до обнаружения в популяции особи с оптимальным генотипом
. В этом случае при проведении экспериментов по исследованию сходимости того или иного ГА на тестовых функциях исследователи сравнивали алгоритмы по числу генераций до обнаружения в популяции особи с оптимальным генотипом ![]() , где
, где ![]() – количество генов особи. Очевидно, что данный критерий не позволяет оценивать способности ГА к нахождению решения задач, в которых идеальное значение критерия неизвестно. К числу таких задач, наряду с задачами самоорганизации, относятся также и классические оптимизационные задачи, в которых имеется информация только о форме оптимизируемой функции, а ее уравнение не задано (такие задачи изучаются, например, в теории экстремальных систем управления).
– количество генов особи. Очевидно, что данный критерий не позволяет оценивать способности ГА к нахождению решения задач, в которых идеальное значение критерия неизвестно. К числу таких задач, наряду с задачами самоорганизации, относятся также и классические оптимизационные задачи, в которых имеется информация только о форме оптимизируемой функции, а ее уравнение не задано (такие задачи изучаются, например, в теории экстремальных систем управления).
Иные критерии нужны также и для исследования возможностей ГА в задачах с динамическими критериями.
Необходимо использовать критерии оценки процесса сходимости как для оценки адаптационных свойств ГА, так и для оценки эффективности ГА в задачах классической оптимизации, где допускается лишь некоторая информация о форме оптимизируемой функции, само же оптимальное значение считается неизвестным.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
