

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
В общем случае границей для квадратичных разделяющих функций является гипергиперболоид. В частных случаях это будут гиперсфера, гиперэллипсоид и гиперэллипсоидальный цилиндр. Общая схема вычислителя квадратичного разделения показана на рис. 24.
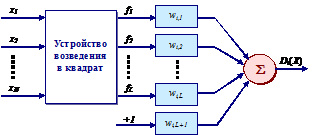
Рис. 24. Вычислитель квадратичной разделяющей функции
2.4. Обучение в линейных классификаторах
Линейный классификатор на два класса легко может быть осуществлен с помощью одного порогового логического элемента. Если образы различных классов линейно разделимы (могут быть разделены гиперплоскостью в пространстве признаков WX), то при правильных значениях весовых коэффициентов w1, w2, ... , wN+1 в (5) можно получить вполне правильное распознавание. Однако, на практике, правильные значения весовых коэффициентов отсутствуют, поэтому предполагается, что классификатор построен так, что он способен устанавливать необходимые (правильные) значения весов по входным образам. Основная идея заключается в том, что, «осматривая» образ известных классов, классификатор может автоматически определять веса, необходимые для правильного распознавания.
Предполагается, что с увеличением числа «показанных» образов способность распознавания классификатора становится все лучше и лучше. Этот процесс называется тренировкой или обучением, а вводимые при этом образы называются обучающими образами или обучающей выборкой. Несколько простых правил обучения кратко рассматриваются в данном параграфе.
Пусть Y обозначает дополненный вектор признаков, равный
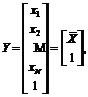 (20)
(20)
где ![]() – вектор признаков образа.
– вектор признаков образа.
Рассмотрим два множества обучающих образов ![]() и
и ![]() , принадлежащих двум различным классам образов А1 и А2. Соответственно этим двум обучающим множествам есть два множества дополненных векторов T1 и T2; элементы T1 и T2 получены путем дополнения векторов, принадлежащих множествам
, принадлежащих двум различным классам образов А1 и А2. Соответственно этим двум обучающим множествам есть два множества дополненных векторов T1 и T2; элементы T1 и T2 получены путем дополнения векторов, принадлежащих множествам ![]() и
и ![]() . To, что два обучающих множества линейно разделимы, означает существование вектора W (называемого вектором весов решения) такого, что
. To, что два обучающих множества линейно разделимы, означает существование вектора W (называемого вектором весов решения) такого, что
![]()
где
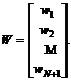 (22)
(22)
2.4.1. Правила обучения
Процедуру обучения («исправление ошибок») для линейного классификатора можно сформулировать следующим образом. Для любого Y Î T1 произведение Y TW должно быть положительным, то есть Y TW > 0. Если классификатор дает ошибочный (то есть YT W < 0) или неопределенный результат (то есть YTW = 0), то надо взять новый вектор весов:
W' = W + aY, (23)
где a > 0 называется поправочным дополнением. С другой стороны, для Y Î T2, YTW < 0. Если выход прибора ошибочный (то есть YTW > 0) или неопределенный, то принимаем
W' = W – aY. (24)
В начале обучения для W принимаются любые удобные значения. Для выбора a можно предложить три правила (на их основе можно построить три вида алгоритмов обучения):
1. Правило фиксированного дополнения: a является любым фиксированным положительным числом.
2. Правило абсолютной поправки: a берется равным наименьшему целому числу, при котором значение YTW переходит порог, равный нулю.
Это означает, что
a = наименьшее целое число > (25)
3. Правило дробной поправки: a выбирается так, что
![]() (26)
(26)
или эквивалентно:
(27)
Сходимость этих трех правил исправления ошибок может быть доказана. Под сходимостью понимается следующее: если два обучающих множества линейно разделимы, то последовательность весовых векторов, построенная по правилам обучения, сходится к вектору весов решения за конечное число шагов обучения или итераций.
2.5. Функции сходства
Объект можно записать в виде последовательности двоичных символов в соответствии со следующим правилом: если i-й объект обладает каким-либо признаком, то x = 1; если не обладает, то x = 0, то есть объект представляет собой двоичный код (число разрядов равно числу признаков), состоящий из единиц (если признак присутствует) и нулей (если признак отсутствует).
Тогда можно произвести относительно тонкую классификацию, если для каждой пары предъявляемых объектов установить степень их сходства и различия, используя двоичное представление признаков реализации.
2.5.1. Таблицы соответствия
Таблицу соответствия двух реализаций xi и xj можно представить в следующем виде:
Таблица 1
Соответствие двух реализаций
xi xj | 1 | 0 |
1 | a | h |
0 | g | b |
Здесь a – число случаев, когда xi и xj обладают одним и тем же признаком:
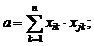
b – число случаев, когда xi и xj не обладают никакими общими свойствами:
;
h – число случаев, когда xi не обладает признаком, присущим xj:
g – число случаев, когда xi обладает признаком, отсутствующим у xj:
.
Из рассмотренных величин видно, что чем больше сходство между xi и xj, тем больше должен быть коэффициент a и тем сильнее он должен отличаться от других.
2.5.2. Распространенные функции сходства
Можно ввести функцию сходства, обладающую следующими свойствами:
− она должна быть возрастающей в зависимости от a;
− симметричной относительно g и h.
Эту функцию, для которой известно несколько вариантов ее вычислений, называют двоичным расстоянием:
S1 (x![]() , x
, x![]() ) =
) = ![]()
![]() – Рассел и Рао;
– Рассел и Рао;
S2 (x![]() , x
, x![]() ) =
) = ![]() – Жакар и Нидмен;
– Жакар и Нидмен;
S3 (x![]() , x
, x![]() ) =
) = ![]() – Дайс;
– Дайс;
S4 (x![]() , x
, x![]() ) =
) = ![]() – Соколь и Сниф;
– Соколь и Сниф;
S5 (x![]() , x
, x![]() ) =
) = ![]() – Соколь и Мишнер;
– Соколь и Мишнер;
S6 (x![]() , x
, x![]() ) =
) =![]() – Кульжинский,
– Кульжинский,
где n – количество признаков.
Если объекты идентичны, то имеем b = n – a, q = h = 0, в этом случае S6 стремится к бесконечности, функции S1, S2, S4, S5 равны единице, а S3 = 0.5.
2.6. Реализация алгоритмов распознавания методом дискриминантных функций
Для закрепления теоретического материала студенту предлагается создать программное обеспечение для решения задач распознавания образов на основе использования линейных дискриминантных функций.
2.6.1. Постановка задачи
1. Изучить устройство линейной распознающей машины и порогового логического блока.
2. Выбрать исходный алфавит классов (цифры, буквы русского алфавита, буквы английского алфавита, буквы греческого алфавита, знаки препинания и арифметические символы, радиоэлементы, геометрические фигуры, узоры).
3. Составить программу, включающую в себя алгоритмы решения двух задач.
Задача 1. Подсчет значений функций сходства для всех эталонов и предлагаемого входного образа с последующей классификацией входного образа к одному из классов на основании рассчитанных значений функций сходства. Кроме того, нужно составить алгоритм подсчета среднеквадратического отклонения эталонов от образа по признакам.
Задача 2. Реализация алгоритма распознавания образов с помощью линейной распознающей машины.
4. Программное обеспечение должно позволять просматривать эталоны (классы) изображений, а также распознаваемые изображения; записывать эталоны изображений в библиотеку на диск, записывать входной образ на диск; позволять редактировать входной образ.
5. Испытать программное обеспечение для различных входных данных.
6. Ввести в алгоритм распознавания средства для обучения (по желанию студента).
7. Произвести оценку качества распознавания для различных случаев, систематизировав полученные результаты в таблицы. Построить графики выявленных зависимостей, сделать выводы.
8. Результаты работы оформить в виде отчета.
2.6.2. Рекомендации по созданию программного обеспечения
После изучения теоретического материала необходимо задаться исходными изображениями и системой признаков. Рекомендуется выбрать способ задания изображения в виде массива точек. Размер изображений должен быть не менее 8 ×12 точек (иначе символы будут слишком маленькими и плохо читаться). На миллиметровке или клетчатой бумаге задаться видом эталонов (классов), чтобы при кодировании не было неоднозначности. Например, буква «Н» выглядит следующим образом (рис. 25).
 Рис. 25. Образ буквы «Н»
Рис. 25. Образ буквы «Н»
Двоичный код этой буквы будет следующим (по строкам): 1 1 1 1 1 , 1 1 1 1 1 . Поскольку каждая строчка представляется восемью битами, то она легко кодируется одним байтом.
В качестве признаков данного класса можно выбрать, например, суммы бит по столбцам и по строкам. Получим двадцать признаков (сначала идут суммы столбцов): 11, 1, 1, 1, 1, 1, 1, 11, 2, 2, 2, 2, 2, 8, 2, 2, 2, 2, 2, 0.
Для использования функций сходства построенных на двоичном коде признаков необходимо соотнести признаки входного образа и эталона. Например, если признак в эталоне и в распознаваемом образе равен нулю, то считаем, что данный признак отсутствует, то есть увеличивается число b. Если признак в эталоне не отличается более чем на 5 % (степень сходства можно выбрать любую) от признака в распознаваемом образе, то считаем, что данный признак присутствует и в эталоне, и в образе, то есть увеличивается число а. По аналогии можно определить случаи наращивания чисел g и h.
Замечания.
1) выбор признаков в данном случае не является универсальным и может оказаться наихудшим, например, для узоров (если будут симметричные узоры);
2) можно использовать цвета при задании эталонов (и при распознавании), тогда одним из признаков будет цвет;
3) двоичное кодирование признаков для функций сходства удобно, если констатируется факт наличия или отсутствия признаков. Но если классифицировать образы можно по различным значениям признака, то иногда необходимо построить собственные функции сходства.
При реализации линейной распознающей машины необходимо будет задать коэффициенты линейной дискриминантной функции для каждого класса. Эту операцию можно произвести вручную, выбрав произвольные значения, а затем путем обучения (ручной настройки) подправить эти коэффициенты в процессе распознавания. Изменять коэффициенты можно с помощью алгоритмов обучения (правил выбора поправочного коэффициента).
2.6.3. Рекомендации по исследованиям
При выполнении исследования линейной распознающей машины и функций сходства необходимо проделать следующие эксперименты по исследованию качества распознавания с помощью созданного программного обеспечения.
Эксперимент № 1. Исследование влияния отклонения изображения от эталона (в разных точках изображения). В качестве исходного распознаваемого образа берется один из эталонов и подправляется таким образом, чтобы отсутствовал один, два и т. д. пикселей в изображении эталона. Эксперимент проводится для нескольких случаев (отсутствие пикселей в разных участках изображения) для всех эталонов.
Эксперимент № 2. Исследование влияния отклонения в виде шума одного, двух, трех и т. д. пикселей в изображении. В качестве исходного распознаваемого образа берется один из эталонов и добавляется несколько (или один) пикселей шума. Эксперимент проводится для различного расположения шума и для различных эталонов.
Эксперимент № 3. Исследование влияния наличия шума и отклонений в изображении в виде одного, двух, трех и т. д. пикселей в изображении. В качестве исходного распознаваемого образа берется один из эталонов. В изображение распознаваемого образа вносится шум в виде нескольких пикселей и удаляется несколько пикселей в изображении символа. Эксперимент повторяется для различного расположения шума и отклонений и для разных эталонов.
Эксперимент № 4. Исследование влияния наличия черной строки или столбца в изображении (как помеха в образе). В качестве исходного распознаваемого образа берется один из эталонов. В изображение вносится черная строка или столбец. Эксперимент повторяется для различного положения строки или столбца в изображении и для различных эталонов.
Эксперимент № 5. Исследование влияния наличия белой строки или столбца в изображении (как помеха в образе). В качестве исходного распознаваемого образа берется один из эталонов. В изображение вносится белая строка или столбец. Эксперимент повторяется для различного положения строки или столбца в изображении и для различных эталонов.
Примечание. При использовании цвета в изображении эксперименты № 4 и № 5 следует проводить для цвета фона и цвета образа. В эксперименте № 4 вместо черной строки или столбца берется столбец или строка цвета образа. В эксперименте № 5 вместо белой строки или столбца берется строка или столбец фонового цвета.
Результаты экспериментов следует оформить в виде таблиц и графиков с пояснениями и подписями. На графиках необходимо показать зависимость ошибки распознавания для различных функций сходства и линейной распознающей машины от количества и вида помех, вносимых в изображение.
Исследуйте также правильность распознавания для различного начертания символов (жирное, наклонное, жирное и наклонное, наклонное в другую сторону). Результаты также оформите в виде таблиц и графиков с пояснениями и комментариями.
В качестве таблиц значений можно использовать табл. 2.
Таблица 2
Численные значения экспериментов
Изображение входного образа | Значение СКО | Значение функций сходства | Значение линейной дискриминантной функции | ||
Рассел-Рио | Жакар-Нидмен | Дайс | Соколь-Сниф | Соколь-Мишнер | Кульжинский |
Заполняйте две копии этой таблицы – одну для эталонов, другую для предъявляемых изображений, записывая в колонки значения функций сходства и значения линейной дискриминантной функции, имеющей максимальное значение.
При моделировании различных ситуаций распознавания на созданном программном комплексе при наличии и отсутствии помех в распознаваемых образах для оценки качества распознавания можно использовать табл. 3.
Таблица 3
Качественные значения экспериментов
Изображение входного образа | СКО | Функции сходства | Линейная распознающая машина | Результат распознавания | |
Рассел-Рио | Жакар-Нидмен | Дайс | Соколь-Сниф | Соколь-Мишнер | Кульжинский |
В столбцах следует указывать, какие функции справились с распознаванием, а какие нет.
3. ВВЕДЕНИЕ В ТЕОРИЮ НЕЙРОННЫХ СЕТЕЙ
3.1. Общие понятия искусственных нейронных сетей
3.1.1. Искусственная нейронная сеть
Искусственная нейронная сеть является некоторой моделью естественной нейронной сети. Каждый элемент искусственной нейронной сети (нейрон) является прототипом, имитирующим свойства и работу биологического нейрона.
Рассмотрим работу искусственной однослойной нейронной сети (рис. 26). На синапсы (однонаправленные входы) искусственного нейрона поступает некоторое множество сигналов. Каждый сигнал умножается на соответствующий вес, характеризующий синаптическую силу. Входные сигналы после синапсов поступают в ячейки нейронов (блоки суммирования), выходом которых являются аксоны, с которых сигналы (возбуждения или торможения), определяющие уровень активации нейрона, поступают на синапсы следующих нейронов (если сеть многослойная) или на основе которых принимается решение. Хотя сетевые парадигмы весьма разнообразны, в их основе почти всегда лежит именно эта конфигурация.
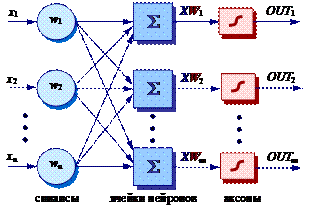
Рис. 26. Искусственная однослойная нейронная сеть
Отметим, что синапсы служат лишь для распределения входных сигналов, а аксоны лишь для выдачи сигналов, поэтому они не считаются слоем (слоем являются ячейки нейронов, выполняющие вычисления с комбинациями входных сигналов). В искусственных и биологических сетях многие соединения могут отсутствовать, все соединения показаны в целях общности. Могут иметь место также соединения между выходами и входами элементов в одном слое.
3.1.2. Искусственный нейрон
Условно эту часть искусственной нейронной сети можно представить искусственным нейроном (рис. 27). Эта простая модель искусственного нейрона игнорирует многие свойства своего биологического двойника. Например, она не принимает во внимание задержки во времени, которые воздействуют на динамику системы. Входные сигналы сразу же порождают выходной сигнал. И, что более важно, она не учитывает воздействий функции частотной модуляции или синхронизирующей функции биологического нейрона, которые ряд исследователей считают решающими.
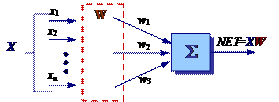
Рис. 27. Входная часть искусственного нейрона
Сигнал NET далее, как правило, преобразуется некоторой активационной функцией F и дает выходной нейронный сигнал OUT.
Активационная функция – это нелинейная усилительная характеристика искусственного нейрона, определяющая его уровень активации.
Коэффициент усиления активационной функции вычисляется как отношение приращения величины OUT к вызвавшему его небольшому приращению величины NET:
![]() .
.
Он выражается наклоном кривой при определенном уровне возбуждения и изменяется от малых значений при больших отрицательных возбуждениях (кривая почти горизонтальна) до максимального значения при нулевом возбуждении и снова уменьшается, когда возбуждение становится большим положительным.
Если активационная функция F сужает диапазон изменения величины NET так, что при любых значениях NET значения OUT принадлежат некоторому конечному интервалу, то F называется «сжимающей» функцией.
3.1.3. Типы активационных функций
Качество работы искусственной нейронной сети во многом зависит от весов синаптических связей и от типа применяемых активационных функций. Рассмотрим типы активационных функций.
Различают следующие виды активационных функций:
− единичная функция;
− линейный порог (функция гистерезиса);
− сигмоидальная функция (гиперболический тангенс).
3.1.4. Единичная функция, персептрон
Единичная активационная функция является самой простой, ее график представлен на рис. 28а.
Для этой функции OUT = 1, если 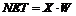 больше некоторой величины T и OUT = 0 в остальных случаях, где Т – некоторая постоянная пороговая величина.
больше некоторой величины T и OUT = 0 в остальных случаях, где Т – некоторая постоянная пороговая величина.
Если в однослойной искусственной нейронной сети применяется единичная активационная функция, то такая сеть называется персептроном. Первое систематическое изучение персептронов было предпринято Маккалокком и Питтсом в 1943 г. В 60-е годы персептроны вызвали большой интерес и оптимизм. Розенблатт доказал замечательную теорему об обучении персептронов. Далее первоначальная эйфория сменилась разочарованием, когда оказалось, что персептроны не способны обучиться решению ряда простых задач. Минский строго проанализировал эту проблему и показал, что имеются жесткие ограничения на то, что могут выполнять однослойные персептроны, и, следовательно, на то, чему они могут обучаться.
3.1.5. Функция линейного порога
Отличием функции линейного порога от единичной функции является не скачкообразное изменение выхода OUT, а в виде линейного тренда. График функции представлен на рис. 28б.
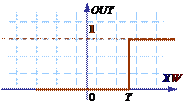

а) б)
Рис. 28. Графики активационных функций:
а) единичная, б) линейная активационная функция
3.1.6. Сигмоидальная функция
В качестве «сжимающей» функции часто используется логистическая или «сигмоидальная» (S-образная) функция. Эта функция математически выражается как
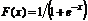 .
.
Таким образом,
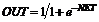 . (28)
. (28)
Данная функция позволяет обрабатывать нейронной сети как слабые, так и сильные сигналы. Слабые сигналы нуждаются в большом сетевом усилении, чтобы дать пригодный к использованию выходной сигнал. Однако усилительные каскады с большими коэффициентами усиления могут привести к насыщению выхода шумами усилителей (случайными флуктуациями), которые присутствуют в любой физически реализованной сети. Сильные входные сигналы в свою очередь также будут приводить к насыщению усилительных каскадов, исключая возможность полезного использования выхода. Сигмоидальная функция решает эту проблему.
В качестве сигмоидальных функций может выступать как логистическая функция (1), так и функция гиперболического тангенса (рис. 29):
OUT = th(NET).
Отличием логистической функции от функции гиперболического тангенса является диапазон выходных значений. У первой он находится в диапазоне (0; 1), а у второй в диапазоне (–1; 1).

Рис. 29. График сигмоидальной активационной функции
3.1.7. Проблема функции «исключающее или»
Один из самых пессимистических результатов Минского показывает, что однослойный персептрон не может воспроизвести такую простую булевскую функцию, как «исключающее или». Проблему можно проиллюстрировать с помощью однослойной однонейронной системы с двумя входами, показанной на рис. 30а. Обозначим один вход через х, а другой через у, тогда все их возможные комбинации будут состоять из четырех точек на плоскости XOY, как показано на рис. 30б. Например, точка х = 0 и у = 0 обозначена на рисунке как точка А0.
В сети на рис. 30а активационная функция F является обычным порогом, так что OUT принимает значение ноль, когда NET меньше 0.5, и единица в случае, когда NET больше или равно 0.5. Персептрон выполняет следующее вычисление:
NET = xw1 + yw2. (29)
Никакая комбинация значений двух весов не может дать соотношения между входом и выходом, задаваемого таблицей истинности функции «исключающее или».
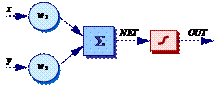
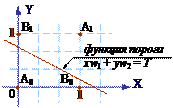
а) б)
Рис. 30. Проблема «исключающее или»:
а) однонейронная система, б) результат разбиения пространства признаков
Невозможность нарисовать прямую линию, разделяющую плоскость XOY так, чтобы реализовывалась функция «исключающее или», является не единственным случаем. Имеется обширный класс функций, не реализуемых однослойной нейронной сетью. Об этих функциях говорят, что они являются линейно неразделимыми и накладывают определенные ограничения на возможности однослойных сетей.
Линейная разделимость ограничивает однослойные нейронные сети задачами классификации, в которых множества точек (соответствующих входным значениям) могут быть разделены геометрически прямой линией. И поскольку линейная разделимость ограничивает возможности персептронного представления, то важно знать, является ли данная функция разделимой. К сожалению, не существует простого способа определить это, если число переменных велико.
3.1.8. Многослойные нейронные сети
К концу 60-х годов проблема линейной разделимости была хорошо понята. К тому же было известно, что это серьезное ограничение представляемости однослойными сетями можно преодолеть, добавив дополнительные слои.
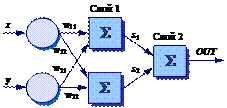
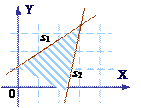
Рассмотрим простую двухслойную сеть с двумя входами, подведенными к двум нейронам первого слоя, соединенными с единственным нейроном в слое 2 (рис. 31а). Пусть порог выходного нейрона равен 0.75, а оба его веса равны 0,5. В этом случае для того, чтобы порог был превышен и на выходе появилась единица, требуется, чтобы оба нейрона первого уровня на выходе имели единицу. Таким образом, выходной нейрон реализует логическую функцию «и».
Каждый нейрон слоя 1 разбивает плоскость XOY на две полуплоскости, один обеспечивает единичный выход для входов ниже верхней линии, другой – для входов выше нижней линии. На рис. 31б показан результат такого двойного разбиения, где выходной сигнал нейрона второго слоя равен единице только внутри V-образной области. Аналогично во втором слое может быть использовано три нейрона с дальнейшим разбиением плоскости и созданием области треугольной формы. Включением достаточного числа нейронов во входной слой может быть образован выпуклый многоугольник любой желаемой формы. Так как они образованы с помощью операции «и» над областями, задаваемыми линиями, то все такие многогранники выпуклы, следовательно, только выпуклые области и возникают. Точки, не составляющие выпуклой области, не могут быть отделены от других точек плоскости двухслойной сетью.
а) б)
Рис. 31. Двухслойная сеть – а) и результат разбиения пространства признаков – б)
Нейрон второго слоя не обязательно ограничен функцией «и», он может реализовывать многие другие функции при подходящем выборе весов и порога. Например, можно сделать так, чтобы единичный выход любого из нейронов первого слоя приводил к появлению единицы на выходе нейрона второго слоя, реализовав тем самым логическое «или». Имеется 16 двоичных функций от двух переменных. Если выбирать подходящим образом веса и порог, то можно воспроизвести 14 из них (все, кроме «исключающее или» и «исключающее нет»).
Входы не обязательно должны быть двоичными. Вектор непрерывных входов может представлять собой произвольную точку на плоскости XOY. В этом случае мы имеем дело со способностью сети разбивать плоскость на непрерывные области, а не с разделением дискретных множеств точек. Для всех этих функций, однако, линейная разделимость показывает, что выход нейрона второго слоя равен единице только в части плоскости XOY, ограниченной многоугольной областью. Поэтому для разделения плоскостей P и Q необходимо, чтобы все P лежали внутри выпуклой многоугольной области, не содержащей точек Q (или наоборот).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
