
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Предположим, что каждый измеритель предназначен для определения одного признака. Тогда комплекс аппаратуры, обеспечивающей измерение всех признаков априорного словаря, должен состоять из совокупности измерителей А = {А1 ..., AN}. Каждому измерителю Aj присущи определенные значения характеристик Grj, j = l, ..., N; r = l, 2, 3, ... .
Будем исходить из естественного предположения о том, что характеристики измерителей обладают свойством аддитивности. Тогда для некоторого комплекса аппаратуры B = {Aj1, Aj2, ..., Ajk) каждая характеристика представляет собой суммарное значение соответствующих характе-ристик измерителей, т. е. ![]()
При построении рабочего словаря признаков системы распознавания может быть использован только такой набор измерителей В, для которого выполняются следующие ограничения относительно характеристик:
(1.26)
Возникновение задачи связано с тем, что априорный словарь признаков не может быть полностью аппаратурно обеспечен, так как хотя бы для одной характеристики имеет место неравенство
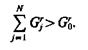 (1.27)
(1.27)
В качестве критерия эффективности системы распознавания В будем рассматривать средний риск `RB принятия решения о принадлежности распознаваемого объекта к некоторому классу.
Пусть применительно к набору измерителей В, реализующему признаковое пространство, описываемое вектором хB = {xj1..., xjk}, установлено, что признаки распознаваемого объекта ω составляют хj1 = х0j1, ..., хjk = х0jk. Обозначим это событие bB. Тогда риск принятия решения о том,
что объект соотносится к классу Ωg, g = l, ..., m, равен
![]() (1.28)
(1.28)
где Clg — потери, связанные с решением ωÎΩg, когда в действительности ωÎΩl,, g, l = 1, ..., m, g ¹ l; Р(Ωi|bB) — апостериорная вероятность, которая может быть определена по (4.31 Глава 1).
В качестве решающего правила, используемого в системе распознавания, будем полагать следующее: если произошло событие bB то ωÎΩg, при
![]() (1.29)
(1.29)
Средний риск (критерий эффективности В системы распознавания) применительно к непре-рывному описанию классов
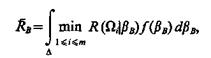 (1.30)
(1.30)
где f(bB) — совместная плотность распределения; D — область признакового пространства, охватывающая все возможные значения bB
Учитывая, что 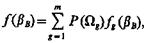 и подставляя это выражение в (1.30), получим
и подставляя это выражение в (1.30), получим
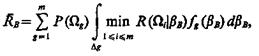 (1.31)
(1.31)
где Dg— область признакового пространства, охватывающая значения bВ, соответствующие g-му классу, т. e. fg(bB) = 0 на D\Dg. Средний риск (критерий эффективности В системы распознавания) применительно к дискретному описанию классов
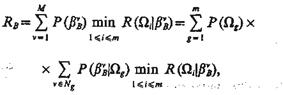 (1.32)
(1.32)
где М — число возможных значений bB; Ng — число возможных значений bB в Ωg - м классе;
Р (bvВ) — безусловная вероятность реализации v-гo варианта значений признаков в системе В; P(bvВ½Ωg) — вероятность реализации v-гo варианта значений признаков у объекта при условии, что он относится к g-му классу.
Сформулируем задачу: в условиях исходной информации относительно {Р(Ωi}, fi(хj1, ..., хjk), где {j1, ..., jk}Î{l, ..., N}, jk £ N; i = l, ..., m, а также платежной матрицы С, дисциплинирующих условий (1.26) требуется определить такое признаковое пространство системы распознавания, которое доставляет экстремальное (минимальное) значение критерию эффективности системы.
Итак, задача в условиях ограничений 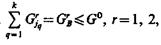 3, ..., сводится к определению:
3, ..., сводится к определению:
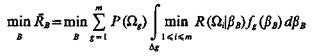 (1.33)
(1.33)
при непрерывном описании классов и к
![]() (1.34)
(1.34)
при дискретном описании классов.
Подставив в (1.30) значение R(Ωi|bB), определяемое (1.28), получим применительно к непрерывному описанию классов
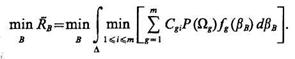 (1.35)
(1.35)
Применительно к дискретному описанию классов
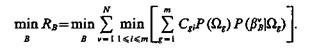 (1.36)
(1.36)
Для определения оптимального пространства В0, доставляющего минимум `RB при рассмотренных описаниях классов, необходимо рассчитать значения `RB при различных допустимых комбинациях аппаратурного оснащения системы распознавания и найти среди них наименьшее значение.
1.5. Сравнительная оценка признаков
Выше были рассмотрены достаточно общие методы выбора совокупности признаков, которые целесообразно и доступно использовать при построении системы распознавания. Однако на прак-тике достаточно часто возникает более простая задача, состоящая в проведении сравнительной оценки качества признаков. Остановимся на некоторых методах решения этой задачи. При этом будем полагать, что качество признака хl выше, чем качество признака хs, l, s = l, ..., N, если в соответствии с выбранным критерием сравнительной оценки показатель качества признака хl больше или меньше (в зависимости от метода сравнения) показателя качества признака хs.
Сравнение апостериорных вероятностей. Пусть задан алфавит классов Ωi, i = l, ..., m, выбран априорный словарь признаков xj, j = 1, ..., Na, известны условные плотности распределений fi(хj) и априорные вероятности Р(Ωi). Требуется произвести сравнительную оценку признаков хl и хs, l,
s = 1, ..., Na, иначе — определить, какой из этих признаков обладает лучшими разделительными свойствами. Разделим диапазон изменения признака х, на интервалы D1i(xl); D2i(xl); ...; Dmi(xl), на которых отличны от нуля соответственно одна функция fi(хl); две функции fi(хl), ..., m функций fi(хl).
То же проделаем и с признаком xs, т. е. определим интервалы D1i(xs); D2i(xs)...; Dmi(xs). Вероятность получить однозначное решение равна
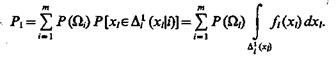 (1.37)
(1.37)
Вероятность получить двузначное решение вида «класс g или класс q», g, q = 1, ..., m, равна
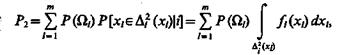 (1.38)
(1.38)
где D2i — совокупность интервалов, на которых отличны от нуля какие-либо две функции из набора fi(хl).
Вероятность получить m-значное решение вида «класс 1, или класс 2, ..., или класс m» равна
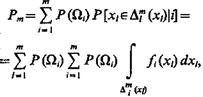 (1.39)
(1.39)
где Dmi(xl) — совокупность интервалов, на которых отличны от нуля все т функции fi(хl)., i = l, 2, ..., m.
Обозначив 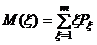 математическое ожидание случайной величины x, которая может принимать значения x=1, 2, ..., m с вероятностями Рx, определим указанное математическое ожидание для первого и второго признаков, т. е. Mxl(x) и Mxs(x). Если Mxl(x) >
математическое ожидание случайной величины x, которая может принимать значения x=1, 2, ..., m с вероятностями Рx, определим указанное математическое ожидание для первого и второго признаков, т. е. Mxl(x) и Mxs(x). Если Mxl(x) > ![]() (x), то признак хs обладает лучшими разделительными свойствами, если Mxs(x) > Mlx(x), то признак xl обладает лучшими разделительными свойствами. Будем полагать, что в первом случае выше качество признака хs, а во втором случае — признака хl.
(x), то признак хs обладает лучшими разделительными свойствами, если Mxs(x) > Mlx(x), то признак xl обладает лучшими разделительными свойствами. Будем полагать, что в первом случае выше качество признака хs, а во втором случае — признака хl.
Сравнение вероятностных характеристик признаков. Сравнительная оценка качества признаков может быть произведена и в случае, когда условные плотности распределений fi(хj) неизвестны, однако известны первые и вторые моменты этих распределений, т. е. mji и Dji. Оценка, основанная на использовании этих данных, возможна в связи с тем, что признаки хj могут быть условно подразделены на две группы.
К первой группе относятся признаки, значения которых незначительно изменяются при переходе от одного объекта данного класса к другому объекту и весьма заметно изменяются при переходе от объекта одного класса к объектам других классов.
Ко второй группе относятся признаки, значения которых чувствительны к переходам от одного объекта данного класса к другому объекту и лишь незначительно изменяются при переходах от объектов одного класса к объектам других классов.
Признаки, относящиеся к первой группе, полезней признаков, относящихся ко второй группе. Количественная оценка качества признаков xj, j = 1, 2, ..., N, может быть произведена следующим образом.
Пусть некоторый механизм вырабатывает значения j-го признака с вероятностями, равными априорным вероятностям Р(Ωi), i = 1, ..., m. Определим математическое ожидание некоторой фиктивной случайной величины, принимающей значения mji с вероятностями Р(Ωi), т. е.
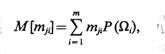 (1.40)
(1.40)
а также математическое ожидание дисперсии j-го признака по классам:
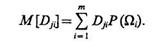 (1.41)
(1.41)
Если M[Dli] < M[Dsi], l, s = 1, ..., Na, то при прочих равных условиях качество признака xl выше, чем качество признака хl, так как вдоль оси признака xs объекты располагаются компактней, чем вдоль оси признака хs.
Дисперсия математического ожидания распределений признаков при переходе от класса к классу 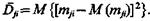 Если `Dli >`Dsi то при прочих равных условиях качество признака xl выше, чем качество признака хs, так как вдоль оси признака хl объекты, относящиеся к разным классам, располагаются на удалениях больших, чем вдоль оси признака xs. Геометрическая интерпретация сказанного прослеживается при рассмотрении рис. 1.2. (а, б).
Если `Dli >`Dsi то при прочих равных условиях качество признака xl выше, чем качество признака хs, так как вдоль оси признака хl объекты, относящиеся к разным классам, располагаются на удалениях больших, чем вдоль оси признака xs. Геометрическая интерпретация сказанного прослеживается при рассмотрении рис. 1.2. (а, б).
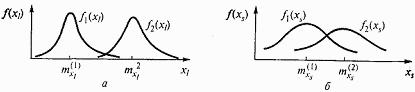
Рис. 1.2. Дисперсия математического ожидания признаков xl, xS
В качестве критерия сравнительной оценки признаков целесообразно использовать величину 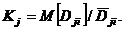
Будем полагать, что если Кl < Кs, то качество признака хl выше, чем качество признака хs при этом наилучший признак тот, который реализует ![]()
Информационный подход. Сравнительная оценка качества признаков xl и xs, l, s = 1, ..., Na, может быть произведена также на основе определения количества информации, которое получает система в процессе распознавания объектов в результате определения каждого из этих признаков.
Пусть распознаваемый объект может принадлежать лишь одному из m классов, априорные вероятности отнесения этого объекта к определенному классу обозначим Р(Ωj) i, j=1, 2, ..., m, а условные плотности распределения значений признаков — fj(xl), fj(xs).
До проведения экспериментов исходная априорная неопределенность состояния системы, или ее энтропия,
![]() (1.42)
(1.42)
Здесь логарифм может быть взят при любом основании а > 1. На практике удобнее пользо-ваться логарифмами при основании 2 и выражать энтропию в битах.
Определим, какое количество информации получает система распознавания при измерении признака xl.
Если признак xl принимает дискретные значения с вероятностями 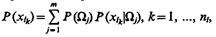
то полная условная энтропия системы распознавания при измерении всех возможных значений признака xl
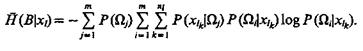 (1.43)
(1.43)
Если признак хl — непрерывный и его совместная плотность распределения — условная плотность распределения ![]() признака xl в Ωj-м классе), то значение полной условной энтропии системы после измерения признака xl
признака xl в Ωj-м классе), то значение полной условной энтропии системы после измерения признака xl
 (1.44)
(1.44)
где G — полная область изменения признака xl по всем классам; Gi — область изменения признака xl в Ωi-м классе.
Таким образом, если проведены эксперименты, связанные с определением признака xh и рассчитаны апостериорные вероятности отнесения объекта к соответствующим классам, то количество информации, которое получает система распознавания в результате проведения этих экспериментов, составит: если признак дискретный, то
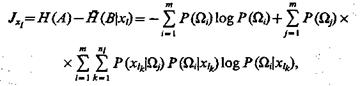 (1.45)
(1.45)
если признак непрерывный, то
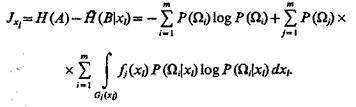 (1.46)
(1.46)
Аналогичные выражения могут быть получены и для признака хs. При этом будем полагать, что качество признака хl выше, чем качество признака хs в случае, если количество информации, связанное с определением признака xl больше, чем количество информации, связанное с определе-нием признака xs т. е. Jxl > Jxs. При этом имеем в виду следующее. Информативность признаков не является постоянной величиной и не представляет собой безусловной величины, а, наоборот, в общем случае количество информации, получаемое системой распознавания в результате измерения каждого данного признака, зависит от того, какие признаки были определены ранее и какие значения они приняли. Это в равной мере относится как к статистически зависимым, так и к статистически независимым признакам.
Пусть задан словарь признаков 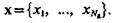 В общем случае
В общем случае
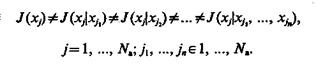 (1.47)
(1.47)
Применительно к статистически зависимым признакам, т. е. когда ![]() ут-верждение, содержащееся в (1.47), обсуждалось в публикациях по проблеме распознавания. В то же время применительно к статистически независимым признакам, т. е. когда
ут-верждение, содержащееся в (1.47), обсуждалось в публикациях по проблеме распознавания. В то же время применительно к статистически независимым признакам, т. е. когда 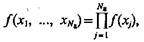 этот вопрос либо вообще не обсуждался, либо трактовался ошибочно.
этот вопрос либо вообще не обсуждался, либо трактовался ошибочно.
Статистическая независимость признаков распознаваемых объектов не является условием ни необходимым, ни достаточным для того, чтобы информативность признаков была величиной, не зависящей от того, какие признаки были определены на предыдущих шагах и какие при этом значения они приняли. Этот вопрос имеет не только теоретическое, но и практическое значение, так как если бы информативность признаков была величиной постоянной, то тогда не представ-ляло бы затруднений решить задачи: 1) минимизации описаний классов объектов на основе априорного определения группы наиболее информативных признаков, определяемых с помощью соотношений (1.45) и (1.46); 2) построения оптимального маршрута распознавания на основе априорного ранжирования признаков в соответствии с их информативностью.
При построении систем распознавания целесообразно априорно оценивать информативность каждого признака (в предположении, что он определен первым). Такая процедура позволяет, по крайней мере предварительно, определять, какие из признаков априорного словаря целесообразно исключить из дальнейшего рассмотрения. Окончательное решение, связанное с построением рабочего словаря признаков, может быть принято на основе общего подхода к проблеме.
Далее (см. юниту 3) будет подробно рассмотрен вопрос о глобальном оптимальном планировании процесса распознавания. Здесь же обсудим возможность использования для локальной оптимизации процесса распознавания информационного подхода.
Пусть оценена информативность всех признаков рабочего словаря, а также известна стоимость C(xj), j = l, ..., Np, определения признаков. На первой стадии экспериментов определяется такой признак из рабочего словаря (например, хk), который доставляет экстремальное значение функции L(xj) = J(xj)/C(xj), т. е.
![]() (1.48)
(1.48)
где J(xj) — количество информации, вносимое в систему распознавания измерением признака xj, усредненное по всему множеству его возможных значений.
Признак хk и надлежит измерить на первой стадии экспериментов. Далее в зависимости от того, какое конкретное значение принял признак хk = х*k, определяется такой признак, например, xh, который в среднем по всему множеству его значений доставляет экстремум функции ![]() т. е.
т. е.
![]() (1.49)
(1.49)
Аналогично определяются третья и последующие стадии экспериментов. При этом на каждом шаге целесообразно проверять, не превзойден ли заданный уровень вероятности отнесения неизвестного объекта к какому-либо классу. Если это произошло, то целесообразно дальнейшее проведение экспериментов прекратить.
1.6. Построение рабочего словаря признаков при отсутствии
априорного словаря признаков
Выше были рассмотрены методы определения признакового пространства при ограничениях на стоимость его реализации и методы сравнительной оценки признаков, возможность применения которых связана с наличием априорного словаря признаков. Однако в практике построения систем распознавания приходится сталкиваться с ситуациями, когда априорный словарь признаков неиз-вестен, а дана лишь некоторая совокупность реализаций сигналов, характеризующих явления или процессы, для распознавания которых предназначена разрабатываемая система. К таким сигналам могут быть отнесены, например, сигналы звуковые, возникающие в процессе работы некоторых тех-нических устройств, радиолокационные или световые, отраженные от каких-либо объектов, элект-рические, возникающие при электрокардиографических или энцефалографических исследова-ниях, и т. д. В подобных ситуациях возникает следующая задача: на основе совокупности сигналов, характеризующих каждый класс объектов или явлений, определить и упорядочить признаки, припи-сывая больший вес признаку, несущему больше информации при различении объектов или явлений.
Решение этой задачи на основе разложения Карунена—Лоэва состоит в следующем. Пусть множество объектов или явлений подразделено на классы Ωi, получена совокупность реализаций сигналов xi(t) на интервале 0 £ t £ T, характеризующая классы, известна априорная вероятность появления объектов Р(Ωi), i = 1, ..., m, и сигналы хi(t) представляют собой случайные функции. Положим, что функции обладают разложением
![]() (1.50)
(1.50)
где Vik — случайные коэффициенты, математическое ожидание которых M(Vik) = 0; {jk(t)} —множество детерминированных ортонормированных координатных функций на интервале (0, Т). Корреляционная функция случайных процессов, описывающих классы Ωi, i = l, ..., m,
![]() (1.51)
(1.51)
Подставив (1.50) в (1.51), получим
(1.52)
Пусть случайные коэффициенты Vik удовлетворяют условиям
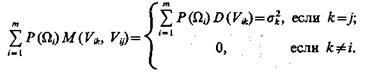 (1.53)
(1.53)
Тогда (1.53) приобретает вид:
 (1.54)
(1.54)
или
(1.55)
Если можно поменять местами суммирование и интегрирование, то (1.55) запишется так:
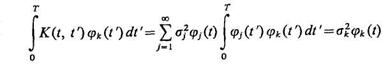 . (1.56)
. (1.56)
Разложение (1.50), в котором функции jk(t) определяются согласно (1.55) или (1.56) через корреляционную функцию K(t, t'), называется обобщенным разложением Карунена—Лоэва.
Искомое признаковое пространство (координатная система) образуется в результате решения интегрального уравнения Фредгольма второго рода (1.56), ядро которого — корреляционная функция K(t, t') случайных процессов хi(t), описывающих классы Ωi, i = l, ..., m, на интервале наблюдения [0, T] относительно координатных функций jk(t), k = l, 2, ... .
При упорядочении координатных функций jk(t) в порядке убывания соответствующих им собственных значений s2k коэффициенты разложения случайных процессов Vik обладают также в порядке убывания наилучшими разделительными качествами, т. е. вносят в систему большее количество информации. Это означает следующее. Пусть координатным функциям jr(t) и jl(t) соответствуют значения дисперсий s2r и s2l и при этом s2r > s2l, k, r, l = 1, 2, ... . Тогда признак хr обладает лучшими разделительными свойствами, чем признак хl. Использование признака хr вносит в систему распознавания больше информации, чем использование признака хl. Заметим, что s2k представляют собой дисперсию математического ожидания распределений найденных признаков (k = 1, 2, ...) при переходе от класса к классу (см. п. 1.5).
Построение признакового пространства системы распознавания на основе коэффициентов разложения Карунена — Лоэва обеспечивает минимизацию начальной энтропии системы, определяемой величиной Р(Ωi) i = 1,..., m. При этом среднеквадратичная ошибка, возникающая за счет того, что реальное признаковое пространство системы реализуется на основе конечного числа признаков, минимальна.
Пример. Пусть дана совокупность реализаций сигналов, принадлежащих классам ![]() и
и ![]() . Будем полагать, что сигналы описывают эргодические случайные стационарные процессы. Выполнено усреднение по множеству реализаций, относящихся к каждому классу, и построены корреляционные функции
. Будем полагать, что сигналы описывают эргодические случайные стационарные процессы. Выполнено усреднение по множеству реализаций, относящихся к каждому классу, и построены корреляционные функции ![]() (t) и
(t) и ![]() (t). Последние будем рассматривать в качестве описаний классов (рис. 1.3).
(t). Последние будем рассматривать в качестве описаний классов (рис. 1.3).
Корреляционные функции ![]() (t) и
(t) и ![]() (t) представим в виде набора числовых значений, относящихся к дискретным моментам времени, а затем применительно к
(t) представим в виде набора числовых значений, относящихся к дискретным моментам времени, а затем применительно к ![]() (t) и
(t) и ![]() (t) выполним обобщенное разложение Карунена—Лоэва. В результате найдем, что суммарное значение дисперсии
(t) выполним обобщенное разложение Карунена—Лоэва. В результате найдем, что суммарное значение дисперсии ![]() , при этом два члена разложения (20-й и 44-й) обеспечивают значение дисперсий s220 + s244 = 0,83, что составляет 97,7% от суммарного значения дисперсии.
, при этом два члена разложения (20-й и 44-й) обеспечивают значение дисперсий s220 + s244 = 0,83, что составляет 97,7% от суммарного значения дисперсии.
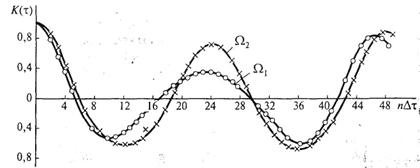
Рис. 1.3. Корреляционные функции для классов ![]() и
и ![]()
Это дает основание признаковое пространство проектируемой системы распознавания строить с использованием только двух признаков, которые обозначим x1 и х2. При этом оценки математических ожиданий и дисперсий признаков по классам ![]() и
и ![]() соответственно равны:
соответственно равны:
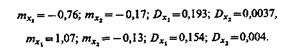
На рис. 1.4. (а, б) показаны гистограммы, представляющие собой описания классов на языке признаков x1 и х2. Из рисунков видно, что признак х1 обладает лучшими разделительными свойствами, чем признак х2 (действительно, s21 » 0,8, в то время как D22 » 0,03).
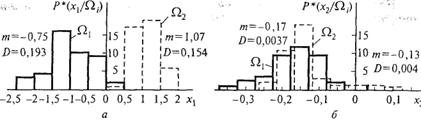
Рис. 1.4. Гистограммы описания классов на языке признаков x1 и x2
2. ВЫЧИСЛИТЕЛЬНЫЕ МЕТОДЫ АЛГЕБРЫ ЛОГИКИ
Применение методов алгебры логики необходимо тогда, когда существенны не только количественные соотношения между величинами, характеризующими рассматриваемые процессы, но и связывающие их логические зависимости. При распознавании объектов эти методы используют в случаях, когда: 1) отсутствуют сведения о количественном распределении объектов по пространственным, временным, весовым, энергетическим или каким-либо другим интервалам в соответствующем пространстве признаков, а имеются лишь детерминированные логические связи между рассматриваемыми объектами и их признаками; 2) известны распределения объектов в пространстве признаков, законы распределения ошибок измерения величин, характеризующих отдельные объекты, но логические зависимости, связывающие признаки и классы объектов, сложны и не поддаются непосредственному анализу.
Примерами задач, для решения которых требуется применение методов алгебры логики, являются: распознавание типа объекта на основе данных наблюдения и известных априорных зависимостей между типами объектов и соответствующими признаками; установление различных совокупностей признаков распознаваемого объекта, учет которых наряду с уже известными приводил бы к определенному заключению о типе объекта; анализ информации, содержащейся в каком-либо докладе или сообщении и относящейся к определенным типам объектов, с целью определить, какие выводы можно сделать о данных объектах на основании полученного сообще-ния; выбор технической политики предприятия, направленной на достижение определенного экономического эффекта, если известны некоторые общие закономерности, связывающие, например, отдельные изменения в области технологии производства с расходами на рекламу, наличием запасов сырья и товаров, уровнем производительности труда, снижением себестоимости продукта и объемом сбыта; прогноз погоды; геологическая разведка; выявление закономерностей, связывающих определенные типы объектов и их признаки (задача обучения), и др.
2.1. Основные понятия алгебры логики
Алгебра логики — не пустое множество элементов, являющееся ее областью, вместе с неко-торым заданным набором операций, которые можно совершать над элементами, не выходя за пределы области. (Алгебра логики впервые была исследована Дж. Булем). Область алгебры логики состоит из множества высказываний — законченных предложений, которые могут иметь одно из двух значений истинности: либо быть истинными, либо быть ложными. Высказывания — элементы области алгебры логики, и поэтому, наряду со словом «высказывание», далее часто будет употребляться термин «элемент». Например, высказывание «пять — четное число» — ложное, а высказывание «логика — наука о законах мышления» — истинное. Высказывания обозначаются буквами А, В, С, ..., К, X, Y; А1 А2, ..., В1, В2, ... .
В качестве операций над высказываниями, с помощью которых из данных высказываний можно получить новые, в алгебре логики используют конъюнкцию (логическое умножение), дизъюнкцию (логическое сложение), отрицание.
Конъюнкция ¾ операция логического умножения, совершаемая, по крайней мере, над двумя высказываниями и соответствующая комбинации этих высказываний с помощью слова «и»; обозначается знаком «×», например А × В читается «А и В». Высказывание А × В истинно тогда и только тогда, когда истинны высказывания А и В одновременно. Например, конъюнкция двух высказываний (самолет — это летательный аппарат) × (прямое попадание мощного снаряда в цель приводит к поражению цели) истинна, тогда как конъюнкция (три — четное число) · (применение танков целесообразно) ложна.
Дизъюнкция ¾ операция логического сложения, совершаемая, по крайней мере, над двумя высказываниями и соответствующая объединению этих высказываний с помощью слова «или»; обозначается знаком «+», например А + В читается «А или B». Высказывание А + В истинно, когда истинно либо только высказывание А, либо только высказывание В, либо истинны высказывания А и В одновременно. Например, дизъюнкция (танки могут остановить наступление пехоты) + (собака — насекомое) истинна. Высказывание А + В ложно тогда и только тогда, когда высказывание А ложно и высказывание В ложно.
Отрицание ¾ операция, совершаемая над одним высказыванием и обозначаемая чертой над буквой, например А, читается «не А» Высказывание `A истинно тогда и только тогда, когда высказывание А ложно.
В результате применения конъюнкции, дизъюнкции и отрицания к некоторому исходному набору элементов А, В, С, ... возникают новые комбинированные элементы X, Y, ..., которые называются булевыми функциями от элементов А, В, С, ... . Чтобы подчеркнуть зависимость функций от данных элементов, часто пишут: Х(А, В, С, ...), Y(A, В, С, .
Рассмотрим две особо важные булевы функции: `А + В и А · В + ![]() ·
· ![]() выражающие опреде-ленные связи между элементами А и В.
выражающие опреде-ленные связи между элементами А и В.
Импликация (следование). Пусть высказывание `А + В истинно. Тогда в соответствии с определением дизъюнкции и отрицания заключаем, что если А истинно, то В тоже истинно, если В ложно, то А тоже ложно. Однако если В истинно, то А может быть как истинно, так и ложно. Такая зависимость между А и В называется импликацией, записывается в виде А® В и читается «если А, то В» или «из А следует В».
Эквивалентность. Пусть высказывание А × В +`А ×`В истинно. Тогда из определения операций над высказываниями следует, что А и В имеют одинаковые значения истинности, т. е. либо оба истинны, либо оба ложны. Такая зависимость между А и В называется эквивалентностью, записывается в виде А — В и читается «А эквивалентно В». Если А = В, то, какова бы ни была булева функция f(A, U, V, ...), справедливо соотношение f(B, U, V, ...) =f(B, U, V, ...), что можно записать в виде
![]() (2.1)
(2.1)
Среди всех булевых функций можно выделить функции, остающиеся истинными, безотносительно к тому, какие значения истинности принимают входящие в эти функции элементы, например 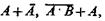 а также (2.1). Такие функции называют универсально истинными или тавтологиями. Так как все тавтологии не различаются между собой с точки зрения значений истинности, то их обозначают I. Следовательно, можно записать
а также (2.1). Такие функции называют универсально истинными или тавтологиями. Так как все тавтологии не различаются между собой с точки зрения значений истинности, то их обозначают I. Следовательно, можно записать ![]() и т. д. Отрицание 1, т. е. `1 — универсально ложный элемент; обозначается 0. Для любых X соотно-шения
и т. д. Отрицание 1, т. е. `1 — универсально ложный элемент; обозначается 0. Для любых X соотно-шения ![]() — тавтологии, так как не зависят от значения истинности X.
— тавтологии, так как не зависят от значения истинности X.
Необходимо отличать тавтологически истинные элементы от функций, которые истинны вследствие сделанных предположений или физических законов. Первые не несут никакой полез-ной информации, в то время как вторые накладывают определенные связи на входящие в них элементы. Например, если применительно к некоторой проблеме утверждается, что функция ![]() + В должна рассматриваться как истинная, т. е. `А + В = `1, то, как указывалось, это эквивалентно связи А®В. Аналогичный пример дает соотношение эквивалентности (А·В +`А·`В =`1) = (А = В). В дальнейшем будут рассматриваться другие возможные формы связей.
+ В должна рассматриваться как истинная, т. е. `А + В = `1, то, как указывалось, это эквивалентно связи А®В. Аналогичный пример дает соотношение эквивалентности (А·В +`А·`В =`1) = (А = В). В дальнейшем будут рассматриваться другие возможные формы связей.
Основные правила алгебры логики следующие:
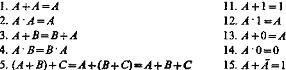

Данные формулы должны рассматриваться как тавтологии. Их справедливость может быть проверена вычислением значений истинности сложных высказываний в левой и правой частях равенства. Некоторые из этих формул могут быть выведены из других форм, 6, 7, 12, 15 и 17 следующим образом:
![]()
![]()
![]()
2.2. Изображающие числа и базис
Булева функция считается заданной, если можно указать значения истинности этой функции при всех возможных комбинациях значений истинности входящих в нее элементов. Таблицу, которая представляет все возможные комбинации значений истинности некоторого набора элементов А, В, С, ..., называют базисом. Если значение «истина» обозначить 1, а значение «ложь» — 0, то для одного элемента А базис содержит 21 колонок:
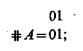
для двух элементов А, В — 22 колонок:
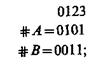
для трех элементов А, В, С — 23 колонок:

и вообще для n элементов А1 ..., Аn базис содержит n строк и 2 колонок. Если колонки базиса рассматривать как целые двоичные числа, записанные так, что самый младший разряд их соответствует первой строке базиса, а самый старший — последней строке, то колонки базиса для n элементов представляют собой числа от 0 до 2n— 1. Будем считать эти числа номерами колонок базиса и отметим сверху каждую колонку ее номером. Если колонки базиса упорядочены и записаны в возрастающем порядке их номеров слева направо, то получим стандартный базис, все другие базисы — нестандартные. Для n элементов существует столько базисов, сколько можно составить перестановок из 2n колонок, т. е. (2n)! Стандартный базис для элементов А, В, С, ... обозначается b[А, В, С, ...], причем порядок элементов в квадратных скобках совпадает с порядком строк базиса.
Строки базиса называют изображающими числами соответствующих элементов и обозначают приписыванием слева от элемента знака #. Заметим, что по отношению к стандартному базису b[А, В, С, В] изображающее число ФА состоит из чередующихся нулей и единиц, #В — из пар нулей и пар единиц, # С — из четверок нулей и четверок единиц и т. д., т. е. #D = 011.
Используя базис, можно явным образом перечислить все значения истинности булевой функции при всех возможных комбинациях значений истинности элементов, от которых она зависит. Для этого необходимо ввести некоторые операции над изображающими числами элементов, соответствующие операциям над высказываниями.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
