
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
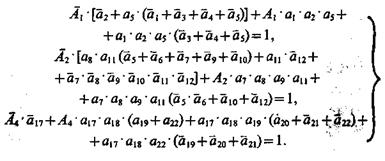 (3.38)
(3.38)
Уравнения (3.38) совместно с (3.23), (3.34), (3.37) эквивалентны исходным соотношениям (3.23) — (3.37). Следствием уравнений (3.38), (3.23) являются соотношения
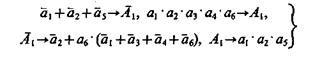 (3.39)
(3.39)
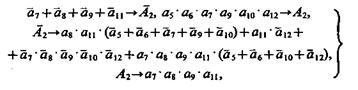 (3.40)
(3.40)
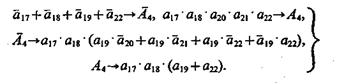 (3.41)
(3.41)
Опираясь на соотношения (3.39) — (3.41) и (3.34), (3.37), можно находить решения задач 1 — 3. Например, если в задаче 1
![]()
![]()
Если в задаче 2 функция Х=`А3 × `А5, то
![]()
т. е. цели А3 и А5 не достигнуты из-за того, что не выполнены какие-либо из мероприятий а13 и а23, а13 и а24 и т. д. Если в задаче 3 Y = A1 × A2 × A3 × A4 × А5, то
![]()
т. е. для достижения состояния, представленного функцией Y, достаточно дополнительно добиться выполнения совокупности мероприятий a13 — a16 и т. п.
3.4. Распознавание объектов в условиях их маскировки
Маскировка — один из основных методов снижения эффективности разведки противника в общем комплексе мероприятий по противодействию. Решение проблемы маскировки требует привлечения, с одной стороны, специалистов инженерного профиля для выработки предложений по выбору эталонов маскировочных моделей объектов и применению конкретных технически реализуемых средств маскировки и, с другой стороны, специалистов в области исследования операций для оценки эффективности предлагаемых инженерных решений и определения наилучшей при данных условиях тактики использования маскировочных средств.
Предположим, что требуется замаскировать объекты классов Ω1 и Ω2 под объекты классов Ω3 и Ω4. Допустим также что, рассуждая за вероятного противника, удалось составить описание распознаваемых противником объектов классов Ω1, Ω2, Ω3 , Ω4, с точки зрения совокупности признаков, выраженных через элементарные высказывания A, В, С следующего вида:
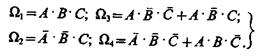 (3.42)
(3.42)
Добавляя к (3.42) уравнение
(3.43)
где f(А, В, С) — булева функция, представляющая собой данные разведки, полученные противни-ком при попытке выявить признаки объектов классов Ω1, Ω2, Ω3, Ω4, а j(Ω1, Ω2, Ω3, Ω4) — неизвестная функция.
Формально сводим задачу распознавания объектов классов Ω1, Ω2, Ω3, Ω4 к нахождению решения j (Ω1, Ω2, Ω3, Ω4) систем (3.42) и (3.43). Вид функции j(Ω1, Ω2, Ω3, Ω4) существенно зависит от объема и качества информации, получаемой о распознаваемом объекте. И объем, и качество информации можно охарактеризовать условными вероятностями правильного y(1|1), q(0|0), ошибочного q(0|1), q(1|0) и неопределенного q(´|0), q(´|1) ответов при попытке установить значения истинности признаков А, В, С, когда фактически высказывания А, В, С истинны (1) и когда они ложны (0):
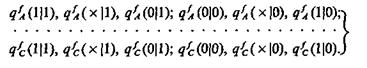 (3.44)
(3.44)
Рассматриваемые способы маскировки будут отличаться значениями вероятностей (3.44), что отмечается индексом f у величин q.
Предположим, что оцениваются следующие варианты маскировки (табл. 3.1).
Таблица 3.1
Варианты маскировки
![]()
где ![]() — объекты классов Ω3 и Ω4 соответственно. Ω1½Ω1 означает, что объекты класса Ω1 не маскируются; f13½Ω1 означает, что объекты класса Ω1 маскируются под объект f13 из класса Ω3, и т. д.
— объекты классов Ω3 и Ω4 соответственно. Ω1½Ω1 означает, что объекты класса Ω1 не маскируются; f13½Ω1 означает, что объекты класса Ω1 маскируются под объект f13 из класса Ω3, и т. д.
Варианты f14½Ω1 и f13½Ω2 не рассматриваются, так как технически невыполнимы. Таким обра-зом, существуют 16 различных способов маскировки объектов Ω1 и Ω2, которые получаются при комбинации элементов первой строки таблицы с элементами второй строки.
Пусть эти способы перенумерованы и j = 1, ..., 16 обозначает номер способа. Каждому значе-нию j отвечает определенный набор вероятностей (3.44). Будем считать, что маскировка эффектив-на, если решение задачи распознавания объектов класса Ω1 или Ω2 таково, что ![]() и неэффективна, если при распознавании объектов класса Ω1 или Ω2 j®Ω1 + Ω2. Имеется еще третья возможность — получить неопределенное решение, например, вида
и неэффективна, если при распознавании объектов класса Ω1 или Ω2 j®Ω1 + Ω2. Имеется еще третья возможность — получить неопределенное решение, например, вида ![]()
Рассмотрим вероятности получения решений указанных типов при выбранном способе маскировки и определенном маскируемом объекте:
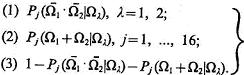 (3.45)
(3.45)
Вероятности (3.45) зависят от значений вероятностей (3.44). Конкретный вид зависимости может быть установлен на основании соотношений (3.42). Предполагая независимость признаков А, В, С, найдем:
(3.46)
При большом количестве признаков, привлекаемых для распознавания объектов, прямое вычисление вероятностей (3.46) затруднительно. В этом случае можно использовать метод статистических испытаний.
Пусть С1lj, С2lj, С3lj — весовые коэффициенты, характеризующие относительные выигрыши в случае, когда распознаваемый объект в действительности является объектом типа Ωl, применен
j-й способ маскировки (j = 1,..., 16) и получено решение вида 1, 2 или 3, что отмечается верхним индексом у величин С1lj. Величина
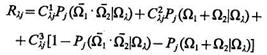 (3.47)
(3.47)
представляет собой средний выигрыш на одно решение при зафиксированном способе маскировки.
Обозначим x1, х2 относительные частоты появления объектов типа Ω1, Ω2, соответственно, a yj, j = 1,..., 16, — относительные частости, с которыми применяется один из способов маскировки. Тогда
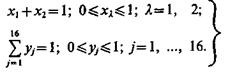 (3.48)
(3.48)
Безусловный средний выигрыш на одно решение
![]() (3.49)
(3.49)
где Rlj и хl — по предположению, известные количества.
Задача по определению наилучшей тактики при маскировке объектов классов Ω1, Ω2 сводится к нахождению таких значений y*j, j = 1, ..., 16, при которых величина R, заданная (3.49), достигает максимума и не нарушаются ограничения (3.48). Это стандартная задача линейного программ-мирования, решение которой в приведенной постановке тривиально и сводится к нахождению наибольшего коэффициента при переменных yj в линейной форме (3.49), причем соответствующее y*j0 = l. Последнее показывает, что при данных условиях существует единственный оптимальный способ маскировки объектов.
Если ввести в рассмотрение дополнительные ограничения, например, по стоимости маскиро-вочных мероприятий, расходам дефицитных материалов и т. д., вида ![]() то оп-тимальное решение задачи линейного программирования может содержать более чем одно поло-жительное y*j. Следовательно, в этом случае наилучшая тактика при маскировке объектов заключается в случайном выборе различных способов с частостями y*j.
то оп-тимальное решение задачи линейного программирования может содержать более чем одно поло-жительное y*j. Следовательно, в этом случае наилучшая тактика при маскировке объектов заключается в случайном выборе различных способов с частостями y*j.
3.5. Распознавание в условиях противодействия
Рассмотрим задачу распознавания объектов в условиях, когда противник может препятство-вать как выявлению отдельных признаков объектов, так и сознательно изменять свою тактику в отношении частости предъявления объектов различных классов распознающей стороне. Пусть
требуется построить систему для распознавания объектов классов Ω1 и Ω2 =`Ω1, которые описы-ваются признаками А1, А2, А3, А4, в виде
![]() (3.50)
(3.50)
Добавив в (3.50) уравнение
![]() (3.51)
(3.51)
придем к стандартной задаче определения неизвестной функции j(Ω1, Ω2) при заданной функции f(A1, A2, А3, А4).
Предположим, что имеется четыре пары распределения случайных величин Xj, заданных через плотности вероятностей fi(xj), i = l, 2; j = 1, ..., 4 (рис. 3.2).
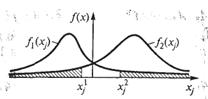
Рис. 3.2. Плотности вероятностей распределения четырех пар случайных величин Xj
Элемент Aj обозначает высказывание «измеренное значение x*j случайной величины Xj относит-ся к распределению f1(xj)», а элемент `Aj — высказывание «x*j, относится к распределению f2(хj)».
Условимся считать, что имеет место элемент Aj, когда x*j<х1j, и элемент ![]() когда x*j>x2j. Если же
когда x*j>x2j. Если же ![]() то значение истинности элемента Aj остается неопределенным относи-тельно принадлежности x*j к распределениям f1(xj) и f2(xj) и не делается никаких заключений.
то значение истинности элемента Aj остается неопределенным относи-тельно принадлежности x*j к распределениям f1(xj) и f2(xj) и не делается никаких заключений.
В соответствии с данным правилом определим вероятности:
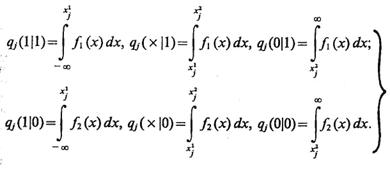 (3.52)
(3.52)
Предположим, что противодействие распознаванию объектов со стороны противника выража-ется в том, что, во-первых, вероятности (3.52) связаны определенными соотношениями вида
![]() (3.53)
(3.53)
ограничивающими область допустимых значений qj, и, во-вторых, если h и 1-h — частоты, с которыми противник предъявляет объекты из классов Ω1 и Ω2 соответственно, то значение h может произвольно изменяться в пределах 0£h£ 1.
Так как противник располагает двумя стратегиями (1 — предъявлять только объекты из класса Ω1; 2 — предъявлять объекты только из класса Ω2), то естественно попытаться расширить арсенал стратегий стороны, проводящей распознавание, и наряду со стратегией 1 классификации объектов, выраженной соотношениями (3.50), (3.51) и
![]() (3.54)
(3.54)
ввести в рассмотрение стратегию 2, которая заключается в следующем:
![]() (3.55)
(3.55)
т. е. принимаем, что распознаваемый объект относится к классу Ω2, если решение уравнений (3.51), (3.52) есть j = Ω1 точно так же считаем, что объект принадлежит классу Ω1, если решение уравнений есть j = Ω2.
Сведем рассматриваемую задачу по определению наилучших стратегий сторон к игре (2 ´ 2). Запишем (3.50) в СДНФ:
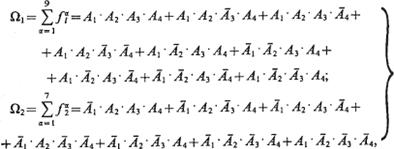 (3.56)
(3.56)
где f11= A1 × A2 × A3 × A4, ..., f91 = Al×![]() ×
×![]() ×А4; f12 = `A1 × A2 × A3× A4, ..., f72 = A1 × `A2 ×`А3 ×`A4 — различные типы объектов из классов Ω1 и Ω2. В соответствии с (3.50) найдем для стратегии 1:
×А4; f12 = `A1 × A2 × A3× A4, ..., f72 = A1 × `A2 ×`А3 ×`A4 — различные типы объектов из классов Ω1 и Ω2. В соответствии с (3.50) найдем для стратегии 1:

Обозначим rai, i = 1, 2, вероятность появления объекта типа fai в классе Ωi. Тогда условные вероятности правильных и ошибочных заключений о классе объектов при использовании стратегии 1
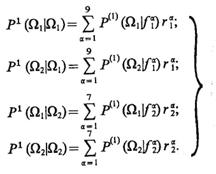 (3.57)
(3.57)
Если распознающей стороне предъявляется объект из класса Ωi, то помимо решений j = Ω1 и j = Ω2 возможны неопределенные ответы, когда класс объекта не устанавливается. Условная вероятность получить неопределенное решение задачи распознавания есть
![]() (3.58)
(3.58)
Пусть величины С1i, С2i, С3i, i=1, 2, обозначают выигрыши, которые получает распознающая сторона за правильное, ошибочное и неопределенное решение задачи распознавания при условии, что предъявлен объект из класса Ωi. Тогда средние условные выигрыши распознающей стороны при использовании стратегии 1
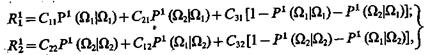 (3.59)
(3.59)
а при использовании стратегии 2, выраженной соотношениями (3.55), выигрыши
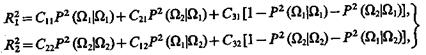 (3.60)
(3.60)
где, согласно (3.55),
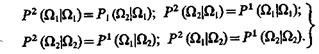 (3.61)
(3.61)
Будем считать, что величины (3.58) и (3.59) образуют платежную матрицу игры размерностью (2 ´ 2) с нулевой суммой:
 (3.62)
(3.62)
в которой «чистые» стратегии распознающей стороны состоят в том, чтобы: а) применять стратегию 1; б) применять стратегию 2. А «чистые» стратегии «противника» есть: а) предъявлять объекты класса Ω1; б) предъявлять объекты класса Ω2.
Обозначим (x, 1 — x), 0 £ x £ 1, смешанные стратегии распознающей стороны, ранее введенные величины (h, l—h), 0 £ h £ 1, являются смешанными стратегиями противника. Игра, представленная
платежной матрицей (3.62), всегда имеет решение (x0, h0) либо в «чистых», либо в смешанных стратегиях:
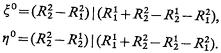 (3.63)
(3.63)
Средний выигрыш R(x, h) распознающей стороны при оптимальных стратегиях x = x0, h = h0 есть
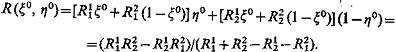 (3.64)
(3.64)
С точки зрения стороны, распознающей объекты, величины х1j, х2j = 1, 2, 3, 4, должны быть выбраны так, чтобы обеспечивался максимальный средний выигрыш max R(x0, h0) при ограни-чениях, заданных (3.53).
3.6. Алгоритмы распознавания, основанные на вычислении оценок
Логические алгоритмы распознавания, рассмотренные выше, в ряде случаев не позволяют полу-чить однозначное решение о принадлежности распознаваемого объекта к определенному классу. предложен класс алгоритмов, называемый алгоритмами распознавания, основанными на вычислении оценок (алгоритмами АВО), который дает возможность получить однозначное решение о принадлежности объекта к определенному классу.
Пусть множество объектов {ω} подразделено на классы Ωi, i = 1, ..., m, и для описания объектов используются признаки хj, j = 1, ..., N. Все объекты описываются одним и тем же набором приз-наков. Каждый из признаков может принимать значения из различных множеств, например, из следующих: {0, 1}, 0 — признак не выражен, 1 — признак выражен; {0, 1, ´}, ´ — информация о признаке отсутствует; {0, 1, ..., d} — степень выраженности признака имеет различные градации; [а, b] — признак принимает значения из числового отрезка; fi(x1 ..., xN) — условная плотность распределения значений признаков. Априорная информация представляется в виде таблицы, содержащей описания на языке признаков {х1, ..., xN} всех объектов, принадлежащих различным классам (табл. 3.1). Алгоритм распознавания сравнивает описание распознаваемого объекта с описаниями всех объектов, содержащихся в таблице, и принимает решение о том, к какому классу отнести объект. Классификация основана на вычислении степени похожести (оценки) распознава-емого объекта, на объекты, принадлежность которых к классам известна. Эта процедура включает в себя два этапа: сначала подсчитывается оценка для каждого объекта из таблицы, а затем полученные оценки используются для получения суммарных оценок по каждому из классов Ωi.
Опыт решения задач распознавания свидетельствует о том, что часто основная информация заключена не в отдельных признаках, а в их различных сочетаниях. Так как не всегда известно, какие именно сочетания информативны, то в АВО степень похожести объектов вычисляется не последовательным сопоставлением отдельных признаков, а сопоставлением всех возможных (или определенных) сочетаний признаков, входящих в описание объектов.
Рассмотрим полный набор признаков х = {х1, ..., xN} и выделим систему подмножеств множества признаков (систему опорных множеств алгоритма) S1, ..., Sl. В АВО при наличии огра-ничений на систему опорных множеств обычно рассматриваются либо все подмножества множества признаков фиксированной длины k, k=2,..., N—1, либо вообще все подмножества множества признаков.
Удалим произвольный поднабор признаков из строк ω1, ω2,..., ωrm, ω¢ и обозначим полученные строки Sω1, Sω2,..., Sωrm, Sω¢. Правило близости, позволяющее оценить похожесть строки Sω¢, соответствующей распознаваемому объекту ω¢, и строки Sωri-l+v, соответствующей произвольному объекту исходной таблицы, состоит в следующем (индекс n-гo объекта класса Ωi, представляет собой сумму порядкового номера последнего объекта предшествующего класса Ωi-1 — ri-1 и порядкового номера n рассматриваемого объекта в данном классе Ωi; естественно, 1 £ n £ ri-ri-1. Пусть «усеченные» строки содержат q первых признаков, т. е. 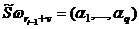 и
и 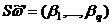 , и заданы пороги e1 ..., eq, d.
, и заданы пороги e1 ..., eq, d.
Строки ![]() и
и ![]() cчитаются похожими, если выполняется не менее чем d неравенств вида
cчитаются похожими, если выполняется не менее чем d неравенств вида ![]()
Величины e1 ..., eq входят в качестве параметров в АВО (табл. 3.2).
Таблица 3.2
Выделение столбцов, соответствующих признакам, входящим в S1
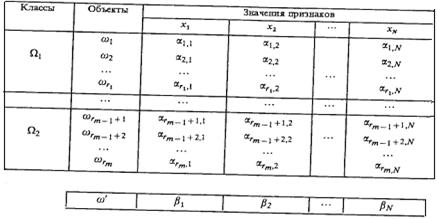
Рассмотрим процедуру вычисления оценок по подмножеству S1. Для остальных подмножеств она полностью аналогична. В табл. 3.2 выделяются столбцы, соответствующие признакам, входящим в S1, а остальные столбцы вычеркиваются. Проверяется близость строки S1ω¢ со строками S1ω1 ..., S1 ωr1, принадлежащими объектам класса Ωi. Число строк этого класса, близких по выбранному критерию классифицируемой строки S1ω¢, обозначается Гs1(ω¢, Ω1); последняя величина представляет собой оценку строки ω¢ для класса Ωi по опорному множеству S1. Аналогичным образом вычисляются оценки для остальных классов: Гs2(ω¢, Ω2), ..., Гs2(ω¢, Ωm). Применение подобной процедуры ко всем остальным опорным множествам алгоритма позволяет получить систему оценок Гs2 (ω¢, Ω1), ..., Гs2 (ω¢, Ωm), ..., Гsl (ω¢, Ω1)..., Гsl (ω¢, Ωm). Величины
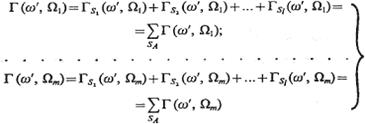 (3.65)
(3.65)
представляют собой оценки строки ω¢ для соответствующих классов по системе опорных множеств алгоритма SA. На основании анализа этих величин принимается решение либо об отнесении объекта ω¢ к одному из классов Ωi, i = 1,..., m, либо об отказе от его распознавания. Решающее правило может принимать различные формы, в частности распознаваемый объект может быть отнесен к классу, которому соответствует максимальная оценка, либо эта оценка будет превышать оценки всех остальных классов не меньше чем на определенную пороговую величину h1, либо значение отношения соответствующей оценки к сумме оценок для всех остальных классов будет не менее значения порога h2 и т. д. Параметры типа hх и h2 также включаются в АВО.
Пример. Заданы следующая таблица обучения и подлежащий распознаванию объект ω¢ (табл. 3.3).
Таблица 3.3
Таблица обучения и подлежащий распознаванию ω¢
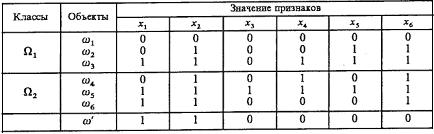
Пусть S1 = <x1, x2,>, S2 = <x3, x4>, S3 = <x5, x6>; строки будем считать близкими, если они полностью совпадают.
Применение вышеописанной процедуры вычисления оценок позволяет получить следующее:
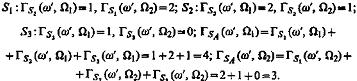
Согласно решающему правилу, реализующему принцип простого большинства голосов, объект соотносится к классу Ωi так, как Г(ω¢, Ω1) > Г(ω¢, Ω2).
Последовательность реализации процедуры распознавания в соответствии с АВО такова: 1) вы-деляется система опорных множеств алгоритма, по которым производится анализ распознаваемых объектов; 2) вводится понятие близости на множестве частей описаний объектов; 3) задаются правила: а) позволяющие по вычисленной оценке степени подобия эталонного и распознаваемого объекта вычислить величину, называемую оценкой для пар объектов; б) формирования оценок для каждого из классов по фиксированному опорному множеству на основе оценок для пар объектов; в) формирования суммарной оценки для каждого из классов по всем опорным подмножествам; г) при-нятия решения, которое на основе оценок для классов обеспечивает отнесение распознаваемого объекта к одному из классов или отказывает ему в классификации.
Способ выбора системы опорных множеств, тип функции близости, правила вычисления оце-нок и решающие правила определяют АВО, а задание значений соответствующих параметров — конкретный алгоритм. Варьируя способ выбора и параметры, можно добиться определения такого АВО, который обеспечивает наилучшее решение задачи распознавания (например, с точки зрения минимума ошибок и отказов от распознавания).
Организация вычислительной процедуры непосредственно в соответствии с приведенным описанием алгоритма при большой мощности системы опорных множеств требует значительного числа машинных операций. В связи с этим для вычисления оценок, определяющих принадлеж-ность распознаваемого объекта некоторому классу, выведены простые аналитические формулы, заменяющие сложные переборные процедуры.
Остановимся на аналитических формулах, обеспечивающих эффективное вычисление оценок Гi(ω¢) при различных способах задания системы опорных множеств АВО:
1. Эффективные формулы при наличии ограничений на систему опорных множеств:
a) SA совпадает с системой всех подмножеств мощности к множеству {х1 ..., xN}:
![]() (3.66)
(3.66)
где р(ωr, ω¢) — число выполненных неравенств вида 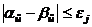 ;
;
б) SA совпадает с системой всех непустых подмножеств множества {х1 ..., xN}:
![]() (3.67)
(3.67)
Пример. Проиллюстрируем применение формулы (3.67) на задаче, рассмотренной в предыдущем примере. Для вычисления оценок распознаваемого объекта ω ¢ по классам Ω1 и Ω2 необходимо определить величины р(ω1, ω ¢),..., р(ω6, ω¢); как и раньше, будем полагать e1, ..., e6 = 0. В таком случае имеем: p(ω1, ω¢) = 4; р(ω2, ω¢) = 3; р(ω3, ω¢) = 3; р(ω4, ω¢) = 3; р(ω5, ω¢) = 2; р(ω6, ω¢) = 5. Применение формулы (3.67) позволяет вычислить значения оценок Г1(ω¢) = (1/3) [(24-1) + (23-1) +
+ (23-1)] = 29/3, Г2(ω¢) = 1/3[(23-1) + (22-1)+(25-1)] = 41/3. Подстановка значений этих оценок в решающее правило, реализующее принцип простого большинства, приводит к отнесению объекта ω' к классу П2. Расхождение с результатом предыдущего примера определяется изменением системы опорных множеств алгоритма. Оно лишний раз свидетельствует о том, как необходимо чрезвычайно внимательно относиться к тому, по каким признакам и комбинациям признаков следует сопоставлять объекты при распознавании.
Отметим, что число непустых подмножеств множества, содержащего шесть признаков, равно 26 — 1 = 63. Таким образом, при отсутствии формулы, элиминирующей перебор, процедуру прямого сравнения распознаваемого объекта ω¢ со строками обучающей таблицы по всем опорным множествам пришлось бы выполнить 6×63 = 378 раз.
2. Эффективные формулы при отсутствии ограничений на систему опорных множеств.
Практика распознавания показывает, что в некоторых случаях априори известны поднаборы признаков, которые следует учитывать при сопоставлении распознаваемого объекта с объектами обучающей таблицы. Эти подмножества признаков не всегда совпадают с частными случаями (3.66) и (3.67); они могут иметь различную длину, исключать запрещенные комбинации и т. п.
Расширение области применения АВО основано на введении характеристической булевой функции системы опорных множеств алгоритма fSA и установлении взаимно однозначного соответствия между подмножествами множества признаков и булевыми векторами длины N (вершинами N-мерного единичного куба).
Пример. Заданы таблица обучения и подлежащий распознаванию объект ω¢(N = 4) (табл. 3.4).
Таблица 3.4
Таблица обучения и подлежащий распознаванию ω¢(N = 4)
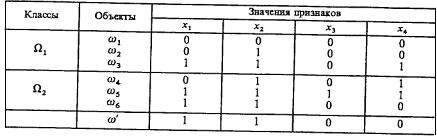
Закодировав вхождение признака в опорное множество через 1, а невхождение — через 0, каждому подмножеству множества признаков <х1, х2, х3, х4> можно сопоставить бинарный вектор или, что то же самое, вершину единичного четырехмерного куба (рис. 3.3).
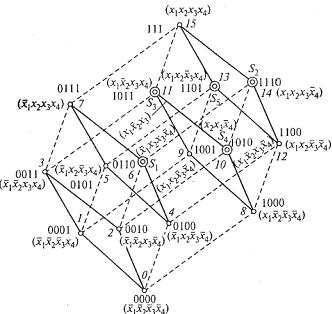
Рис. 3.3. Бинарные векторы множества признаков <х1, х2, х3, х4>
На множестве этих векторов можно определить характеристическую булеву функцию, единицы которой будут определять подмножества множества признаков, включенные в систему опорных множеств алгоритма SA.
Пусть ![]() (вершина 6),
(вершина 6), ![]() , (вершина 14).
, (вершина 14).
В таком случае 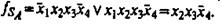
В тех случаях, когда множество единиц fsA образует в единичном Af-мерном кубе интервал или сумму непересекающихся интервалов, также существуют аналитические формулы для вычис-ления оценок. Напомним, что подмножество вершин единичного N-мерного куба называется ин-
тервалом, если оно соответствует некоторой элементарной конъюнкции. Очевидно, что все грани, ребра и вершины единичного N-мерного куба являются интервалами.
Система опорных множеств организована следующим образом (соответствующий интервал пред-ставлен ребром, соединяющим вершины 6 и 14): в нее включены все признаки, входящие в ДНФ характеристической функции без отрицания (х2 и х3), и не включены признаки, входящие в ДНФ с отрицанием (х4), а по остальным признакам (х1) происходит полная вариация, т. е. рассмат-риваются подмножества, как включающие, так и не включающие эти признаки (xl, x2, х3 и х2, х3).
Эффективная аналитическая формула для вычисления оценок в случаях, когда характеристической функции системы опорных множеств соответствует интервал, имеет вид
![]() (3.68)
(3.68)
В (3.68) учитывается вклад только тех строк таблицы обучения («эффективных»), постоянная часть которых (в нашем случае <x2, x3> близка постоянной части ω¢; р*(ω¢r, ω¢) — число выполненных неравенств вида |aj-bj| £ ej, - на варьируемой части (здесь <x1>).
Таким образом, при условии e1 ..., e6 = 0 и, учитывая, что эффективны в Ω1 строки ω1 и ω3, в Ω2 — строки ω4 и ω6, р*(ω¢2, ω¢)= 0, р*(ω¢3, ω¢) = 1, р*(ω¢4, ω¢) = 0, р*(ω¢6, ω¢) = 1, имеем: Г1(ω¢) = (1/3)(20 +
+21) = 1; Г2 = (ω¢) = (1/3)(20+21) = 1.
Полученный результат означает, что при указанном выборе системы опорных множеств строка ω¢ не классифицируется.
Если характеристической функции соответствует сумма непересекающихся интервалов (пред-ставляется ортогональной ДНФ), как, например, в случаях SA = {S1, S2, S3, S4, S5}, S1 = <x2, x3> (вершина б), S2 = <x1, x2, x3> (вершина 14), S3 = <x1, x3, x4> (вершина 11), S4=<x1, x3> (вершина 10), S5 = <x1, x2, x4> (вершина 13), 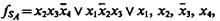 то при вычислении оценок (3.68) применяется к каждому интервалу отдельно и результаты суммируются.
то при вычислении оценок (3.68) применяется к каждому интервалу отдельно и результаты суммируются.
Сложность формулы вычисления оценок в АВО при произвольной SA пропорциональна сложности ДНФ, представляющей характеристическую функцию системы опорных множеств алгоритма. Это означает, что построение простой формулы для вычисления оценок Гi(w¢) связано с задачей минимизации булевых функций в классе ДНФ, а точнее — с задачей построения кратчайшей ортогональной ДНФ или ДНФ, в которой каждый интервал имеет небольшое число пересечений с соседними. В общем случае задача такого синтеза неразрешима и потому следует пользоваться приближенными алгоритмами, обеспечивающими получение «достаточно простых» ортогональных ДНФ или ДНФ с небольшим числом взаимных пересечений интервалов.
Таким образом, если для вычисления расстояний rj(aj, bj) существует эффективный алгоритм и число операций при одном таком вычислении не превосходит некоторой величины Q, то число операций при вычислении всех величин Гi(ω¢), i = 1, ..., m, не превосходит 2QNm.
Число операций при распознавании одного объекта в фиксированном алгоритме А пропор-ционально «площади» таблицы ТN, m с коэффициентом пропорциональности, не превосходящим 2Q.
Сведение задачи построения экстремальных алгоритмов типа АВО к отысканию экстремумов функции многих переменных было обосновано . Для проведения оптимизации могут быть применены методы переборного типа (при небольшом числе параметров), градиентного типа или случайного поиска.
АВО успешно используется для решения задач медицинской и технической диагностики, геологической разведки, идентификации и управления технологическими процессами, оптимиза-ции процесса принятия решений, обработки результатов биологического эксперимента и т. д. Алгоритмы этого класса позволяют решать некоторые задачи проблемы распознавания: выбора словаря признаков на основе оценки их информативности, описания классов на языке признаков, отнесения распознаваемого объекта к одному из классов, автоматической классификации.
ЗАДАНИЯ ДЛЯ САМОСТОЯТЕЛЬНОЙ РАБОТЫ
1. Составьте логическую схему базы знаний по теме юниты:
2. Совокупность признаков объектов, используемых в рабочем словаре, описывается
N-мерным вектором (l = l1 l2, ..., lN), компоненты которого принимают значения … или … в зависимости от того, имеется или отсутствует возможность определения соот-ветствующего признака объекта. Какие это значения?
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
3. Установите соответствие между операциями над высказываниями А и В и их формализованным представлением:
Операции над высказываниями | Формализация высказываний |
Конъюнкция | `А, читается «не А» |
Дизъюнкция | А®В (читается «если А, то В») |
Отрицание | А×В (читается «А и В») |
Импликция | А+В (читается «А и В») |
4. В логических системах распознавания различают прямую и обратную задачи распозна-вания. Приведите математическую постановку этих задач:
а) прямая задача распознавания______________________________________________________
_____________________________________________________________________________________
_____________________________________________________________________________________
_____________________________________________________________________________________
б) обратная задача распознавания____________________________________________________
_______________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________________
5. Последовательность реализации процедуры распознавания в соответствии с алгорит-мами АВО, используемыми в логических системах распознавания, состоит из трех шагов:
Шаг 1. Выделяется система опорных множеств алгоритма, по которому производится анализ распознаваемых объектов;
Шаг 2. Вводится понятие близости на множестве частей описаний объектов;
Шаг 3. Задаются правила.
В шаге 3 задаются три правила «а», «б» и «в» Какие это правила?
а) _______________________________________________________________________________
_____________________________________________________________________________________
б) _______________________________________________________________________________
_____________________________________________________________________________________
в) _______________________________________________________________________________
__________________________________________________________________________________________________________________________________________________________________________
ГЛОССАРИЙ
№ п/п | Новое понятие | Содержание |
1 | 2 | 3 |
1 | Априорный словарь | словарь признаков, относительно которых может быть получена априорная информация, необходимая для описания классов на языке этих признаков |
2 | Алгебра логики | не пустое множество элементов, являющееся ее областью, вместе с некоторым заданным набором операций, которые мож-но совершать над элементами, не выходя за пределы области |
3 | Алгоритмы АВО | предложенный класс алгоритмов, называемый алгоритмами распознавания, основанными на вычислении оценок |
4 | Базис | таблица, которая представляет все возможные комбинации зна-чений истинности некоторого набора элементов А, В, С, ... |
5 | Буль Дж. () | английский математик, создатель булевой алгебры - раздела математической логики, изучающего высказывания и операции над ними |
6 | Булева функция | булевой функцией от n аргументов называется функция F из |
7 | Высказывания | законченные предложения, которые могут иметь одно из двух значений истинности: либо быть истинными, либо быть ложными |
8 | Дизъюнкция | операция логического сложения, совершаемая, по крайней мере, над двумя высказываниями и соответствующая объединению этих высказываний с помощью слова «или» |
9 | И (род. в 1935 г.) | специалист в области информатики и математической кибер-нетики, академик по отделению информатики, вычислительной техники и автоматизации (1992 г.) |
10 | Конъюнкция | операция логического умножения, совершаемая, по крайней мере, над двумя высказываниями и соответствующая комби-нации этих высказываний с помощью слова «и» |
11 | Логические системы распознавания | системы, содержащие большое число классов и признаков, оценка эффективности которых связана со значительными трудностями |
12 | Метрика | мера близости или подобия между объектами в N-мерном век-торном пространстве признаков |
13 | Маскировка | один из основных методов снижения эффективности разведки противника в общем комплексе мероприятий по противо-действию |
14 | Отрицание | операция, совершаемая над одним высказыванием и обозна-чаемая чертой над буквой, например`А, читается «не А» |
15 | Обратная задача распознавания | задача, состоящая в том, чтобы определить множество априори неизвестных посылок, из которых следуют некоторые данные выводы |
16 | Прямая задача распознавания | задача, состоящая в том, чтобы определить, какие выводы можно сделать относительно классов на основе общих сведений априорного характера и апостериорной информации |
17 | Рабочий словарь | словарь, включающий только признаки, которые, с одной сторо-ны, наиболее информативны, а с другой, могут определяться име-ющейся или специально созданной измерительной аппаратурой |
18 | Среднеквадратичный разброс класса | мера близости между объектами данного класса |
1 | 2 | 3 |
19 | Среднеквадратичный разброс объектов | мера близости между объектами данной пары классов |
20 | Стандартный базис | базис, колонки которого упорядочены и записаны в возрастаю-щем порядке их номеров слева направо |
21 |
( г. г.) | специалист в области вычислительной математики и математи-ческой физики, академик по Отделению математики (1966 г.) |
22 | Элементарное произведение | произведение вида А1, А2, …; Аn-1, Аn, составленное из элементов Ai или их отрицаний Aj и содержащее n сомножителей |
23 | Элементарные суммы | сумма вида |
МЕТОДЫ РАСПОЗНАВАНИЯ
ГЛАВА 2
РАБОЧИЙ СЛОВАРЬ ПРИЗНАКОВ СИСТЕМ РАСПОЗНАВАНИЯ.
МЕТОДЫ АЛГЕБРЫ ЛОГИКИ В РАСПОЗНАВАНИИ.
ЛОГИЧЕСКИЕ СИСТЕМЫ РАСПОЗНАВАНИЯ
Ответственный за выпуск
Корректор
Операторы компьютерной верстки: ,
_____________________________________________________________________________________
НОУ "Современная Гуманитарная Академия"
* Полужирным шрифтом выделены новые понятия, которые необходимо усвоить. Знание этих понятий будет проверяться при тестировании.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
