

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
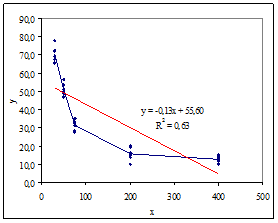
Рис. 5а
Найдем преобразование 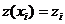 , посредством которого аппроксимирующая функция
, посредством которого аппроксимирующая функция ![]() , заданная на множестве точек
, заданная на множестве точек 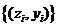 , будет линейной.
, будет линейной.
Для этого разобьем исходное множество точек на пять подмножеств в соответствие с пятью значениями ![]() (30, 50, 75, 200, 400):
(30, 50, 75, 200, 400):
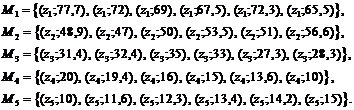
В каждом подмножестве ![]() вычислим среднее значение случайной величины
вычислим среднее значение случайной величины ![]() и сформируем пять точек
и сформируем пять точек ![]() :
: ![]() ,
, 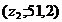 ,
, ![]() ,
, 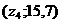 ,
, ![]() .
.
Для этих пяти точек сформулируем условия (2*) в виде:
| (**) |
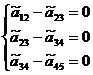 , где
, где Способ решения полученной системы уравнений детально описан выше для случая детерминированной модели.
Адекватным преобразованием[11] для точек ![]() будут значения:
будут значения: 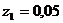 ,
, ![]() ,
, 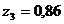 при заданных «произвольных»
при заданных «произвольных» 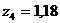 и
и ![]() .
.
Для аппроксимирующей функции ![]() , заданной на исходном множестве из 30 точек
, заданной на исходном множестве из 30 точек ![]() , регрессионные статистики[12] имеют следующие значения:
, регрессионные статистики[12] имеют следующие значения:
| -48,611 | 73,028 |
|
| 1,28 | 1,13 |
|
| 0,98 | 3,17 |
|
| 1437,83 | 28 |
|
| 14448,56 | 281,37 |
|
Видно (рис. 5б), что аппроксимирующая функция ![]() практически полностью объясняет наблюдаемую зависимость.
практически полностью объясняет наблюдаемую зависимость.
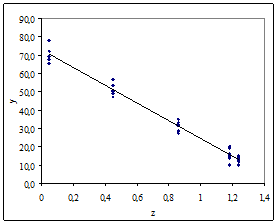
Рис. 5б
Ряд практических задач, в т. ч. построение многомерных регрессионных моделей в оценочной деятельности, не требует аналитического представления линеаризующего преобразования, достаточно нахождения численного решения системы уравнений (**).
Преобразование, близкое к численному решению системы (**), может быть получено с помощью инструмента Solver(Поиск решения) в MSExcel.[13]
Покажем это.
Как и прежде разобьем исходную выборку на подмножества ![]() , для всех точек которого ищется адекватное преобразование
, для всех точек которого ищется адекватное преобразование ![]() .
.
Применение численного метода оптимизации предполагает наличие начального приближения, которое можно задать произвольным образом (например, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,![]() ), но обязательно сохраняя порядок следования (нарастания значений) меток[14] аналогичным порядку нарастания значений
), но обязательно сохраняя порядок следования (нарастания значений) меток[14] аналогичным порядку нарастания значений ![]() .
.
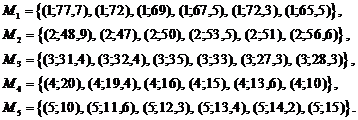
По полученным точкам, с помощью функции ЛИНЕЙН() построим аппроксимирующую функцию 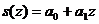 (рис. 5в), характеристиками которой являются следующие значения статистик:
(рис. 5в), характеристиками которой являются следующие значения статистик:
| -15,13 | 81,70 |
|
| 0,77 | 2,54 |
|
| 0,93 | 5,94 |
|
| 389,08 | 28 |
|
| 13741,07 | 988,86 |
|
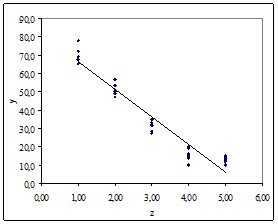
Рис. 5в
Это – промежуточный результат нахождения линеаризующей функции, соответствующий начальному приближению значений ![]() , произвольно заданному лишь с учетом ограничений на неотрицательность и монотонность следования меток.
, произвольно заданному лишь с учетом ограничений на неотрицательность и монотонность следования меток.
Теперь с помощью инструмента Solver, подберем значения ![]() , минимизирующие сумму квадратов остатков
, минимизирующие сумму квадратов остатков ![]() , что эквивалентно максимизации коэффициента детерминации
, что эквивалентно максимизации коэффициента детерминации ![]() .
.
Не забудем учесть условия адекватности преобразования[15], для чего в диалоговом окне инструмента Solverвведем ограничения (условия неотрицательности и монотонности) на допустимые значения ![]() (рис. 6).
(рис. 6).
|
|
Рис. 6 |
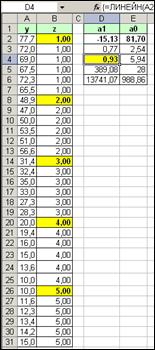
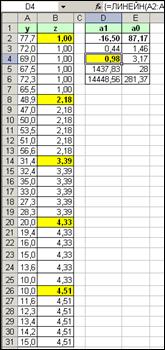
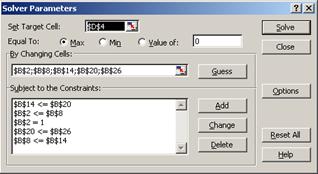
В результате оптимизации получена линейная аппроксимирующая функция ![]() (рис. 5г) со значениями[16]
(рис. 5г) со значениями[16]![]() ,
, ![]() ,
, 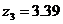 ,
, ![]() ,
, 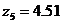 и следующими регрессионными статистиками:
и следующими регрессионными статистиками:
| -16,507 | 87,174 |
|
| 0,44 | 1,46 |
|
| 0,98 | 3,17 |
|
| 1437,83 | 28 |
|
| 14448,56 | 281,37 |
|
Сравнивая регрессионные статистики, полученные аналитической и оптимизационной процедурами решения системы (**), можно видеть, что обе процедуры дают практически одинаковые[17] результаты: 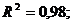
![]() =3,17;
=3,17; 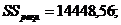
![]()
Рис. 5г |
Коэффициенты регрессионных уравнений, полученных в результате сравниваемых процедур, различаются, однако это слабо отражается на значениях моделируемой функции. Например, для значения аргумента ![]() =75:
=75:
при аналитическом решении - ![]() ,
, 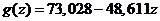 = 31,22
= 31,22
при «оптимизационном» решении - ![]() ,
, 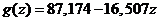 = 31,23
= 31,23
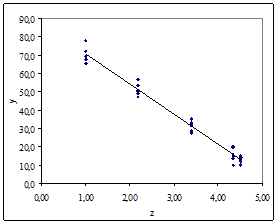
В то же время, прогнозное значение модели с линейной зависимостью от ![]() (рис. 5а):
(рис. 5а): ![]() = 46,0 существенно отличается от среднего значения
= 46,0 существенно отличается от среднего значения ![]() = 31,23.
= 31,23.
Если теперь рассмотреть зависимости ![]() преобразованной переменной от исходной (рис. 7), можно видеть монотонный характер огибающих этих зависимостей, как бы «зеркальных» исходной зависимости
преобразованной переменной от исходной (рис. 7), можно видеть монотонный характер огибающих этих зависимостей, как бы «зеркальных» исходной зависимости 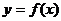 (рис.4) относительно оси абсцисс. В условиях малого объема рыночных данных обеспечение монотонного характера полученных зависимостей и соответствие их характера (с учетом «зеркальности») закономерностям, наблюдаемым на рынке, может служить дополнительными признаками адекватности проведенных преобразований.
(рис.4) относительно оси абсцисс. В условиях малого объема рыночных данных обеспечение монотонного характера полученных зависимостей и соответствие их характера (с учетом «зеркальности») закономерностям, наблюдаемым на рынке, может служить дополнительными признаками адекватности проведенных преобразований.
Рис. 7
Итак,аналитическим расчетом либо оптимизационной процедурой с корректным использованием инструмента Solverрешается задача учета в аддитивной регрессионной модели нелинейной монотонной зависимости , заданной на конечном множестве точек, путем адекватного преобразования ![]() исходной влияющей переменной.
исходной влияющей переменной.
При этом существенно улучшаются показатели точности регрессионной модели по сравнению с моделью без такого преобразования (линейной по![]() ).
).
Также очевидно, что адекватных преобразований может быть несколько в зависимости от заданных значений «свободных» переменных (начальных условий оптимизации).
Полученные выше результаты легко обобщаются на случай, когда объясняющая переменная ![]() не имеет повторяющихся значений.
не имеет повторяющихся значений.
Как и прежде, ищется преобразование ![]() , вместе с линейной функцией
, вместе с линейной функцией ![]() , заданной на множестве .
, заданной на множестве .
В этом случае возникает дополнительная задача разбиения исходного множества ![]() на подмножества
на подмножества ![]() так, чтобы каждое подмножество (кластер) содержало близкие значения
так, чтобы каждое подмножество (кластер) содержало близкие значения ![]() , а значения
, а значения ![]() разных кластеров отличались друг от друга существенно.
разных кластеров отличались друг от друга существенно.
Эта задача обычно решается экспертом на основе анализа имеющейся выборки данных либо методами кластерного анализа.
Затем в каждом подмножестве ![]() вычисляются средние значения случайных величин
вычисляются средние значения случайных величин ![]() ,
,![]() . Каждая координата точки
. Каждая координата точки 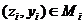 представляется как сумма среднего значения случайной величины, вычисленного на данном подмножестве
представляется как сумма среднего значения случайной величины, вычисленного на данном подмножестве ![]() , и отклонения
, и отклонения 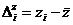 .
.
В итоге, преобразуя формулы (5)–(7), получаем требуемый результат.
Таким образом, от предыдущего случая данная ситуация отличается лишь тем, что набор ![]() приписывается не единственному значению
приписывается не единственному значению ![]() , а среднему
, а среднему ![]() по подмножеству
по подмножеству ![]() .
.
Приемы и нюансы практического применения оптимизационного инструмента Solverпри построении регрессионных моделей на малых объемах данных (выборках) требуют отдельного рассмотрения, выходящего за рамки данной публикации.
Список литературы:
1. , Левыкина моделирование в оценке недвижимости. – Запорожье: Полиграф, 2003.
2. , Сивец методы оценки стоимости недвижимого имущества / под. ред. , . - М: Финансы и статистика, 2008.
3. , , Грибовский разнотипных ценообразующих факторов в многомерных регрессионных моделях оценки недвижимости - Вопросы оценки, №2, 2004. http://www. *****/default. aspx? SectionId=41&Id=1575
4. Руководство пользователя. Microsoft®Excel. Версия 5.0, Корпорация Microsoft, 1993.
,
член Экспертного Совета НП СРО «НКСО»,
заместитель директора
агентство оценки» (ГК Поволжский Центр Развития),
г. Самара
«Формирование регионального фонда данных рынка недвижимости
с использованием ГИС-технологий для повышения точности и обоснованности индивидуальной и массовой оценки»
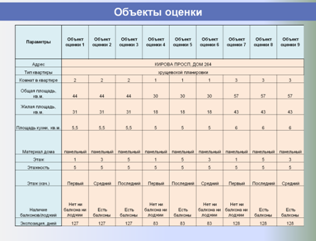
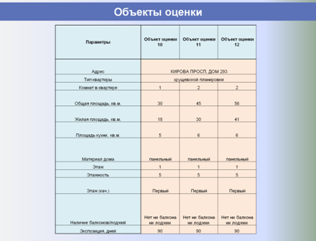
Точная и обоснованная оценка недвижимости невозможна без формирования полноценных и информативных баз данных объектов недвижимости и проведения на их основе необходимых аналитических процедур.
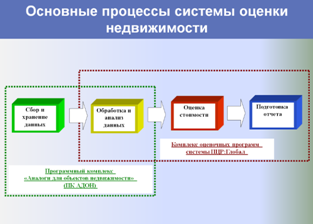
Процесс формирования регионального фонда данных рынка недвижимости, проведения аналитических исследований, выполнения расчетных процедур и формирования итоговых отчетов об оценке состоит из нескольких функциональных блоков (этапов), и все они могут быть автоматизированы. Необходимые для этого технологии созданы, и длительное время успешно используются на практике в Поволжском Центре Развития, г. Самара.
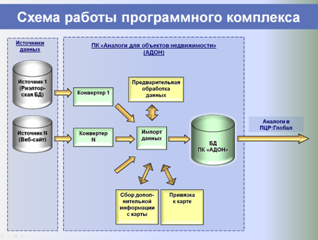
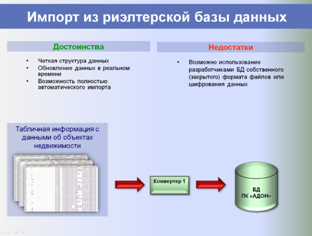
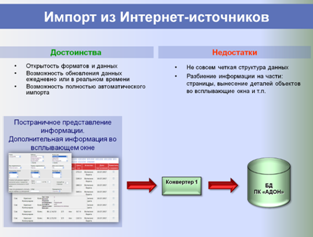
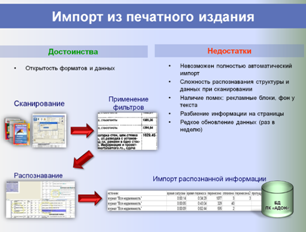
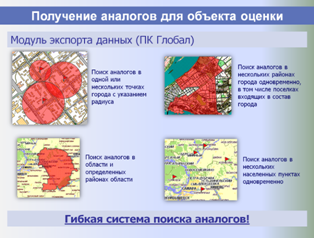
На этапе сбора и хранения исходных данных из всех доступных источников (риэлтерские базы данных, веб-сайты, печатные журналы с предложениями о продаже и аренде) регулярно в автоматическом режиме собираются все объекты-аналоги, структура их данных приводится к единому формату, после чего они импортируются в единую базу данных.
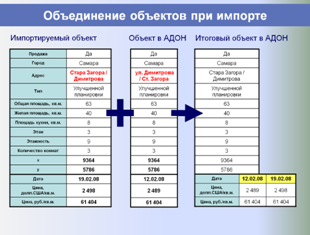
Собранные в единую БД аналоги фильтруются: удаляются аналоги с некорректными или подозрительными ценами и прочими параметрами. Также производится объединение дублей (когда один аналог представлен в нескольких источниках или повторяется на разные даты) – что также позволяет накапливать по каждому аналогу историю изменения его цены и узнавать срок экспозиции.
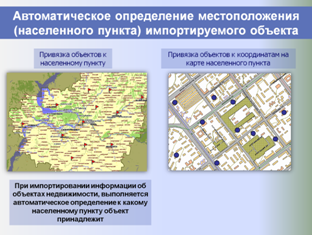
Анализируются адреса аналогов, производится их поиск на карте и осуществляется привязка объектов к геоинформационной подоснове – электронным картам населенных пунктов (успешно разрешена проблема распознавания адресов).
По координатам аналога для него с электронных карт собирается дополнительная информация (обеспеченность транспортом, плотность застройки квартала, деловая активность и т. д.), которая тоже может быть использована в оценке или при анализе рынка.
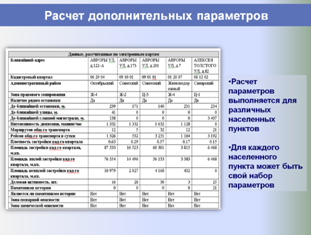
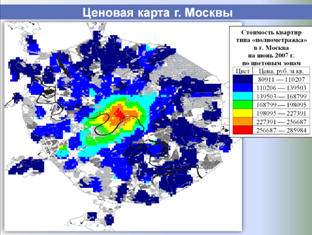
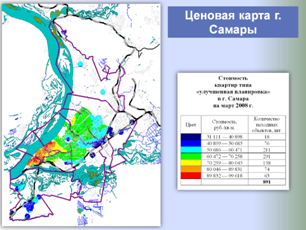
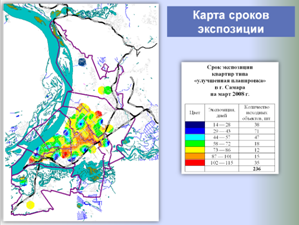
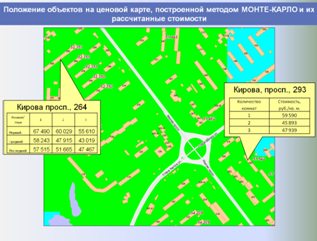
Единая БД аналогов используется в дальнейшем как быстрый, корректный и информативный источник аналогов для объектов оценки, а также для построения различных аналитических отчетов о структуре и динамике рынка недвижимости, включая ценовые карты, динамики стоимостей и арендных ставок, величины сроков экспозиции, зависимости стоимости от материала стен, этажа расположения и т. п.
Все элементы системы автоматизации Поволжского Центра Развития подтверждены свидетельствами Роспатента.
Аналогичные системы помимо Самары внедряются Поволжским Центром Развития и в других городах-миллионниках Российской Федерации.
Ниже представлены слайды, показывающие этапы работы разработанной и внедренной системы в части автоматизированного формирования регионального фонда данных рынка недвижимости и проведения аналитических исследований, применяемых для выполнения расчетных процедур и формирования итоговых отчетов об оценке.
|
|
1 | 2 |
|
|
3 | 4 |
|
|
5 | 6 |
|
|
7 | 8 |
|
|
9 | 10 |
|
|
11 | 12 |
|
|
13 | 14 |
|
|
15 | 16 |
|
|
17 | 18 |
|
|
19 | 20 |
|
|
21 | 22 |
|
|
23 | 24 |
|
|
25 | 26 |






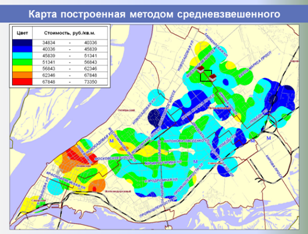
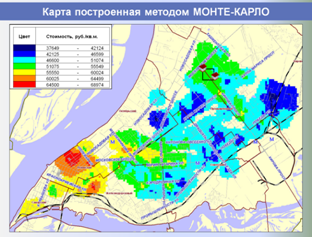
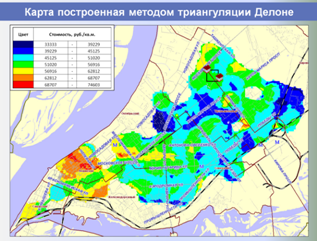
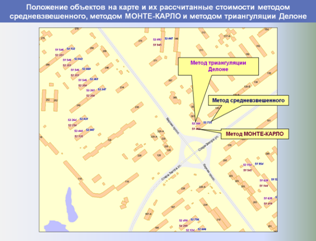

,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 |
