
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
9.1 Устранение непроизводящих правил.
Непроизводящими правилами грамматики начинаются правила, применение которых никогда не приводит к построению терминальных цепочек.
Например, рассмотри правила для нетерминала А
А®А А½ В А
В этом случае, появившись в цепочке, нетерминал А никогда не будет заменен терминальной цепочкой (имеется в виду, что других правил для А нет). Естественно, в реальности ситуации бывают не столь простые. Алгоритм устранения непроизводящих нетерминалов:
Построение множества производящих нетерминалов NR: Строится множество NR1 = {A/ A®bj, bjÎVT} Последовательно строятся множества NRi+1={ A/ A®bj, bjÎ(NRiÈVT)*} до тех пор, пока получим NRi+1= NRi или же NRi= VN. Тогда NR = NRi. Исключаем из грамматики все правила, в правых частях которых нетерминалы из VN\ NR. Исключаем из грамматики правые части правил, в которых присутствуют нетерминалы из VN\ NR.Например, рассмотрим грамматику G с множеством правил
![]() S® AB½BC
S® AB½BC
A® AA½AB
B® bB½a
С®сС½d ½AC
Построим множество NR. NR1={B, C}, NR2={S, B, C}, NR3= NR2= NR.
Преобразованная грамматика примет вид:
S® BC
![]() B® bB½a
B® bB½a
С®сС½d
9.2. Устранение недостижимых нетерминалов.
Недостижимыми нетерминалами называются нетерминалы, которые никогда не могут быть построены при построении вывода, начиная с начального символа грамматики. Следует отметить, что такие нетерминалы в грамматиках встречаются в основном тогда, когда исключены некоторые непроизводящие символы, т. е. недостижимым нетерминал становится чаще всего после исключения некоторых непроизводящих симовлов. Например, если в грамматике для нетерминала А правила А®А А½ В А, и нетерминал В не встречается в других правых частях правил грамматики, то в этом случае, после устранения нетерминала А нетерминал В становится недостижимым, и, следовательно, его можно исключить из грамматики без изменения порождаемого ей языка. Построение множества недостижимых нетерминалов похоже на построение множества непроизводящих нетерминалов: мы строим множество всех достижимых нетерминалов, а затем исключаем все остальные нетерминалы грамматики. Алгоритм построения грамматики, в которой используются только достижимые нетерминалы (множество достижимых нетерминалов –D) , выглядит следующим образом:
Пусть дана грамматика G=< VT,VN, S, R>, строится эквивалентная грамматика без непроизводящих символов G’ =< VT,VN’, S, R’>.
1. Начальное значение D0=S.
2. Итерационное построение множества D: Di+1= DiÈ{A/B®aAbÎR&BÎ Di}
3. Построение продолжается, до тех пор, пока Di+1= Di или Di+1= VN, в обоих случаях VN’= Di+1,
R’={ Ri / Ri=(A®j), AÎ VN’,jÎ( VN’È VT)*}
Построенная грамматика не содержит недостижимых нетерминалов.
Например, рассмотрим грамматику G с множеством правил
![]() S® A C ½B C
S® A C ½B C
A® AD½ DF
D® aA ½ D A
F® b F½l
B® bB½a
С®сС½d
Тогда здесь A и D непроизводящие нетерминалы, после их устранения нетерминал F становится недостижимым, поэтому нетерминалы A, D и F могут быть исключены из грамматики с сохранением языка, порождаемого грамматикой.
9.3. Устранение l - правил
Устранение l - правил связано с исключением построения цепочек, которые после преобразований превращаются в пустую цепочку. Цель такого преобразования грамматики – если в грамматике строится пустая цепочка, то она строится в результате первого шага построения. Применение любого из оставшихся правил приводит к построению непустых цепочек, более того, цепочка, построенная из каждого из нетерминала, состоит не менее чем из одного терминального символа.
Пусть дана грамматика G=< VT,VN, S, R>, строится эквивалентная грамматика G’ =< VT,VN’, S, R’>.
1. Построить множество Nl = { A / A Þ+ l } - множество нетерминальных символов, из которых возможен вывод пустой цепочки. Множество Nl строится итерационно. На первом шаге строится Nl0.
Nl0 = { B / B ® l Î R}
Пусть построено Nl1, Nl2, ..., Nli , ( i ³ 0). Тогда Nli+1 = Nli È{ B / B ® j Î R & j Î ( Nli)* }.
Если на очередном шаге Nli+1 = Nli, то искомое множество Nl найдено ( Nl = Nli ).
2. Построить R’ — множество правил эквивалентной грамматики так, что:
a) Если A®a0 B1 a1 B2 ... Bk ak Î R, k ³ 0 и Bi Î Nl для 0 £ i £ k, но ни один символ в цепочках aj, 1 £ j £ k не содержит символа из Nl, то включить в R’ все правила вида
A ® a0X1a1X2...Xkak
Xi либо Bi, либо l (при этом правило A ® l не включать; это могло бы произойти, если все ai = l ).
b) если S Î Nl, включить в R’ также правило S’® S½l где S’ - новый начальный символ.
Таким образом, любая КС—грамматика может быть приведена к виду, когда R не содержит l - правил, либо есть точно одно правило S’ ® l и S’ не встречается в правых частях остальных правил из R. Такие грамматики будем называть неукорачивающими.
Например, пусть дана грамматика G с множеством правил
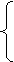
S®A B½ BC
A® aAb ½l
B® dB½c
C® CC½Ac½l
Nl0= {A, C}
Nl1= {A, C}= Nl. Поскольку lÏL(G) (SÏ Nl), правила грамматики примут вид
S®A B ½B½ BC
A® aAb ½ab
B® dB½c
C® CC½Ac½a½ c
Б. Устранение правил А ® В (цепных правил)
Применение цепных правил приводит к увеличению длины ветвей синтаксического дерева, исключение цепных правил часто приводит к большей «прозрачности» грамматики и уменьшению длины выводов, которые можно построить. Алгоритм исключения цепных правил:
1. Для каждого AÎ VN построить NA = { B / A ® B }, т. е. множество нетерминальных символов, выводимых из данного символа. Процедура построения следующая:
а) положить NA0 ={A}.
б) пусть построены NA0, NA1 ... NAi . Тогда
NAi+1 = { C / B ® C Î R & B Î NAi } È NA0.
Если на очередном шаге NAi+1 = NAi, то положить NA = NAi.
2. Построить R’ (множество правил эквивалентной грамматики) так: если B ® a Î R и не является цепным правилом, то включить в R’ правила A ® a. для всех таких A, что
B Î NA.
Рассмотрим пример. Пусть множество правил грамматики имеет вид:
![]() S®T+S½T
S®T+S½T
T® M*T½M
M® (S)½ i
Простроим для данной грамматики множества NA
NS ={S, T, M}
NT = {T, M}
NM = {M}
После преобразования грамматики она примет вид:
![]() S®T+S½ M*T½(S)½ i
S®T+S½ M*T½(S)½ i
T® M*T ½(S)½ i
M® (S)½ i
В данном случае преобразование грамматики не привело к её упрощению, но построенные синтаксические деревья будут иметь меньшую глубину, и построение дерева будет происходить быстрее.
Грамматика называется неукорачивающей, если для любого правила грамматики j®y выполняется½j½£½y½. Такое определение применимо как к КС-грамматикам, так и к КЗ-грамматикам. А-грамматика так же может быть неукорачивающей. Для КС и А-грамматик необходимым и достаточным условием принадлежности к классу неукорачивающих грамматик является отсутствие в них l-правил.
Грамматика называется приведенной, если она неукорачивающая и не содержит непроизводящих символов.
Поэтому, если lÏL(G), то существует приведенная грамматика G1, такая, что L(G1)=L(G).
В случае же lÎL(G), существует эквивалентная грамматика с единственным укорачивающим правилом.
10. Разрешимые и неразрешимые свойства КС-грамматик
10.1. Разрешимые свойства КС-грамматик
Теорема. Свойство lÎL(G) разрешимо для КС-грамматик.
Разрешимость этого свойства обеспечивается алгоритмом исключения l-правил, приведенным в предыдущем разделе.
Теорема. Если G=< VT, VN, S, R> – КС, неукорачивающая грамматика, то язык L(G) разрешим, т. е. для любой цепочки aÎ VT * можно определить, aÎL(G) или же aÏL(G).
Доказательство:
Пусть, aÎL(G) и½a½=n. Тогда существует вывод цепочки a I,…, b, g,…, b, … , , a. Т. е. некоторая цепочка встречается в выводе более одного раза. Тогда, удалив из вывода фрагмент g,…, b, получим опять вывод цепочки a.
Значит, для любого слова aÎL(G) существует его бесповторный вывод в G, т. е. вывод, в котором все цепочки различны, причем длина каждой цепочки £ n. Число таких цепочек ограничено числом![]()
![]() , а значит, длина вывода ограничена числом r(n)!( в принципе можно дать более точную оценку, но достаточно и этой). Откуда получается простой алгоритм распознавания нам здесь aÎL(G) или же aÏL(G)?
, а значит, длина вывода ограничена числом r(n)!( в принципе можно дать более точную оценку, но достаточно и этой). Откуда получается простой алгоритм распознавания нам здесь aÎL(G) или же aÏL(G)?
Перебираем все бесповторные последовательности цепочек длины £ n, в которых каждая следующая цепочка не короче предшествующей, и проверяем, является ли она выводом в данной грамматике. Сложность такой проверки ограничена, т. к. на каждом шаге проверяем выводимость ai+1 из ai. Если хоть одна последовательность является выводом требуемой цепочки, то aÎL(G) иначе aÏL(G).
Теорема. Если G – приведенная грамматика без цепных правил, то существуют константы с1 и с2, зависящие от G, что для любого вывода D(a) цепочки aÎL(G)
c1½a½£½D (a)½£c2½a½, где ½D (a)½ - длина вывода цепочки a.
Доказательство:
Пусть имеется грамматика G=< VT,VN, S, R>.
Обозначим K - ½ VN ½, L – максимальная длина правой части правила в R, т. е. L={max½b½/ A ®bÎR & AÎ VN}. Т. к. G не содержит цепных и укорачивающих правил, то для любого вывода bÞK g, ½g½>½b½, значит, для вывода SÞK½a½g, ½g½>½a½, следовательно, ½D (a)½£K½a½, с другой стороны, ½a½£L½D (a)½, поэтому, ½a½/L£½D (a)½, что требовалось доказать.
Теорема.
Если G=< VT,VN, S, R> – КС-грамматика, то L(G) бесконечен Û существует нетерминальный символ Ai такой, что SÞ+ X Ai Y, AiÞ+ Z AiW, ½ZW½³ 1, и AiÞ+ V&(X, Y, Z, W, VÎ VT*).
Доказательство:
Считаем, что рассматриваемая грамматика не содержит цепных правил.
1. Доказательство бесконечности языка при условии SÞ+ X Ai Y, AiÞ+ Z AiW, ½ZW½³ 1, и AiÞ+ V очевидно, т. к. при представленных условиях фрагмент вывода AiÞ+ Z AiW может быть включен в вывод произвольное число раз; следовательно, SÞ+ X VY, и SÞ+ X ZjVWjY для всех j³0,что и обеспечивает построение бесконечного множества цепочек заданного вида.
2. Пусть язык, порождаемый грамматикой, является бесконечным, а условие теоремы не выполняется. Тогда максимальная глубина (длина ветви) синтаксического дерева для цепочки, порождаемой грамматикой, не превышает ½ VN ½. Число таких деревьев конечно, значит, конечно число цепочек, порождаемых грамматикой.
Если же язык бесконечен, то глубина деревьев не ограничена, значит, в каком-нибудь синтаксическом дереве Т существует нетерминал Ai, через который ветвь дерева проходит неоднократно, причем это дерево соответствует выводу терминальной цепочки. Значит, во-первых, существует путь из начальной вешнины в данную вершину, и в силу отсутствия цепных правил, SÞ* a Aib, aÞ*X, bÞ*Y, X, YÎVT*, во-вторых, в силу выводимости из Ai терминальной цепочки, AiÞ V&VT ÎVT, в третьих, из-за повторения нетерминала Ai в ветви дерева AiÞ+dAie, dÞ*Z, eÞ*W, Z, W Î VT*, значит, AiÞ+ Z AiW, ½ZW½³ 1. Что и требовалось доказать.
Из доказанной теоремы следует
Следствие 1. Для КС-грамматики G=< VT,VN, S, R> существуют числа p, q такие, что для любой цепочки aÎL(G), если ½a½>p, то она имеет вид a=bgwde, где ½gd½>0, ½gwd½< q, и для любого n цепочка вида bgnwdne ÎL(G), n³0.
Следствие 2. Язык {an bn cn, n³1} не порождается КС-грамматикой.
Теорема. Свойство L(G)=Æ разрешимо для КС-грамматик.
Разрешимость свойства следует из рассмотренных ранее алгоритмов: Язык L(G) не пуст тогда и только тогда, когда начальный символ грамматики является производящим.
10.2. Неразрешимые свойства КС-грамматик.
Поскольку класс множеств (слов), порождаемых грамматиками, совпадает с классом перечислимых множеств, то для языков класса «0» справедлив аналог теоремы Райса «никакое нетривиальное свойство языков класса 0 не является алгоритмически разрешимым» (Т. е. для нетривиального свойства не существует алгоритма, который по произвольной грамматике G выяснял, обладает ли данным свойством язык L(G)).
Для КЗ-грамматик проблема пустоты и бесконечности неразрешимы. Для КС-грамматик эти проблемы разрешимы.
Неразрешимые проблемы для КС-грамматик следуют из неразрешимости проблемы Поста.
Формулировка этой проблемы в виде, удобном для наших целей, следующая: для двух списков цепочек X=(a1,a2,…,am) и Y=(b1,b2,…bm) в алфавите U определить, существует ли последовательность индексов i1,i2,…in, такая, что ![]() .
.
Пусть U и m фиксированы. Введём алфавит дополнительных символов U0={b1,b2,…bm}, U0Ç U=Æ/
U1= U0 ÈU. Пусть X=(a1,a2,…,am) –цепочки в U. Тогда Q(X) – множество цепочек вида 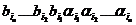 , n³1.
, n³1.
Тогда для Q(X) справедливы утверждения
1. Если X=(a1,a2,…,am) и Y=(b1,b2,…bm) списки цепочек в U, то комбинаторная проблема Поста разрешима тогда и только тогда, когда Q(X) ÇQ(Y)=Æ. Пусть существует gÎ Q(X) и gÎQ(Y). Тогда ![]() , а значит,
, а значит, ![]()
2. Для любого списка X=(a1,a2,…,am) цепочек в U, Q(X) – КС-язык в U. Соответствующая КС-грамматика G=< VT, VN, S, R> для языка Q(X) - G=< U1,{I} , I, R>; R: { I®bi I ai, I®bi ai }. Грамматика является однозначной.
Из введенных утверждений следует теорема:
Теорема. Не существует алгоритма, который по двум КС-грамматикам G1 и G2 определял бы, L(G1) ÇL(G2)=Æ?
Доказательство: Если бы такой алгоритм существовал, то проблема Поста была бы разрешима.
Теорема. Не существует алгоритма, который по любой КС - грамматике позволял бы определить, является ли эта грамматика однозначной.
Доказательство:
Рассмотрим множества Q(X) для X=(a1,a2,…,am) и Q(Y) для Y=(b1,b2,…bm). Правила грамматики для порождения Q(X): RX={ A®bi A ai, A®bi ai } правила грамматики для построения множества Q(Y): RY={ B®bi B bi, B®bi bi }.
Грамматика для порождения Q(X)ÈQ(Y) G=<U, {A, B}, I, R>, где R=RXÈRYÈ {I®A½B}. Эта грамматика однозначна, если Q(X)ÇQ(Y)=Æ, а это свойство неразрешимо.
Другие неразрешимые проблемы для КС-языков:
1. Является ли КС-языком пересечение КС-языков?
2. Является ли КС-языком дополнение КС-языков?
3. Проблема тривиальности КС-языка L=V*(= проблеме пустоты дополнения)?
4. Проблема эквивалентности КС-грамматик.
11. Синтаксический анализ для КС-языков
Может рассматриваться синтаксический анализ в широком или же узком смысле. Синтаксический анализ в узком смысле – по цепочке определить её структуру (или же построить синтаксическое дерево). Т. Е. задача сводится к построению вывода данной цепочки в данной грамматике.
Синтаксический анализ в широком смысле – определение, может ли данная цепочка быть построена с использованием данной грамматики. Это в общем случае гораздо более сложная задача.
Существующие алгоритмы синтаксического анализа классифицируются по:
Cпособу построения вывода : нисходящие, восходящие, смешанные Способу выбора альтернативы: детерминированные и недетерминированные. В первом случае на каждом шаге выбирается правильная альтернатива, во втором – альтернатива выбирается наугад. Способу возврата (для недетерминированного выбора альтернативы): разбор с быстрым или медленным возвратом. По степени доступности цепочки: или цепочка доступна вся сразу, или же читается слева направо посимвольно (при этом доступно для анализа определенное число символов).Обычно рассматривается нисходящий или восходящий разбор при чтении цепочки слева направо.
Типовая задача синтаксического анализа:
Имеется активный нетерминал S и множество альтернатив:
S®j1½j2½¼½jk и текущее состояние анализируемой цепочки Y. Пусть выбрана альтернатива S®X1X2…Xn, XiÎVNÈVT, при iÎ[1,n]. Если X1Î VT, то он должен совпадать с первым символом цепочки Y. Если совпадает, то укорачиваем цепочку на этот символ и переходим к X2. Если не совпадает, то переходим к другой альтернативе.
Если же XiÎVN, тогда из Xi необходимо вывести какое-нибудь начало цепочки Y. Если из Xi нельзя вывести никакое начало цепочки Y, то возможны 2 варианта:
1). Сразу перейти к Xi-1 и попытаться вывести из Xi-1 другое начало и т. д. ( получаем полный перебор вариантов вывода) – разбор с медленным возвратом.
2). Сразу отказаться от альтернативы S®X1X2…Xn (разбор с быстрым возвратом).
Очевидно, что наиболее удобными при анализе цепочек являются грамматики, допускающие детерминированный разбор, когда на каждом шаге мы можем однозначно выбрать альтернативу, и в случае невозможности подобрать нужную альтернативу цепочка не принадлежит языку (никакой вывод не может быть построен). Одним из таких типов грамматик являются LL(k)-грамматики.
11.1 LL(k)-грамматики
LL(k)-грамматиками называются грамматики, допускающие детерминированное построение левого разбора (left) при чтении анализируемой цепочки слева (left) направо, подсматривая вперед не более чем на k символов.
Например, рассмотрим грамматику с множеством правил:
![]() S ®a S½bB
S ®a S½bB
B ® b B½l
Эта грамматика является LL(1)-грамматик, т. к. для выбора правильной альтернативы на каждом шаге нам достаточно анализировать один (текущий) символ цепочки.
Грамматика называется разделённой, если все правила грамматики имеют вид
A®a1j1½a2 j2½…½akjk, причём ai¹aj при i¹j, aiÎVT, jiÎ(VTÈVN)* при iÎ[1,k]. Очевидно, что в случае разделённой грамматики строится детерминированный нисходящий разбор.
Очевидно, что разделённые грамматики принадлежат к классу LL(1) грамматик. Грамматики могут оказаться LL(k) грамматиками для различных k, например, грамматика может быть LL(3) грамматикой, но не LL(2) грамматикой. Бывают и грамматики, которые не являются LL(k) грамматикой ни для какого k.
Например, рассмотрим грамматику с множеством правил:
![]() S ®0 S½0B
S ®0 S½0B
A ® 0 A a½c L(G)= {0n+1 c an, 0n+1 d bn, n³ 0}
B ® 0 B b½d
SÞl AÞ n+10n+1 с an
SÞl BÞ n+1 0n+1 d bn ( n ³ 0 ).
Чтобы определить по заданной терминальной цепочке, какое правило ( S ® A или S ® B ) было применено на первом шаге вывода, нужно прочитать n+1 символ, следовательно данная грамматика не является LL(k) ни при каком k
Дадим формальное определение LL(k) грамматики. Для этого введем определение
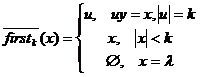
- определяются первые k символов терминальной цепочки. Т. к. для пустой цепочки это пустое множество, то определим для данной грамматики пополненную грамматику, к которой не будут встречаться пустые цепочки:
Для грамматики G=< VT,VN, S, R> соответствующая пополненная грамматика G’=< VTÈ{$},VNÈ{S’}, S’, R’>, где множество правил R’=RÈ{S’® S $ }, где каждая цепочка имеет справа граничный маркер($).
Расширим определение множества first так, чтобы охватить произвольные цепочки aÎ(VTÈVN)*:
Для aÎ(VTÈVN)* Firstk(a)= { x/ aÞ* Z, ZÎVT*, x=![]() }.
}.
Например, рассмотрим грамматику с множеством правил
![]() S ® abA½abB
S ® abA½abB
A ® ab A ½c L(G)= {(ab)nc, (abc)n, n³ 1}
B ® cab B½c
Правила соответствующей пополненной грамматики:
![]() S’® S $
S’® S $
S ® abA½abB
A ® ab A ½c
B ® cab B½c
Для данной грамматики
First1(S)={a}, First1(A)={a, c}, First1(B)={c}; First2(S)={ab}, First2(A)={ab, c$}, First2(B)={c$, ca}, First3(S)={abc}, First3(A)={abc, c$}, First3(B)={c$, cab}.
Тогда мы можем формально определить LL(k) грамматику как грамматику, для которой для любых двух левых выводов
SÞ*w A aÞ w b a Þ *w x
SÞ*w A aÞ w g a Þ *w y
AÎVN, w, x, y Î VT*, a, b, g Î (VN È VT)*, из условияFirstk(x)=Firstk(y) следует b=g.
Несложно показать, что наше формальное определение соответствует не формальному.
Теорема: LL(k) грамматика является однозначной.
Неоднозначность грамматики противоречит LL(k) свойству. Неоднозначна – значит, существуют два вывода для некоторой цепочки, значит, не сможем определить по k символам, каое из правил следует применить.
Теорема: КС-грамматика G=< VT,VN, S, R> является LL(k) грамматикой Û для любых двух правил А®j1 и А®j2 Firstk(j1 a)Ç Firstk(j2 a)=Æ для любой цепочки a, такой что SÞ*wAa.
Использование LL(k) свойства при построении анализатора.
Пусть текущее состояние левого вывода цепочки z=wy имеет вид wАa, где w выведенное терминальное начало цепочки, А – текущий нетерминал( самый левый нетерминал), y не просмотренная часть цепочки.
Рассмотрим Firstk(y). Пусть для нетерминала А существуют альтернативы:
А®j1½j2½¼jn ÎR. Надо найти ji для применения на данном шаге. Для этого надо вычислить ![]() =Firstk(jia). Это множество может быть заранее вычислено для всех А, a, ji. При этом из LL(k) свойства следует, что
=Firstk(jia). Это множество может быть заранее вычислено для всех А, a, ji. При этом из LL(k) свойства следует, что ![]() при i¹j.
при i¹j.
Выбираем ji, такое, что Firstk(y)= Firstk(jia). Если такого ji нет, то zÏL(G).
Затем переходим к анализу полученной цепочки xÞwyÞw’y’, где w’ – терминальное начало цепочки wj1a.
Шаги повторяются, пока не разберём всю цепочку, или не установим, что zÏL(G).
Пример:
Рассмотрим анализ цепочки acbbd в грамматике
![]() S ®ac S½bB
S ®ac S½bB
B ® b B½d
Эта грамматика является LL(1) На первом шаге определяем, какое правило применялось вначале: First1(acS)={a}, First1(bB)={b}, поэтому на первом шаге применяется правило S ®ac S, анализируемая цепочка принимает вид:bbd, First1(bbd)={b}, поэтому применяется правило S ® bB, и анализируемая цепочка принимает вид bd. Определяем First1(bB)={b}, First1(d)={d}, поэтому применяемое правило B ® b B, анализируемая цепочка принимает вид d, применяем правило B ® d, остается пустая цепочка как в выводе, так и анализируемая цепочка, поэтому анализируемая цепочка принадлежит языку, порождаемому грамматикой.
Проблемы, возникающие при построении анализатора для LL(k) грамматик:
1. При k>1 ![]() может стать неприемлемо большой, т. к.
может стать неприемлемо большой, т. к. ![]() пропорциональна k.
пропорциональна k.
2. 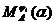 является функцией от трёх переменных: А, ji, a - т. е. велик сам объём предварительных вычислений.
является функцией от трёх переменных: А, ji, a - т. е. велик сам объём предварительных вычислений.
Однако можно упростить задачу, усилив условия, накладываемые на грамматику:
Обозначим 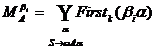 и потребуем, чтобы
и потребуем, чтобы ![]() при i¹j.
при i¹j.
Грамматика G называется строго LL(k) грамматикой, если для любых двух левых выводов
SÞ*w1 A a1Þ w1 b a1Þ *w1x
SÞ*w2A a2 Þ w2 g a2 Þ *w2 y
AÎVN, w1, w2, x, y Î VT*, a1, a2, b, g Î (VN È VT)*, из условияFirstk(x)=Firstk(y) следует b=g. Несложно показать, что G является строго LL(k) грамматикой Û для любого AÎVN из того, что A®bÎR, A®gÎR, b¹g, следует, что MAbÇMAg=Æ.
Теорема: LL(1) грамматика всегда строго LL(1) грамматика.
Доказательство:
Предположим, что некоторая грамматика G - LL(1) грамматика, но не строго LL(1) грамматика. Тогда существуют два вывода
SÞ*w1 A a1Þ w1 b a1Þ *w1x1a1Þ *w1x1y1
SÞ*w2A a2 Þ w2 g a2 Þ *w2 x1a2Þ *w1 x2y2,
Такие, что First1 (x1y1)= First1(x2y2) & b¹g - Условие (*).
Но т. к. G - LL(1) грамматика, то
SÞ*w1 A a1Þ w1 b a1Þ *w1x1a1Þ *w1x1y1
SÞ*w1 A a1Þ w1 g a1Þ *w1x2a1Þ *w1x2y1
и из First1 (x1y1)= First1(x2y1) следует, что b=g - Условие (**).
Покажем, что условия (*) и (**) несовместны.
Рассмотрим следующие случаи:
1. x1¹l, x2¹l, тогда First1(x1y1)=First1(x1), First1(x2y2)=First1(x2), First1(x1 )=First1(x2)по условию (*) b¹g.
С другой стороны, по условию (**) First1(x1 )=First1(x2)Þb=g. Противоречие.
2. x1=l, x2=l приводит к неоднозначности грамматики.
3. Пусть x1=l, x2¹l. Тогда в условии (*)First1(x1y1)=First1(y1)= First1(x2y2)=First1(x2) & b¹g
По условию (**) First1(x1y1)=First1(y1)= First1(x2y1)=First1(x2) & b=g. Противоречие.
Случай 4, x1¹l, x2=l разбирается аналогично случаю 3.
Из теоремы следует критерий принадлежности грамматики классу LL(1):
G – LL(1)Û MAbÇMAg=Æ при b¹g для всех AÎVN, где MAb=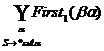
При этом если
а) "m, bÞ*m, m¹l, то MAb=First1(b)
b) bÞ*l, MAb=First1(b)È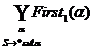
Т. К. рассматриваем пополненную грамматику, то a¹l (First1(l)=Æ).
Определим множество Follow1(X)={a/ SÞ+wXab&aÎVT}, XÎ(VNÈVT).
Т. о. G - LL(1) грамматика Û "AÎVN, "b,"g A®bÎR&A®gÎR&b¹g Þ MAbÇMAg=Æ.
Определения и алгоритмы нахождения множеств First и Follow
1. First1(b)
1.1. First1(l)=Æ
1.2. "aÎVT First1(a)=a
1.3. First1(A)={ First1(xi)/A®x1x2…xnÎR&i=1Úi=m&x1…xm-1Þ+l}
1.4. First1(x1x2…xn)={ First1(xi)/ First1(x1)& i=1Úi=m&x1…xm-1Þ+l}
Например, рассмотрим грамматику:
![]() S ® ABC½CA
S ® ABC½CA
A®a½l
B ® b B½l
C®cC½d
В пополненной грамматике добавляется начальной правило S’® S$.
![]() S’® S
S’® S
S ® ABC½CA
A®a½l
B ® b B½l
C®cC½d
First1(A)={a};
First1(B)={b};
First1(C)={c, d};
First1(S)= First1(ABC)È First1(AC)={a, b, c, d}
2. Follow1(A)= ={First1(a)/ S Þ*w A a }
Рассматриваем грамматику без непроизводящих правил, тогда если S Þ*j B yÞ j d A g y, то First1(g y)Í Follow1(A).
2.1. Неверно, что gÞ*l, тогда First1(gy)=First1(g).
2.2. gÞ*l, тогда First1(gy)=First1(g)ÈFirst1(y).
Поэтому Follow1(A)={ First1(Xm)/ B®d A X1 X2…XnÎR&m=1ÚX1X2…XmÞ*l}È {Follow1(B)/B®d A g ÎR &gÞ*l}
Т. е. просматриваются все правые части правил, в которые входит исследуемый нетерминал.
Рассмотрим грамматику
![]() S’® S $
S’® S $
S ® ABC½CA
A®a½l
B ® b B½l
C®cC½d
Здесь Nl={A, B}
Follow1(S)={$},
Follow1(A)= First1(B)È First1(C) È Follow1(S)={b, c, d, $},
Follow1(B)= First1(C)={c, d},
Follow1(C)= First1(A) )È Follow1(S)={a,$}.
Проанализируем LL(1) свойство грамматики:
MSABC= First1(A)È First1(B)È First1(C)={a, b, c, d},
MSCA= First1(C)={c, d}.
Т. к. MSABC ÇMSCA¹Æ , то грамматика не является LL(1) –грамматикой.
Восходящий анализ.
При восходящем анализе цепочка сворачивается путем применения правил в обратном порядке (дерево вывода строится снизу вверх).
Введенные строки анализируются слева направо, полученные подстроки сопоставляются в правыми частями грамматики, и при совпадении заменяются на соответствующий нетерминальный символ в левой части правила (свёртка). Цепочка, заменяемая на этот символ, называется основой.
Если свёртываемая основа выбирается случайно, то может потребоваться возврат, и число шагов построения вывода пропорционально длине цепочки.
Среди грамматик выделяется класс LR(k) грамматик - тот тип грамматик, для которых однозначно восстанавливается правый вывод (R) при чтении цепочки слева (L) направо, при подглядывании вперёд не более чем на k символов.
Алгоритм такого разбора в общем случае сложен, поэтому чаще всего рассматривается удобный подкласс ГПП (грамматики простого предшествования) – частный случай LR(k) грамматик, в которых для выделения основы используются отношения простого предшествования.
Пусть цепочка X получена G=< VT,VN, S, R> с помощью правого вывода:
SÞb1Þb2Þ….Þbn=X Î(VT)*.
Тогда при восходящем анализе будем иметь
X=bn ├ bn-1 …├ b0 = S.
Выделим i-ый шаг вывода SÞ*aAy (=bi-1)Þ a j y (=bi)Þ*x y, здесь aAy текущее состояние правого вывода, A – самый правый нетерминал в выводе. Свёртка состоит в переходе от a j y к aAy, (a j y├ aAy) т. е. мы должны выделить подцепочку j, которая сворачивается в нетерминал A применением правила AÞ j в обратном порядке.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
