
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
На правах рукописи
МАТЕМАТИЧЕСКОЕ МОДЕЛИРОВАНИЕ СЕГМЕНТАЦИИ РЫНКА
С ИСПОЛЬЗОВАНИЕМ ДВУХУРОВНЕВОГО ПОДХОДА
05.13.18 – Математическое моделирование, численные методы
и комплексы программ
АВТОРЕФЕРАТ
диссертации на соискание учёной степени
кандидата физико-математических наук
Ростов-на-Дону – 2007
Работа выполнена на кафедре прикладной математики Карачаево-Черкесской государственной технологической академии
Научный руководитель
доктор физико-математических наук,
профессор
Официальные оппоненты:
доктор физико-математических наук,
профессор
кандидат физико-математических наук,
профессор
Ведущая организация: Ростовский государственный экономический
университет "РИНХ"
Защита диссертации состоится “ 1 ” ноября 2007 г. в 11-00 часов на заседании диссертационного совета К 212.208.04 по физико-математическим и техническим наукам в Южном Федеральном Университете г. Ростов-на-Дону, пр. Стачки 200/1, корпус 2, ЮГИНФО ЮФУ, к. 206.
С диссертацией можно ознакомиться в Зональной научной библиотеке ЮФУ по адресу: г. Ростов-на-Дону, .
Автореферат разослан “_____” ______________ 2007 г.
Ученый секретарь
диссертационного совета, д. ф.-м. н., доцент
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы. Математическое моделирование является важнейшим инструментом познания окружающего мира. Особенностью развития математического моделирования на современном этапе является то, что оно все больше используется для исследования социально-экономических объектов, явлений и процессов. Одним из таких объектов является сегментация рынка.
В современную эпоху, эпоху глобализации, для того, чтобы добиться успеха фирме (компании, организации, предприятию) недостаточно производить продукцию (или оказывать услуги) высокого качества: необходимо знать и учитывать потребности покупателей, их желания, возможности. Однако, потребители в своей массе разнородны: разные покупатели имеют различные потребности, интересы, характеризуются различными признаками (возраст, пол, доход и т. п.).
Сегментация рынка, важнейший этап и фундамент любого маркетингового исследования, заключается в разделении потребителей на группы (сегменты) так, чтобы покупатели внутри группы обладали примерно одинаковыми потребностями и характеристиками. На основе полученного разбиения рынка на сегменты разрабатываются маркетинговые стратегии, модели, позволяющие фирме более полно использовать свои конкурентные преимущества, максимально эффективно использовать имеющиеся ресурсы.
Для сегментации рынка необходимы исходные данные. Отличительными особенностями таких данных являются многомерность, т. е. каждый исследуемый объект характеризуется некоторым набором признаков, разнотипность (признаки измерены по разным шкалам) и неточность (неполнота) данных. Многомерность, разнотипность и неполнота данных значительно усложняют их обработку и анализ, затрудняют процесс разработки модели сегментации рынка. Поэтому особенно актуальной становится разработка модели исходных данных, позволяющая учесть особенности данных.
Для проведения сегментации чаще всего используются следующие методы: дискриминантный анализ (параметрические и непараметрические методы), различные алгоритмы кластерного анализа, гибкая сегментация, многоступенчатые методы и т. д. Однако, существующие подходы обладают значительными недостатками: 1) серьезные ограничения, налагаемые на исходные данные (обязательное отсутствие или, наоборот, присутствие корреляций, подчиненность нормальному или другому распределению и т. п.); 2) чувствительность к неполноте, к шуму в исходных данных; 3) невозможность выполнения на практике теоретических допущений, заложенных в вышеупомянутых методах, что влечет за собой малоизученные ошибки; 4) большая роль эксперта на некоторых стадиях проведения сегментации (особенно в кластерном анализе, гибкой сегментации, многоступенчатых методах); 5) для большинства методов требуется однотипность данных и т. д.
Для преодоления вышеперечисленных обстоятельств в диссертационном исследовании разработан двухуровневый подход к математическому моделированию сегментации рынка. На нижнем уровне моделирования исходные данные (разнотипные и неточные) преобразуются к виду, удобному для использования на верхнем уровне. Задача сегментации на верхнем уровне моделирования определяется как задача многокритериальной дискретной оптимизации.
Таким образом, математическое моделирование сегментации рынка в условиях многокритериальности и неопределенности данных с использованием двухуровневого подхода является актуальной проблемой.
Степень разработанности проблемы. Сегментация рынка как раздел маркетинга подробно исследуется в работах ,
На нижнем уровне моделирования сегментации рынка строится модель разнотипных и неточных данных, позволяющая проводить сегментацию согласно выбранным критериям, описывать выделенные сегменты и получать классифицирующую функцию с учетом неполноты и неточности исходных данных. Методы обработки разнотипных данных рассматривались , , подходы к построению нечетких классификаций – в работах ,
При моделировании сегментации на верхнем уровне используется аппарат теории многокритериальной дискретной оптимизации, которая получила развитие в работах ученых: , , и др. В настоящей диссертационной работе для проведения сегментации предложены приближенные эффективные (полиномиальные) алгоритмы покрытия интервально взвешенного графа звездами. Разработка и исследование таких алгоритмов в настоящее время находится на начальной стадии развития.
Объектом исследования диссертационной работы является сегментация рынка как важнейшая задача маркетинга, решение которой позволяет компании (фирме, предприятию, организации) получить конкурентное преимущество и в результате добиться успеха.
Предмет исследования: построение математической модели сегментации рынка и разработка математических алгоритмов сегментации.
Цель и задачи исследования. Целью диссертационного исследования является построение двухуровневой модели сегментации рынка, разработка алгоритмов сегментации, позволяющих находить разбиение на сегменты в условиях разнотипности и неточности исходных данных, а также создание программного комплекса, реализующего разработанные алгоритмы.
В соответствии с целью необходимо решить задачи:
– разработать схему двухуровневого моделирования сегментации рынка;
– разработать на нижнем уровне модель исходных данных;
– построить на верхнем уровне теоретико-графовую модель задачи сегментации как многокритериальной задачи с вектором критериев специального вида (в том числе с интервальными весами ребер), исследовать свойства задачи сегментации;
– разработать приближенные полиномиальные алгоритмы (включая доказательство их асимптотической точности либо статистической эффективности) для решения задачи сегментации как многокритериальной задачи покрытия графа звездами, в том числе и с интервальными данными;
– разработать способы описания полученных сегментов с учетом неполноты и неточности информации, построить классифицирующую функцию;
– разработать программный комплекс, позволяющий проводить сегментацию рынка с учетом двухуровневого подхода к моделированию сегментации рынка.
Методы диссертационного исследования основываются на использовании аппарата теории графов, методов теории сложности дискретных задач, аппарата интервального исчисления, теории алгоритмов с оценками и теории вероятностного анализа алгоритмов, дискретного анализа, методов теории нечетких множеств и нечетких отношений.
Основные результаты диссертационной работы соответствуют пункту 1 "Паспорта специальности 05.13.18 – Математическое моделирование, численные методы и комплексы программ": "Разработка новых математических методов моделирования объектов и явлений, перечисленных в формуле специальности".
Научная новизна заключается в следующем.
1. Разработан двухуровневый подход к математическому моделированию сегментации рынка, в рамках которого исследуемая задача сводится к многокритериальной (с вектором критериев специального вида) задаче покрытия взвешенного графа звездами, в том числе и с интервальными весами. Исследованы свойства задачи сегментации рынка.
2. Разработаны приближенные полиномиальные методы для проведения сегментации рынка в случае интервальных данных, т. е. алгоритмы покрытия интервальновзвешенного графа звездами. Доказаны достаточные условия их асимптотической точности либо статистической эффективности.
3. При моделировании сегментации рынка усовершенствованы: 1) методы представления разнотипных исходных данных в булевом пространстве;
2) методы описания закономерностей сегментов, полученных с помощью разработанных алгоритмов сегментации, путем построения системы булевых функций.
4. Результатами моделирования сегментации рынка являются разбиение на сегменты и классифицирующая функция. Для рассматриваемой модели сегментации рынка разработан метод построения классифицирующей функции.
5. Для проведения сегментации рынка разработан программный комплекс, описанный в приложениях, который позволяет проводить унификацию разнотипных исходных данных, полученных из анкет покупателей, проводить сегментацию рынка алгоритмами, построенными в диссертации, получить классифицирующую функцию.
Достоверность полученных результатов подтверждается строгими математическими формулировками и доказательствами с использованием аппарата теории графов, теории вероятностей, теории нечетких множеств, интервального исчисления и теории вычислительной сложности алгоритмов, а также сравнением с результатами, уже описанными в существующей литературе.
Положения, выносимые на защиту:
1. Концепция двухуровневого подхода к математическому моделированию сегментации рынка, где на нижнем уровне моделирования рассматриваются методы построения унифицированной модели данных, позволяющей преодолеть разнотипность исходных данных, а на верхнем уровне – моделирование сегментации как многокритериальной экстремальной задачи, в том числе и с интервальными данными.
2. Полиномиальные асимптотически точные алгоритмы, построенные для проведения сегментации при подходе post hoc и реализованные в программном комплексе.
3. Полиномиальные статистически эффективные методы, реализованные в программном комплексе, предназначенные для моделирования сегментации рынка при подходе a priory в интервальной и многокритериальной постановках.
4. Усовершенствованные методы унифицированного булева представления исходных данных и описания закономерностей сегмента в виде булевой функции.
5. Метод построения классифицирующей функции, являющейся результатом математического моделирования сегментации рынка, на основе разделения рынка на нечеткие сегменты.
Практическая значимость определяется двухуровневым подходом к моделированию сегментации рынка, который дает возможность проводить сегментацию в ситуации, когда исходные данные разнотипны и неточны. Приближенные алгоритмы проведения сегментации полиномиальной вычислительной сложности позволяют получать разбиение на сегменты за приемлемое время. Разработанный подход позволяет существенно автоматизировать процесс сегментации и минимизировать участие экспертов-маркетологов в проведении сегментации рынка.
Апробация работы. Результаты диссертации докладывались и обсуждались на 7-м Международном симпозиуме "Математическое моделирование и компьютерные технологии" (Кисловодск, 2005); на 4-й Международной научно-практической конференции "Проблемы регионального управления, экономики, права и инновационных процессов в образовании" (Таганрог, 2005 г.); на 6-й региональной научно-практической конференции "Рациональные пути решения социально-экономических и научно-технических проблем региона" (Черкесск, 2006); на 17-й Международной конференции по применению компьютерных технологий и математики в архитектуре и гражданском строительстве (Веймар, Германия, 2006); на IX Международной конференции "Интеллектуальные системы и компьютерные науки" (Москва, 2006); на 3-й Международной конференции "Нелокальные краевые задачи и родственные проблемы математической биологии, информатики и физики" (Нальчик, 2006); на Всероссийском симпозиуме "Математические модели и информационные технологии в экономике" (Кисловодск, 2007 г.); на научных семинарах кафедры прикладной математики Карачаево-Черкесской государственной технологической академии.
Отдельные результаты работы вошли в отчеты по гранту Российского фонда фундаментальных исследований, проект № а "Структурирование, выявление несоответствий и прогнозирование эволюционных дискретных процессов и систем при наличии долговременных корреляций".
Материалы по теме диссертационного исследования были использованы в курсах лекционных и семинарских занятий по дискретной математике, экономической кибернетике в Карачаево-Черкесской государственной технологической академии.
Публикации. Материалы диссертации отражены в 10 публикациях: 4 статьи, из которых 2 в изданиях ВАК, 6 тезисов докладов. Общий объем публикаций составляет 5,75 печ. л., из которых автору принадлежит 4,0 печ. л.
Вклад автора в работе в [2] заключается в постановке проблемы, в [3] – в доказательстве труднорешаемости задачи сегментации, в работе [6] – доказательство неразрешимости задачи сегментации с помощью алгоритмов линейной свертки критериев, в работе [7] – алгоритм покрытия графа звездами, в [9] – доказательство полноты интервальных задач на графах.
Структура и объем работы. Диссертация состоит из введения, четырех глав, заключения, списка литературы, 8 приложений. Основной текст диссертации (без учета приложений) составляет 164 страницы, содержит 8 таблиц, 4 рисунка, библиография насчитывает 126 наименований. В приложениях содержится 13 рисунков и 1 таблица.
СОДЕРЖАНИЕ РАБОТЫ
Во введении обосновывается актуальность темы диссертации, сформулированы цель и задачи диссертационной работы, научная новизна и практическая значимость, указаны основные положения, выносимые на защиту.
В первой главе дано определение сегментации рынка, вводятся необходимые понятия из области маркетинга. Для задачи сегментации рынка характерны множественность критериев сегментации, неточность и разнотипность данных, неоднозначность при описании сегментов, порождаемая неопределенностью параметров задачи. В результате проведенного анализа определено, что существующие методы сегментации делятся на 2 категории: 1) методы a priory (известна гипотеза сегментации[1], примерное количество сегментов) и 2) методы post hoc (гипотеза сегментации перед проведением исследования неизвестна). Существующие методы сегментации обладают рядом недостатков и дают лишь частичную возможность учета выделенных факторов неопределенности и требований специального вида, предъявляемых к получаемым решениям. Отсюда вытекает необходимость разработки двухуровневого подхода к моделированию сегментации рынка.
В главе формализуется понятие сегментации, рассматривается связь между задачей сегментации и классификацией. Было определено, что существующие методы классификации не позволяют учесть все условия, возникающие при постановке задачи сегментации, и все требования, предъявляемые к получаемому решению. Поэтому в главе рассматривается двухуровневый подход к математическому моделированию задачи сегментации, приводится его общая схема, в рамках которой на нижнем уровне проводится моделирование исходных данных, а на верхнем – разработка алгоритмов сегментации. На верхнем уровне используется теоретико-графовая модель сегментации рынка как многокритериальной задачи покрытия взвешенного графа звездами, в том числе и с интервальными данными.
При подходе a priory математическая постановка многокритериальной задачи сегментации формулируется на двудольном графе ![]() ,
, ![]() и
и ![]() ,
, ![]() . Вершины
. Вершины ![]() ,
, ![]() , поставлены во взаимнооднозначное соответствие предъявленным видам товара. Вершины
, поставлены во взаимнооднозначное соответствие предъявленным видам товара. Вершины ![]() ,
,![]() , поставлены во взаимнооднозначное соответствие потребителям. Каждое ребро
, поставлены во взаимнооднозначное соответствие потребителям. Каждое ребро ![]() графа
графа ![]() взвешено числами
взвешено числами ![]() ,
, ![]() , где веса
, где веса ![]() отражают собой критерии потребительской пригодности
отражают собой критерии потребительской пригодности 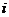 -го типа товара для покупателей из группы
-го типа товара для покупателей из группы ![]() ,
, 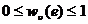 ,
, ![]() ,
, ![]() .
.
Допустимым решением формулируемой на двудольном графе 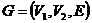 задачи сегментации является всякая такая его часть (или подграф)
задачи сегментации является всякая такая его часть (или подграф) 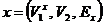 ,
, ![]() ,
, 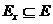 графа , каждая компонента связности которой (которого) представляет собой либо некоторое ребро
графа , каждая компонента связности которой (которого) представляет собой либо некоторое ребро ![]() , либо
, либо ![]() -вершинную звезду,
-вершинную звезду, ![]() , центром которой является некоторая вершина
, центром которой является некоторая вершина ![]() и ребра которой образуют множество
и ребра которой образуют множество ![]() ,
, ![]() . Вводится также ограничение, связывающее количество
. Вводится также ограничение, связывающее количество ![]() покупаемых потребителями единиц
покупаемых потребителями единиц ![]() -го типа товара и минимально допустимое количество
-го типа товара и минимально допустимое количество ![]() экземпляров товара этого типа, при котором его производство (или реализация) оказывается экономически выгодным:
экземпляров товара этого типа, при котором его производство (или реализация) оказывается экономически выгодным:
| (1) |
где центр ![]() ,
, ![]() и объединение
и объединение ![]() . При этом неравенство (1) не учитывается для вершин
. При этом неравенство (1) не учитывается для вершин 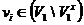 .
.
На множестве всех допустимых решений (МДР) ![]() определена векторная целевая функция (ВЦФ):
определена векторная целевая функция (ВЦФ):
, | (2) |
состоящая из ![]() критериев весового вида MAXSUM
критериев весового вида MAXSUM
| (3) |
и одного критерия комбинаторного вида
, | (4) |
отражающего разнообразие номенклатуры, т. е. количество типов (товара), которые целесообразно производить или продавать. ВЦФ (2)-(3) определяет собой в МДР ![]() паретовское множество (ПМ)
паретовское множество (ПМ) ![]() , состоящее из всех паретовских оптимумов (ПО)
, состоящее из всех паретовских оптимумов (ПО) ![]() . В диссертационном исследовании рассматривается алгоритмическая проблема нахождения полного множества альтернатив (ПМА).
. В диссертационном исследовании рассматривается алгоритмическая проблема нахождения полного множества альтернатив (ПМА).
В реальных условиях значения весов ![]() ,
, ![]() , имеют приближенный характер. Для отражения неопределенности подобного рода в математической модели используется интервальное представление данных. Пусть известны минимально возможное
, имеют приближенный характер. Для отражения неопределенности подобного рода в математической модели используется интервальное представление данных. Пусть известны минимально возможное ![]() и максимально возможное
и максимально возможное ![]() значения признака сегментации
значения признака сегментации ![]() , тогда вес ребра
, тогда вес ребра ![]() представляется в виде интервала
представляется в виде интервала ![]() ,
, ![]() .
.
Интервальная задача сегментации определяется как задача покрытия двудольного графа ![]() - звездами,
- звездами, ![]() , для однокритериального
, для однокритериального ![]() случая. Каждое ребро
случая. Каждое ребро ![]() графа
графа ![]() взвешено интервалом
взвешено интервалом ![]() ,
, ![]() . Допустимое решение формулируемой на двудольном графе
. Допустимое решение формулируемой на двудольном графе ![]() интервальной задачи сегментации определяется аналогично многокритериальному случаю. На МДР
интервальной задачи сегментации определяется аналогично многокритериальному случаю. На МДР ![]() определена векторная целевая функция, отражающая интервальное задание весов
определена векторная целевая функция, отражающая интервальное задание весов
| (5) |
состоящая из весового критерия вида MAXSUM
| (6) |
где ![]() ,
, 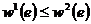 ,
, 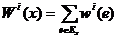 ,
, ![]() , и одного критерия комбинаторного вида (аналогичного (4))
, и одного критерия комбинаторного вида (аналогичного (4))
| (7) |
отражающего разнообразие номенклатуры товара.
При подходе post hoc задача сегментации рассматривается на полном графе. Вершины полного графа соответствуют потребителям, а веса ребер полного графа определяются как степени близости потребителей, вычисленные с помощью коэффициента Жаккара ![]() : – число пар значений компонент
: – число пар значений компонент ![]() векторов
векторов ![]() вида
вида ![]() ,
, ![]() ; – число пар значений компонент
; – число пар значений компонент ![]() векторов
векторов ![]() вида
вида ![]() ,
, ![]() ; – число пар значений компонент
; – число пар значений компонент ![]() векторов
векторов ![]() вида
вида ![]() ,
, ![]() ; – число пар значений компонент
; – число пар значений компонент ![]() векторов
векторов ![]() вида
вида ![]() ,
, ![]() . Решением задачи сегментации в случае post hoc, как и в случае a priory, является покрытие графа звездами.
. Решением задачи сегментации в случае post hoc, как и в случае a priory, является покрытие графа звездами.
Допустимым решением формулируемой на полном графе ![]() задачи сегментации является всякая такая его часть (или подграф)
задачи сегментации является всякая такая его часть (или подграф) ![]() , графа
, графа 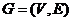 , каждая компонента связности которой (которого) представляет собой либо некоторое ребро
, каждая компонента связности которой (которого) представляет собой либо некоторое ребро ![]() , либо
, либо ![]() -вершинную звезду, центром которой является некоторая вершина
-вершинную звезду, центром которой является некоторая вершина ![]() .
.
Критериями качества в этом случае являются весовой критерий
| (8) |
и комбинаторный критерий количества звезд в покрытии
| (9) |
В интервальном случае задача сегментации post hoc формулируется на графе 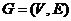 . Каждое ребро
. Каждое ребро ![]() графа
графа ![]() взвешено интервалом
взвешено интервалом ![]() ,
, 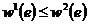 . Допустимым решением в этом случае является такой остовный подграф
. Допустимым решением в этом случае является такой остовный подграф ![]() ,
, ![]() , в котором каждая компонента связности представляет собой
, в котором каждая компонента связности представляет собой ![]() -вершинную звезду. На МДР
-вершинную звезду. На МДР 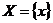 определена максимизируемая интервальная целевая функция (ИЦФ)
определена максимизируемая интервальная целевая функция (ИЦФ)
| (10) |
где при вычислении интервальнозначной функции ![]() осуществляется классическое суммирование интервалов
осуществляется классическое суммирование интервалов 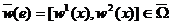 :
: ![]() , где
, где
| (11) |
Решением интервальной задачи является такой элемент ![]() , при котором ИЦФ (10) достигает максимального значения.
, при котором ИЦФ (10) достигает максимального значения.
Во второй главе рассматривается нижний уровень моделирования задачи сегментации, который подразумевает построение математической модели исходных данных. В главе построена математическая модель наблюдения в виде булева протокола наблюдения. На основе этой математической модели строится взвешенный граф, веса ребер которого получены с использованием коэффициента Жаккара.
Для моделирования сегментации рынка на нижнем уровне рассматривается представление данных, полученных в результате наблюдения, в табличном виде (протокол наблюдений).
Определение 1. Шкалой ![]() называется конечное или бесконечное множество значений, которое может принять некоторая переменная
называется конечное или бесконечное множество значений, которое может принять некоторая переменная ![]() . Шкалирование есть отображение возможных состояний переменной
. Шкалирование есть отображение возможных состояний переменной ![]() на множество значений шкалы:
на множество значений шкалы: ![]() .
.
Пусть набор признаков 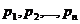 характеризует исследуемый объект наблюдения. Тогда каждому признаку
характеризует исследуемый объект наблюдения. Тогда каждому признаку ![]() ,
, ![]() ставится в соответствие переменная, называемая предметной переменной
ставится в соответствие переменная, называемая предметной переменной ![]() ,
, ![]() . Каждой предметной переменной
. Каждой предметной переменной ![]() ,
, ![]() , соответствует некоторая шкала измерений
, соответствует некоторая шкала измерений ![]() (предметная шкала). Множество предметных переменных
(предметная шкала). Множество предметных переменных ![]() ,
, ![]() , порождает множество предметных шкал
, порождает множество предметных шкал
| (12) |
Декартово произведение шкал (12) 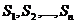 образует предметное пространство объекта наблюдения
образует предметное пространство объекта наблюдения
| (13) |
При решении задачи сегментации необходимо получить не только разбиение множества потребителей на сегменты, но классифицирующую функцию, позволяющую распределять потребителей по сегментам. В диссертационной работе под классификацией понимается отображение 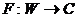 предметного пространства
предметного пространства ![]() пространство классификаций
пространство классификаций ![]() , или, согласно (13)
, или, согласно (13) ![]() , где вид классифицирующей функции
, где вид классифицирующей функции ![]() определяется предметным пространством явления. При разнотипности предметных шкал в задаче сегментации становится затруднительным решение вопроса о выборе вида классифицирующей функции
определяется предметным пространством явления. При разнотипности предметных шкал в задаче сегментации становится затруднительным решение вопроса о выборе вида классифицирующей функции ![]() . Для решения этой проблемы используется представление всех данных в унифицированном виде, т. е. при
. Для решения этой проблемы используется представление всех данных в унифицированном виде, т. е. при ![]() получаем
получаем ![]() . Определяется формальное преобразование предметного пространства
. Определяется формальное преобразование предметного пространства ![]() в пространство унифицированного булева представления. Реализация унифицированного представления является двухэтапной. На первом этапе, на основании исходных данных, строится стандартная предметная таблица протокола. На втором этапе табличное представление сводится к унифицированному булевому представлению, которое и служит моделью данных. Для этого рассматривается задача булева разложения признака. Дан признак
в пространство унифицированного булева представления. Реализация унифицированного представления является двухэтапной. На первом этапе, на основании исходных данных, строится стандартная предметная таблица протокола. На втором этапе табличное представление сводится к унифицированному булевому представлению, которое и служит моделью данных. Для этого рассматривается задача булева разложения признака. Дан признак ![]() , для измерения которого определена шкала измерения
, для измерения которого определена шкала измерения ![]() , т. е. определено отображение
, т. е. определено отображение ![]() . Пусть
. Пусть ![]() – конечное множество и задано отображение
– конечное множество и задано отображение ![]() . Для булева разложения признака рассматривается семейство предикатов
. Для булева разложения признака рассматривается семейство предикатов ![]() :
:
|
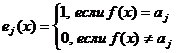 ,
, Каждый предикат проверяет равенство значения функции ![]() от измеренного по шкале
от измеренного по шкале ![]() значения признака
значения признака ![]() определённому элементу множества
определённому элементу множества ![]() . Семейство предикатов
. Семейство предикатов ![]() определяет собой отображение
определяет собой отображение ![]() , которое определено правилом
, которое определено правилом ![]() , где
, где ![]() – булево пространство. Булевым разложением признака называется суперпозиция отображений
– булево пространство. Булевым разложением признака называется суперпозиция отображений ![]() и
и ![]() :
: ![]() . Для булева разложения стандартной предметной таблицы протокола наблюдения для каждого предметного признака
. Для булева разложения стандартной предметной таблицы протокола наблюдения для каждого предметного признака ![]() , измеренного по шкале
, измеренного по шкале ![]() , выбирается композиция отображений
, выбирается композиция отображений ![]() . Построенная таким образом таблица является булевым протоколом
. Построенная таким образом таблица является булевым протоколом ![]() наблюдения.
наблюдения.
Результатом моделирования на нижнем уровне является либо двудольный взвешенный граф ![]() (сегментация a priory), либо полный взвешенный граф
(сегментация a priory), либо полный взвешенный граф 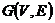 (сегментация post hoc), веса ребер которых получены на основе булева протокола наблюдения
(сегментация post hoc), веса ребер которых получены на основе булева протокола наблюдения ![]() с использованием коэффициента Жаккара. Вершины графа ставятся во взаимнооднозначное соответствие строкам булевого протокола
с использованием коэффициента Жаккара. Вершины графа ставятся во взаимнооднозначное соответствие строкам булевого протокола ![]() , а ребру
, а ребру ![]() присваивается вес, равный коэффициенту Жаккара, т. е. вычисляется мера близости вершин
присваивается вес, равный коэффициенту Жаккара, т. е. вычисляется мера близости вершин ![]() и
и ![]() . В случае интервальных данных веса ребер представляют собой интервалы, каждый из которых содержит вес соответствующего ребра для точного случая.
. В случае интервальных данных веса ребер представляют собой интервалы, каждый из которых содержит вес соответствующего ребра для точного случая.
В третьей главе рассматривается верхний уровень моделирования задачи сегментации на базе теоретико-графового подхода. Исследованы свойства задачи сегментации, в том числе и для интервального задания весов; доказывается труднорешаемость задачи сегментации в интервальной и многокритериальной постановках; разрабатываются приближенные алгоритмы полиномиальной вычислительной сложности, приводится обоснование достаточных условий их асимптотической точности либо статистической эффективности. Были получены следующие результаты.
Теорема 1. При ![]() проблема нахождения ПМА задачи сегментации с ВЦФ (2)-(3) является труднорешаемой.
проблема нахождения ПМА задачи сегментации с ВЦФ (2)-(3) является труднорешаемой.
Следствие 1. Интервальная задача сегментации с ВЦФ (5)-(7) является труднорешаемой.
Отсюда возникает необходимость в разработке малотрудоемких приближенных алгоритмов решения задачи сегментации.
В главе используется эквивалентность интервальной задачи сегментации и производной двукритериальной задачи. Эта эквивалентность дает возможность проводить единое исследование алгоритмических проблем задачи сегментации как для векторного представления, так и для интервального представления критерия качества.
Среди методов отыскания паретооптимальных решений векторных задач, т. е. элементов ![]() , наиболее распространены алгоритмы линейной свертки критериев (АЛСК). Доказывается неразрешимость задачи сегментации в интервальной и многокритериальной постановках с помощью алгоритмов линейной свертки критериев. Применение АЛСК дает возможность получить только аппроксимацию искомого множества решений поставленной задачи в интервальной и многокритериальной постановках.
, наиболее распространены алгоритмы линейной свертки критериев (АЛСК). Доказывается неразрешимость задачи сегментации в интервальной и многокритериальной постановках с помощью алгоритмов линейной свертки критериев. Применение АЛСК дает возможность получить только аппроксимацию искомого множества решений поставленной задачи в интервальной и многокритериальной постановках.
Теорема 2. Интервальная задача сегментации с учетом неравенства (1) и ИЦФ (6) неразрешима с помощью АЛСК.
Теорема 3. Многокритериальная задача сегментации с условием (1) и ВЦФ (2)-(4) неразрешима с помощью АЛСК.
Для решения задачи сегментации при подходе post hoc используется алгоритм ![]() . Исходная информация на входе алгоритма
. Исходная информация на входе алгоритма ![]() состоит из описания
состоит из описания ![]() -вершинного 1-взвешенного полного графа
-вершинного 1-взвешенного полного графа ![]() и заданного множества типов звезд
и заданного множества типов звезд 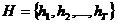 ,
, ![]() . Алгоритм заключается в разбиении графа
. Алгоритм заключается в разбиении графа ![]() на подграфы
на подграфы ![]() ,
, ![]() , из которых строится набор двудольных графов
, из которых строится набор двудольных графов 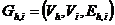 ,
, 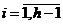 ; в каждом двудольном графе выделяется совершенное паросочетание. Объединение всех полученных паросочетаний образует
; в каждом двудольном графе выделяется совершенное паросочетание. Объединение всех полученных паросочетаний образует ![]() -дольный остовной подграф
-дольный остовной подграф ![]()
![]() , который представляет собой допустимое решение
, который представляет собой допустимое решение ![]() (покрытие графа звездами) рассматриваемой задачи на полном графе.
(покрытие графа звездами) рассматриваемой задачи на полном графе.
Лемма 1. Допустимое решение ![]() , полученное в результате применения алгоритма
, полученное в результате применения алгоритма ![]() к 1-взвешенному полному графу, является оптимальным по критерию (9).
к 1-взвешенному полному графу, является оптимальным по критерию (9).
Пусть ![]() – монотонно возрастающая последовательность чисел
– монотонно возрастающая последовательность чисел ![]() ,
, 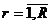 на отрезке
на отрезке ![]() ,
, ![]() ,
, ![]() ,
, ![]() ;
; 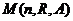 – множество полных
– множество полных ![]() -вершинных 1-взвешенных графов, ребрам которых приписаны веса
-вершинных 1-взвешенных графов, ребрам которых приписаны веса 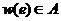 при фиксированных параметрах
при фиксированных параметрах ![]() ,
, ![]() ,
, ![]() ;
; ![]() – произвольная, сколь угодно медленно растущая функция,
– произвольная, сколь угодно медленно растущая функция, ![]() с ростом
с ростом ![]() ;
; ![]() – вероятностный
– вероятностный ![]() -вершинный полный граф, в котором его произвольному ребру
-вершинный полный граф, в котором его произвольному ребру ![]() приписывается вес
приписывается вес ![]() , с вероятностью
, с вероятностью ![]() согласно распределению вероятностей
согласно распределению вероятностей
| (14) |
где ![]() – интегральная функция распределения,
– интегральная функция распределения, ![]() .
.
Теорема 4. Если распределение весов ребер графа ![]() удовлетворяет неравенству
удовлетворяет неравенству ![]() , то с вероятностью
, то с вероятностью 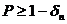 ,
, 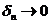 при
при ![]() решение
решение ![]() , полученное с помощью алгоритма
, полученное с помощью алгоритма ![]() , является асимптотически точным. При этом вычислительная сложность этого алгоритма
, является асимптотически точным. При этом вычислительная сложность этого алгоритма ![]() .
.
В главе предложен асимптотически точный алгоритм ![]() для интервальной задачи сегментации post hoc. Предварительно каждому ребру исходного интервальновзвешенного графа присваивается значение линейной свертки значений границ его весового интервала, а затем находится допустимое решение. Алгоритм
для интервальной задачи сегментации post hoc. Предварительно каждому ребру исходного интервальновзвешенного графа присваивается значение линейной свертки значений границ его весового интервала, а затем находится допустимое решение. Алгоритм ![]() является модификацией алгоритма
является модификацией алгоритма ![]() для случая интервальных весов ребер.
для случая интервальных весов ребер.
Асимптотическая точность алгоритма ![]() доказана аналогично обоснованию асимптотической точности базового алгоритма
доказана аналогично обоснованию асимптотической точности базового алгоритма ![]() . Пусть ребра графа
. Пусть ребра графа ![]() взвешены интервалами из множества интервалов
взвешены интервалами из множества интервалов ![]() ,
, ![]() ,
, ![]() , т. е. для ребра
, т. е. для ребра ![]() его вес
его вес ![]() ,
, ![]() ,
, ![]() . При фиксированном
. При фиксированном ![]() к элементам
к элементам ![]() применяется операция преобразования их в линейную свертку (ЛС)
применяется операция преобразования их в линейную свертку (ЛС) ![]() ,
, ![]() . Через
. Через ![]() обозначено упорядоченное по возрастанию множество
обозначено упорядоченное по возрастанию множество 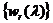 ,
, ![]() , а через
, а через ![]() – вероятностный
– вероятностный ![]() -вершинный полный граф, в котором всякому его ребру приписывается вес ЛС
-вершинный полный граф, в котором всякому его ребру приписывается вес ЛС 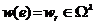 с вероятностью
с вероятностью ![]() согласно распределению вероятностей (14).
согласно распределению вероятностей (14).
Теорема 5. Если распределение вероятностей (14) для весов ребер графа ![]() удовлетворяет неравенству
удовлетворяет неравенству ![]() , то с вероятностью
, то с вероятностью ![]() , при
, при ![]() решение
решение ![]() , полученное с помощью алгоритма
, полученное с помощью алгоритма ![]() , является асимптотически точным. При этом вычислительная сложность этого алгоритма
, является асимптотически точным. При этом вычислительная сложность этого алгоритма ![]() .
.
Для задачи сегментации в многокритериальной и интервальной постановках (подход a priory) предложены алгоритмы ![]() и
и ![]() , являющиеся статистически эффективными.
, являющиеся статистически эффективными.
Для задачи сегментации в многокритериальной постановке предложен алгоритм ![]() : множество вершин второй доли
: множество вершин второй доли ![]() разбивается на подмножества
разбивается на подмножества ![]() ,
, ![]() ,
, ![]() ,
, ![]() . Для каждого подмножества
. Для каждого подмножества ![]() строится двудольный граф
строится двудольный граф ![]() , где множество
, где множество ![]() состоит из ребер, у каждого из которых концевая вершина
состоит из ребер, у каждого из которых концевая вершина ![]() и концевая вершина
и концевая вершина ![]() . В результате имеется последовательность двудольных графов
. В результате имеется последовательность двудольных графов ![]() ,
, ![]() . Затем в каждом графе
. Затем в каждом графе ![]() находится совершенное паросочетание
находится совершенное паросочетание 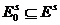 . Алгоритм завершается построением остовного подграфа
. Алгоритм завершается построением остовного подграфа ![]() , множество ребер которого
, множество ребер которого 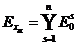 .
.
По определению алгоритма ![]() остовной подграф является допустимым решением задачи покрытия данного графа
остовной подграф является допустимым решением задачи покрытия данного графа ![]() звездами.
звездами.
В алгоритме ![]() используется вспомогательный алгоритм
используется вспомогательный алгоритм ![]() нахождения решения задачи о совершенном паросочетании в
нахождения решения задачи о совершенном паросочетании в ![]() -критериальной постановке на двудольном графе с критериями вида (3).
-критериальной постановке на двудольном графе с критериями вида (3).
Пусть ![]() – множество всех
– множество всех ![]() -взвешенных двудольных
-взвешенных двудольных ![]() - вершинных графов
- вершинных графов ![]() с равномощными долями
с равномощными долями ![]() , у которых каждое ребро
, у которых каждое ребро ![]() взвешено числами
взвешено числами ![]() ,
, ![]() ;
; ![]() – произвольная, сколь угодно медленно растущая функция
– произвольная, сколь угодно медленно растущая функция 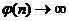 с ростом
с ростом ![]() .
.
Лемма 2. Если ![]() , то для почти всех двудольных графов
, то для почти всех двудольных графов 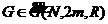 алгоритм
алгоритм ![]() находит ПМА задачи о совершенных паросочетаниях с ВЦФ (1), (3), причем
находит ПМА задачи о совершенных паросочетаниях с ВЦФ (1), (3), причем ![]() и сложность нахождения ПМА
и сложность нахождения ПМА ![]() .
.
Обозначим через 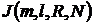 множество
множество ![]() -взвешенных двудольных графов
-взвешенных двудольных графов ![]() , с мощностями долей
, с мощностями долей ![]() ,
, ![]() ,
, ![]() , в каждом из которых всякому ребру
, в каждом из которых всякому ребру ![]() приписаны веса
приписаны веса ![]() ,
, ![]() .
.
Теорема 6. Если ![]() и
и 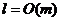 , то для почти всех графов
, то для почти всех графов ![]() алгоритм
алгоритм ![]() находит ПМА задачи сегментации с ВЦФ (2)-(4), причем ПМА является одноэлементным
находит ПМА задачи сегментации с ВЦФ (2)-(4), причем ПМА является одноэлементным ![]() и сложность его нахождения
и сложность его нахождения 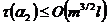 .
.
Для решения интервальной задачи сегментации в главе предложен приближенный двухуровневый алгоритм ![]() .
.
Обозначим через множество 1-взвешенных двудольных графов ![]() с мощностями долей
с мощностями долей ![]() ,
, ![]() ,
, ![]() , y которых каждому ребру
, y которых каждому ребру ![]() приписан вес
приписан вес ![]() , представляющий собой интервал из множества интервалов
, представляющий собой интервал из множества интервалов ![]() ,
, 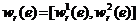 ,
, ![]() ,
, ![]() , где элемент
, где элемент 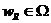 является максимальным.
является максимальным.
Теорема 7. Если ![]() , то для почти всех графов алгоритм
, то для почти всех графов алгоритм ![]() находит ПМА задачи покрытия полного интервальновзвешенного графа звездами с ИЦФ (6), причем ПМА является одноэлементным
находит ПМА задачи покрытия полного интервальновзвешенного графа звездами с ИЦФ (6), причем ПМА является одноэлементным 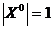 и сложность его нахождения
и сложность его нахождения ![]() .
.
В четвертой главе исследуется метод построения аналитической записи закономерностей полученных сегментов в виде булевой функции, проводится построение нечетких законов сегментов и классифицирующей функции (с учетом неполноты информации) с использованием методов нечеткой классификации.
Если на некотором булевом протоколе наблюдения задано разбиение на сегменты 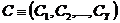 , то строки этой таблицы группируются по принадлежности к определенному сегменту. В результате получаются булевы протоколы сегментов. Булев протокол сегмента
, то строки этой таблицы группируются по принадлежности к определенному сегменту. В результате получаются булевы протоколы сегментов. Булев протокол сегмента ![]() является таблицей истинности для булевой функции
является таблицей истинности для булевой функции ![]() сегмента
сегмента ![]() от
от ![]() переменных
переменных
|
областью определения которой является предметное пространство ![]() , а областью истинности является множество векторов булевого протокола сегмента. Синтезирована булева формула для функции
, а областью истинности является множество векторов булевого протокола сегмента. Синтезирована булева формула для функции ![]() с использованием стандартной процедуры алгебры логики для записи совершенной дизъюнктивной нормальной формы (СДНФ):
с использованием стандартной процедуры алгебры логики для записи совершенной дизъюнктивной нормальной формы (СДНФ):
| (15) |
где каждое слагаемое ![]() ,
, ![]() , представляет собой такое произведение
, представляет собой такое произведение
| (16) |
Булева функция 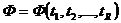 вида (15)-(16), имеющая таблицей истинности булев протокол сегмента
вида (15)-(16), имеющая таблицей истинности булев протокол сегмента ![]() ,
, 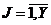 , является приближенным булевым законом сегмента в случае реального наблюдения (неполноты данных).
, является приближенным булевым законом сегмента в случае реального наблюдения (неполноты данных).
Неполнота информации в протоколе реального наблюдения влечет за собой неполноту сегмента ![]() ,
, ![]() . Для преодоления неполноты сегмента вводятся понятия
. Для преодоления неполноты сегмента вводятся понятия ![]() -окрестности вектора булева пространства
-окрестности вектора булева пространства ![]() ,
, ![]() -расширения сегмента
-расширения сегмента ![]() и операции расширения сегмента
и операции расширения сегмента ![]() . После построения области расширения сегмента
. После построения области расширения сегмента ![]() на основе базовых векторов сегмента
на основе базовых векторов сегмента ![]() получается дополнительное множество элементов этого сегмента. Объединение дополнительного множества элементов сегмента и множества элементов сегмента представляется как нечеткий сегмент
получается дополнительное множество элементов этого сегмента. Объединение дополнительного множества элементов сегмента и множества элементов сегмента представляется как нечеткий сегмент ![]() , для описания которого как нечеткого множества для каждого элемента необходимо определить значение функции принадлежности
, для описания которого как нечеткого множества для каждого элемента необходимо определить значение функции принадлежности ![]() , характеризующей степень принадлежности элемента к сегменту
, характеризующей степень принадлежности элемента к сегменту ![]() . В качестве значения функции принадлежности
. В качестве значения функции принадлежности ![]() для произвольного вектора
для произвольного вектора ![]() берется значение модифицированного коэффициента Жаккара
берется значение модифицированного коэффициента Жаккара 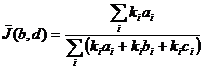 (
(![]() – количество одинаковых строк в протоколе, которые соответствуют -му вектору):
– количество одинаковых строк в протоколе, которые соответствуют -му вектору):
| (17) |
Для векторов пространства ![]() определена функция принадлежности (17) к заданному сегменту
определена функция принадлежности (17) к заданному сегменту ![]() . В результате получена матрица
. В результате получена матрица ![]() , состоящая из значений функции принадлежности вектора пространства заданному сегменту
, состоящая из значений функции принадлежности вектора пространства заданному сегменту ![]() , и построена булева таблица
, и построена булева таблица ![]() -расширения сегмента
-расширения сегмента ![]() , называемая булевым протоколом
, называемая булевым протоколом ![]() -расширения сегмента
-расширения сегмента ![]() . Булев протокол
. Булев протокол ![]() -расширения сегмента
-расширения сегмента ![]() является таблицей истинности для булевой функции
является таблицей истинности для булевой функции ![]() сегмента
сегмента ![]() от
от ![]() переменных
переменных ![]() , областью определения которой является предметное пространство
, областью определения которой является предметное пространство ![]() , а областью истинности является множество векторов булевого протокола
, а областью истинности является множество векторов булевого протокола ![]() -расширения сегмента
-расширения сегмента ![]() . Синтезируемая булева формула для функции
. Синтезируемая булева формула для функции ![]() с использованием стандартной процедуры алгебры логики для записи СДНФ имеет вид:
с использованием стандартной процедуры алгебры логики для записи СДНФ имеет вид:
| (18) |
где каждое слагаемое ![]() ,
, ![]() , является произведением вида (16).
, является произведением вида (16).
Определение 2. Нечеткий закон сегмента есть композиция двух отношений ![]() , где
, где ![]() – булева функция сегмента, двойка
– булева функция сегмента, двойка ![]() – нечеткое отношение подобия,
– нечеткое отношение подобия, ![]() – - мерное пространство,
– - мерное пространство, ![]() – функция принадлежности, связанная взаимнооднозначным соответствием с точками пространства
– функция принадлежности, связанная взаимнооднозначным соответствием с точками пространства ![]() ,
, ![]() – - расширение области сегмента
– - расширение области сегмента ![]() .
.
Элементы матрицы ![]() взаимнооднозначно соответствуют векторам конечного булева пространства
взаимнооднозначно соответствуют векторам конечного булева пространства ![]() . Всем элементам матрицы, являющимся базовыми векторами рассматриваемого сегмента
. Всем элементам матрицы, являющимся базовыми векторами рассматриваемого сегмента ![]() , соответствуют значения "1.0". Весовые коэффициенты равны "0.0" для подмножества векторов с пустыми
, соответствуют значения "1.0". Весовые коэффициенты равны "0.0" для подмножества векторов с пустыми ![]() -окрестностями. Остальные векторы пространства
-окрестностями. Остальные векторы пространства ![]() получат значения весов в интервале
получат значения весов в интервале 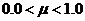 . При построении нечетких множеств матрица
. При построении нечетких множеств матрица ![]() рассматривается как функция принадлежности элемента пространства
рассматривается как функция принадлежности элемента пространства ![]() к данному сегменту.
к данному сегменту.
Определение 3. Классифицирующая функция на булевом пространстве ![]() определяется системой отношений
определяется системой отношений ![]() , где
, где ![]() – нечеткий закон
– нечеткий закон ![]() -го сегмента, который представляет собой композицию двух отношений
-го сегмента, который представляет собой композицию двух отношений ![]() , где
, где ![]() – булева функция сегмента,
– булева функция сегмента, ![]() – функция принадлежности в виде матрицы, связанной взаимнооднозначным соответствием с точками пространства
– функция принадлежности в виде матрицы, связанной взаимнооднозначным соответствием с точками пространства ![]() .
.
В заключении приведены основные результаты, полученные в диссертационной работе.
В приложении приведено описание программного комплекса, результаты применения разработанных алгоритмов к исходным данным, полученным в результате анкетирования респондентов, проведенного с целью исследования рынка мобильных телефонов.
СПИСОК РАБОТ, ОПУБЛИКОВАННЫХ ПО ТЕМЕ ДИССЕРТАЦИИ
1. Шенкао анализ временного ряда потребительских расходов Карачаево-Черкесской республики // Сборник научных трудов 7-й Международного симпозиума "Математическое моделирование и компьютерные технологии". – Кисловодск: КИЭП, 2005. – С. 45-48.
2. , Тебуева -графовая модель сегментации рынка по видам продукции // Сборник 4-й Международной научно-практической конференции "Проблемы регионального управления, экономики, права и инновационных процессов в образовании" (8-10 сентября 2005 г.). – Т. 2. – Таганрог: Изд-во ТИУиЭ, 2005. – С. 172-175.
3. , , Тебуева многокритериальной постановки теоретико-графовой задачи сегментации на двудольном графе // Известия высших учебных заведений. Северо-Кавказский регион. Серия Естественные науки. – 2005. – Приложение . – С. 48-56.
4. Шенкао квантование и задача сегментации // Материалы 6-й региональной научно-практической конференции "Рациональные пути решения социально-экономических и научно-технических проблем региона" (17-18 апреля 2006 г.). – Часть 1. – Черкесск: КЧГТА, 2006. – С. 71-73.
5. Шенкао подход к моделированию одной задачи из области сегментирования рынка. – Деп. в ВИНИТИ 11.07.2006, 2006. – 40 с.
6. Shenkao T. M., Perepelitsa V. A., Tebueva F. B. Solvability exploration of segmentation problem with linear convolution algorithms // Proceedings of the 17th International Conference on the Application of Computer Science and Mathematics in Architecture and Civil Engineering (July 12-14, 2006). – Weimar, Germany. – 2006. – 13 p. – http://euklid. bauing. uni-weimar. de/papers. php? lang=en&what=9
7. , Тебуева с оценками для дискретной задачи сегментации // Материалы IX Международной конференции "Интеллектуальные системы и компьютерные науки" (23-27 октября 2006 г.). – Т. 1, часть 2. – М.: Изд-во механико-математического факультета МГУ, 2006. – С. 271-274.
8. Шенкао вычислительной сложности теоретико - графовой задачи сегментации // Материалы 3-й Международной конференции "Нелокальные краевые задачи и родственные проблемы математической биологии, информатики и физики". – Нальчик: НИИ ПМА КБНЦ РАН, 2006. – С. 320-322.
9. , , О вычислительной сложности интервальных задач на графах // Известия высших учебных заведений. Северо-Кавказский регион. Серия Естественные науки. – 2006. – Приложение . – С. 18-30.
10. Шенкао данных в задаче классификации // Сборник научных трудов Всероссийского симпозиума "Математические модели и информационные технологии в экономике" (19-20 апреля 2007 г.). – Т. 2. – Кисловодск: КИЭП, 2007. – С. 81-84.
[1] Сегментирование рынка: практическое руководство. – М.: Дело и Сервис, 2002. – 288 с.
