


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
- поддержки принятия решений - обслуживают частично структурированные задачи, результаты которых трудно спрогнозировать заранее. Имеют более мощный аналитический аппарат с несколькими моделями. Информацию получают из управленческих и операционных ИС. Используются всеми, кому необходимо принимать решение. Характеристики: обеспечивают решение проблем, развитие которых трудно прогнозировать; оснащены сложными инструментальными средствами моделирования и анализа; позволяют легко менять постановки решаемых задач и входные данные; отличаются гибкостью и легко адаптируются к изменению условий по несколько раз в день; имеют технологию, максимально ориентированную на пользователя;
3) стратегического уровня - обеспечивают поддержку принятия решений по реализации стратегических, перспективных целей развития производства. Обладают следующими возможностями: помогают персоналу высшего звена решать неструктурированные задачи; осуществляют долгосрочное планирование путем сравнения изменений вовне производства с потенциалом производства; реализуют информационную поддержку в любой момент из многих источников. Играют вспомогательную роль из-за сложности решаемых задач.
В соответствии с классификацией по сфере применения выделяют следующие виды ИС:
1) организационного управления. Для автоматизации функций управленческого персонала. Сюда относятся ИС управления как промышленными, так и непромышленными производствами. Основные функции: оперативный контроль и регулирование, оперативный учет и анализ, перспективное и оперативное планирование, бухучет, управление сбытом и снабжением и др. экономические и организационные задачи;
2) управления технологическими процессами – для автоматизации функций производственного персонала. Используются при организации поточных линий, изготовлении микросхем, на сборке, для поддержания технологического процесса в различных видах промышленности;
3) автоматизированного проектирования (САПР). Для автоматизации функций инженеров – проектировщиков, конструкторов, архитекторов, дизайнеров при создании новой техники или технологии. Основные функции – инженерные расчеты, создание графической документации (чертежей, схем, планов), создание проектной документации, моделирование проектируемых объектов;
4) интегрированные (корпоративные) – для автоматизации всех функций производства и охватывают весь цикл работ от проектирования до сбыта продукции.
По типу используемой информации выделяют классы ИС:
1) фактографические. В таких ИС регистрируются факты – конкретные значения данных об объектах реального мира. Все данные сообщаются компьютеру в заранее обусловленном формате. Информация имеет четкую структуру, позволяющую компьютеру отличать одно данное от другого. Такая информационная система способна давать однозначные ответы на вопросы типа: «Сколько студентов получили 5 по информатике?» и т. д.;
2) документальные. Обслуживают принципиально иной класс задач, которые не предполагают однозначного ответа на поставленный вопрос. БД таких систем образует совокупность неструктурированных текстовых документов и графических объектов, снабженная тем или иным формализованным аппаратом поиска. Цель системы – выдать в ответ на запрос пользователя список документов или других объектов, удовлетворяющих сформулированным в запросе условиям. Примером подобной системы является любая поисковая система Интернета.
Глава 3. Фактографические информационные системы
3.1. Основные понятия
Данный класс ИС использует для организации информационных массивов структурированные данные, в которых отражаются отдельные факты источника информации - предметной области.
Предметная область – это часть реального мира, которая описывается или моделируется с помощью информационных массивов и использующих их приложений (программного обеспечения). Это может быть предприятие в целом, некоторая его функциональная часть или подразделение, процесс, система и т. д. Предметная область моделируется с использованием понятий информационных объектов и функций, выполняемых этими объектами или для них.
Информационный объект – это идентифицируемый (т. е. такой, который можно выделить в предметной области) объект реального мира, понятие, процесс или явление. В роли информационных объектов в зависимости от прикладных задач, которые должна решать ИС, могут выступать люди, изделия, счета и т. д. Информационный объект описывается с помощью количественных и качественных характеристик, которые выделяются на этапе первичного восприятия информации, являющемся первым в информационном процессе. Каждая из характеристик определяется именем и значением.
Например, если ИС предназначена для учета успеваемости студентов вуза, то в качестве информационного объекта можно рассматривать студента как участника учебного процесса. Его характеристиками являются фамилия, имя, отчество, контактные данные (для связи деканата), оценки в сессию (для назначения стипендии) и т. д. Это – имена характеристик. Если задаться конкретным студентом, то характеристики приобретают значения. Например (в порядке перечисления характеристик), , Информатика – 5, КСЕ – 4, Программирование – 5.
Совокупность имени и всех значений характеристики информационного объекта называется элементом данных.
Для нашего примера элементами данных являются (в каждой строке представлен элемент данных):
фамилия, имя, отчество ();
контактные данные (тел.);
оценки в сессию (Информатика – 5, КСЕ – 4, Программирование – 5).
Если студентов трое, элементы данных приобретут вид (каждая строка по-прежнему - элемент данных):
фамилия, имя, отчество (; ; );
контактные данные (тел. , ;
оценки в сессию (Информатика – 5, КСЕ – 4, Программирование – 5; Информатика – 3, КСЕ – 3, Программирование – 4; Информатика – 5, КСЕ – 3, Программирование – 4).
Подобные данные привычнее (и удобнее) представлять таблицей:
фамилия, имя, отчество | контактные данные | оценки в сессию |
Информатика – 5, КСЕ – 4, Программирование – 5 | ||
Информатика – 3, КСЕ – 3, Программирование – 4 | ||
Информатика – 5, КСЕ – 4, Программирование – 5 |
Здесь элементом данных является каждый столбец, который, как должен подсказывать читателю его программистский опыт, является полем данных для соответствующего файла. Видно, что структура каждого столбца единообразна: есть заголовок – суть имя характеристики информационного объекта, а также имеется множество значений данной характеристики – под заголовком.
Запись об объекте – совокупность значений элементов данных, которые описывают конкретный экземпляр объекта.
Для нашего примера, представленного таблицей, запись об объекте – это одна из строк таблицы со значениями, например,
Информатика – 5, КСЕ – 4, Программирование – 5 |
Очевидно, совокупность записей об объекте представляется на машинном носителе файлом, играющим роль информационного массива для структурированных данных.
Для различения экземпляров объектов в файле (т. е. записей файла) применяется идентификатор – элемент данных (или совокупность элементов данных), используемый для определения записи (или нескольких записей). Идентификация может быть уникальной (или однозначной), когда идентификатору сопоставим один экземпляр объектов, и неуникальной (многозначной), когда идентификатору сопоставимо множество (возможно, одноэлементное) экземпляров объекта.
Так, в нашем примере поля «фамилия, имя, отчество» и «контактные данные» могут служить однозначным идентификатором – каждое значение соответствующей характеристики определяет только одну запись. В то же время поле «оценки в сессию» является примером многозначного идентификатора – одинаковые результаты сдачи сессии принадлежат разным студентам.
3.2. Проектирование структуры данных[6]
Проектирование структуры данных для фактографических ИС является сложным процессом, включающим три самостоятельных этапа – концептуальное, логическое и физическое проектирование.
При концептуальном проектировании осуществляется сбор и анализ данных. Данный этап входит в состав более крупной задачи проектирования автоматизированной информационной технологии обработки данных, которая заключается в определении информационных потребностей производства или его подразделения, а также тех информационных процессов и данных, которые необходимы для обеспечения этих потребностей. Для этого вначале определяются цели и задачи производства или его подразделения и анализируются функции управления, обеспечивающие достижение этих целей и выполнение поставленных задач. Затем осуществляется разбиение этих процессов на подпроцессы более низкого уровня до тех пор, пока в результате декомпозиции ни будет достигнуто уровня приложений и функций, выполнение которых возможно без дальнейшего разбиения. Далее определяются информационные потребности каждого приложения и определяются требования к данным. Собственно концептуальное проектирование данных состоит в определении требований к данным на уровне их состава и взаимосвязи (для автоматизируемых функций), а также в обеспечении осмысленной интерпретации этих требований.
Для формального представления концептуальной модели при проектировании структуры данных используется ER[7]-модель. Она применяет следующие базовые понятия и их обозначения:
|
сущность (объект); ранее - информационный объект
атрибут сущности (свойство, характеризующее объект);
ранее – характеристика информационного объекта
 |
ключевой атрибут (атрибут, входящий в первичный ключ);
ранее – идентификатор информационного объекта
 |
связь; ранее отсутствовала
Первичный ключ - атрибут или группа атрибутов, однозначно идентифицирующих объект. Первичный ключ может состоять из нескольких атрибутов, тогда в нотации ER-модели подчеркивается каждый из них.
Объект и его атрибуты соединяются ненаправленными дугами:
 |
 |
Связи между объектами могут быть 3-х типов:
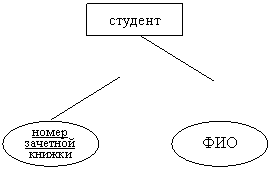
§ Один - к одному. Этот тип связи означает, что каждому объекту первого вида соответствует не более одного объекта второго вида, и наоборот. Например: студент может иметь только одну зачетную книжку и, наоборот, одна зачетная книжка принадлежит только одному студенту.
§ Один - ко многим. Этот тип связи означает, что каждому объекту первого вида может соответствовать более одного объекта второго вида, но каждому объекту второго вида соответствует не более одного объекта первого вида. Например: в каждой учебной группе может числиться множество студентов, но каждый студент числится только в одной учебной группе.
§ Многие - ко многим. Этот тип связи означает, что каждому объекту первого вида может соответствовать более одного объекта второго вида, и наоборот. Например: каждый преподаватель может обучать множество студентов, и каждый студент может обучаться у разных преподавателей.
Ромб связи и прямоугольник объекта соединяются ненаправленными дугами в сторону "ко многим" и направленными в сторону "к одному":
 |
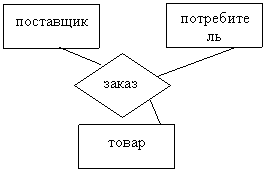
Если связь соединяет две сущности, она называется бинарной. Связь может соединять более двух сущностей, например, связь, соединяющая три сущности, называется тернарной:
 |
Иногда используют также понятие "слабая сущность". Это сущность, которая не может быть однозначно идентифицирована с помощью собственных атрибутов, а только через связь с другой сущностью. Пусть, например, фамилия студента является уникальной только в пределах учебной группы, т. е. в разных группах могут быть студенты с одинаковыми фамилиями. Уникальной в данном случае будет комбинация "фамилия студента, шифр учебной группы". Сущность "студент" является слабой. В нотации ER- модели слабые сущности обозначаются двойными линиями.
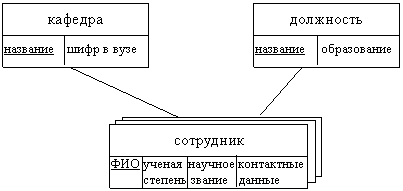
Пусть, например, требуется разработать концептуальную модель данных, описывающую организационную структуру кафедр вуза. Тогда кафедры являются предметной областью для задачи. Данная предметная область характеризуется следующими сущностями и их атрибутами:
сотрудник – ФИО, ученая степень, научное звание, контактные данные;
кафедра – название, шифр в вузе;
должность – название, образование.
Сформируем ER-диаграммы, описывающие сущности и связи между ними:
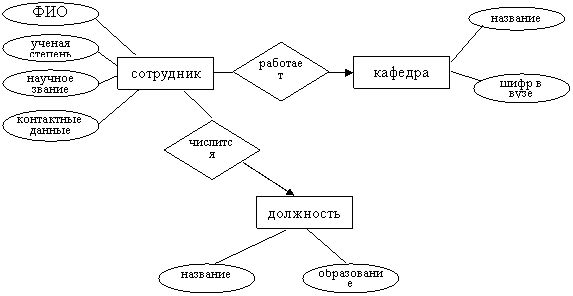 |
Определим, какие атрибуты могут играть роль ключевых:
§ для сущности кафедра оба атрибута однозначно определяют объект, поскольку не бывает в рамках одного вуза разных кафедр с одинаковыми названиями или шифрами. Для выбора следует ориентироваться на то, какой атрибут, скорее всего, будет использоваться при поиске нужной записи в БД. Очевидно, пользователю удобнее применять название кафедры, поэтому данный атрибут определим как ключевой;
§ для сущности должность ключевым может служить атрибут название, поскольку разные должности могут характеризоваться одним значением атрибута образование (высшее, среднее и т. д.);
§ для сущности сотрудник дело обстоит гораздо сложнее. Предметная область такова, что в реальной ситуации ни один из указанных атрибутов не может служить ключевым. В самом деле, в вузе возможны сотрудники с одинаковыми ФИО. Гораздо меньше вероятность полных тезок и однофамильцев в рамках одной кафедры. Тогда в качестве ключевых атрибутов следует использовать совокупность идентификаторов сотрудников и кафедр.
На этапе логического проектирования требования к данным преобразуются в структуры, применяемые в используемой системе управления данными.
Физическое проектирование решает вопросы, связанные с производительностью системы; определяются способы размещения данных в файлах (т. е. на машинных носителях) и методы доступа к данным. Этот уровень проектирования связан также с типами записывающих устройств, методами доступа, длинами блоков и т. д., т. е. с теми физическими характеристиками машинных носителей, которые являются предметом изучения и освоения специалистов технических профессий.
В настоящее время все действия по физическому проектированию выполняются системами управления базами данных (СУБД), а потому не актуальны для учебного курса. Тем не менее, логическое проектирование, связанное с разработкой моделей данных, а также вопросы физического проектирования, связанные со структурами хранения данных, входят в программу дисциплины «Информационные системы» и являются предметом подробного рассмотрения далее.
3.3. Логическое проектирование структур данных
Концептуальная модель данных позволяет перейти к формированию логических моделей. Существует три вида логических моделей данных: реляционные, иерархические (или древовидные), сетевые (или сети).
Реляционная модель – это совокупность элементов данных, описывающих информационные объекты одного класса, а потому имеющие одинаковый состав характеристик. Например, следующая таблица описывает результаты сдачи сессии студентами:
фамилия, имя, отчество | оценки в сессию |
Информатика – 5, КСЕ – 4, Программирование – 5 | |
Информатика – 3, КСЕ – 3, Программирование – 4 | |
Информатика – 5, КСЕ – 4, Программирование – 5 |
Элемент данных, играющий роль идентификатора объекта, называется ключевым полем, или попросту ключом. Ключ, выполняющий однозначную идентификацию, называется первичным. Ключ, выполняющий многозначную идентификацию, называется вторичным. Если в качестве ключа выступает один элемент данных, такой ключ называется простым. Если используются несколько элементов данных в качестве ключа, такой ключ называется составным.
Для построенной ранее концептуальной модели можно сформировать три реляционные структуры, поскольку выделены три сущности, причем для таблицы, соответствующей сущности сотрудник, требуется составной первичный ключ, включающий атрибуты ФИО, название кафедры (первичные ключи выделены полужирно):
сотрудник кафедра должность
ФИО | ученая степень | научное звание | контактные данные | название (кафедры) | название (должности) | название | шифр в вузе | название | образование | ||
… | … | … | … | … | … | … | … | … |
Все остальные поля могут рассматриваться как вторичные ключи, если пользователь заинтересован в организации последующего доступа к данным по этим полям.
Иерархическая модель (или дерево) – это конечное множество Т элементов, такое, что выполняются следующие условия:
1) имеется один специально выделенный элемент, называемый корнем дерева;
2) остальные элементы (кроме корня) содержатся в m³0 попарно не пересекающихся множествах Т1, ....Тm, каждое из которых в свою очередь является деревом. Деревья Т1, ....Тm являются поддеревьями данного дерева.
Пример дерева показан на рисунке:
 |
Дадим некоторые определения, которые понадобятся нам в дальнейшем:
1) уровень иерархии – показывает упорядоченность элементов дерева по старшинству. Корень дерева – нулевой уровень, затем уровни нумеруются по возрастанию номеров;
2) подобные элементы – элементы (вершины дерева), расположенные на одном уровне иерархии. Такие элементы, как правило, имеют одинаковую внутреннюю структуру;
3) порожденные элементы – элементы (вершины дерева), расположенные на следующем уровне иерархии;
4) родительские элементы – элементы (вершины дерева), расположенные на предыдущем уровне иерархии.
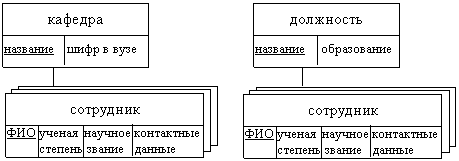
Построим иерархическую модель для концептуальной модели из рассмотренного ранее примера. Для этого воспользуется видом связи «один-ко-многим», которая показана на ER-диаграмме. Чтобы продемонстрировать эту связь на схеме, сущность, выступающую в роли «ко-многим», изобразим в виде повторяющихся прямоугольников:
 |
 |
Видно, что имеют место два дерева, одно из которых моделирует отношения сотрудников с кафедрами, а второе – сотрудников и занимаемые ими должности.
С учетом атрибутов сущностей данная схема выглядит следующим образом (первичные ключи выделены подчеркиванием):
 |
Сетевая модель (сеть) – это два множества Т и R, между которыми задано отображение Г: Т ® R, где Т – множество элементов сети, R – множество бинарных отношений между ними, Г – отображение, показывающее, какие элементы какими отношениями связаны. Нестрого сетевые модели можно определить как несколько иерархических моделей, соединенных вершинами максимального уровня иерархии.
Построим сетевую модель для нашего примера. Уже иллюстрации к дереву показывают, что модель информационно избыточна – в обоих деревьях находится описание одних и тех же сотрудников. Этот недостаток устраняется в сетевых моделях:
 |
3.4. Физическое проектирование структур данных
В данном разделе рассмотрим способы организации хранения на машинных носителях информационных массивов, отражающих одну из рассмотренных логических моделей данных. Каждый раз при решении вопроса о выборе способа структуризации файла, основным критерием является последующая минимизация времени доступа к данным по запросам пользователя, который включает, в общем случае, наименование и значение ключевого поля. Для этого часто вводятся дополнительные массивы данных, что ведет к перерасходу объемов внешней памяти, но позволяет оптимизировать доступ к данным.
3.4.1. Методы физического проектирования для реляционных моделей
Поскольку для реляционных структур существуют вторичные и первичные ключи, которые используются при поиске данных, различают методы физического проектирования для доступа по первичному и вторичному ключу. При рассмотрении каждой физической модели одновременно будет обсуждаться вопрос доступа к данным, что является основным критерием при решении вопроса о структурах хранения.
Для доступа по первичному ключу различают модели: последовательная организация, индексно-последовательная организация, индексно-произвольная организация, рандомизация. Для доступа по вторичному ключу выделяют модели: цепь подобных записей и инвертированные файлы.
3.4.1.1. Последовательная организация
Записи файла соответствуют логической модели данных. Число реляционных структур (таблиц) соответствует числу файлов. Доступ к записям осуществляется тремя способами: последовательным сканированием, блочным, двоичным.
При последовательном сканировании записи файла могут быть неупорядочены по первичному ключу. Для обозначения значения ключевого поля в запросе введем нотацию Кдоступ. Последовательно, начиная с первой записи, сравнивается ключ каждой записи файла К с ключом доступа Кдоступ. При равенстве обоих ключей требуемая запись найдена: содержащаяся в ней информация полностью или частично выводится пользователю. Если же равенство не выполняется, последующие шаги алгоритма различаются для упорядоченного и неупорядоченного файла:
· для неупорядоченного файла сравнение повторяется до достижения его конца. В этом случае, если совпадения ключей так и не было, делается вывод об отсутствии нужной записи;
· для упорядоченного файла проверяется условие, например, превышения значения ключа доступа Кдоступ значения ключа К: если файл упорядочен по возрастанию, поиск продолжается; если по убыванию – поиск прекращается ввиду отсутствия нужной записи.
При блочном способе записи файла должны быть упорядочены по первичному ключу. Для удобства дальнейшего изложения предположим (здесь и далее по реляционным моделям), что упорядочение выполнено по возрастанию значения ключа.
Файл разделяется на виртуальные блоки размером ÖN записей, где N – число записей в файле. С ключом доступа Кдоступ сравниваются ключевые поля последних записей в блоках - Кjблока, начиная с первого блока (j – номер блока). С помощью такого сравнения вначале определяется блок, в котором возможно нахождение нужной записи (для этого требуется выполнение условия Кдоступ < Кjблока)[8], а затем уже, как правило, методом последовательного сканирования - сама запись в блоке.
При двоичном способе записи файла также должны быть упорядочены по первичному ключу. Файл последовательно делится на две части, уменьшая пространство поиска каждый раз вдвое. Ключ доступа Кдоступ сравнивается с ключевым полем «средней» записи - Кср. Здесь возможны варианты:
Кдоступ = Кср; «средняя» запись является искомой, алгоритм заканчивает работу;
Кдоступ > Кср; поиск продолжается в той половине файла, где первичные ключи имеют бóльшие значения;
Кдоступ < Кср; поиск продолжается в той половине файла, где первичные ключи имеют мéньшие значения.
Продолжение поиска заключается вновь в делении выбранной половины файла пополам и т. д. Алгоритм заканчивает работу при нахождении нужной записи или при условии, когда очередная «половина» файла содержит только одну запись, ключевое поле которой не совпадает с Кдоступ. Делается вывод об отсутствии нужной записи в файле.
3.4.1.2. Индексно-последовательная организация
Записи файла должны быть упорядочены по первичному ключу. Аналогично блочному методу доступа, файл делится на виртуальные блоки размером ÖN. Затем ключевые поля последних записей блоков вместе с порядковыми номерами этих записей в файле включаются в дополнительные файлы, которые называются индексами. Видно, что данный способ использует дополнительные построения, - назовем тогда исходный файл основным.
Пусть основной файл соответствует реляционной модели для сущности кафедра из рассмотренного ранее примера и имеет вид:
кафедра
название | шифр в вузе |
АПП | 238 |
СУиВТ | 239 |
ТАМ | 145 |
Экономики | 056 |
Для этого файла N = 4. Это значит, что индекс будет иметь вид:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
