


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Из рисунка видно, что структура этих описаний соответствует структуре самого индекса: первое поле – это ключевое слово, а второе – ссылка на файл, следующий в цепочке подобных текстов.
Рассмотрим, как решается задача поиска релевантного текста при такой организации.
Пусть запрос по-прежнему содержит ключевое слово К1. Тогда алгоритм просмотра имеет вид:
1) по индексу определяется элемент со значением ключевого слова К1;
2) по полю ссылки находится имя файла, первого в цепочке файлов, содержащих данное слово – это Ф1; выводится содержимое данного файла;
3) по полю ссылки для ключевого слова К1 файла Ф1 определяется имя файла, следующего в цепочке ключевого слова К1, – это Ф3;
4) выводится содержимое файла Ф3;
5) по полю ссылки для ключевого слова файла Ф3 определяется имя файла, следующего в цепочке ключевого слова К1. Поскольку ссылка пуста, цепочка закончена, и алгоритм прекращает работу.
4.1.3. Инвертированные файлы
Этот способ организации текстовых файлов является развитием предыдущего: в справочник включаются все адресные ссылки, соответствующие тому или иному ключевому слову. Одновременно адресные ссылки исключаются из самих текстовых файлов. Тогда ТБД из предыдущего раздела при данной организации хранения будет иметь в составе следующие составляющие:
1) текстовые файлы Ф1, Ф2, Ф3, Ф4 вида:
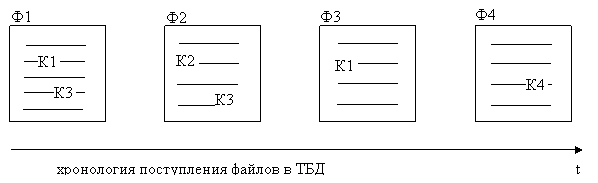 |
2) индекс вида:
Ключевое слово | Ссылки |
К1 | Ф2, Ф3 |
К2 | Ф2 |
К3 | Ф1, Ф2 |
К4 | Ф4 |
Как видно, поле Ссылки индекса содержит список ссылок на все файлы, содержащие то или иное ключевое слово.
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1. Тогда алгоритм просмотра имеет вид:
1) по индексу определяется строка, содержащая данное ключевое слово; по полю Ссылки выбираются имена файлов ТБД, которые характеризуются данным ключевым словом, – это файлы с именами Ф2 и Ф3;
2) средствами файловой системы выполняется поиск и вывод текстов файлов пользователю. Алгоритм заканчивает работу.
Рассмотренный метод позволяет легко решать задачи поиска по сложным запросам.
Пусть запрос содержит ключевые слова К1, К3, связанные оператором «или», т. е. пользователю требуется найти тексты, содержащие либо слово К1, либо слово К3. Используя предыдущий алгоритм, находим файлы, релевантные запросу:
для К1 – {Ф1, Ф3};
для К3 – {Ф1, Ф2}.
Тогда множество файлов, удовлетворяющих запросу в целом, соответствует объединению полученных множеств:
К1ÚК3 ® {Ф1, Ф3}È{Ф1, Ф2} = {Ф1, Ф2, Ф3}.
Пусть запрос содержит ключевые слова К1, К3, связанные оператором «и», т. е. пользователю требуется найти тексты, содержащие одновременно слова К1 и К3. Используя известный алгоритм, находим файлы, релевантные запросу:
для К1 – {Ф1, Ф3};
для К3 – {Ф1, Ф2}.
Тогда множество файлов, удовлетворяющих запросу в целом, соответствует пересечению полученных множеств:
К1ÙК3 ® {Ф1, Ф3}Ç{Ф1, Ф2} = {Ф1}.
4.1.4. Кластерные файлы
Тексты делятся на группы - кластеры родственных текстов, для чего исследуется подобие ключевых слов, характеризующих каждый текст. Тогда в один кластер включаются тексты, которые оказались подобны друг другу. Внутри кластера тексты могут быть организованы любым из рассмотренных ранее способов. Каждый кластер описывается множеством ключевых слов, которые входят в состав профиля кластера (формально определяется далее). В описание включается также адресная ссылка на соответствующий кластер. При хранении кластер может отождествляться с папкой (в терминологии операционной системы Windows’xx).
Пусть ТБД содержит файлы Ф1 – Ф4, которые входят в состав двух кластеров С1 и С2 следующим образом: С1 = {Ф2, Ф4}, С2 = {Ф1, Ф2, Ф3}. Профили П1 и П2 кластеров С1 и С2, соответственно, имеют в составе ключевые слова: П1 = {К2, К4}, П2 = {К1, К3}. Файлы внутри кластеров имеют последовательную организацию.
Тогда ТБД имеет в составе следующие компоненты:
1) описание кластеров в виде индекса, где в графе Ссылка заданы адреса кластеров (т. е. имена папок), а в графу Ключевое слово включен список ключевых слов, формирующих профили кластеров;
Ключевое слово | Ссылка |
К1 | С2 |
К2 | С1 |
К3 | С2 |
К4 | С1 |
2) текстовые файлы Ф1 – Ф4, распределенные по кластерам С1 и С2:
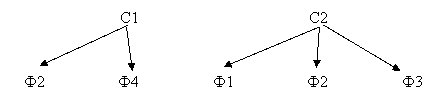 |
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1. Тогда алгоритм просмотра:
1) по индексу находится элемент с заданным ключом;
2) по полю Ссылка определяется нахождение кластера, содержащего требуемый текст, – это кластер С2;
3) в кластере С2 ищется текст (тексты) с нужным ключевым словом. При этом применяются методы поиска, рассмотренные ранее для последовательной организации. Такими текстами являются тексты в файлах Ф1 и Ф3.
Следует отметить, что наиболее употребляемыми из рассмотренных методов являются инвертированные и кластерные файлы, поэтому дальнейшее изложение ориентировано на эти способы хранения текстовых файлов.
4.2. Методы индексирования
Как видно из описаний методов организации ТБД, в них активно используются ключевые слова. Задача выделения в том или ином тексте ключевых слов имеет самостоятельное значение и рассматривается в данном разделе.
Выделение ключевых слов в тексте называется его индексированием. Эта процедура сводится к последовательным действиям:
1) выделение из текста всех слов на основании различных разделителей (пробелов, знаков препинания и т. д.). При этом в состав выделенных слов попадают такие, которые не отвечают смыслу ключевого слова, например, союзы, предлоги, числительные и другие служебные слова;
2) удаление из полученного списка упомянутых служебных слов. Они известны для каждого естественного языка и заранее включаются в так называемые стоп-словари;
3) нормализация оставшихся слов, которая состоит в приведении существительных и прилагательных в единственное число, именительный падеж, глагола – в неопределенную форму, причастий и деепричастий – в неопределенную форму глагола и т. д. Кроме того, средствами морфологического анализа слова возможно выделение его основы и использование ее в качестве ключевого слова. Для этого используются обширные лингвистические данные, и вся эта задача в целом носит прикладной лингвистический характер, а потому в данном пособии не рассматривается. В результате получается список ключевых слов (или их основ), подобный тому, что был использован в приведенных ранее примерах (внимательный читатель заметил, что ключевые слова из справочников отличались местами от тех, которые встречались в исходных текстах);
4) для придания бóльшей значимости выделенным словам присваиваются весовые коэффициенты (веса), которые позволяют числовым образом оценить, насколько хорошо данное слово отражает смысл текста в целом. На практике, как правило, применяются не просто списки ключевых слов, как это было сделано в предыдущих примерах, а списки взвешенных ключевых слов. Методы назначения весов могут быть статистическими и позиционными и рассматриваются далее.
Таким образом, приведенные ранее примеры упрощали представление индексов, а также процедуры просмотра и добавления новых текстов в ТБД: на самом деле они включают и используют веса ключевых слов.
В результате описанных действий формируется список индексационных терминов (далее – терминов) – это ключевые слова, снабженные весами.
4.2.1. Позиционные методы назначения весов
На значение веса термина влияют следующие факторы:
1) более значимыми являются термины, входящие в заглавие всего текста или его разделов, в начальные абзацы и т. д.;
2) повышаются веса терминов, входящих в толковые словари по некоторой предметной области, значимой или совпадающей с предметной областью.
К сожалению, в литературе отсутствуют публикации аналитических зависимостей веса термина и его позиции в тексте. Решение данной задачи выполняется эвристическими методами на усмотрение разработчиков соответствующего программного обеспечения.
4.2.2. Статистические методы назначения весов
Используют частотные параметры терминов tk в тексте Di, которые характеризуют частоту встречаемости того или иного слова в том или ином тексте. Эти параметры называют частотами и обозначают fik, где i – обозначение текста, k – обозначение термина. Следует иметь в виду, что методы используют абсолютную частоту терминов, т. е. число их появлений. Данные методы включают частотные модели; модель, учитывающую различительную силу термина, и ее модификацию; модель, использующую динамическую оценку информативности.
4.2.2.1. Частотные модели
В применение частоты для оценки значимости термина вкладывают следующий смысл: чем чаще используется тот или иной термин, тем теснее он связан с семантикой текста. Этот тезис побуждает связать вес wik термина tk в тексте Di напрямую с частотой, т. е. wik = fik. Однако этого делать нельзя по двум причинам:
1) бóльшей частотой могут обладать служебные слова типа предлогов, союзов и т. п., которые не связаны с выражением семантики текста;
2) минимальной частотой могут характеризоваться «узкие» термины, которые хорошо отражают семантику текста.
По этим соображениям формула для расчета веса термина приобретает вид:
wik = fik* К,
где К – коэффициент, который рассчитывается по разным зависимостям в соответствии с разновидностью частотных моделей.
Так, модель, использующую текстовую частоту термина, определяет К:
К = IDFk,
где IDFk (Inverse Document Frequency) – обратная частота tk в наборе из n текстов:
IDFk = ![]() ,
,
Dk – текстовая частота - число текстов набора из n, в которых есть tk.
Модель, учитывающая соотношение «сигнал-шум», рассчитывает К как:
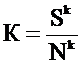 ,
,
где Nk – шум термина tk в наборе из n текстов:
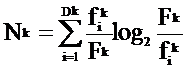 ,
,
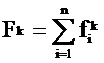 - суммарная частота термина tk в наборе из n текстов,
- суммарная частота термина tk в наборе из n текстов,
Sk - сигнал термина tk в наборе из n текстов:
![]() .
.
Модель, учитывающая распределение частоты термина, определяет К по формуле:
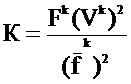 ,
,
где ![]() - средняя частота термина tk в наборе из n текстов:
- средняя частота термина tk в наборе из n текстов:
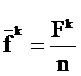 ,
,
(Vk)2 - среднеквадратическое уклонение термина tk:
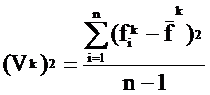 .
.
4.2.2.2. Модель, учитывающая различительную силу термина
В этой модели «хорошим», т. е. имеющим бóльший вес, считается термин, уменьшающий коэффициент подобия текстов. Вес термина здесь также прямо пропорционален его частоте, однако в расчете коэффициента К учитывается роль термина в усилении или уменьшении подобия текстов, что исключает данный метод из числа частотных.
Введем некоторые понятия:
§ вектор Vi текста Di: Vi = {(tk, fik)} или Vi = {(tk, wik)};
§ коэффициент подобия S(Di, Dj) текстов Di и Dj:
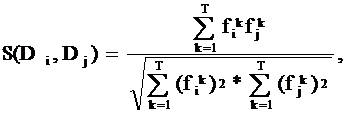
где T = |{tk}| - число индексационных терминов.
Коэффициент подобия принимает значения от 0 до 1: при 0 тексты различны, при 1 – полностью идентичны (по смыслу).
В данной модели К = DVk
где ![]() - различительная сила (Difference Volume) термина tk:
- различительная сила (Difference Volume) термина tk:
![]() ,
,
![]() - среднее значение коэффициента попарного подобия текстов данного набора в присутствии термина tk:
- среднее значение коэффициента попарного подобия текстов данного набора в присутствии термина tk:
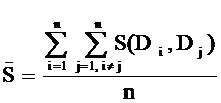 ,
,
![]() - то же в отсутствие термина tk.
- то же в отсутствие термина tk.
Недостатком данной модели является то, что для вычисления средних попарных подобий текстов из набора n текстов требуется n2 операций. Модификация этого метода использует понятие пространства текстов и его характеристик - профиля и плотности пространства текстов.
Пространство текстов – множество текстов, каждый из которых характеризуется вектором. Профиль П пространства из n текстов – это виртуальный текст, вектор которого VП определяется как:
VП = {(tПk, fПk)},
где {tпk} = 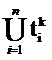 , т. е.множество {tпk} индексационных терминов есть объединение индексационных терминов текстов набора,
, т. е.множество {tпk} индексационных терминов есть объединение индексационных терминов текстов набора,
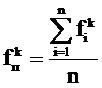 , т. е. частоты терминов есть усредненные частоты терминов по текстам набора.
, т. е. частоты терминов есть усредненные частоты терминов по текстам набора.
Плотность Q пространства текстов:
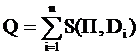 ,
,
где S(П, Di) – коэффициент подобия профиля и текста Di:
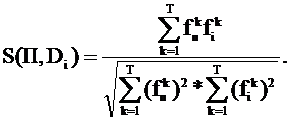
Чем больше Q, тем больше сходство между текстами набора.
С использованием плотности пространства Q можно по другому определить различительную силу DVk термина tk:
DVk = Qk – Q,
где Qk – плотность пространства текстов, когда термин tk исключен из всех текстов набора n,
Q - плотность пространства текстов в присутствии термина tk.
4.2.2.3. Модель, использующая динамическую оценку информативности
Вес wik термина tk в тексте Di определяется как:
wik = IVik,
где IVik – информативность (Information Value) термина tk в тексте Di, принимает значения от 0 до 2.
![]() Информативность того или иного термина определяется экспериментально, а первоначально всем терминам приписываются одинаковые значения информативности, например, равные 1 (точка на рисунке). Таким образом, начальными условиями для динамического назначения информативности для каждого tik являются: IVik = 1 и xik = 0. Тогда в случае полезности термина в процессе его использования его информативность увеличивается, а в случае бесполезности – уменьшается, причем указанные изменения имеют синусоидальный характер.
Информативность того или иного термина определяется экспериментально, а первоначально всем терминам приписываются одинаковые значения информативности, например, равные 1 (точка на рисунке). Таким образом, начальными условиями для динамического назначения информативности для каждого tik являются: IVik = 1 и xik = 0. Тогда в случае полезности термина в процессе его использования его информативность увеличивается, а в случае бесполезности – уменьшается, причем указанные изменения имеют синусоидальный характер.
![]()

![]() IV IV=1+sin(x)
IV IV=1+sin(x)
 2
2

 1
1
![]() 0 - p/2 0 p/2 x
0 - p/2 0 p/2 x
Увеличение (+) или уменьшение (-) информативности выполняется по формуле
![]() ,
,
где ![]() ,
,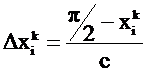 ;
;
c – константа, имеющая смысл: число экспериментов для установления информативности термина.
Таким образом, в результате индексирования набора из n текстов (любым из рассмотренных методов) формируется справочник со структурой:
Термин tk | Текст Di | |||
Ф1 | Ф2 | ... | Фn | |
t1 | w11 | w21 | wn1 | |
t2 | w12 | w22 | wn2 | |
... | ||||
tT | w1T | w2T | wnT |
Такие справочники характерны для инвертированных файлов.
4.3. Кластеризация текстов
Для организации хранения кластерных файлов требуется их разбиение на кластеры.
Методы кластеризации основаны на построении полной матрицы подобия текстов заданного пространства, в которой для каждой пары текстов Di, Dj приводится коэффициент подобия S(Di, Dj). Затем вводится некоторое пороговое значение коэффициента подобия Ŝ: если S(Di, Dj)> Ŝ, тексты Di, Dj включаются в кластер, иначе – не включаются.
4.4. Поиск релевантных текстов
Как отмечалось, наиболее употребляемыми на практике являются два способа – инвертированные и кластерные файлы. Рассмотрим, как решается задача поиска релевантных текстов в этих случаях.
4.4.1. Поиск в инвертированных файлах
Пусть есть пространство текстов размером n, каждый из которых характеризуется вектором Vi = {(tk; wki)}. Пусть запрос содержит множество ключевых слов (терминов): q = ({tkq}). Определим формально текст, релевантный запросу q, как такой текст ТБД, для которого коэффициент подобия с запросом отличен от нуля.
Для расчета коэффициента подобия запроса и текстов ТБД применяются вектора текстов и запроса. Определим вектор запроса Vq:
Vq = {(tkq; wkq)},
где tkq – термин запроса;
wkq - вес этого термина.
Тексты Di характеризуются векторами Vi:
Vi = {(tk; wki)},
где tk – термин вектора текста – индексационный термин;
wki - вес этого термина:
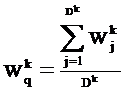
Тогда при поиске релевантного текста (текстов) по запросу q рассчитываются коэффициенты подобия запроса и каждого из текстов ТБД:
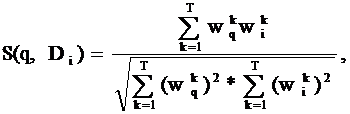
После определения релевантных текстов возможны два подхода:
1) тексты упорядочиваются по убыванию релевантности, т. е. коэффициента подобия запросу, и предоставляются пользователю в таком упорядоченном виде;
2) вводится пороговый коэффициент подобия Ŝ: пользователю выдаются только те тексты ТБД, для которых подобие с запросом превышает пороговое значение.
4.5.2. Поиск при кластерной организации хранения
Пусть пространство текстов разбито на множество кластеров {Cl}, каждый из которых есть своё подпространство размером nl текстов исходного пространства размером n текстов. При этом каждый кластер характеризуется профилем Пl и вектором Vl вида:
Vl = {(tlk, flk)},
где {tlk} = 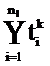 , т. е. множество {tlk} индексационных терминов есть объединение индексационных терминов текстов кластера Сl,
, т. е. множество {tlk} индексационных терминов есть объединение индексационных терминов текстов кластера Сl,
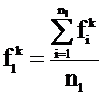 , т. е. частоты терминов есть усредненные частоты терминов по текстам кластера.
, т. е. частоты терминов есть усредненные частоты терминов по текстам кластера.
Рассчитываются коэффициенты подобия S(q, Cl) запроса и кластера, представленного своим вектором:
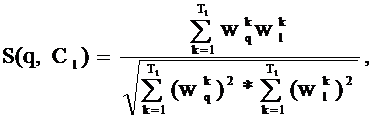
где wlk – вес термина tk в профиле кластера Cl;
Тl – число индексационных терминов в профиле кластера Сl.
После определения релевантного кластера (его подобие с запросом отлично от нуля) поиск релевантного текста (текстов) выполняется внутри кластера.
4.5. Методы расширенного поиска
Часто при поиске в ТБД необходимо увеличить число релевантных текстов (в поисковых системах Интернет это называется расширенным поиском). Пространство релевантности увеличивается за счет дополнительных совпадений терминов запроса и индексационных терминов.
Для увеличения числа совпадений используются методы:
1) применение словаря синонимов (тезауруса), в котором термины сгруппированы в классы синонимии, или эквивалентности. Для построения тезауруса используют методы кластеризации элементов, в которых в качестве элементов выступают индексационные термины;
2) исключение из рассмотрения префиксной и постфиксной частей терминов и выделение их основ путем проведения морфологического анализа;
3) использование ассоциативного индексирования для приписывания терминам дополнительных терминов, которые ассоциируются с исходными;
4) вероятностное индексирование.
4.5.1. Построение словаря синонимов
Смысл этого метода сводится к тому, что с каждым термином tk связывается множество его синонимов Synk. Образуется тезаурус. Тогда вектор запроса пополняется терминами из тезауруса, что расширяет число текстов, релевантных запросу.
Связь термина tk с множеством Synk может быть представлена дополнительной графой справочника, в которой множество синонимов задано либо явно, либо списком номеров синонимичных терминов из того же справочника, например:
Термин tk | Синонимы Synk | Текст | |||
Ф1 | Ф2 | Ф3 | Ф4 | ||
К1 | К4 | wФ1К1 | wФ2К1 | wФ3К1 | wФ4К1 |
К2 | - | wФ1К2 | wФ2К2 | wФ3К2 | wФ4К2 |
К3 | - | wФ1К3 | wФ2К3 | wФ3К3 | wФ4К3 |
К4 | К1 | wФ1К4 | wФ2К4 | wФ3К4 | wФ4К4 |
Тогда, например, если в запросе участвует термин К1, а его синонимом является термин К4, то запросу релевантны тексты, характеризующиеся как термином К1, т. е. Ф1, так и К4, т. е. Ф4.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
