


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
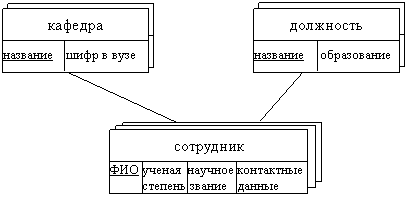 |
Описание элементов сети задано в таблицах:
сотрудник кафедра должность
ФИО | ученая степень | научное звание | контактные данные | название | шифр в вузе | название | образование | ||
к. т.н. | доцент | 234567 | СУиВТ | 239 | ассистент | высшее | |||
к. т.н. | нет | 456789 | ТАМ | 145 | доцент | высшее | |||
нет | нет | 123456 | профессор | высшее | |||||
д. т.н. | профессор | 345678 |
Описание связей между элементами сети задано таблицей:
обозначение поля | элемент сети | родительская запись | порожденная запись |
название (кафедры) | СУиВТ | - | 6, 8 |
название (кафедры) | ТАМ | - | 7, 9 |
название (должности) | ассистент | - | 8 |
название (должности) | доцент | - | 6, 7 |
название (должности) | профессор | - | 9 |
ФИО | 1 | - | |
ФИО | 2 | - | |
ФИО | 1 | - | |
ФИО | 2 | - |
3.4.3.6. Битовые отображения
Пусть исходная сеть соответствует последнему примеру. Описание элементов сети задано в таблицах:
сотрудник кафедра должность
ФИО | ученая степень | научное звание | контактные данные | название | шифр в вузе | название | образование | ||
к. т.н. | доцент | 234567 | СУиВТ | 239 | ассистент | высшее | |||
к. т.н. | нет | 456789 | ТАМ | 145 | доцент | высшее | |||
нет | нет | 123456 | профессор | высшее | |||||
д. т.н. | профессор | 345678 |
Связи между элементами сети показаны в таблице:
Обозначение строк | Обозначение столбцов | |||||
название (кафедры) | название (должности) | |||||
СУиВТ | ТАМ | ассистент | доцент | профессор | ||
ФИО | 0 | 1 | 0 | 0 | 1 | |
0 | 0 | 0 | 1 | 0 | ||
0 | 1 | 0 | 0 | 0 | ||
0 | 1 | 0 | 0 | 0 |
Глава 4. Документальные информационные системы
Как отмечалось ранее, информационные массивы таких систем содержат неструктурированные данные произвольного формата. Наиболее представительное множество документальных систем основано на текстовых данных, поэтому дальнейшее изложение относится именно к ним.
Минимальным информационным элементом в документальных ИС является файл. В ответ на запрос пользователя ИС отклик системы содержит не данные, описывающие отдельные факты, как в случае фактографических ИС, а целые файлы (или ссылки на них), релевантные запросу, т. е. отвечающие его смыслу. Выделение смысла текста (или запроса) – самостоятельная очень сложная проблема, которая касается такой области современной информатики как искусственный интеллект, а потому здесь не рассматривается. На практике определение релевантности текста и запроса выполняется, в простейшем случае, на основе совпадения терминов запроса и текста, что, конечно, сильно обедняет результат поиска, поскольку один смысл можно выразить по-разному. При этом в качестве таких терминов могут использоваться как отдельные слова, так и словосочетания. Применяемые для поиска релевантных текстов термины называются также ключевыми словами (или ключами)[9].
При организации хранения неструктурированных данных решаются две основные задачи:
1) минимизация времени доступа к данным. Это приводит к дополнительным построениям при размещении данных, что требует затрат времени и памяти компьютера;
2) уменьшение «шума» отклика ИС, т. е. нахождение данных, наиболее релевантных запросу.
4.1. Методы организации хранения неструктурированных данных
Различают следующие методы хранения неструктурированных данных, организованных в виде файлов:
1) последовательные файлы,
2) цепочечные файлы,
3) инвертированные файлы,
4) кластерные файлы.
Совокупность файлов, содержащих текстовые данные, составляет полнотекстовую базу данных – ТБД, т. е. информационные массивы ИС.
4.1.1. Последовательные файлы
Файлы хранятся в произвольном порядке, например, в порядке их поступления. Не определены ни группы, ни классы файлов, нет справочников или других списков, обеспечивающих доступ к любому файлу.
Для нахождения всех файлов, обладающих некоторой характеристикой, требуется просмотр всего массива файлов. Неэффективность данного метода объясняет его практическое неиспользование.
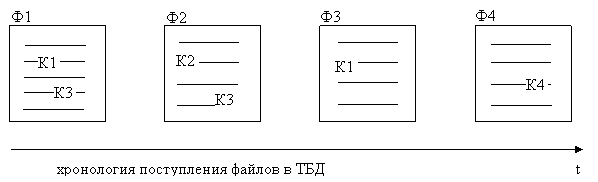
Пусть, например, имеются тексты, которые хранятся в файлах с именами, соответственно, Ф1, Ф2, Ф3, Ф4, содержащие некоторые ключи Кi (на рисунке схематично показаны текстовые файлы, где в тексте среди слов содержатся ключевые слова):
 |
Рассмотрим решение задачи поиска релевантного текста.
Пусть запрос содержит ключевое слово К1, например, компьютер. Тогда алгоритм поиска имеет вид:
1) из группы файлов выбирается первый файл Ф1 и соответствующий текст сканируется от начала – ищется совпадение слов текста с заданным ключевым словом;. Поскольку совпадение установлено, сканирование данного файла прекращается, пользователю выдается первый релевантный текст из файла Ф1;
2) из группы выбирается файл Ф2 и выполняется его сканирование от начала до конца. Совпадений нет, выполняется переход к анализу файла Ф3;
3) из группы файлов выбирается файл Ф3 и соответствующий текст сканируется. Выявляется совпадение, сканирование файла прекращается, и он выдается пользователю как второй релевантный текст. Выполняется переход к анализу файла Ф4;
4) из группы выбирается файл Ф4 и выполняется его сканирование от начала до конца. Совпадений нет, делается попытка перехода к анализу следующего файла, а поскольку все файлы просмотрены, алгоритм заканчивает работу.
Подобный метод организации хранения файлов и последующий поиск требуемых данных осуществляется в операционных системах семейства Windows и характеризуется большими временными затратами.
4.1.2. Цепочечные файлы
Файлы разделены на множества так, что все элементы одного множества отождествлены с помощью ключевого слова. По аналогии со структурированными данными можно говорить о подобии текстов, отождествленных с помощью одного ключа. Внутри каждого множества файлы соединены ссылками, а для доступа к первому элементу в цепочке организуются справочники - индексы. В роли ссылок могут выступать, в частности, полные имена файлов.
Пусть ТБД содержит те же файлы, что и в предыдущем примере. Индекс – это структурированный файл вида:
Ключевое слово | Ссылка |
К1 | Ф1 |
К2 | Ф2 |
К3 | Ф1 |
К4 | Ф4 |
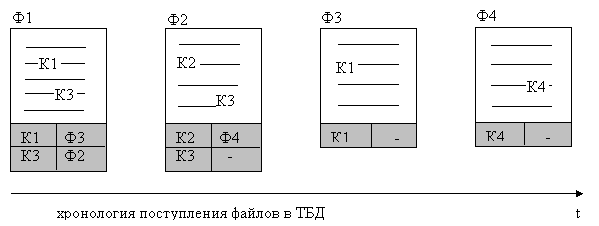 Кроме того, претерпевают изменения и сами файлы Ф1 – Ф4: они содержат описания цепочек подобных файлов, размещенные, например, в конце самих текстов (показаны заливкой):
Кроме того, претерпевают изменения и сами файлы Ф1 – Ф4: они содержат описания цепочек подобных файлов, размещенные, например, в конце самих текстов (показаны заливкой):

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 10 11 |
