

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. правило ближайшего соседа (NN),
2. правило ближайшего соседа с выбором информативной системы признаков по критерию минимума ошибок (NN+ U ),
3. правило ближайшего соседа с выбором информативной системы признаков по функции конкурентного сходства ( NN+Fs ),
4. правило ближайшего соседа относительно системы эталонных образцов, построенных алгоритмом FRiS-Stolp, с выбором информативной системы признаков по функции конкурентного сходства (Stolp+Fs).
На Рис. 2.11 приведена усредненная надежность распознавания контрольной выборки в этих экспериментах для задач фиксированной размерности (500 признаков, половина из которых статистически не связана с целевым) и числом объектов в обучающей выборке M, изменяющимся от 30 до 100.
Нетрудно видеть, что алгоритм FRiS-Agent оказался наиболее успешным при решении задач распознавания, характеризующихся малым объемом обучающей выборки. Этот эксперимент также подтвердил выводы, сделанные ранее, что в качестве критерия информативности при выборе системы признаков целесообразнее использовать среднее значение функции конкурентного сходства, а не среднюю ошибку распознавания, вычисленную в режиме скользящего экзамена.
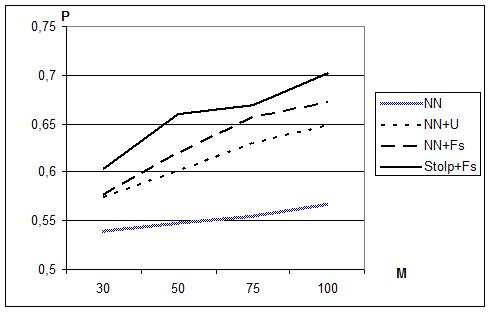
Рис. 2.11. Сравнение эффективности различных методов решения задачи DX, для задач с фиксированной размерностью N=500 и числом объектов М=30, 50, 75 и 100.
Выводы по второй главе
1. Для оценки информативности признаков или признаковых систем следует использовать не количество правильно распознанных объектов обучающей выборки U, а среднее значение Fs функции конкурентного сходства объектов обучающей выборки с эталонами своих образов [68]. Критерий Fs в этом случае оказывается менее чувствительным к эффекту «псевдоинформативности», и позволяет выбирать системы признаков, результаты распознавания в пространстве которых оказываются более устойчивыми и воспроизводятся на контрольных выборках.
2. Сравнение значения меры Fs для информативной подсистемы признаков, найденной на обучающей таблице, и аналогичной величины, вычисленной на серии случайных таблиц того же размера, позволяет получить качественную оценку степени «неслучайности» выбранного подпространства признаков.
3. Значение функции конкурентного сходства контрольного объекта с тем или иным образом дает возможность сопроводить принятое решение оценкой уверенности в правильности этого решения. Предложенная методика восстановления зависимости между величиной FRiS-функции и вероятностью ошибочного распознавания объекта по исходной таблице объект-свойство для каждой конкретной задачи оказалась эффективной при решении прикладных задач.
4. В процессе решения задачи DX целесообразно опираться не на все объекты выборки, а лишь на некоторый набор эталонных образцов (столпов). Среднее значение функции конкурентного сходства, вычисленное с опорой на набор столпов, является наилучшим критерием качества при решении задачи выбора информативной для распознавания системы признаков.
Глава 3. Использование функций конкурентного сходства при решении задачи SD
Задача таксономии (кластеризации, автоматической классификации) не теряет своей актуальности уже на протяжении многих лет. Несмотря на многочисленные попытки формализовать те принципы, которые человек-эксперт использует при построении классификации, до сих пор не удалось создать универсальный алгоритм таксономии, который мог бы составить реальную конкуренцию человеческой способности к обобщению, воспроизвести ее. Одним из возможных объяснений этого факта может служить высказанное в вводной части утверждение, что человек решает несколько задач одновременно, и только переход от решения основных задач распознавания к комбинированным позволит достаточно адекватно моделировать человеческую способность структурировать информацию.
В данной главе предпринята попытка решить данную проблему с помощью перехода от задачи таксономии S к задаче таксономии с одновременным построением решающего правила SD и привлечением к ее решению инструмента FRiS-функций. Тем самым мы с одной стороны подготовили базис для решения более общей задачи – задачи таксономии с одновременным построением решающего правила и выбором наиболее информативного пространства признаков SDX, а с другой – получили алгоритм, имеющий самостоятельную ценность при решении задачи таксономии.
3.1. Редуцированная функция конкурентного сходства
При решении задачи построения решающего правила мы работали с классифицированной выборкой. Потому определение функции конкурентного сходства как соотношения между расстояниями от объекта до двух конкурирующих образов было оправданным. В процессе исследования, результаты которого описаны в предыдущей главе, было показано, что ![]() - среднее значение функции конкурентного сходства по выборке с опорой на систему столпов S является среди прочего критерием, демонстрирующим то, насколько полно и точно данная система столпов описывает исходную выборку. Вспомним, что задача таксономии по сути является задачей построения сокращенного, но достаточно полного и точного описания выборки за счет перехода от объектов к классам объектов (эталонам классов). В связи с этим способность FRiS-функций выявлять такого рода описания может оказаться полезной в рамках и этой задачи. Однако так как на начальном этапе в задаче таксономии никакой информации о принадлежности объектов выборки к тому или иному образу (классу) нет, определение функции конкурентного сходства в ней несколько меняется. В отсутствие реального образа-конкурента, вводится некий виртуальный конкурент, равноудаленный от всех объектов выборки. Ниже приводится точное определение конкурентного сходства в задаче таксономии.
- среднее значение функции конкурентного сходства по выборке с опорой на систему столпов S является среди прочего критерием, демонстрирующим то, насколько полно и точно данная система столпов описывает исходную выборку. Вспомним, что задача таксономии по сути является задачей построения сокращенного, но достаточно полного и точного описания выборки за счет перехода от объектов к классам объектов (эталонам классов). В связи с этим способность FRiS-функций выявлять такого рода описания может оказаться полезной в рамках и этой задачи. Однако так как на начальном этапе в задаче таксономии никакой информации о принадлежности объектов выборки к тому или иному образу (классу) нет, определение функции конкурентного сходства в ней несколько меняется. В отсутствие реального образа-конкурента, вводится некий виртуальный конкурент, равноудаленный от всех объектов выборки. Ниже приводится точное определение конкурентного сходства в задаче таксономии.
Считается, что все объекты исходной выборки А принадлежат одному образу. Если зафиксировать набор столпов этого образа S={s1, s2, …, sk}, то для каждого объекта aÎA можно найти расстояние r1(а,S) (от объекта до ближайшего столпа из множества S). Но отсутствие образа-конкурента не позволяет определить расстояние r2 (от объекта до ближайшего столпа образа-конкурента). В связи с этим, на первом этапе вводится виртуальный образ-конкурент, ближайший столп которого удален от каждого объекта выборки на фиксированное расстояние, равное r2*. Таким образом, в задаче таксономии вместо обычной FRiS-функции мы будем использовать некую ее модификацию, которая для объекта aÎA имеет вид :
F*(a,S)=(r2*-r1(a,S))/(r2*+r1(a,S)). (3.1)
Далее в тексте эта модификация будет называться редуцированной FRiS-функцией [71]. Помимо этого нас будет интересовать среднее значение редуцированной функции для всех M объектов множества А:
![]() =
= 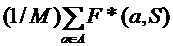 . (3.2)
. (3.2)
Если столпы расположены в центрах локальных сгустков объектов, то ![]() имеет максимальное значение. Именно значение средней редуцированной функции конкурентного сходства мы использовали в качестве индикатора при поиске центров локальных сгустков.
имеет максимальное значение. Именно значение средней редуцированной функции конкурентного сходства мы использовали в качестве индикатора при поиске центров локальных сгустков.
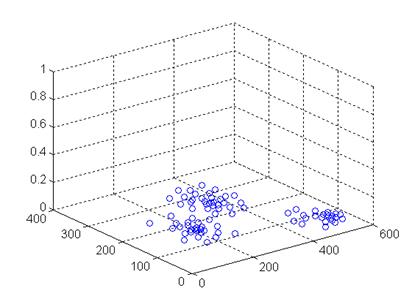
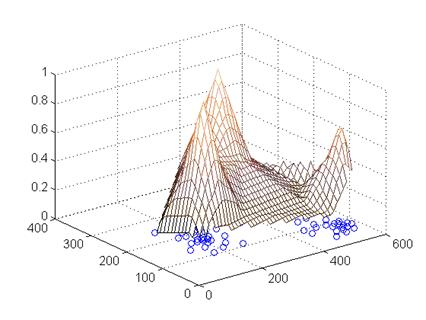
Рис. 3.1. Использование редуцированной FRiS-функции в качестве индикатора локальных сгустков.
На Рис. 3.1 представлена поверхность ![]() , порожденная набором объектов А, показанных точками на плоскости. Локальные максимумы этой функции располагаются в центрах локальных сгустков объектов.
, порожденная набором объектов А, показанных точками на плоскости. Локальные максимумы этой функции располагаются в центрах локальных сгустков объектов.
3.2. Алгоритм FRiS-Tax
Перейдем теперь непосредственно к описанию алгоритма. Его работа состоит из двух этапов. На первом этапе, называемом FRiS-Cluster, отыскиваются центры локальных плотностей объектов. Каждый из них рассматривается как эталонный образец (столп) некоторого кластера. Все объекты выборки естественным образом распределяются между кластерами. Каждый объект a относится к тому кластеру, чей эталонный образец оказался к нему ближайшим. Полученное разбиение уже может рассматриваться как готовый результат, если эксперта устраивает его качество. В противном случае полученная кластеризация передается на второй этап работы алгоритма, называемый FRiS-Class. На этом этапе происходит процедура укрупнения таксонов, усложнения их формы. Соседние кластеры, удовлетворяющие определенным условиям, признаются принадлежащими одному классу. Это позволяет создавать таксоны произвольной формы, не обязательно линейно разделимые.
3.2.1 Кластеризация (этап FRiS-Cluster)
Предложенный алгоритм выбирает число кластеров автоматически. Пользователь задает лишь предельное число кластеров К, среди которых он хотел бы получить наилучший вариант кластеризации. Алгоритм последовательно ищет решения задачи кластеризации для всех значений k=1, 2,…,K, чтобы потом выбрать из них наиболее удачные. Происходит это следующим образом:
1. При k=1 произвольно выбранный объект а назначается столпом и для него по формуле (3.2) вычисляется средняя редуцированная FRiS-функция ![]() .
.
2. П.1 повторяется при поочередном назначении столпами всех М объектов выборки. В качестве первого столпа s1 выбирается объект a*, для которого величина 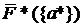 оказывается максимальной.
оказывается максимальной.
3. После того, как первый столп зафиксирован, определяется, какой объект будет наилучшим в роли второго столпа. Произвольный объект a, не совпадающий с s1, назначается вторым столпом. Затем для набора из двух столпов {a, s1} вычисляется средняя редуцированная FRiS-функция ![]() ({a, s1}).
({a, s1}).
4. На роль второго столпа поочередно назначаются все объекты выборки, не совпадающий с s1, и повторяется п. 3. В качестве второго столпа s2 выбирается тот объект а*, который в паре с s1 обеспечивает максимальное значение средней редуцированной функции конкурентного сходства ![]() ({a*, s1}).
({a*, s1}).
5. После того, как были найдены два столпа, вся выборка распределяется между ними по следующему правилу. Объект относится к тому кластеру, расстояние r1 до столпа которого минимально. Объекты, присоединенные к первому столпу s1, образуют кластер А1. Объекты, ближайшим для которых оказался столп s2, образуют кластер A2.
6. Если при k=1 в первый кластер A1 входили все М объектов, то теперь при k=2 часть объектов переходит в новый кластер A2. При этом может получиться так, что для описания кластера A1 наилучшим окажется не столп s1, а какой-то другой объект из этого кластера. Чтобы найти окончательное положение эталонных объектов этих двух кластеров мы выполняем следующую процедуру. По очереди каждый объект а1 кластера А1 назначается на роль столпа, и по формуле (2.2) вычисляется средняя FRiS-функция F({a1,s2}). В качестве столпа выбирается такой s12, который обеспечивает максимальную величину среднего значения FRiS-функции. Аналогично в кластере A2 определяется новое положение столпа s2 по максимуму функции F({s12,a2}). На этом этапе вместо редуцированной FRiS-функции мы используем обычную FRiS-функцию, отражающую процесс конкуренции между реальными столпами. Среднее значение FRiS-функции при описании всей выборки столпами {s12,s22} и используется в качестве оценки качества кластеризации при числе таксонов k=2: F2= ![]() ({s12,s22}).
({s12,s22}).
7. Для дальнейшего расширения списка столпов мы снова используем исходные столпы {s1, s2} и редуцированную FRiS-функцию. Все объекты выборки поочередно «пробуются» на роль третьего столпа. Для каждого из вариантов вычисляется средняя редуцированная функция конкурентного сходства и выбирается тот из них, для которого эта величина максимальна. Этот объект и фиксируется в качестве очередного столпа. После этого описанное в пункте 6 переопределение столпов делается для всех трех кластеров и вычисляется качество кластеризации F3.
8. Процесс продолжается, пока не будут получены кластеризации для всех значений k = 1,2,.., К. При этом каждый раз список столпов {s1, s2,…, sk}, с одной стороны, используется для нахождения очередного столпа sk+1, а, с другой, - для получения окончательного разбиения и оценки его качества Fk для этого k . На Рис. 3.2 этот процесс изображен схематически. Движению по вертикали вниз соответствует процесс наращивания числа столпов с использованием редуцированной FRiS-функции. Движению по горизонтали – уточнение положения столпов и вычисление качества кластеризации с использованием FRiS-функции. Подчеркиваем, что переходить от редуцированной к обычной FRiS-функции, так же как и переустанавливать столпы, целесообразно лишь для получения окончательного результата разбиения на k кластеров.
Очевидно, что в случае, когда все объекты выборки используются в качестве столпов (всего М столпов), качество кластеризации FM достигает своего максимального значения, равного 1. Однако на пути к этому главному экстремуму имеются локальные максимумы. Наши эксперименты показали, что достигаются локальные максимумы при таком числе кластеров, которое человеком-экспертом в двумерном случае «на глаз» признается «разумным». Под «разумностью» в данном случае понимается то, что объекты, отнесенные экспертом к разным таксонам, в результате проведения кластеризации нашим алгоритмом оказываются в разных кластерах.
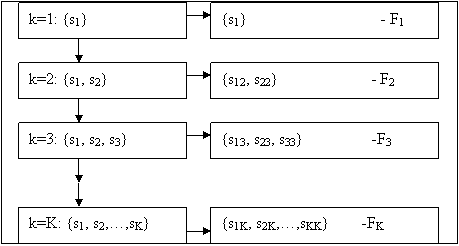

Рис. 3.2. Схема работы алгоритма на этапе FRiS-Cluster.
3.2.2. Построение классификации (этап FRiS-Class)
Часто классы, выделяемые экспертами, оказываются достаточно сложной формы, которую не удается описать единственным эталонным объектом. Именно поэтому в алгоритме FRiS-Tax предусмотрена процедура FRiS-Class для объединения нескольких кластеров в один класс, которая запускается для наиболее удачных вариантов кластеризации, полученных на первом этапе.
Основная идея, лежащая в основе этого этапа алгоритма заключается в следующем. Если процедура кластеризации проведена удачно, то кластеры, относящиеся к разным классам, отделяются друг от друга зонами с пониженной плотностью объектов. А на границе кластеров, относящихся к одному классу, такого понижения плотности нет, объекты выборки там распределены достаточно равномерно. Формализованный алгоритм проверки характера расположения объектов на границах кластеров выглядит следующим образом:
1. Каждую пару кластеров Аi и Аj проверяют на наличие объектов, которые находятся около разделяющей их границы (в зоне конкуренции). Объект а считается относящимся к зоне конкуренции кластеров Аi и Аj, если выполняются следующие условия:
а) столпы кластеров Аi и Аj являются двумя ближайшими к нему столпами;
б) абсолютная величина FRiS-функции для этого объекта меньше некоторого порога F*;
в) расстояние от a до «своего» столпа меньше, чем расстояние между столпами si и sj. Это условие необходимо в связи с тем, что большие расстояния могут означать общую удаленность объекта от всех эталонов.
Кандидатами на объединения считаются те пары кластеров, зоны конкуренции которых не пусты.
2. Расстоянием Dij между кластерами Ai и Aj считается минимальное расстояние между двумя объектами а и b, попавшими в зону конкуренции и принадлежащими разным кластерам.
3. Для этих объектов а из Ai и b из Aj, определяются расстояния Da и Db от каждого из них до ближайшего своего соседа.
4. Кластеры Ai и Aj считаются принадлежащими одному классу, если значения этих трех величин Dij, Da и Db мало отличаются друг от друга. Например, может проверяться следующее условие:
(Da<αDb)&(Db<αDa)&(Dij<α(Da+Db)/2), где α>1.
По окончании второго этапа качество классификации пересчитывается. Только, в отличие от первого этапа, когда каждый кластер описывался единственным эталонным образцом (столпом), здесь более сложная структура - класс может описываться набором из нескольких столпов.
3.2.3. Выбор оптимального числа таксонов
Напомним, что при запуске алгоритма пользователь задает диапазон, в котором варьируется число кластеров k. После окончания первого этапа мы имеем по одному варианту кластеризации для каждого k из заданного диапазона с вычисленным качеством кластеризации Fk. На втором этапе алгоритма мы уже работаем лишь с теми вариантами кластеризации, качество которых оказалось локально-максимальным, то есть
(Fk-1<Fk)&(Fk+1<Fk).
После второго этапа отсеиваются совпадающие варианты классификации, и такие, которые в результате объединения образуют единственный класс. Но даже после этого может остаться несколько вариантов таксономии, из которых надо выбрать единственный. Наши эксперименты показали, что в случае незначительной разницы между числом кластеров в разных вариантах классификации, выбирать следует тот из них, который обеспечивает максимальное среднее значение FRiS-функции. В случае же с большой разницей между количеством кластеров в разных вариантах этот подход нельзя использовать, и приходится оставлять несколько вариантов таксономии. Однако, подобная «неоднозначность» согласуется со следующим наблюдением. В зависимости от требуемого уровня детализации человеком тоже могут быть построены варианты таксономии с разным числом классов. Например, в структуре военнослужащих могут быть выделены таксоны-полки и таксоны-батальоны. И сказать, что один из этих вариантов предпочтительнее другого нельзя до тех пор, пока строго не будет зафиксирована цель, для которой создается таксономия.
3.3. Примеры работы алгоритма
Проиллюстрируем работу алгоритма на конкретном примере. На Рис. 3.3 изображено кольцо с изолированным сгустком в центре. Эту простенькую задачу любой человек легко решит «на глаз», но она оказывается не под силу большинству существующих алгоритмов таксономии.
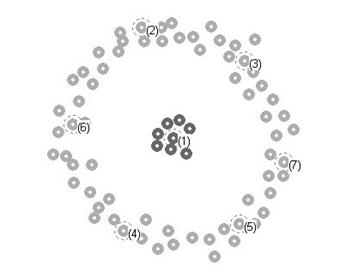
Рис. 3.3. Результаты работы алгоритма FRiS-Class – объединение 7 кластеров на 2 класса. Столпы здесь помечены пунктирной обводкой, а классы – изменением тона объектов.
Для усложнения задачи число классов, на которое требовалось разбить представленное множество объектов, не задавалось. Единственным ограничением, зафиксированным перед началом работы, было то, что число столпов, построенных на первом этапе, не должно превышать 15. После завершения 1-го этапа работы алгоритма и выбора локальных максимумов для FRiS-функции, из 14 вариантов кластеризации осталось два – разбиение на 7 и 11 кластеров (Рис. 3.4).
Оба варианта после процедуры укрупнения кластеров на 2-ом этапе дали идентичные результаты: в один таксон выделилось кольцо, а в другой – сгусток в центре. Таким образом, наш алгоритм автоматически определил, на какое число таксонов требуется разбить выборку. При этом его вариант решения задачи совпал с решением, которое выбирают эксперты.
![]()
![]()
Рис. 3.4. Динамика изменения качества кластеризации (FRiS-функции) в зависимости от числа кластеров. Локальные максимумы на графике обведены.
На Рис. 3.5 показаны еще 4 различных тестовых примера, для которых с помощью FRiS-функций удалось определить оптимальное число кластеров и классов по описанной выше методике. Несмотря на разный характер рассматриваемых примеров, варианты решения их всех, предложенные алгоритмом FRiS-Tax были признаны человеком-экспертом разумными и оправданными.


Рис. 3.5. Примеры тестовых задач, успешно решенных алгоритмом FRiS-Class.
3.4. Экспериментальная проверка алгоритма FRiS-Tax, сравнение с существующими аналогами
Предложенный алгоритм таксономии доказал свою эффективность не только на простых тестовых примерах, но и на реальных прикладных задачах. В одной из них обучающая выборка состояла из спектров 160 образцов, которые по химическому составу делились на 7 групп. Каждый спектр представлял собой 1024-мерный вектор. Проводилось разбиение обучающей выборки в пространстве спектральных характеристик на классы (их число варьировалось от 2 до 18) несколькими известными алгоритмами таксономии. Аналогичная задача, решалась с помощью алгоритмов FRiS-Cluster и FRiS-Tax. Построенные разбиения сравнивались с имеющейся классификацией исследуемых образцов по их химическому составу. Эффективность алгоритмов оценивалась через величину однородности полученных таксонов с точки зрения химического состава объектов, попавших в них. Подчеркнем, что знания о химическом составе не участвовали в процессе таксономии, а использовались только для оценки получаемых результатов.
В качестве количественной меры неоднородности n использовалась энтропия. Она определялась следующим образом. Если в j-ом таксоне, ![]() среди Mj объектов обучающей выборки есть Mji представителей i-го образа,
среди Mj объектов обучающей выборки есть Mji представителей i-го образа, ![]() (в данном случае L=10 , по количеству цифр) (Mj=
(в данном случае L=10 , по количеству цифр) (Mj=![]() Mji), то, принимая доли αi каждого образа (соответствующего каждой цифре) в этой смеси равными αi= Mji/Mj определяем меру неоднородности (энтропию) таксона:
Mji), то, принимая доли αi каждого образа (соответствующего каждой цифре) в этой смеси равными αi= Mji/Mj определяем меру неоднородности (энтропию) таксона:
Ej=-α1*logα1- α2*logα2-…- αL*logαL (здесь log –логарифм по основанию 2, 0*log0=0).
Однородность j-ого таксона определяется следующим соотношением:
nj=1-Ej/Emax, где Emax=-log(1/L).
Общее качество полученной таксономии оценивалось как средневзвешенная однородность по всем таксонам:
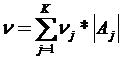 . (3.3)
. (3.3)
Всего в тестировании участвовало 5 алгоритмов. Все они оперируют понятием центра таксона, и после окончания своей работы предоставляют пользователю не только само разбиение, но и набор эталонных образцов – столпов. Перечислим их:
1. самый популярный на западе алгоритм k-Means [33, 47],
2. алгоритм Forel, «раскатывающий» множество исследуемых объектов на таксоны сферической формы с фиксированным радиусом [15],
3. алгоритм Scat, который из сферических таксонов, созданных алгоритмом Forel, конструирует таксоны более сложной формы [15],
4. алгоритм FRiS-Cluster, который создает линейно разделимые кластеры, и каждому кластеру ставит в соответствие один эталонный образец.
5. Алгоритм FRiS-Tax, который создает таксоны сложной формы, объединяя несколько кластеров в один таксон.
Рассмотрение нового алгоритма в двух вариациях объясняется тем, что каждая из них позволяет решать свой класс задач. FRiS-Cluster корректнее сравнивать с алгоритмами k-Means и Forel, создающими таксоны простой формы, а FRiS-Class позволяет находить решения одинакового порядка сложности с алгоритмом Scat.
На Рис.3.6 приводятся оценки качества таксономии (определяемого мерой однородности таксонов), полученной этими пятью алгоритмами для разного числа таксонов от 2 до 15.
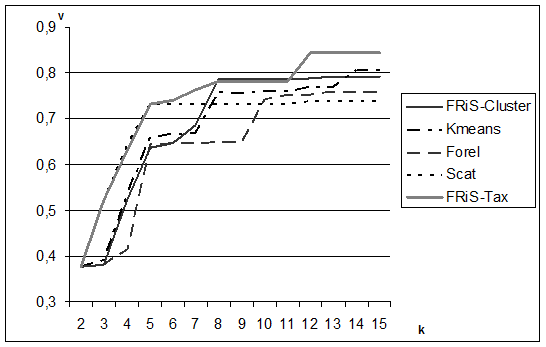
Рис. 3.6. Сравнение качества n(однородности получаемых таксонов) пяти алгоритмов таксономии.
Нетрудно увидеть, что результаты алгоритма FRiS-Cluster сопоставимы с результатами конкурентов, а результаты FRiS-Tax превышают результаты конкурентов. Однако основное преимущество предложенного алгоритма состоит даже не в этом. Только использование FRiS-функции позволяет нам довольно четко определить, какой вариант таксономии следует предпочесть, на каком числе таксонов, следует остановиться.
На Рис. 3.7. приводится динамика изменения качества кластеризации после этапа FRiS-Cluster. При изменении числа кластеров от 2 до 20 на графике проявляются 4 локальных максимума – при разбиении на 2, 5, 8 и 19 кластеров.
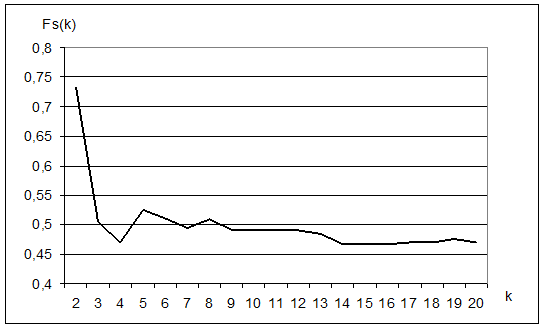
Рис. 3.7. Зависимость качества кластеризации (FRiS-функции) от числа кластеров.
После запуска второго этапа алгоритма FRiS-Tax для этих четырех случаев были получены 4 варианта таксономии, характеристики которых приводятся в Таблице 3.1. Здесь среднее значение FRiS-функции, подсчитанное для таксонов сложной формы (классов), позволяет выбрать наиболее удачный варианты таксономии. Им оказался вариант, когда 8 кластеров образуют 5 классов.
Таблица 3.1.
Сравнение качества разбиения тестовой задачи на различное число кластеров
k кластеров | K классов | FRiS-функция | Однородность |
2 | 2 | 0.733385 | 0.376637 |
5 | 4 | 0.739799 | 0.633148 |
8 | 5 | 0.775601 | 0.732845 |
19 | 13 | 0.512541 | 0.790021 |
Так как величина однородности изначально не может использоваться для сравнения качества разбиений с разным числом таксонов, то единственным более или менее объективным критерием в данном случае может считаться экспертная оценка. А для ее понимания необходимо чуть глубже вникнуть в природу задачи. Представленные в обучающей выборке образцы по химическому составу состояли из железа с относительно небольшой долей тех или иных примесей (Fe+Pb, Fe+Tl, Fe+Mo, Fe+S, Fe+Ni, Fe+Ni+Mn, Fe+Ni+Co). В случае разбиения на 5 таксонов в одной группе оказались образцы, содержащие никель (Fe+Ni, Fe+Ni+Mn, Fe+Ni+Co), а оставшиеся четыре типа веществ образовали каждое свой таксон. Более подробный анализ никелевых смесей показал, что добавки кобальта (Со) и марганца (Mn) в них составляют не более одного процента. И вклад их в спектральный портрет образца был настолько незначителен, что он не проявлялся и при анализе спектров вручную. Поэтому можно считать, что разбиение, выбранное нашим алгоритмом на роль оптимального, действительно является наилучшим, которое можно было достигнуть на представленном материале.
Выводы по третьей главе
1. Введение виртуального конкурента позволяет вычислять функцию конкурентного сходства по неклассифицированной выборке. Среднее значение редуцированной функции конкурентного сходства, вычисленное с опорой на виртуального конкурента, оказалось надежным индикатором для обнаружения центров областей сгущения объектов выборки.
2. Алгоритм FRiS-Tax [71, 74] использующий полезные свойства FRiS-функций для решения задачи SD, позволяет строить разбиение выборки на адекватные с точки зрения человеческого восприятия кластеры и классы. При этом кластеры представляют из себя мелкие линейно разделимые группы объектов, имеющие простую форму, которые, объединяясь, образуют более сложные структуры произвольной формы - «классы».
3. Использование среднего значения FRiS-функции для оценки качества таксономии позволило автоматизировать процесс выбора оптимального числа кластеров и таксонов в создаваемой таксономии. Эксперименты показали, что варианты кластеризации, соответствующие локальным максимумам зависимости FRiS-функции от числа кластеров, признаются наиболее «разумными» человеком - экспертом.
Глава 4. Задача «естественной» классификации и ее связь с задачей комбинированного типа SX
Задача комбинированного типа SX - задача построения таксономии в наиболее информативном подпространстве признаков считается более неоднозначной, чем задача DX – задача построения решающего правила в наиболее информативном пространстве из-за того, что оптимизируемый критерий качества для первой не определен однозначно. В данной главе предложен новый подход к построению критерия качества таксономии в выбранной подсистеме признаков. И в рамках этого подхода разработан алгоритм построения классификации, обладающей свойствами «естественных классификаций.
4.1. Дискуссионная природа термина «естественная классификация»
При обсуждении трудного вопроса о формальных критериях качества таксономии часто возникает термин «естественная таксономия» или «объективная классификация», которым обозначают некий идеал, к которому следует стремиться при разработке методов. При этом приводятся примеры некоторых классификаций, которые были в свое время разработаны великими естествоиспытателями, выдержали проверку временем и используются до сих пор.
Научное сообщество разделилось на два лагеря. Представители одного из них, например [8], считают, что разделение классификаций на естественные и искусственные неправомерно и наносит непоправимый вред естествознанию. Они утверждают, что любые классификации должны строиться для достижения фиксированных целей, с учетом некоторых фиксированных способов их достижения. Стремление же к получению естественных классификаций они сводят к стремлению получить такую классификацию, которая обеспечивала бы эффективное достижение всех известных и неизвестных целей всеми известными и неизвестными способами. Действительно, классификация, признанная хорошей одним поколением, следующему скорее всего не понравится. Это происходит потому, что хотя всякая удачная классификация отражает существующие в природе сходства и различия, распознаем эти сходства и различия мы. В том, как мы это делаем, отражаются наши нужды, знания, технические достижения, все это эволюционирует, и, следовательно, не может быть заданной раз и навсегда совершенно «объективной» классификации.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
