

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Представители другого лагеря – сторонники идеи «естественной классификации» дают следующие определения этого термина. «Естественной классификацией является та и только та классификация, которая выражает закон природы» [14]. «Естественная классификация представляет собой теорию структуры какой-то совокупности объектов» [20]. В [7] приводятся следующие требования, предъявляемые к «естественной классификации» как к специфической форме выражения закона природы:
- предсказание максимума свойств объекта по его месту в классификации;
- максимум общих утверждений о каждом классе;
- сохранение структуры классов при смене классификационных признаков;
- объективность, надежность, прогностическая сила.
Трудно не согласиться, что классификация, созданная для конкретных целей и с учетом средств их достижения, практически всегда будет эффективнее некой универсальной классификации с точки зрения достижения этих целей. Для обозначения таких классификаций введен специальный термин « классификация с суперцелью» [16], важность и ценность подобного рода классификаций несомненна. Однако, такая сущность, как «естественная классификации» все же время от времени возникает в естествознании. Мы будем рассматривать такие классификации как примеры удачной реализации человеческой способности к систематизации и использовать их для выделения характерных особенностей этой способности. Другими словами, мы попытаемся определить, какую итоговую цель осознанно или неосознанно преследует человек, строящий «естественную» классификацию, какие допущения использует, на какие предположения опирается. Функционал качества таксономии, построенный на основе анализа специфических особенностей и требований, предъявляемых к «естественным» классификациям, позволит создать новый подход и новые алгоритмы для анализа, систематизации и упрощения больших массивов информации.
4.2. Специфические свойства «естественных» классификаций
Рассмотрение классификаций, созданных экспертами и относимых к удачным, естественным классификациям, позволяет выделить следующие их основные черты.
Во-первых, в естественных классификациях разбиение производится по небольшому числу признаков. Специалисты, глубоко знающие изучаемые объекты, для целей естественной классификации ищут такое подпространство, т. е. взгляд на объекты с такой точки зрения, при которой хорошо видны четко отделяемые друг от друга группы объектов, похожих друг на друга. Если речь идет об иерархической таксономии, то на каждом уровне иерархии используется свое наиболее информативное подпространство признаков. Признаки, выбранные для таксономии, называют существенными.
Во-вторых, естественная классификация считается удачной, если ее дальнейшее использование позволяет предсказывать неизвестные свойства объектов, путем «распространения единичных наблюдений на весь класс» [20]. Наблюдая свойства небольшого числа реализаций из «естественного» класса, исследователь предполагает, что такими же свойствами, вероятно, обладают все представители этого класса. Классификация в этом случае не просто сводка единичных наблюдений, а гипотеза, предсказывающая многие (в том числе скрытые) свойства по немногим, лежащим в основе такой классификации. Общеизвестный пример подобных предсказаний – классификация элементов по атомному весу [62]. Когда предложил свою систему, кто-то в шутку посоветовал расположить элементы в алфавитном порядке по их названиям. На этом примере ярко видна разница между классификацией, не дающей никаких предсказаний, и естественной классификацией, ведущей к открытию глубинных пластов сходства, даже если эта классификация опирается на одно-единственное свойство.
Декандоль отделил голосеменные растения от покрытосеменных, такое важное свойство последних, как двойное оплодотворение, еще не было известно. Открытие этого свойства явилось неожиданным и тем более впечатляющим подтверждением таксономической гипотезы. В дальнейшем многочисленные (не всегда осознанные) попытки опровержения этой таксономии с помощью вновь открываемых цитологических или молекулярных признаков лишь подтвердили ее жизнеспособность.
Продолжая перечисление примеров, подтверждающих важность свойства «предсказательности» естественной классификации, нельзя не вспомнить известное высказывание биолога-систематика К. Линнея о том, что не признаки определяют род, а род определяет признаки.
Таким образом, классификация, обладающая свойством «естественности» с одной стороны должна удовлетворять неким геометрическим критериям характерным для любой таксономии. Так в пространстве информативных характеристик классы должны образовывать компактные и хорошо отделимые друг от друга группы объектов. Допустима и желательная иерархическая структура у такой классификации. Система информативных признаков должна быть минимальна.
С другой стороны существенным признаком и критерием естественной классификации является ее индуктивность, предсказательная сила. Именно возможности, открывающиеся благодаря появлению этого свойства, делают построение естественных классификаций столь желаемым итогом процесса структуризации информации.
Теперь, после того как мы явно определили основные свойства естественных классификаций, постараемся формализовать метод их построения, чтобы автоматизировать этот процесс.
4.3. Формулировка задачи построения «естественной» классификации в терминах задач комбинированного типа
Основной проблемой для классификаторов был и остается выбор подмножества существенных признаков из множества всех наблюдаемых признаков. При автоматической классификации выбор подмножества признаков может осуществляться тем или иным переборным алгоритмом. Важную роль играет критерий качества, в соответствии с которым признак или множество признаков признается существенным. С одной стороны, признаки могут считаться информативными для группировки, если после таксономии в их подпространстве таксоны хорошо отделимы друг от друга. Однако выполнение этого условия никак не может гарантировать предсказательную силу полученной таксономии. Так, например, если при классификации животных в число наблюдаемых признаков попадет пол, возраст, окрас, то разбиение по этому набору признаков может обладать высоким качеством с точки зрения геометрических таксономических критериев. Но не всегда такая классификация окажется полезной для дальнейшего применения.
Итак, в соответствии с нашими рассуждениями, алгоритмы естественной таксономии в процессе разделения множества объектов на таксоны должны одновременно решать задачу выбора подмножества не просто информативных, но существенных характеристик. Таким образом, в формальном выражении задача построения «естественной» классификации сводится к задаче комбинированного типа SX – задаче одновременного построения разбиения множества объектов и выбора информативного множества признаков (набора существенных признаков). Здесь под информативной системой понимается система, формально удовлетворяющая требованиям некоторого критерия информативности. Существенной же считается система признаков, обладающая предсказательной силой, то есть система информативная с точки зрения конкретного критерия, информативности в задаче естественной классификации, вид которого будет определен далее.
Напомним, что в соответствии с определением, данным в Главе 1. под задачей SX мы понимаем оптимизационную задачу (1.4) максимизации некоего функционал качества Qft(p,c,A), где А – анализируемая выборка, c- разбиение этой выборки на классы, а p-некоторое подмножество признаков из P(X), выбранных на роль информативных. В задаче построения естественной классификации этот функционал Qft(p,c,A) зависит от двух составляющих – непосредственно качества таксономии Qt в пространстве характеристик p и качества ожидаемой предсказательной силы Qr полученных таксонов во всем признаковом пространстве. При этом мы опираемся на предположение, что классификация, выбранная по критерию четкой разделимости таксонов и их предсказательной силы, способна выявить скрытые структурные закономерности множества анализируемых объектов, которые находят свое отражение во множестве существенных признаков и приближают формальную таксономию к идеальной естественной классификации.
4.3.1 Критерий качества в задаче « естественной классификации»
Относительно того, как может выглядеть критерий качества таксономии Qt, характеризующий меру компактности полученных групп объектов, существует достаточно разработанная теория. У различных алгоритмов таксономии есть свои собственные меры компактности, максимум которых они отыскивают в процессе работы. Так, например, в алгоритме KMean [33, 47], разбивающем множество объектов A на k групп {A1,…, At,…,Ak} с центрами в точках {s1,…, st,…,sk}, соответственно, критерий качества выглядит следующим образом:
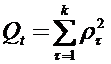 , где
, где 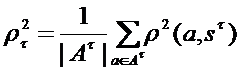 .
.
Здесь наилучшему разбиению соответствует минимальное значение Qt, то есть ищется такой вариант классификации, при котором объекты максимально похожи на центр «своего» класса.
В другом алгоритме таксономии FOREL [15], разбивающем множество объектов на таксоны сферической формы, оптимизируемый критерий качества выглядит несколько иначе:
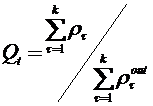 , где
, где 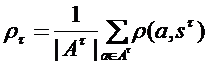 ,
,
![]() .
.
Теперь нужно оценить прогностическую способность Qr полученной таксономии. В общем случае речь идет об оценке возможности прогнозирования новых признаков для всего класса на основе информации, полученной при анализе прецедентов из этого класса. Фактически же мы можем оценить только возможности прогнозирования тех признаков, которые содержатся в исходной таблице «объект-признак». Прогнозы могут быть разными по сложности и получаемой точности [31]. Если всех пациентов госпиталя разделили на таксоны по существенным симптомам, а признак «температура тела» не вошел в их число, то для будущих прогнозов температуры можно попытаться найти закономерную связь между принадлежностью пациента к данному таксону и температурой его тела. С этой целью по данным исходной таблицы можно построить уравнения регрессии, которые связывали бы значения существенных признаков с температурой у пациентов этого таксона. Можно воспользоваться и любыми другими способами прогнозирования. В самом простом случае можно вычислить среднее значение температуры в таксоне и всем новым пациентам, отнесенным к этому таксону, приписывать найденное среднее значение. Такой прогноз будет явно не очень хорошим, но все же лучше, чем средняя температура по больнице.
Мы остановимся на последнем варианте, так как он проще всего поддается формализации. Для каждого признака j и таксона t определим его прогнозируемое значение как среднее по всем объектам, попавшим в этот таксон. Тогда следующая величина может быть использована для оценки ошибки такого прогнозирования:
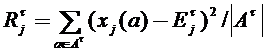 , где
, где 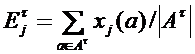 . (4.1)
. (4.1)
Эффективность таксономии для прогнозирования j-го признака в случае, когда этот признак нормированный (то есть величина ![]() £1) , может определяться следующей величиной:
£1) , может определяться следующей величиной:
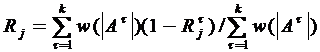 . (4.2)
. (4.2)
Здесь для усиления вклада больших таксонов в общую величину надежности вводится монотонно возрастающая весовая функция w(x). В наших экспериментах обычно использовалось w(x)=x или w(x)=x1/2.
А общая предсказательная сила данной таксономии, и, соответственно, рассматриваемого набора признаков p может считаться как среднее по всему набору признаков, либо по L признакам с наилучшим качеством прогнозов.
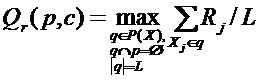 . (4.3)
. (4.3)
Такой вариант оценки прогностической способности таксономии позволит повысить устойчивость к шумящим признакам, которые могут содержаться в наборе.
Можно предложить различные варианты объединения компонент Qt и Qr в общий критерий Qft. В численных экспериментах нами использовался критерий качества, позволяющий свести исходную задачу к задаче двухуровневой оптимизации следующего вида:
Qft(p, c,A)= Qr(p, c*(p)) ![]() , где c*(p)=
, где c*(p)=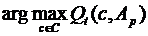 .
.
4.3.2 Алгоритм NatClass
В результате, общий алгоритм решения задачи выглядит следующим образом. В фиксированном признаковом подпространстве p находится оптимальное разбиение множества объектов на таксоны одним из известных алгоритмов таксономии. Затем вычисляется прогностическая способность Qr этого разбиения. Таким образом, перебирая различные варианты признаковых подпространств одним из методов направленного перебора, отыскивается то подпространство p*, такcономия c*(p*) в котором обладает максимальной прогностической способностью. Алгоритм, реализующий поиск подпространства существенных характеристик с одновременным разбиением множества объектов на «естественные» классы, действующий в соответствии с описанными правилами, далее будет называться алгоритмом NatClass.
4.4. Иерархическая таксономия
Выше отмечалось, что естественная классификация часто представляет из себя не просто разбиение множества объектов на классы, а некую иерархическую структуру, обычно дерево. Так в биологических классификациях видов виды объединяются в рода, рода – в отряды, отряды в классы. Для реализации этого подхода машинными методами предложен следующий вариант иерархической таксономии «сверху вниз».
4.4.1. Иерархический NatClass
На первом шаге все множество объектов разбивается на некоторое число таксонов k1 в некотором подпространстве существенных признаков p1 с помощью алгоритма NatClass и вычисляется оценка качества этого варианта таксономии Q1. На следующем шаге эту процедуру таксономии применяем к первому из полученных k1 таксонов, который разделится в некотором пространстве p21 на k21 более мелких таксонов. В результате получается таксономия, соcтоящая из (k1-1)+(k21) таксонов. Качество этой таксономии равно Q21. Затем восстановим первый таксон и сделаем таксономию объектов, входящих во второй таксон. Получим новый вариант таксономии в пространстве p22 с новой оценкой качества Q22. Аналогичные процедуры проделаем для всех k1 таксонов, полученных на первом шаге, и выберем для разбиения тот таксона i, который обеспечивает максимальное значение критерия Q2i. Именно разбиение этого таксона мы зафиксируем в качестве окончательного итога работы второго шага алгоритма. Таким образом, к началу следующего шага мы уже имеем разбиение множества наблюдаемых объектов на k1-1+k2i таксона, которые в дальнейшем будут участвовать в конкурсе на лучшее качество разбиения. Для них мы повторяем описанную выше процедуру поочередной таксономии всех висячих вершин и вычисления оценок качества получаемых вариантов Q3. После выбора варианта с наилучшим качеством получается иерархическая таксономия новой структуры с новым числом висячих вершин.
В результате, на каждом шаге будет дробиться одна из висящих вершин иерархического дерева, причем пространство признаков в каждом случае будет свое. Подобное дробление можно продолжать до тех пор, пока у нас не исчерпаются имеющиеся машинные ресурсы, либо пока будет улучшаться предсказательная сила полученной таксономии. Эту величину можно оценивать так же, как и в алгоритме однослойной естественной классификации, усредняя ее по всем таксонам, находящимся в рассмотрении на каждом шаге.
В данном методе можно наложить некоторые ограничения на число таксонов, получаемых за один шаг. При этом, если в какой-то момент в качестве подмножества существенных признаков выделится такое подмножество, которое использовалось на более высоком уровне иерархии, то можно осуществить откат до этого уровня и раздробить объекты, относящиеся к нему, на большее число таксонов.
Такой алгоритм далее будет называться иерархическим NatClass.
4.4.2. Другие возможные подходы к построению иерархической естественной классификации
Для построения иерархической структуры может использоваться не только движение «сверху вниз» от более общих классов к частным реализациям, но и обратный подход - движение снизу вверх. Для естественных классификаций это выглядит следующим образом. Предварительно мы разбиваем исходное множество объектов на заведомо большое число таксонов в пространстве существенных признаков с помощью алгоритма естественной классификации. Для дальнейшей таксономии используются не сами объекты, а типичные представители таксонов. При этом на каждом шаге из пространства существенных признаков выбирается подпространство, обеспечивающее наилучшую разделимость таксонов, не заботясь о предсказательной силе таксономии. Другими словами, при таком подходе на первом шаге мы выделяем элементарные компоненты структуры – переходим от прецедентов к базовым понятиям, а далее уже исследуем, как эти понятия сливаются в более общие, на основании близости существенных свойств.
Наконец, можно использовать третий способ построения иерархического дерева, основанный на комбинации двух, описанных выше. На первом этапе мы, как и во втором способе, выделяем слой базовых понятий и набор признаков, существенных для всего анализируемого материала. Далее, мы от этого слоя поднимаемся вверх (как описано во втором способе), строя иерархию понятий. Но помимо этого от слоя базовых понятий мы еще спускаемся вниз (как описано в первом методе). Это эквивалентно тому, что для каждого базового понятия мы ищем признаки, существенные именно для него, а не для всего множества полученных понятий, и производим дальнейшее дробление понятия по ним. Если вспомнить биологические классификации, то базовым понятиям там будут соответствовать виды, а при спуске вниз виды начнут разделяться на подвиды, породы и т. п.
Подобного рода иерархические классификации требуют больших затрат машинных ресурсов, однако они могут оказаться полезными для обнаружения новых знаний на фоне лавинообразного накопления эмпирических наблюдений, и вполне применимы, с учетом тенденций роста вычислительных скоростей, появления суперкомпьютеров.
4.5. Экспериментальная проверка эффективности алгоритма NatClass
Исследование и тестирование алгоритма NatClass проводилось на задаче о группировке арабских рукописных цифр. В нашем распоряжении была таблица, содержащая 64 мерные описания различных вариантов написания десяти цифр и помимо этого имелась информация о том о какой цифре идет речь в каждом конкретном случае. Всего выборка содержала 3823 объекта. В работе алгоритма информация о том, какой вектор какой цифре соответствует, не использовалась. Однако она использовалась для оценки и сравнения качества различных алгоритмов таксономии. При этом считалось, что неизвестным «существенным» признаком является принадлежность к одному из 10 образов, соответствующих 10 цифрам. Чем более однородными по составу получались таксоны тем лучше и «естественней» считалась классификация. Однородность n вычислялась по формуле (3.3).
На Рис. 4.1 приведены результаты первых двух шагов работы иерархического алгоритма NatClass, в основе которого лежал алгоритм таксономии Skat и алгоритм выбора системы информативных признаков AdDel. В проведенных экспериментах мы использовали следующие ограничения: каждый таксон на каждом шаге алгоритм мог дробить не более чем на пять таксонов в пространстве не более чем пяти признаков.

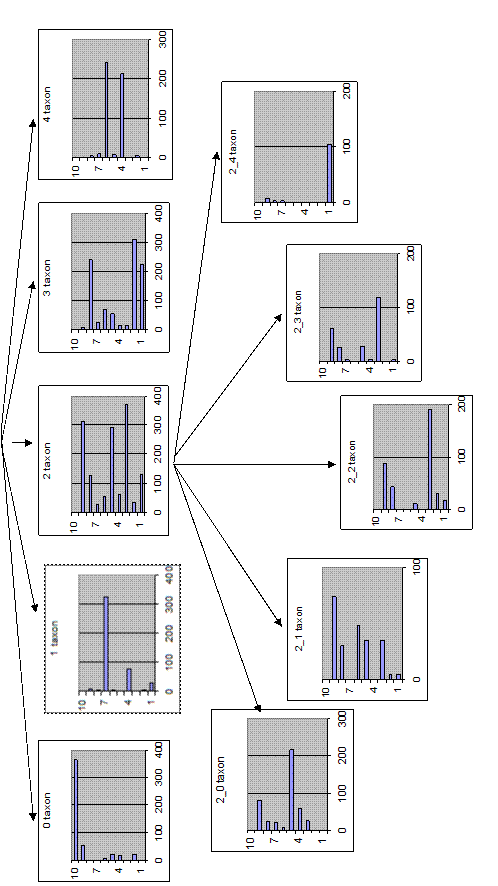

Рис. 4.1. Первые два шага работы алгоритма NatClass при решении задачи группировки рукописных цифр.
Качественный состав полученных таксонов изображен в виде гистограммы, отображающей количество объектов, принадлежащих к каждому из десяти анализируемых классов, и попавших в этот таксон. Из рисунка видно, что на втором шаге наибольшее улучшение однородности таксономии было обеспечено разбиением наиболее неоднородного таксона. Это тем более показательно, если вспомнить тот факт, что при построении таксономии состав таксонов был неизвестен и алгоритм NatClass никак на эту информацию не опирался.
Далее на Рис. 4.2 и Рис. 4.3 сравнивается однородность таксономии полученной одношаговыми алгоритмами Forel и Skat и таксономии, полученной нашим алгоритмом, с тем же, что и в этих алгоритмах таксономическими критериями качества.
Их анализ показывает, что подход, опирающийся на принципы естественных классификаций, оказывается более эффективным, чем алгоритмы таксономии, используемые им, сами по себе.
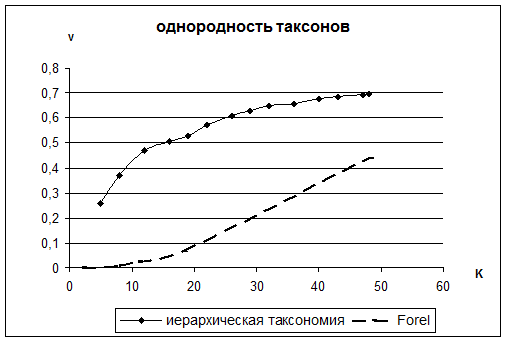
Рис. 4.2. Сравнение качества иерархического NatClass и алгоритма Forel.
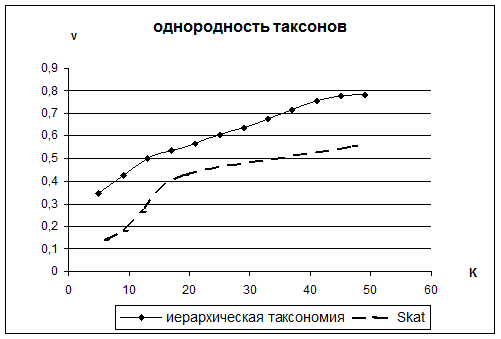
Рис. 4.3. Сравнение качества иерархического NatClass и алгоритма Scat.
4.6. Связь FRiS-функции и предсказательной способности таксономии
Как было сказано выше, одним из базовых свойств «естественных» классификаций можно считать их индуктивность (предсказательную способность). Различные варианты формализации этого свойства позволяют создавать различные алгоритмы построения классификации. В описанном выше алгоритме NatClass используется наиболее простое определение предсказательной способности, основанное на измерении степени похожести всех объектов класса на некий эталонный образец. При этом похожесть оценивалась через абсолютное расстояние от объекта до эталона. Однако, во второй главе нами было определено понятие конкурентной похожести (сходства), которое оказалось во многих смыслах более эффективным и полезным, чем простое определение сходства. В терминах конкурентного сходства формула для оценки предсказательной способности таксономии при прогнозировании j-го признака может выглядеть следующим образом:
![]() ,
,
где Fj(a) – функция конкурентного сходства, вычисленная в пространстве одного признака j либо с опорой на все объекты выборки (с учетом их принадлежности к построенным классам), либо с опорой на некоторый набор эталонных образцов классов. А общий критерий качества может выглядеть следующим образом:
Qft(p,c,A)= ,
здесь суммирование производится по всем признакам, не вошедшим в число существенных. В качестве альтернативы суммированию одномерных FRiS-функций по всем признакам можно использовать значение FRiS-функции, вычисленное в пространстве этих признаков:
Qft(p,c,A)= .
Разработке алгоритма, опирающегося на эту меру предсказательной способности таксономии для решения задачи SDX, посвящена следующая глава.
Выводы по четвертой главе
1. Задача «естественной классификации» возникает если исследователю необходимо построить некоторое разбиение объектов на группы для случая, когда не имеется информации ни о целях, для которых создается данная таксономия, ни о том, насколько важны и существенны признаки, характеризующие анализируемое множество объектов. Предполагается, что такая таксономия должна сократить и упростить описание исходного множества объектов, сохранив максимальное количество информации не только об этом множестве, но и о связях между признаками, используемыми для описания классов объектов со всеми прочими признаками, характеризующими объекты. Термин «естественная классификация» хоть и считается спорным, однако имеет примеры своей реализации в окружающем мире. Анализ удачных реализаций естественных классификаций, предложенных в различное время в разных естественно-научных областях, позволил нам выделить основные свойства и требования, предъявляемые к естественным классификациям.
2. Ключевым свойством всех анализируемых естественных классификаций являлась их высокая предсказательная способность. Формализация этого понятия, а также рассмотрение задачи автоматического построения классификации, обладающей свойствами «естественной», как задачи комбинированного типа SX, позволила сформировать критерий качества для построения таксономии с одновременным выбором системы существенных признаков. Для ее решения был разработан алгоритм NatClass [60, 61], который позволяет строить как одноуровневые таксономии, так и многоуровневые, представленные в виде иерархического дерева.
3. Анализ поведения предложенного алгоритма на прикладных задачах, оценка осмысленности классов, сформированных этим алгоритмом в соответствии с принципами «естественной» классификации, подтвердил пригодность этого алгоритма для структуризации малоизученных наборов информации. Сравнение качества алгоритма NatClass с другими алгоритмами таксономии, используемыми в данный момент, показало целесообразность выбора информативной подсистемы признаков для целей таксономии даже в тех задачах, в которых изначально не предполагается наличие неинформативных признаков в общем списке признаков.
Глава 5. Использование FRiS функции для решения задачи SDX
Перейдем к рассмотрению наиболее общей задачи распознавания, когда перед исследователем оказывается набор данных единой природы (из ограниченной предметной области), представленный в виде таблицы «объект-свойство». При этом относительно представленного набора известно лишь одно – он достаточно полно отражает многообразие объектов этой природы (предметной области) и многообразие признаков, их описывающих. Задачей же исследователя является структуризация этого возможно избыточного набора информации, представление его в виде, удобном для дальнейшего анализа и использования человеком. Человек в силу особенностей своего восприятия предпочитает иметь дело не со всеми M объектами, а с небольшим числом k групп (кластеров) этих объектов, описанных небольшим набором информативных признаков p, выбранных из их исходного множества Х. Групповое имя объектов, входящих в кластер, является образом этих объектов. Такое сокращенное описание должно содержать систему решающих правил, в соответствии с которыми каждый новый анализируемый объект может быть отнесен к тому или иному образу. Эти правила могут быть представлены в любом виде, удобном для использования, например в виде набора эталонов образов, на основании близости к которым будет распознаваться принадлежность нового объекта к тому или иному образу.
Из принципов натуральной классификации вытекает следующее. Будем считать, что подсистема pÎP(X) из l (l<N) информативных признаков хорошо отражает основное содержание исходной таблицы, если она не только обеспечивает хорошее распознавание принадлежности объектов к своим образам, но еще и позволяет предсказывать значения остальных (N-l) признаков, не вошедших в состав информативных. В связи с этим, помимо решающих правил сокращенное описание выборки должно содержать систему индуктивных правил, устанавливающих связь между этими двумя подмножествами признаков. По таким правилам для каждого объекта, входящего в образ, по значениям его информативных признаков можно восстанавливать значения остальных признаков. В качестве индуктивных правил могут использоваться регрессионные зависимости между двумя подмножествами признаков. Можно использовать и такие простые индуктивные правила: значения неинформативных признаков любого объекта образа i приравниваются средним значениям этих признаков, вычисленным по всем объектам данного образа, или их значениям у эталона этого образа.
Задача такого приведения исходной информации к виду, удобному для восприятия человеком, нами формулируется в терминологии задач комбинированного типа как задача типа SDX – задача одновременного формирования образов (классов) с решающими правилами для их распознавания в наиболее информативном подпространстве признаков. Для решения этой задачи будут использованы все наработки, полученные на предыдущих этапах – при решении более простых задач комбинированного типа – SD, DX и SX.
Для каждого варианта признакового подпространства p мы будем решать задачу типа SD. Переход от исходного множества объектов к набору кластеров с эталонными образцами (столпами) обеспечивает нас сразу и наилучшей классификацией c*(p) и наилучшим решающим правилом d*(p) в данном подпространстве. Оценку качество подпространства р, и, тем самым, качества решения всей задачи SDX будем основывать на отмеченных выше требованиях к качеству распознавания объектов и качеству предсказания значений неинформативных признаков. Перебор вариантов признаковых подпространств p и выбор наилучшего сочетания c*(p) и d*(p) в них продолжается до выполнения того или иного условия остановки.
Для произвольного объекта а в качестве прогнозируемого значения признака, не попавшего в список информативных, будет использоваться значение этого признака для столпа, ближайшего к рассматриваемому объекту в пространстве информативных (существенных) признаков. Таким образом, от исходного описания, представленного в виде таблицы размера M´N, мы перейдем к таблице k´N, где k- число классов, на которые было разбито исходное множество объектов. При этом l помеченных информативных признаков будут использоваться для принятия решения о принадлежности нового объекта к тому или иному классу, а значения оставшихся (N-l) являются прогнозируемыми значениями этих признаков для соответствующих классов.
Так выглядит содержательная формулировка задачи SDX в наиболее простом виде.
5.1. Формальная постановка задачи SDX
Обозначим исходное множество объектов за А. Для фиксированного набора столпов SÍА и некоторого подмножества информативных признаков из исходного множества признаков Х (YÍX) определим качество, с которым выбранный набор данных <S,Y> описывает исходный набор <А,X> как:![]()
![]() , (5.1)
, (5.1)
где rX и rY – метрики в пространстве X и Y соответственно.
В этом критерии предсказательная сила системы признаков Y и набора столпов S оценивается через близость всех объектов исходной выборки к своим прогнозируемым значениям, определяемым значениями этих же признаков для столпов, в полном пространстве признаков. При этом для каждого объекта а в качестве «своего» (прогнозирующего) берется столп s, ближайший к объекту а в информативной системе Y. Чем больше величина Q(S,Y) тем менее точные прогнозы мы имеем и, соответственно, тем хуже пара <S,Y> решает задачу SDX. Целью же является отыскание такой пары <S*,Y*>, которая обеспечит минимальное значение функционалу качества Q. Таким образом, рассматриваемая задача может быть записана в следующем оптимизационном виде:
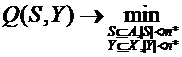 , (5.2)
, (5.2)
где 1<n*<N, 1<m*<M – величины, ограничивающие размер информативного подпространства и количество столпов соответственно. Необходимость в ограничениях на мощность отыскиваемого множества столпов S и набора признаков Y возникает из-за того, что своего глобального минимума (наивысшей точности прогноза) Q(S,X) достигает при S=А и Y=X, то есть в случае отказа от сжатия информации в угоду сохранения точности ее представления.
5.1.1. Формулировка задачи SDX в терминах FRiS-функций
Заметим, что в зависимости от используемых метрик r, вид критерия качества Q может меняться. Исследования, проведенные в предыдущих главах, показали, что в качестве меры близости объекта к классу (в данном случае к столпу, как типичному представителю класса) часто оказывается целесообразнее использовать не абсолютное значение расстояния, а функцию конкурентного сходства (FRiS-функцию). И действительно, функция конкурентного сходства, по сути, является альтернативным вариантом r, вычисляемым в соответствии с принципами человеческого восприятия. Применительно к этой конкретной задаче это выразится в том, что критерий качества Q перепишется в следующем виде:
![]() , (5.3)
, (5.3)
где FX –функция конкурентного сходства в пространстве X, rY – метрика в подпространстве Y. По-прежнему новый объект будет относиться к классу, чей типичный представитель окажется ближайшим в пространстве информативных признаков. Однако для оценки предсказательной способности построенной системы классов на объектах обучающей выборки будет вычисляться функция конкурентного сходства в пространстве всех признаков. Естественно, при таком подходе нужно отыскивать S и Y, максимизирующие сумму FRiS-функций. И в такой альтернативной формулировке интересующая нас задача выглядит следующим образом:
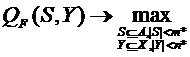 (5.4)
(5.4)
Очевидно, что обе сформулированные выше задачи решаются точно лишь полным перебором. Мы же рассмотрим два подхода, позволяющие находить достаточно хорошие их решения за полиномиальное время.
5.2. Алгоритм отыскания решения задачи SDX
Разложим исходную задачу (5.2) с оптимизацией по двум параметрам на две задачи.
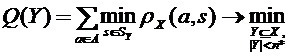 ,
,

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
