

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
где 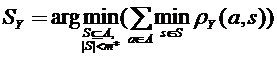 (5.5)
(5.5)
В одной из них мы строим набор столпов SY в фиксированном пространстве Y, обеспечивающий нас наиболее точным описанием выборки в рамках заданных ограничений на мощность. Для отыскания такого набора столпов в данном случае целесообразно применить алгоритм таксономии k-Means, в котором под компактностью таксона понимается именно похожесть объектов на центр. Единственным ограничением является тот факт, что указанный алгоритм строит синтетические столпы вместо того, чтобы отыскивать типичных представителей среди объектов выборки. Если условие SYÍA, является непринципиальным для решаемой конкретной задачи, то в качестве множества SY можно брать центры m* таксонов, найденные алгоритмом k-Means, а в качестве прогнозируемых значений признаков из множества X/Y (тех, что не попали в число информативных) для заданного таксона берется среднее их значение по всем объектам, попавшим в этот таксон. Если же SYÍA является необходимым, то каждому центру таксона s в построенной таксономии ставится в соответствие ближайший к нему объект выборки ![]() , и уже этот набор ближайших реальных аналогов используется в качестве набора эталонов. В этом случае в качестве прогнозируемых значений признаков из множества X/Y для заданного таксона с типичным представителем
, и уже этот набор ближайших реальных аналогов используется в качестве набора эталонов. В этом случае в качестве прогнозируемых значений признаков из множества X/Y для заданного таксона с типичным представителем ![]() используются значения этих признаков у данного типичного представителя.
используются значения этих признаков у данного типичного представителя.
Аналогичный переход к двум более простым задач можно выполнить для задачи (5.4):
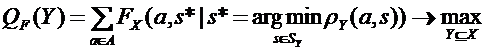 ,
,
где 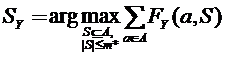 . (5.6)
. (5.6)
В одной из них мы строим набор столпов SY в фиксированном пространстве Y, который обеспечивает нас наиболее точным описанием выборки в рамках заданных ограничений на мощность. Набор столпов SY для зафиксированной подсистемы признаков Y отыскивается с помощью алгоритма таксономии FRiS-Tax, который опирается на использование функций конкурентного сходства и в процессе работы строит набор столпов, обеспечивающий максимум среднего значения функции конкурентного сходства по выборке. Процедура решения задачи (5.6) в результате оказывается более трудоемкой, чем процедура решения задачи (5.5), использующей алгоритм таксономии k-Means. Однако, алгоритм FRiS-Tax обладает возможностью автоматически определять число таксонов (столпов) в диапазоне от 1 до m*, в то время как алгоритм k-Means работает лишь после фиксации числа таксонов в разбиении.
При переходе к решению задачи таксономии, мы опираемся на допущение, что в пространстве Y существенных (информативных) характеристик классы, обладающие реальными предсказательными свойствами, должны образовывать компактные сгустки, и, как следствие, отыскиваться с помощью некоторой таксономической процедуры. Выбор же самого пространства Y после определения алгоритма для вычисления QF(Y) может осуществляться одной из известных процедур направленного поиска (алгоритмом AdDel, GRAD, СПА), либо локального спуска.
Таким образом, сложная задача SDX сводится к серии более простых, решение которых позволяет представлять исходную выборку объектов в виде их групп (S), формирует решающее правило (D) для отнесения новых объектов к этим группам в информативном подпространстве признаков (Х).
5.3.Иерархическая классификация
Обсуждаемый выше подход касался построения одноуровневой классификации в едином информативном подпространстве. Теперь же мы можем перейти к рассмотрению более сложной задачи построения решения задачи SDX в виде иерархической классификации, описываемой деревом T. Корневой вершине T0 в этом дереве будет соответствовать все множество объектов обучающей выборки A. Конечным классам (группам) в этом дереве будут соответствовать висячие вершины. Поддереву в виде вершины Ti и всех связанных с ней вершин следующего уровня ![]() ,
,![]() , …,
, …,![]() соответствует разбиение группы объектов на подгруппы (Рис. 5.1). На каждом таком разветвлении (для каждого разбиения) может использоваться свое собственное подпространство признаков Yi.
соответствует разбиение группы объектов на подгруппы (Рис. 5.1). На каждом таком разветвлении (для каждого разбиения) может использоваться свое собственное подпространство признаков Yi.
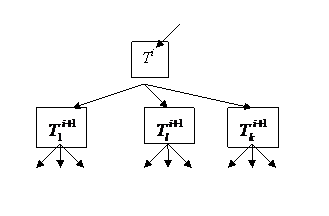 |
Рис. 5.1. Поддерево, соответствующее разбиению класса с уровня i на k подклассов на уровне i+1.
Каждой вершине (классу) ставится в соответствие свой эталонный образец (столп), который используется уже для распознавания новых объектов по дереву в соответствии со следующим итеративным правилом. Если промежуточный класс Ti в подпространстве Yi разбивается на подклассы ![]() ,
,![]() , …,
, …,![]() с эталонами
с эталонами ![]() ,
, ![]() , …,
, …, ![]() соответственно, то при распознавании нового объекта а, попавшего по цепочке в класс Ti, он относится к тому подклассу, расстояние до эталона которого в подпространстве Yi оказывается минимальным.
соответственно, то при распознавании нового объекта а, попавшего по цепочке в класс Ti, он относится к тому подклассу, расстояние до эталона которого в подпространстве Yi оказывается минимальным.
В соответствии с этим правилом каждому новому объекту a сопоставляется цепочка связанных вершин, по которым осуществляется переход от вершины T0 к некоторой висячей вершине ![]() с эталоном
с эталоном ![]() в подпространстве Yd-1. В примере на Рис. 5.2 переходы с уровня на уровень выделены пунктиром. Каждому переходу соответствует процедура определения ближайшего эталона по всем вершинам следующего уровня, связанным с текущей. Цепочка в нем может быть записана в виде последовательности эталонов {
в подпространстве Yd-1. В примере на Рис. 5.2 переходы с уровня на уровень выделены пунктиром. Каждому переходу соответствует процедура определения ближайшего эталона по всем вершинам следующего уровня, связанным с текущей. Цепочка в нем может быть записана в виде последовательности эталонов {![]() ,…,
,…, ![]() ,
, ![]() ,
, ![]() }, на которые максимально похож объект а на каждом уровне иерархии. При этом каждый из перечисленных эталонов располагается в своем подпространстве Y0,…, Yi-1, Yi,…, Yd-1 соответственно.
}, на которые максимально похож объект а на каждом уровне иерархии. При этом каждый из перечисленных эталонов располагается в своем подпространстве Y0,…, Yi-1, Yi,…, Yd-1 соответственно.
Однако реального типичного представителя ![]() класса
класса ![]() , в который попал произвольный объект a, мы будем определять в пространстве всех характеристик, используемых в процессе его соотнесения с этим классом, то есть в пространстве Y=
, в который попал произвольный объект a, мы будем определять в пространстве всех характеристик, используемых в процессе его соотнесения с этим классом, то есть в пространстве Y=![]() . Для этого выполняется следующая процедура. Для каждого признака yÎY находим j*=max{j| yÎYj}- максимальную глубину, на которой располагается подпространство, содержащее этот признак. Тогда sd(y)=sj*(y), то есть в качестве значения признака y для sd будем использовать значение этого признака y промежуточного столпа с уровня j*.
. Для этого выполняется следующая процедура. Для каждого признака yÎY находим j*=max{j| yÎYj}- максимальную глубину, на которой располагается подпространство, содержащее этот признак. Тогда sd(y)=sj*(y), то есть в качестве значения признака y для sd будем использовать значение этого признака y промежуточного столпа с уровня j*.
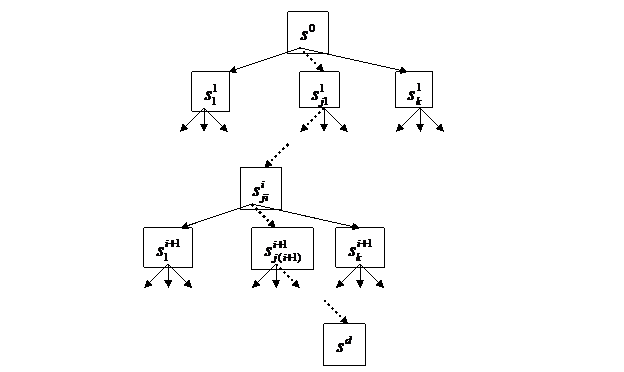

Рис. 5.2. Процедура распознавания объекта a по дереву T.
Если же ставится условие, что в качестве типичного представителя может выступать лишь объект выборки, то при построении столпов на последнем этапе для синтетического столпа sd выполняется процедура поиска ближайшего к нему в подпространстве Y объекта из выборки 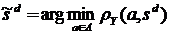 .
.
Таким образом, для каждой висящей вершины определяется ее эталонный образец. При появлении нового объекта a по дереву T отыскивается вершина (класс), в которую он попадает, и, соответственно, эталонный образец этого класса будем обозначать через T(a). В качестве прогнозируемых значений признаков из X\Y, неизвестных для нового объекта, берутся значения этих признаков для эталона класса, в который попал этот объект. Тогда оптимизируемый критерий качества для построения решения задачи SDX в виде дерева выглядит следующим образом:
![]() (5.7)
(5.7)
Здесь T(a) – столп, определяемый по дереву T, для висящей вершины, в которую попал объект а по правилам, описанным выше. В процессе построения решения задачи SDX в виде иерархии ищется такое дерево T, которое обеспечивает минимальное значение функционала ![]() при заданных ограничениях:
при заданных ограничениях:
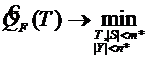 (5.8)
(5.8)
5.3.1. Алгоритм решения иерархической задачи SDX
Для того, чтобы решить эту задачу, необходимо разделить ее на более простые задачи, каждой из которых соответствует разделение одной вершины дерева. Дроблению же одной вершины соответствует задача (5.2) или (5.4) в зависимости от того, какими вычислительными ресурсами мы обладаем. Если повышение трудоемкости не является существенным фактором, то, как уже было сказано выше, целесообразно использовать критерий, основанный на FRiS функциях. Далее мы будем рассматривать только этот вариант задачи SDX.
На каждом шаге дробиться будет та висячая вершина, разбиение которой обеспечивает максимальное увеличение значения критерия QF, вычисляемого по формуле (5.4). При этом для каждой висячей вершины создаваемого дерева на объектах, попавших в нее, реально приходится решать задачу (5.6), которая отыскивает приближенные решения задачи (5.5).
5.4. Экспериментальная проверка
Алгоритм, реализованный в соответствии с методикой, предложенной для построения иерархического решения задачи SDX был применен для анализа следующей выборки. Для образцов различных горных пород были замерены их спектральные портреты. Каждый спектр представлял собой 1024-мерный вектор. При этом спектры 160 образцов обучающей выборки были разделены экспертами по химическому составу на 7 групп. Эффективность алгоритма оценивалась через величину однородности полученных таксонов с точки зрения химического состава объектов, попавших в них. Подчеркнем, что знания о химическом составе не участвовали в процессе решения задачи SDX, а использовались только для оценки получаемых результатов.
Алгоритм дробил каждую вершину этого дерева на два класса, описываемых двумя столпами. Информативное подпространство, в котором производилось разбиении, не должно было содержать больше шести спектральных полос. Дерево, полученное в результате работы алгоритма с заданными ограничениями, изображено на Рис. 5.3. Оно последовательно отделило 4 класса химических веществ друг от друга, слив три других в один класс. Более подробный анализ показал, что вещества, попавшие в один класс, имеют практически идентичный состав и количество примесей в них, минимально и фактически не проявляется в спектральных портретах.
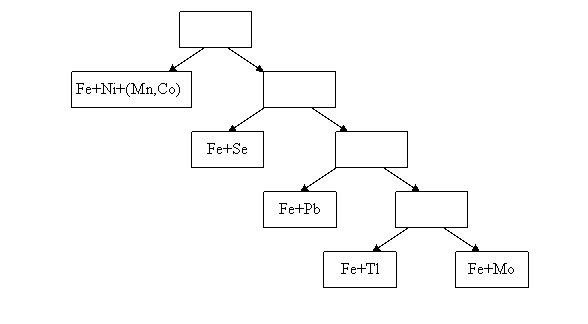

Рис. 5.3. Разбиение набора спектров образцов на 5 классов максимально сохранило однородность этих классов по химическому составу.
Выводы по пятой главе
1.Задача SDX (одновременного выбора наилучшего разбиения множества объектов на классы, решающего правила для их распознавания и наиболее информативного подпространства признаков) может рассматриваться как задача систематизации и структуризации информации в самом общем виде [76].
2. Формулировка этой задачи в терминах FRiS-функций позволяет использовать для ее решения все основные наработки, полученные в данной работе, и предложить эффективный алгоритм для построения иерархической классификации с одновременным выбором решающего правила и пространства наиболее информативных признаков.
Заключение
Разработка методов решения задач распознавания образов комбинированного типа является актуальным направлением исследований. Сами задачи такого вида лучше согласуются с общими механизмами анализа информации, используемыми человеком. Объясняется это тем, что в силу особенностей восприятия человеческий мозг обычно решает несколько базовых задач по систематизации и структуризации новых данных одновременно и согласованно. Таким образом, рассматривая возникающие прикладные задачи анализа данных как задачи комбинированного типа, мы можем имитировать действия человека-эксперта и в некоторых случаях заменять его. Кроме того, комбинированный подход позволяет минимизировать число дополнительных предположений относительно анализируемой выборки, а получаемые решения оказываются более устойчивыми к ошибкам и выбросам в исходных данных. В связи с этим особенно полезным комбинированный подход оказывается при решении задач Data Mining в условиях, которые не позволяют применить методы классической статистики. Ярким примером являются задачи, в которых число объектов M меньше числа описывающих их характеристик N и, кроме того, априорная информация о распределениях объектов, о зависимостях между объектами и между признаками отсутствует.
Наиболее общей задачей комбинированного типа, интересующей нас в данном исследовании, является задача SDX, когда одновременно решается задача таксономии (S), построения решающего правила для ее описания (D) и выбора информативного пространства признаков (X). Для корректного решения этой сложной задачи необходимо уметь решать все три основные задачи распознавания образов согласовано.
Единым базисом для решения всех задач распознавания образов в данной работе является функция конкурентного сходства. Именно использование этой функции, имитирующей особенности человеческого восприятия при определении меры похожести объектов и явлений, позволило нам создать ряд алгоритмов для решения более простых комбинированных задач SX, DX, SD и перейти к решению интересующей нас в первую очередь задачи SDX.
Перечислим основные результаты, полученные в данной работе:
1. В рамках анализа существующих подходов к решению задачи DX был исследован процесс возникновения «псевдоинформативных» признаков в плохо обусловленных задачах распознавания. Продемонстрировано, что критерий выбора информативной системы признаков для дальнейшего распознавания, основанный на функции конкурентного сходства (Fs), оказывается более устойчивым к эффекту «псевдоинформативности» и позволяет получать лучшие результаты, в сравнении с наиболее популярными критериями выбора признаков. Кроме того, показано, что сравнение значения меры (Fs), вычисляемой для наилучшей информативной подсистемы признаков на основе обучающей таблицы, и аналогичной величины, вычисленной на серии случайных таблиц того же размера, позволяет получить качественную оценку степени «неслучайности» выбранного подпространства признаков.
Было обнаружено, что в процессе решения задачи DX целесообразно опираться не на все объекты выборки, а лишь на некоторый набор эталонных образцов (столпов). Среднее значение функции конкурентного сходства, вычисленное с опорой на набор столпов, является наиболее эффективным критерием выбора информативной для распознавания системы признаков. Кроме того, величина функции конкурентного сходства контрольного объекта с образом, к которому он был отнесен, дает возможность сопроводить принятое решение оценкой уверенности в правильности этого решения.
2. Введение в рассмотрение «виртуального конкурента» позволило определить редуцированную функцию конкурентного сходства для неклассифицированной выборки. Предложенный алгоритм FRiS-Tax, опирающийся на редуцированную FRiS-функции, в процессе решения задачи SD позволяет строить разбиение выборки на адекватные с точки зрения человеческого восприятия кластеры и классы. При этом кластеры представляют из себя мелкие линейно разделимые группы объектов, имеющие простую форму, которые, объединяясь, образуют более сложные структуры «классы» произвольной формы. Использование среднего значения FRiS-функции для оценки качества таксономии позволило автоматизировать процесс выбора оптимального числа кластеров и классов в создаваемой таксономии.
3. При анализе наиболее удачных «естественных» классификаций было обнаружено, что ключевым их свойством является высокая предсказательная способность. Формализация этого понятия, а также рассмотрение задачи автоматического построения классификации, обладающей свойствами «естественной», как задачи комбинированного типа SX, позволила сформировать новый критерий качества для построения таксономии с одновременным выбором системы существенных признаков. Для ее решения был разработан алгоритм NatClass, который позволяет строить таксономии, обладающие свойствами «естественных», в виде иерархического дерева.
4. Задача SDX рассматривалась как задача представления данных в сжатом виде, удобном для дальнейшего анализа и использования человеком, который в силу особенностей своего восприятия предпочитает иметь дело с небольшим числом групп объектов, описанным в небольшом информативном подпространстве исходных признаков. Подобное сокращенное описание должно содержать систему простых правил, в соответствии с которыми каждый новый анализируемый объект может быть отнесен к той или иной группе. Кроме того, сокращенное описание выборки должно удовлетворять требованию «естественности», то есть содержать систему простых правил, по которым для нового объекта значения признаков, не вошедших в число информативных, должны восстанавливаться по значениям его информативных признаков и по общим характеристикам группы, к которой относится этот объект.
Формулировка задачи SDX в терминах FRiS-функций позволяет использовать для ее решения все основные наработки, полученные в данной работе, и предложить эффективный алгоритм FRiS-SDX для построения иерархической классификации с одновременным выбором решающего правила и отысканием пространства наиболее информативных признаков.
5. Все предложенные в работе алгоритмы проверялись как на различных модельных задачах, так и на реальных данных. Такая проверка подтвердила их применимость и эффективность в процессе решения задач распознавания образов комбинированного типа. Кроме того, большая часть описанных здесь алгоритмов вошла в пакет программ «Спектран» для интеллектуального анализа спектральных характеристик химических веществ, созданного по заказу Института Криминалистики ФСБ. Данная разработка получила высокую оценку заказчика.
Список литературы
1. Айвазян, статистика: Классификация и снижение размерности / , , . - Москва: Финансы и статистика, 1989. – 607 с.
2. Айвазян, статистика: Основы моделирования и первичная обработка данных / , , . - Москва: Финансы и статистика, 1983. – 471 с.
3. Аркадьев, машины классификации объектов / , . - Москва: Наука, 1971. – 192 с.
4. Боровков, статистика / . - Новосибирск: Наука, 1997. – 772 с.
5. Вапник, и программы восстановления зависимостей / , , ; Под редакцией . – М.: Наука, Главная редакция физико-математической литературы, 1984. – 816 с.
6. Вапник, распознавания образов / , . - Москва: Наука, 1974. – 415 с.
7. Витяев, знаний из данных. Компьютерное познание. Модели когнитивных процессов / . - Новосибирск: Издательство НГУ, 2006. – 293 с.
8. Воронин в теорию классификаций / . - Новосибирск, 1982. – 194 с.
9. Горелик, состояние проблемы распознавания / , , . - Москва: Радио и связь, 1985. – 160 с.
10. Дуда, Р. Распознавание образов и анализ сцен / Р. Дуда, П. Харт. - Москва: Мир, 1976. – 511 с.
11. Ёлкина, критерии качества таксономии и их использование в процессе принятия решений / , // Вычислительные системы. - Новосибирск, 1969. - Вып.36. - С. 29-46.
12. Жук, в кластер анализе многомерных наблюдений / , . - Минск: Белгосуниверситет, 1998. – 240 с.
13. Журавлев, : Математические методы. Программная система. Практические применения / , , . - Москва: Фазис, 2006. – 176 с.
14. Забродин, В. Н. О критериях естественности классификаций / // - НТИ, сер.2, 1981. - №8. - С. 92-112.
15. Загоруйко, методы анализа данных и знаний / . - Новосибирск: , 1999. – 270 с.
16. Загоруйко, распознавания и их применение / . - Москва: Сов. Радио, 1972. – 208 с.
17. Ивахненко, принципа самоорганизации для объективной кластеризации изображений, системного анализа и долгосрочного прогноза / // Автоматика№1. С. 5-11.
18. Колмогоров, А. Н. “К вопросу о пригодности найденных статистическим путем формул прогноза”/ // Заводская лаборатория№1. - С. 164-167.
19. Котюков, решающих правил / // Вычислительные системы. - Новосибирск, 1971. - Вып.44. - С. 37-48.
20. Красилов, проблемы теории эволюции / . - Владивосток: Изд-во ДВГУ, 1986. – 138 с.
21. Лапко, системы обработки информации / , . - Москва: Наука, 2000. – 352 с.
22. Лбов, дерева разбиений в задаче группировки объектов с использованием логических функций / , // Анализ данных в экспертных системах: Вычислительные системы. - Новосибирск, 1986. - Вып. 117. С. 63-77.
23. Лбов, решающие функции и вопросы статистической устойчивости решений / , . - Новосибирск: , 19с.
24. Мазуров, комитетов в распознавании образов / // Метод комитетов в распознавании образов. - Свердловск: Изд. УО АН СССР, 1974. – С. 10-40.
25. Миленький, А. В. “Классификация сигналов в условиях неопределенности / . - Москва: Советское радио, 1975. – 328 с.
26. Раудис, Ш. Ю. Об определении объема обучающей выборки линейного классификатора / // Вычислительные системы. - Новосибирск, 1967. - Вып.28. – С. 79-88.
27. Себестиан, принятия решений при распознавании образов/ . - Киев: Техника, 1965. – 151 с.
28. Смирнов, анализ / . – Москва: МГУ, 1969. – 352 с.
29. Ту, Д. Принципы распознавания образов / Дж. Ту, Р. Гонсалес. - Москва: Мир, 1978. – 411 с.
30. Фу, К. Последовательные методы в распознавании образов и обучении машин / К. Фу. - Москва: Наука, 1971. – 256 с.
31. Введение в статистическую теорию распознавания образов / К. Фукунага. - Москва: Наука, 1979. – 367 с.
32. Шлезингер, М. Десять лекций по статистическому и структурному распознаванию /М. Шлезингер, В. Главач. - Киев: Наукова Думка, 2004. – 548 с.
33. Шлезингер, М. И. О самопроизвольном разделении образов / // Читающие автоматы и распознавание образов: cб. науч. трудов – Киев: Наукова думка, 1965. - С. 46-61.
34. Battiti, R. Using Mutual Information for Selecting Features in Supervised Neural Net Learning / Battiti R. // IEEE Trans. Neural Networksvol. 5, no. 4. - P. 537-550.
35. Boser, E. A training algorithm for optimal margin classifiers / E. Boser, I. M. Guyon, V. N. Vapnik // 5th Annual ACM Workshop on COLT. - Pittsburgh, 1992. - P. 144-152.
36. Dempster, A. Maximum likelihood from incomplete data via the EM algorithm / A. Dempster, N. Laird, *****bin // Journal of the Royal Statistical Society, Series B. – 1977. - Vol. 39(1). - P. 1–38.
37. Dy, J. G. Feature Subset Selection and Order Identification for Unsupervised Learning / J. G. Dy, C. E. Brodley // Proc. 17th Int’l Conf. Machine Learning. – 2000. - P. 247-254.
38. Everitt, B. S. Cluster analysis. Third edition. / B. Everitt. - London: Edvard Arnold, 1993. – 170 pp.
39. Fukunaga, K. A criterion and an algorithm for grooping data / K. Fukunaga, W. L.G. Koontz // IEEE p., C-19. – 1970. - P. 917-923.
40. Gennari, J. H. Models of incremental concept formation / J. H. Gennari, P. Langeley, D. Fisher // Artificial Intelligence 40. – 1989. - P.
41. John, G. Irrelevant features and the subset selection problem / G. John, R. Kohavi, K. Pfleger // Machine Learning: Proc. Of the 11-th Int. Conf. - Morgan Kaufmann, 1994. - P.121-129.
42. Kim, Y. Feature Selection in Unsupervised Learning via Evolutionary Search / Y. Kim, W. Street, F. Menczer // Proc. Sixth ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining. -2000. - P. 365-369.
43. Kira, K. The Feature Selection Problem: Traditional Methods and a New Algorithm / K. Kira, L. Rendell // Proc. 10th Nat’l Conf. Artificial Intelligence (AAAI-92). – 1992. - P. 129-134.
44. Kohavi, R. Wrappers for Feature Subset Selection / R. Kohavi, G. H. John // Artificial Intelligence. – 1997. - vol. 97, nos. 1-2. - P. 273-324.
45. Kwak, N. Input Feature Selection by MutualInformation Based on Parzen Window / N. Kwak, C.-H. Choi // IEEE Trans. Pattern Analysis and Machine Intelligence. – 2002. - vol. 24, no. 12. - P. .
46. Law, M. H.C. Simultaneous Feature Selectio and Clustering Using Mixture Models / M. H.C. Law, M. A.T. Figueiredo, A. K. Jain // IEEE Trans. Pattern Analysis and Machine Intelligence. – 2004. - vol. 26, no. 9. - P. 1-13.
47. MacQueen J. “Some methods for classification and analysis of multivariate observations / J. MacQueen // Proceedings of the 5th Berkley Symposium on Mathematical Statistic and Probability. - University of California Press, 1967. - Vol.1. - P. 281-297.
48. Merill, T. On the effectiveness of receptors in recognition systems / T. Merill, O. M. Green // IEEE Trans. Inform. TheoryVol. IT-9. - P.11-17.
49. Michalski, R. S. Machine Learning and Data Mining, Methods and Applications / R. S. Michalski, I. Bratko, M. Kubat. - N. Y.: John Wiley & Sons, 1998. – 472 pp.
50. Mitra, P. Unsupervised Feature Selection Using Feature Similarity / P. Mitra, C. A. Murthy // IEEE Trans. Pattern Analysis and Machine Intelligence. – 2002. - Vol. 24, No. 3. - P. 301-312.
51. Niemann, H. Pattern analysis and understanding / H. Niemann. - Springer-Verlag, 19pp.
52. Pawalk, Z. Rough sets: preset state and the future / Z. Pawalk // Foundations of Computing and Decision Sciences. – 1993. – Vol. 18(3-4). - P. 157-166.
53. Robnik-Sikonja, M. Theoretical and Empirical Analysis of ReliefF and RReliefF / M. Robnik-Sikonja, I. Kononenko // Machine Learning. – 2003. - Vol. 53. – P. 23-69.
54. Sahami, M. Using Machine Learning to Improve Information Access / M. Sahami // PhD thesis, Computer Science Dept., Stanford Univ– 240 p.
55. Siedlecki, W. “On automatic feature selection / W. Siedlecki, J. Sklansky // Int. Journal of Patt. Rec. and Art. Intel. – 1988. – VolP. 179-220.
56. Siedlecki, W. A note on genetic algorithms for large-scale feature selection”/ W. Siedlecki, J. Sklansky // Pattern Recognition Letters. – 1989. - Vol.10. - P. 335-347.
57. Thrun, S. B. The Monk’s problems: A performance comparison of different learning algorithms / S. B. Thrun et al. // Technical Report CMU-CS-91-97. - Carnegie Mellon University, 1991. – 112 pp.
58. Watanabe, M. S. Knowing and Guessing: Formal and Qualitative Study/ M. S. Watanabe. - N. Y.: John Wiley, 19pp.
59. Xu, L. Best first strategy for feature selection / L. Xu, P. Yan, T. Chang // 9-Int. Conf. on Patt. Rec. - IEEE Comp. Society Press, 1989. - P. 706-708.
60. Борисова, классификация / , // Интеллектуальный анализ информации. Сборник трудов российско-украинского научного семинара, Киев, 19-21 мая 2004 г. – Киев: Просвiта, 2004. – С.
61. Zagoruiko, N. G. Principles of natural classification / N. G. Zagoruiko, I. A. Borisova // Pattern Recognition and Image Analysis. - Germany: Springer Verlag GmbH, 2005. - vol 15, №1. - P[Принципы естественной классификации]
62. Borisova, I. A. Algorithms of Natural Classification and Systematization / I. A. Borisova, A. N. Zagoruiko, N. G. Zagoruiko // Pattern Recognition and Information Processing. Proceedings of the 8-th International Conference, Minsk, 18-20 May 2005. – Minsk, 2005. - P. [Алгоритмы естественной классификации и систематизации]
63. Alves, A. Predictive Analysis of Gene Data from Human SAGE Libraries / A. Alves, N. Zagoruiko, O. Okun, O. Kutnenko and I. Borisova // Procceedings of the Workshop W10 “Discovery Challenge” ECML/PKDD, Portugal, 3-7 October 2005. – Porto, 2005. - P.[Предсказывающий анализ генетических данных из библиотек Human SAGE]
64. Загоруйко, информативного подпространства признаков (Алгоритм GRAD) / , O. A. Кутненко, // Математические методы распознавания образов. Доклады 12-ой Всероссийской конференции, Москва, 2005. - Москва, 2005. - С. 106-109.
65. Борисова, траекторий и восстановление структуры генных сетей / , , // Анализ структурных закономерностей. Вычислительные системы. - Новосибирск, 2005 г. - выпуск 174. - С. 54-64.
66. Zagoruiko, N. G. Selection of informative subset of gene expression profiles in prognostic analysis of type 2 diabetes / N. G. Zagoruiko, O. A. Kutnenko, I. A. Borisova, A. N. Kiselev, A. A. Ptitsin // Proceedings of the 5-th International Conference on Bioinformatics of Genome Regulation and Structure, Novosibirsk, July 2006. - Novosibirsk, 2006. – Volume 1. - P. [Выбор информативных профилей активности генов в прогнозировании диабета второго типа]
67. Загоруйко, выбора подсистем информативных признаков / , , // Применение многомерного статистического анализа в экономике и оценке качества. Труды VIII Межд. Конференции. - Москва, 2006. - C. 90-91.
68. Zagoruiko, N. G. Criteria of informativeness and suitability of a subset of attributes, based on the similarity function / N. G. Zagoruiko, I. A. Borisova, O. A. Kutnenko // Pattern Recognition and Information Processing. Proceedings of the 9-th International Conference, Minsk, 22-24 May 2007. – Minsk, 2007. - P. 257-261. [Критерий информативности и пригодности подмножества признаков, основанный на функции сходства]
69. Борисова, И. А Критерий информативности и пригодности подмножества признаков / , , // Knowledge-Dialog-Solution. Proceedings of the 13-th International Conference, Varna, 18-25 June 2007. – Sofia, 2007. - P.
70. Борисова, FRiS-функции для построения решающего правила и выбора признаков(задача комбинированного типа DX) / , , // Знания. Онтологии. Теории. Материалы Всероссийской Конференции, Новосибирск, 2007. – Новосибирск, 2007. - том 1. - С. 37-44.
71. Борисова, конкурентного сходства в задаче таксономии / , // Знания. Онтологии. Теории. Материалы Всероссийской Конференции, Новосибирск, 2007. – Новосибирск, 2007. - том 2. - С. 67-76.
72. Zagoruiko, N. G. Function of rival similarity in pattern recognition / N. G. Zagoruiko, I. A. Borisova, V. V. Dubanov, O. A. Kutnenko // Proceedings of the Eighth International Conference Pattern Recognition and Image Analysis, Yoshkar-Ola, 8-12 October 2007. - Yoshkar-Ola, 2007. – Vol. 2. - P. 63-66. [Функция конкурентного сходства в распознавании образов]
73. Загоруйко, поиска ближайшего аналога в большой базе изображений / , , // Математические методы распознавания образов. Доклады 13-й Всероссийской конференции, Москва, 2007. - Москва, 2007. - С. 131-134.
74. Борисова, таксономии FRiS-Tax / // Научный вестник НГТУ – Новосибирск : Изд-во НГТУ, 2007. - №3. - С. 3-12.
75. Борисова, информативности и пригодности подмножества признаков, основанные на функции сходства / , , // Заводская лаборатория. Диагностика материалов. - Москва, 2008. - №1, том 74. - С. 68-71.
76. Борисова, комбинированного типа в интеллектуальном анализе данных”/ , // Сборник научных трудов научной сессии МИФИ-2008. - Москва, 2008. - том 10. - C. 209-210.
77. Zagoruiko, N. G. Methods of recognition based on the function of rival similarity / N. G. Zagoruiko, I. A. Borisova, V. V. Dyubanov, O. A. Kutnenko // Pattern Recognition and Image Analysis. - Germany: Springer Verlag GmbH, 2008. – Vol.18, №.1. - P. 1-6. [Методы распознавания, основанные на функции конкурентного сходства]

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
