

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Институт математики им. СО РАН
На правах рукописи
МЕТОДЫ РЕШЕНИЯ ЗАДАЧ РАСПОЗАНАВАНИЯ ОБРАЗОВ КОМБИНИРОВАННОГО ТИПА
Специальность 05.13.17 – Теоретические основы информатики
Диссертация на соискание ученой степени кандидата технических наук
Научный руководитель:
д. т.н., проф.
Новосибирск 2008
Содержание
Введение……………………………………………………………………………..5
Глава 1. Формулировка задач распознавания образов основного и комбинированного типов с кратким обзором существующих подходов к их решению…………………………………………………………………………....13
1.1. Задачи распознавания образов основных типов……………………………..13
1.1.1. Формулировка задачи построения решающего правила………………13
1.1.2. Формулировка задачи таксономии……………………………………...17
1.1.3. Формулировка задачи выбора системы информативных признаков…20
1.2. Задачи распознавания образов комбинированного типа……………………23
1.2.1. Построение решающего правила + выбор признаков (DX)…………...23
1.2.2. Таксономия+выбор признаков (SX)…………………………………….26
1.2.3. Таксономия+построение решающего правила (SD)…………………...28
1.2.4. Таксономия+распознавание+выбор признаков (SDX)………………...29
Выводы по первой главе…………………………………………………...……....31
Глава 2. Функция конкурентного сходства в задаче DX…………………….33
2.1. Функция конкурентного сходства……………………………………………34
2.2. Реальная и случайная информативность в задаче DX………………………36
2.2.1. Эффект «псевдоинформативности» в задаче DX………………………37
2.2.2. Сравнение критериев информативности………………………………..41
2.2.3. Оценка «неслучайности» выбранных подсистем………………………45
2.2.4. Проверка на реальных данных…………………………………………..48
2.3. Целесообразность и эффективность применения аппарата FRiS-функций
в задаче DX………………………………………………………………………….49
2.3.1 Построение решающего правила алгоритмом FRiS-Stolp……………...50
2.3.2. Оценка надежности распознавания конкретных объектов……………54
2.3.3. Алгоритм FRiS-Agent в задаче DX ………………………………….….59
Выводы по второй главе…………………………………………………………...62
Глава 3. Использование функций конкурентного сходства при решении задачи SD…………………………………………………………………………...64
3.1. Редуцированная функция конкурентного сходства…………………………64
3.2. Алгоритм FRiS-Tax …………………………………………………………...67
3.2.1 Кластеризация (этап FRiS-Cluster)……………………………………….67
3.2.2. Построение классификации (этап FRiS-Class)…………………………70
3.2.3. Выбор оптимального числа таксонов…………………………………...71
3.3. Примеры работы алгоритма…………………………………………………..72
3.4. Экспериментальная проверка алгоритма FRiS-Tax, сравнение с существующими аналогами……………………………………………………….75
Выводы по третьей главе…………………………………………………………..80
Глава 4. Задача «естественной» классификации и ее связь с задачей комбинированного типа SX……………………………………………………...81
4.1. Дискуссионная природа термина «естественная классификация»………...81
4.2. Специфические свойства «естественных» классификаций…………………83
4.3. Формулировка задачи построения «естественной» классификации
в терминах задач комбинированного типа………………………………………..85
4.3.1 Критерий качества в задаче « естественной классификации»…………86
4.3.2 Алгоритм NatClass………………………………………………………..89
4.4. Иерархическая таксономия…………………………………………………...89
4.4.1. Иерархический NatClass…………………………………………………89
4.4.2. Другие возможные подходы к построению
иерархической естественной классификации………………………………..91
4.5. Экспериментальная проверка эффективности алгоритма NatClass……….92
4.6. Связь FRiS-функции и предсказательной способности таксономии………95
Выводы по четвертой главе……………………………………………………….96
Глава 5. Использование FRiS функции для решения задачи SDX………...98
5.1. Формальная постановка задачи SDX……………………………………….100
5.1.1. Формулировка задачи SDX в терминах FRiS-функций………………101
5.2. Алгоритм отыскания решения задачи SDX………………………………...102
5.3.Иерархическая классификация ………………………………………………104
5.3.1. Алгоритм решения иерархической задачи SDX………………………107
5.4. Экспериментальная проверка………………………………………………..107
Выводы по пятой главе…………………………………………………………...108
Заключение………………………………………………………..……………...110
Список литературы…………………………….………………………………..114
Введение
Человек обладает врожденной способностью к обработке информации, ее систематизации, обобщению, упрощению. Эта способность с древнейших времен интересовала исследователей, которые пытались понять ее механизмы. Процесс изучения способности человека производить знания продолжается до сих пор, по сути, он бесконечен. Долгое время им интересовались в основном философы, затем к ним подключились биологи, физиологи, психологи. С появлением компьютеров решение этих вопросов стало уже делом не только удовлетворения некоторого абстрактного научного любопытства. Теперь изучение и формализация человеческой способности к анализу информации, к познанию мира дает возможность частично наделять этой способностью искусственные объекты – компьютеры.
Даже самые примитивные модели анализа данных, реализованные в виде алгоритмов и компьютерных программ, позволяют достигать значительных результатов в процессе обработки информации. Машина не просто выполняет некоторые рутинные операции, освобождая человека для творческих занятий. Использование этих моделей позволяет с помощью машин решать задачи, ранее недоступные человеку из-за своей громоздкости и трудоемкости. Это становится особо актуально в последнее время, когда накопление информации в различных прикладных областях идет с огромной скоростью и ее обработка в принципе невозможна без помощи компьютера.
Одним из наиболее важных этапов обработки информации нам представляется ее систематизация и упрощение – представление в виде, доступном для понимания, более подробного исследования и дальнейшего использования. Человеком для этого используются различные приемы, многие из которых формализованы в рамках предметной области, называемой интеллектуальным анализом данных (ИАД), и относятся к задачам распознавания образов.
Упоминание о первом из них – группировке встречается еще у Демокрита в «Письме к ученому соседу». Он пишет: «Если тебе, мой друг, нужно разобраться в сложном нагромождении фактов или вещей, ты сначала разложи их на небольшое число куч по похожести. Картина прояснится, и ты поймешь природу этих вещей». Этот способ познания - создание классификационных структур на множестве объектов схожей природы широко используется наукой и в наши дни. Его формализация и развитие делается в рамках научного направления, которое называется большим количеством синонимов: таксономия, группировка, кластерный анализ, автоматическая классификация, обучение без учителя, самообучение и т. д. В задаче таксономии упрощение информации происходит за счет сокращения числа рассматриваемых объектов. Вместо изучения каждого отдельного представителя выборки появляется возможность сосредоточить внимание на изучении классов сходных объектов. Похожесть в рамках класса позволяет заменять множества объектов из этого класса неким эталонным (идеальным) образцом.
Этой задачей занимались такие известные российские и зарубежные ученые как , , С, и другие. Далее мы будем обозначать задачу таксономии символом S.
Если разбиение на классы задано непосредственно в исходных данных, то для дальнейшей работы обычно требуется построить некоторую обобщающую систему описаний этих классов, позволяющую отличать их друг от друга и отвечать на вопрос, к какому классу принадлежит новый объект. Эта задача в различных источниках называется задачей распознавания, задачей построения решающего правила, обучением с учителем, задачей классификации. В ней упрощение информации происходит за счет упрощения описания классов. Действительно, исходное описание класса в виде прямого перечисления всех объектов, попавших в него, заменяется описанием в виде обобщающего правила (логического решающего правила, линейной разделяющей границы и т. п.). Построение описаний уже существующих классов в виде решающих правил той или иной степени сложности, позволяет более четко представить структуру этих классов, их однородность.
Исследованиям задачи построения решающего правило посвящено огромное количество работ. Значительный вклад в развитие этой области внесли , , Н, Я, Д, Симон, Фу К., и многие другие исследователи. Задачу построения решающего правила далее мы будем обозначать символом D.
В процессе интеллектуального анализа информации объект обычно рассматривается как некая система признаков. Часть из них поступает человеку через его рецепторы (зрение, слух, осязание), часть проявляет себя во взаимодействии с другими объектами (измеряется приборами), часть может быть выведена (объем предмета через длины его сторон). От правильного выбора системы учитываемых свойств в общем случае зависит простота и эффективность оперирования с объектом. Таким образом, третьим способом упрощения исследуемого множества объектов является сокращение числа используемых в их описании признаков. Производиться оно может как за счет исключения слабых, неинформативных, несущественных, случайных, шумящих признаков, так и за счет выделения такой системы информативных, существенных признаков, по которой можно восстановить все остальные неслучайные признаки с достаточной степенью точности.
Методики выбора информативной системы признаков активно разрабатывались в рамках ИАД такими исследователями как , Барабашом, Мерилом, Грином и рядом других. Далее эту задачу мы будем обозначать символом X.
Все описанные выше методы упрощения информации и соответствующие им задачи распознавания образов могут использоваться по отдельности. Однако самая совершенная система анализа информации – человеческий мозг – обычно решает их одновременно. То есть выбор системы информативных признаков, построение некоторой классификации объектов и решающего правила для различения созданных классов происходит параллельно и взаимосвязано. Аналогом реализации такого комплексного подхода в ИАД является задача комбинированного типа SDX [16].
Объект исследований. Задача SDX считается сложной и общего подхода к ее решению не существует. Прежде чем приступить к решению этой задачи, мы рассмотрим более простые задач комбинированного типа SX, DX, SD, в каждой из которых одновременно используются два из трех описанных выше приема упрощения информации [16]. Это позволит нам создать необходимый фундамент для решения задачи SDX непосредственно. Именно задачи распознавания образов комбинированного типа являются основными объектами исследования в данной работе. Комбинированные задачи хорошо согласуются с механизмами анализа информации, используемыми человеком, и открывают новые возможности для решения сложных плохо обусловленных прикладных задач.
Цель работы. В отличии от задач основных типов, алгоритмов и методов решения задач комбинированного типа имеется относительно немного, по большей части они разработаны для частных случаев и оказываются эффективными лишь при выполнении ряда дополнительных требований к исходным данным. В связи с этим целью данной работы является разработка системы согласованных и универсальных алгоритмов для решения задач комбинированного типа.
Основные направления исследований. Требование согласованности алгоритмов здесь оказывается очень важным. Для его выполнения необходимо иметь единый базис для решения всех задач. В этой работе таким базисом стали функции конкурентного сходства (FRiS-функции) [68]. Выбор функций конкурентного сходства в качестве основы для большинства представленных алгоритмов решения задач комбинированного типа объясняется еще и тем, что основным методом исследования для нас является моделирование интеллектуальной деятельности человека при решении комбинированных задач. FRiS-функция оказывается при этом особенно эффективной, так как она моделирует психофизиологические особенности человеческого восприятия при оценке близости между объектами.
Методы исследований Помимо имитационного моделирования для решения задач распознавания образов комбинированного типа привлекается аппарат методов оптимизации и математическая статистика.
Научная новизна исследования состоит в том, что к решению задач комбинированного типа привлекается принципиально новый подход, основанный на функциях конкурентного сходства. А универсальность и эффективность алгоритмов, полученных в рамках данного исследования, обеспечивают его практическую значимость.
Именно задачам комбинированного типа, их связям с естественно-человеческой методологией познания, методам решения этих задач, анализу возможностей алгоритмов комбинированного типа, и областям их применения посвящена данная диссертация.
На защиту выносятся следующие основные результаты:
· В рамках исследования применимости FRiS-функций показана их эффективность в качестве критерия информативности при решении задачи одновременного построения решающего правила и выбора наиболее информативного подпространства признаков. Предложена методика оценки надежности получаемых информативных систем признаков, их «неслучайности». Также предложена методика оценки надежности распознавания каждого нового объекта при использовании решающих правил, полученных с помощью алгоритма FRiS-Stolp.
· Разработан алгоритм FRiS-Tax для решения задачи комбинированного типа – одновременного построения таксономии и решающего правила, ее описывающего. Этот алгоритм не только достаточно точно воспроизводит действия человека эксперта при решении задач таксономии в пространствах малых размерностей, но и позволяет автоматически определять оптимальное число таксонов из заданного диапазона.
· Сформулированы основные требования, предъявляемые к «естественным» классификациям. Установлена связь между задачей построения «естественной» классификации и одной из задач распознавания образов комбинированного типа – задачей построения таксономии с одновременным выбором наиболее информативного подпространства признаков. Для решения данной задачи разработан алгоритм NatClass.
· Сформулирована наиболее сложная задача распознавания образов комбинированного типа - SDX – задача одновременного построения таксономии и решающего правила для ее описания в наиболее информативном признаковом пространстве. Предложена методика ее решения, позволяющая максимально структурировать массивы данных в случае отсутствия какой бы то ни было дополнительной информации относительно природы этих данных.
· Все алгоритмы, описанные в диссертации, опробованы на модельных и реальных прикладных задачах, проведено сравнение их эффективности с существующими в настоящее время аналогами. Большая часть разработок включена в пакет сервисных программ, автоматизирующих работу человека эксперта при анализе спектров образцов различных материалов для целей криминалистики.
Достоверность и обоснованность предлагаемых решений подтверждается результатами применения предложенных алгоритмов как к модельным, так и к реальным задачам различной природы.
Практическая ценность работы состоит в том, что практика использования разработанных алгоритмов для задач с плохо обусловленными данными показывает их более высокую эффективность по сравнению с существующими аналогами. Кроме того предложенные алгоритмы позволяют имитировать действия человека при анализе информации. Большая часть разработок включена в пакет сервисных программ, автоматизирующих работу эксперта при анализе спектров образцов мелкодисперсных материалов созданный по заказу института криминалистики.
Апробация работы. Основные результаты, представленные в данной работе, были доложены на следующих международных и всероссийских конференциях и форумах:
· KDS-2001, 2007 (Knowledge-Dialog-Solutions),
· PRIA-2004, 2007 (Pattern Recognition and Image Analysis),
· PRIP-2005, 2007 (Pattern Recognition and Image Processing),
· ММРО-12, 13 (Математические Методы Распознавания Образов),
· ACIT-SE-2005 (Automation, Control and Information Technology),
· BGRS-2006 (Bioinformatics of Genome Regulation and Structure),
· ЗОНТ-2007 (Знания, Онтологии, Теории).
Отдельные этапы работы прошли экспертизу в ходе выполнения проектов, поддержанных грантами РФФИ (проекты № -а, №-а).
Публикации. По теме диссертации опубликованы 16 работ, из них 2 научные статьи в журналах, входящих в перечень изданий, рекомендованных ВАК РФ, 2 научные статьи в ведущих рецензируемых журналах, 2 – в сборниках научных трудов, 10 – в сборниках трудов конференций.
Структура работы. Диссертационная работа изложена на 121 страницах и состоит из введения, обзора литературы (глава 1), четырех глав, содержащих основные результаты, и заключения. Иллюстративный материал представлен 24 рисунками и 1 таблицей. Список литературы включает 77 ссылок.
В главе I более четко формулируются задачи основных и комбинированных типов. Описываются основные подходы, используемые при их решении на текущий момент. Для задач комбинированного типа описываются случаи, когда их использование оправдано и желательно.
В главе II дается определение функции конкурентного сходства и анализируется ее применимость и эффективность при решении задачи DX.
Глава III посвящена использованию FRiS-функции для решения задачи SD. В ней предлагается алгоритм таксономии, успешно воспроизводящий действия человека-эксперта как при построении таксономии, так и при выборе оптимального числа таксонов в ней.
Глава IV посвящена решению задачи комбинированного типа SX. В ней, устанавливается связь между задачей SX и задачей «естественной классификации». Основываясь на принципах «естественности», формулируется критерий качества, позволяющий решать задачу автоматического построения «естественной классификации», предлагается алгоритм решения этой задачи.
В главе V результаты, полученные в предыдущих главах, обобщаются и применяются при решении основной задачи комбинированного типа - задачи SDX.
Глава 1. Формулировка задач распознавания образов основного и комбинированного типов с кратким обзором существующих подходов к их решению
1.1. Задачи распознавания образов основных типов
Исторически сложилось, что в области распознавания образов выделяются несколько основных типов задач: это задача построения решающего правила (D), задача выбора информативной системы признаков (X), задача таксономии (S).
Чтобы сформулировать эти задачи введем некоторые общие обозначения. Пусть рассматривается некоторая генеральная совокупность изучаемых объектов Г. Данное множество объектов (явлений, ситуаций) разбито на ряд подмножеств (классов, образов) Г1,…,Гt,…,Гk, где k – число образов, k>1. Под образом понимается подмножество объектов, обладающих с точки зрения исследователя некоторыми общими интересующими его свойствами. Например, в области медицинской диагностики подмножество Гt – люди, имеющие одно и то же заболевание.
Пусть каждый объект из Г описывается набором из N характеристик Х={X1,…,Xj,…,XN}, где N может меняться от одного до десятков тысяч. Если Wj – множество возможных значений признака Xj, тогда W= Wj задает многомерное пространство переменных. Произвольному объекту аÎГ может быть поставлен в соответствие вектор Х(а)=( X1(a),…,Xj(a),…,XN(a)), где Xj(a) – значение переменной Xj для объекта а. Далее для краткости Х(а) будем обозначать через х, Xj(a) – через xj.
1.1.1. Формулировка задачи построения решающего правила
Чтобы сформулировать задачу построения решающего правила для распознавания образов, нужно ввести еще одну переменную Y c множеством значений WY={1, 2, … , t, …, k}. Переменная Y является номинальной и указывает, к какому образу относится произвольный объект а. Обозначим через Y(a)=y значение переменной Y для объекта а. Тогда задача распознавания образов состоит в том, чтобы для произвольного объекта аÎГ по значениям x1,…,xj,…xN определить y.
Отображение d: W®WY назовем решающей функцией. Ей соответствует разбиение множества W на k непересекающихся подмножеств W1,…, Wt,… Wk покрывающих W, где Wt={x | d(x)=t}. Через D0 обозначим множество всевозможных отображений W®WY.
Предполагается, что объект а из генеральной совокупности Г выбирается случайным образом. Поэтому величины X1,…,Xj,…,XN являются случайными величинами. Под стратегией природы понимается совместное распределение Р(у, х) случайной величины Y и N-мерной случайной величины Х=(X1,…,Xj,…,XN), уÎWY, хÎW. В дальнейшем стратегию природы будем обозначать через f.
Оптимальной решающей функцией в случае произвольной стратегии природы f называется такая функция d0, при которой выполняется соотношение: R(d0, f)= R(d, f), где R(d, f) – риск, математическое ожидание потерь (штрафа) при использовании решающей функции d для распознавания фиксированной стратегии природы f. В частном случае, если за каждое ошибочное решение платится единичный штраф, риск определяется как вероятность ошибки распознавания P(d, f). При этом оптимальной решающей функцией является Байесовская решающая функция d*, которой соответствует следующая стратегия: при эмпирическом факте Х(а)=х объект а следует отнести к тому образу w, при котором условная вероятность Px(w)=P{Y(a)=w|X(a)=α} максимальна, то есть Px(w)=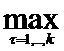 Px(t). Когда максимальное значение достигается на нескольких образах, объект а относится к любому из них. Очевидно, что, построив решающую функцию, мы тем самым решим задачу распознавания. Чем ближе построенная функция окажется к Байесовой, тем выше будет точность, с которой она определяет имя образа.
Px(t). Когда максимальное значение достигается на нескольких образах, объект а относится к любому из них. Очевидно, что, построив решающую функцию, мы тем самым решим задачу распознавания. Чем ближе построенная функция окажется к Байесовой, тем выше будет точность, с которой она определяет имя образа.
На практике стратегия природы f не известна. В этом случае для построения решающей функции используется эмпирическая информация, заданная в виде таблицы данных u={xi,yi}, i=1,…,M, xi=(x1i,…,xji,…,xNi)=X(ai), где xji=Xj(ai) – значение переменной Xj для объекта aiÎА, yi=Y(ai) – значение целевой переменной для объекта ai; А – множество объектов случайно выбранных из генеральной совокупности Г, АÌГ; M – число объектов множества А; N – размерность пространства (число переменных). Такую таблицу u будем называть обучающей выборкой, множество А – множеством объектов, данных для обучения. Заметим, что для каждого объекта aÎА известны не только значения описывающих переменных X1,…,Xj,…,XN, но и значение целевой переменной Y.
Традиционно задача распознавания образов решается в два этапа. На первом этапе строится решающее правило d (разбиение множества W на k непересекающихся подмножеств), вид которого определяется той информацией, которую мы смогли извлечь из обучающей выборки A. А на втором этапе происходит уже непосредственно сам процесс распознавания, когда решение о принадлежности любого объекта a к одному из k образов принимается на основании правила d(x).
Для удовлетворительного решения задачи построения решающего правила часто возникает необходимость в дополнительных предположениях, касающихся природы задачи. Эти предположения могут формулироваться как в виде ограничений, накладываемых на класс стратегий природы F, к которому относится f, так и в виде ограничений на класс решающих функций D, среди которых ищется d [23].
При построении решающего правила по конечной выборке А при неизвестной стратегии f, можно условно выделить два пути.
- первый основан на построении так называемых подстановочных решающих правил [12]. Суть его заключается в восстановлении совместного распределения вероятностей Р(у, х), соответствующего стратегии природы f, посредством тех или иных непараметрических методов [10], либо за счет конкретизации вида распределения с точностью до конечного числа параметров, которые затем восстанавливаются на основе обучающей выборки А. После восстановления стратегии природы f`(A), для минимизации риска R(d, f`(A)) (вероятности ошибки P(d, f`(A))) строится Байесова решающая функция на основе выборочного распределения. Этот подход достаточно хорошо разработан в рамках аппарата, предоставляемого математической статистикой для построения оценок.
- другой путь, в соответствии с которым создается основная масса эвристических алгоритмов распознавания, заключается в следующем. Вместо вероятности ошибки P(d, f) минимизируется некоторый ее аналог P`(d, A), определяемый на обучающей выборке, минуя процедуру оценки параметров стратегии природы. В качестве P` может, к примеру, использоваться вероятность ошибочной классификации по правилу d, вычисленная на обучающей выборке А. Для построения эффективных процедур поиска оптимального решающего правила и заботясь об устойчивости получаемых решений, класс решающих правил D, в котором отыскивается d*, обычно ограничивается. В результате возникает комбинаторная задача, которую из соображений удобства мы будем записывать как задачу на максимум, переходя от минимизации ошибки распознавания к максимизации надежности распознавания Qr:
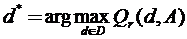 , где Qr(d,A)=1-P`(d,А). (1.1)
, где Qr(d,A)=1-P`(d,А). (1.1)
Другими словами отыскивается такое решающее правило d* из класса D (набор параметров, конкретизирующих это правило), которое обеспечит максимум функции Qr. При этом, естественно, предполагается что Qr (P`(d, A) ) и D выбираются таким образом, чтобы обеспечить максимальную возможную надежность распознавания новых объектов (контрольной выборки). Именно такой вариант постановки задачи распознавания мы и будем рассматривать в рамках данной работы как задачу распознавания.
1.1.2. Формулировка задачи таксономии
В содержательной постановке целью задачи таксономии принято считать построение такого разбиения объектов на классы, чтобы объекты одного класса были «близки» друг к другу и «удалены» от объектов других классов. Существуют два основных подхода к решению этой задачи:
- вероятностный;
- геометрический.
Вероятностный подход основан на предположении, что наблюдения из одной группы (классы) являются одинаково распределенными случайными векторами. Таким образом, мы используем ту же модель, что и при формулировке задачи построения решающих правил. В рассмотрение вводится номинальная переменная Y c множеством значений WY={1, 2, … , t, …, k} в соответствии с которой все множество объектов генеральной совокупности Г разбивается на k классов. Фиксация стратегии природы с позволяет нам перейти от рассмотрения множества объектов из Г к рассмотрению случайных событий в вероятностном пространстве, с заданным совместным распределением Р(у, х) случайной величины Y и N-мерной случайной величины Х=( X1,…,Xj,…,XN), уÎWY , хÎW. И также возникает задача минимизации риска, которая легко решается для случая, когда известны все распределения вероятностей стратегии природы. Разница заключается в том, что при переходе от генеральной совокупности объектов Г к конечному множеству объектов А, предоставленных для обучения, информация о номерах классов отсутствует даже для этих объектов. То есть обучающая выборка описывается таблицей u={xi}, i=1,…,M. Соответственно, в статистической постановке эта задача еще более сложная, чем задача распознавания, так как требуется восстановить не только параметры стратегии природы с, но еще и значения целевого признака Y для обучающей выборки. Однако даже в этом случае может быть использован подход, основанный на построении подстановочных решающих правил, который в задаче таксономии называется прямым методом самообучения [25]. По неклассифицированной выборке строятся оценки P/(x,y), например оценки максимального правдоподобия, которые затем и используются в решающем правиле для классификации выборки А. Более типичными, однако, считаются методы самообучения с обратной связью, в итеративном процессе уточняющие как параметры стратегии природы, так и номера классов обучающей выборки.
При геометрический подходе объекты воспринимаются как точки в пространстве наблюдений, которые необходимо разбить на компактные группы таким образом, чтобы в одной группе оказались объекты «похожие» друг на друга и «непохожие» на объекты из других групп. Более строго задача таксономии формулируется следующим образом. Имеется некоторая совокупность исследуемых объектов A мощности M в пространстве размерности N. Ей в соответствие ставится таблица данных u={xi} размера M´N. Разбиение множества объектов А на k групп обозначим через с={А1,…,Аk}, сÎС, где С – множество всех таких разбиений. Мощность этого множества равна B(M,k) – числу Стирлинга 2-го рода. Для произвольного разбиения можно оценить его качество с помощью некоторого критерия Qt=Qt(с,A), который зависит от того, что в той или иной задаче мы понимаем под компактностью и какую меру близости r(x,y) между объектами мы используем [28, 29]. Одним из наиболее популярных критериев качества таксономии является критерий, используемый в алгоритме k-Means [33, 47]. В этом алгоритме компактность таксонов оценивается через похожесть объектов на центр таксона, в который они попали. Вычисляется он по следующей формуле:
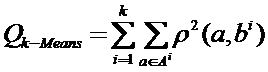 ,
,
где bi – центр таксона Ai. В данном случае, чем больше значение критерия, тем меньше объекты, попавшие в таксон, похожи на его центр и, соответственно, тем ниже качество таксономии. Для отыскания оптимального решения в данном случае необходимо решать экстремальную задачу на минимум. Однако в общем виде мы, без ограничения общности можем считать задачу таксономии задачей на максимум, в которой для получения наилучшего разбиения с* необходимо решить следующую экстремальную задачу:
![]() . (1.2)
. (1.2)
В дальнейшем под задачей таксономии мы будем понимать именно ее геометрическую интерпретацию. В ней существенным является как формулировка оптимизируемого критерия качества, обеспечивающего компактность получаемых таксонов, так и построение эффективного алгоритма, позволяющего отыскать оптимальное или близкое к оптимальному решение для предложенного критерия Qt.
В [8] приводятся следующие формальные показатели, призванные оценивать качество построенного разбиения:
- эмпирическая обоснованность – показывает, насколько имеющийся эмпирический материал представителен с точки зрения построенного разбиения;
- предсказательная сила – соответствие полученной классификации некоторой идеальной абстрактной классификации, построенной на всей генеральной совокупности;
- диагностическая сила – эффективность использования этой классификации в прикладных задачах;
- теоретическая обоснованность – согласованность с имеющимися теоретическими представлениями о связях внутри классов и между классами;
- эвристическая сила – возможность получать новые, неизвестные закономерности из построенной классификации;
- экономичность – небольшое число классов и используемых признаков;
- простота – прозрачность связей признаков внутри классов и между классами.
Они в том или ином виде могут использоваться в формулировке критерия качества таксономии [11].
1.1.3. Формулировка задачи выбора системы информативных признаков
Информативность признаков – понятие относительное. Одна и та же система признаков может быть информативна для решения одной задачи и не информативна – для другой. Поэтому, прежде чем приступать к решению этой задачи, необходимо определить, для каких целей выбираются признаки и сформулировать критерий Qf для оценки качества набора признаков. При этом система информативных признаков может выбираться из числа исходных (selection), или определяться по какому-либо правилу по совокупности исходных признаков, например как их линейные комбинации (extraction). Имеется, по крайне мере, три основных типа принципиальных предпосылок, обуславливающих возможность перехода от большего числа исходных описывающих признаков к меньшему числу наиболее информативных переменных [1]. Это:
- дублирование информации, доставляемое сильно взаимосвязанными признаками;
- неинформативность признаков, мало меняющихся при переходе от одного объекта к другому;

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
