

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
![]() .
.
Пример.
Внутренние аудиторы большой компании интересуются системой обработки счетов доходов. Они взяли случайную выборку объемом ![]() законченных счетов и проверили их. Четыре из них оказались дефектными. Затем провели вторую случайную выборку объемом
законченных счетов и проверили их. Четыре из них оказались дефектными. Затем провели вторую случайную выборку объемом ![]() завершенных счетов и обнаружили три неисправных счета. Имеется ли какое-либо основание предполагать, что ошибки стали делаться реже?
завершенных счетов и обнаружили три неисправных счета. Имеется ли какое-либо основание предполагать, что ошибки стали делаться реже?
Решение.
Нулевая гипотеза предполагает, что две выборки случайно взяты из двух биномиальных генеральных совокупностей с равными долями ошибок:
![]() ;
;
![]() ,
,
т. е. предполагается, что доля ошибок сократилась, поэтому здесь приемлемо испытание с одной границей.
Будем принимать решение на 5 %-м уровне значимости. Здесь проходит нормальное распределение, поскольку размеры обеих выборок большие. По таблице нормального распределения в Приложении 4 находим:
![]() ;
;
![]() ;
;
![]() .
.
Предполагая, что гипотеза ![]() верна, лучшая оценка доли дефектных счетов в генеральной совокупности достигается осреднением долей двух выборок. В общем оказывается 7 дефектов из 110 случаев. Поэтому лучшей оценкой генеральной доли является
верна, лучшая оценка доли дефектных счетов в генеральной совокупности достигается осреднением долей двух выборок. В общем оказывается 7 дефектов из 110 случаев. Поэтому лучшей оценкой генеральной доли является
![]() ,
,
тогда
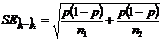 ,
,
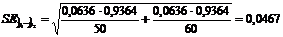 .
.
Проверочной статистикой является:
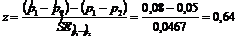 .
.
Поскольку
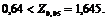
Результат не существенен на 5 %-м уровне. Факты согласуются с гипотезой ![]() на данном уровне значимости. У нас нет причины предполагать, что при обработке счетов доля ошибок сократилась.
на данном уровне значимости. У нас нет причины предполагать, что при обработке счетов доля ошибок сократилась.
4. Испытания непараметрических гипотез
Будем рассматривать примеры испытаний гипотез, которые не требуют ни предположения о нормальности, ни использования генеральных параметров. Этот раздел испытаний относится к непараметрическим испытаниям. Общая процедура испытания гипотез та же, что и для параметрических испытаний.
Рассмотрим самый общий непараметрический критерий «хи-квадрат». Он основан на сравнении ряда наблюдаемых частот с ожидаемыми частотами, если верна нулевая гипотеза. Будем использовать этот метод для проверки взаимосвязи признаков. Предположим, что нас интересуют два разных признака и мы хотим знать, существуют ли между ними какие-либо связи.
Пример.
Имеются данные по оценкам, полученным группой студентов на экзамене по экономической теории и по математике. Нас интересует, существует ли связь между оценками, полученными на экзамене по экономической теории и тем, сдан ли студентами экзамен по математике (табл. 7)
Таблица 7
Пример таблицы сопряженности
Результат экзамена по математике | Оценка по экономической теории | |||
Отлично | Хорошо | Удовлетво- рительно | Неудовлетво- рительно | |
Сдан |
|
|
|
|
Не сдан |
|
|
|
|
Число или частота студентов, которые сдали экзамен по математике и получили оценку отлично по экономической теории, записано в верхней левой части таблицы. Число студентов, не сдавших математику и получивших оценку отлично по экономической теории, записывается в нижней левой части таблицы и т. д. Такой тип таблицы называется таблицей сопряженности.
Табл. 7 имеет две строки и четыре столбца, т. е. является таблицей ![]() «два на четыре». Используя соответствующую нулевую гипотезу, мы можем рассчитать число студентов, которое ожидается в каждой клетке. Если нулевая гипотеза верна, различия между наблюдаемыми и ожидаемыми частотами будут небольшие. Будем использовать те же правила для решения, что и в прошлом испытании. Проверочная статистика рассчитывается на основе разницы между наблюдаемыми и ожидаемыми частотами для всех клеток таблицы.
«два на четыре». Используя соответствующую нулевую гипотезу, мы можем рассчитать число студентов, которое ожидается в каждой клетке. Если нулевая гипотеза верна, различия между наблюдаемыми и ожидаемыми частотами будут небольшие. Будем использовать те же правила для решения, что и в прошлом испытании. Проверочная статистика рассчитывается на основе разницы между наблюдаемыми и ожидаемыми частотами для всех клеток таблицы.
Если обозначить наблюдаемую частоту события ![]() и ожидаемую частоту
и ожидаемую частоту ![]() , то
, то ![]() – разность между наблюдаемой и ожидаемой частотами. Проверочной статистикой будет служить
– разность между наблюдаемой и ожидаемой частотами. Проверочной статистикой будет служить
![]() .
.
Возведение в квадрат разности ![]() необходимо для того, чтобы избежать нулевого эффекта при суммировании отрицательных и положительных величин. К тому же, чтобы достичь независимости от значения фактических частот, квадраты отклонений делят на ожидаемые частоты. Это стандартизирует все величины. Получаемая статистика подчиняется
необходимо для того, чтобы избежать нулевого эффекта при суммировании отрицательных и положительных величин. К тому же, чтобы достичь независимости от значения фактических частот, квадраты отклонений делят на ожидаемые частоты. Это стандартизирует все величины. Получаемая статистика подчиняется ![]() -распределению при достаточно больших значениях ожидаемых частот. Ориентиром обычно служит условие: ожидаемая частота должна быть не меньше 5, т. е.
-распределению при достаточно больших значениях ожидаемых частот. Ориентиром обычно служит условие: ожидаемая частота должна быть не меньше 5, т. е. ![]() .
.
Если одна или более ожидаемых частот меньше, чем 5, то категории должны быть скомбинированы до тех пор, пока частота не превысит установленного значения.
Для таблиц сопряженности ![]() , в которых сумма частот меньше или равна 100, иногда применяется корректировка – поправка Йетса. Тогда проверочная статистика вычисляется по следующей формуле:
, в которых сумма частот меньше или равна 100, иногда применяется корректировка – поправка Йетса. Тогда проверочная статистика вычисляется по следующей формуле:
![]() .
.
Такая поправка проводится потому, что ![]() является непрерывным распределением, а данные выборки – дискретные.
является непрерывным распределением, а данные выборки – дискретные.
Для больших выборок разница между исправленными и неисправленными значениями ![]() является небольшой и в таких случаях корректировка не требуется.
является небольшой и в таких случаях корректировка не требуется.
Форма ![]() -распределения зависит от числа степеней свобод в данной задаче. При использовании таблиц сопряженности число степеней свободы равняется:
-распределения зависит от числа степеней свобод в данной задаче. При использовании таблиц сопряженности число степеней свободы равняется:
![]() ,
,
где r и c – число строк и столбцов в таблице сопряженности, соответственно. Если таблица имеет только одну строку, то число степеней свободы равно ![]() и данные представляют собой ряд распределения по одной переменной.
и данные представляют собой ряд распределения по одной переменной.
Пример.
Управляющий рестораном и кафе для выработки стратегии деятельности предприятия провел опрос жителей микрорайона, в котором расположены эти объекты. Результаты опроса представлены в табл. 8.
Таблица 8
Результаты опроса
Группа опрошенных | Оценка по экономической теории | ||
Часто | Иногда | Не посещают | |
Молодые | 120 | 55 | 47 |
Пожилые | 139 | 105 | 98 |
Решение.
![]() нет связи между возрастной категорией опрашиваемого и частотой посещения ресторана и кафе, т. е.
нет связи между возрастной категорией опрашиваемого и частотой посещения ресторана и кафе, т. е. ![]() .
.
![]() есть связь между возрастом опрашиваемого и частотой посещения ресторана и кафе, т. е.
есть связь между возрастом опрашиваемого и частотой посещения ресторана и кафе, т. е. ![]() .
.
Будем испытывать нулевую гипотезу на 5 %-м уровне значимости, используя критерий ![]() с
с 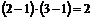 степенями свободы.
степенями свободы.
Из таблицы в Приложении 2 находим, что ![]() .
.
Для расчета проверочной статистики нужно определить ожидаемые частоты по каждой категории.
Таблица 9
Ожидаемые частоты
Группа опрошенных | Частота посещения ресторана или кафе | |||
Часто | Иногда | Не посещают | Итого | |
Молодые | 102 | 63 | 57 | 222 |
Пожилые | 157 | 97 | 88 | 342 |
Итого | 259 | 160 | 145 | 564 |
259 опрошенных заявили, что они посещают эти учреждения часто. Доля этой категории составляет 259/564. Если нет связи между посещением и возрастом, то такая же доля часто посещающих будет как среди молодых, так и среди пожилых, т. е. 259/564 из 222 относятся к категории завсегдатаев. Таким образом, ожидаемая клеточная частота в первой клетке таблицы равна: 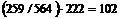 чел., т. е. ожидаемые частоты рассчитываются как произведение сумм частот по строке и столбцу таблицы, деленное на объем выборки.
чел., т. е. ожидаемые частоты рассчитываются как произведение сумм частот по строке и столбцу таблицы, деленное на объем выборки.
Ожидаемые частоты являются средними значениями и могут не округляться до целого. Расчет «хи-квадрат» приведен в табл. 10.
Таблица 10
Ожидаемые частоты
|
|
|
|
|
120 139 55 105 47 98 | 102 157 63 97 57 88 | 18 -18 -8 8 -10 10 | 324 324 64 64 100 100 | 3,18 2,06 1,02 0,66 1,75 1,14 |
564 | 564 | – | – | 9,81 |
Найденное значение ![]() показано на рис. 11.
показано на рис. 11.
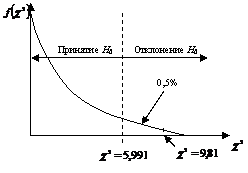

Рис. 11. Критическое значение ![]() на 5 %-м уровне значимости
на 5 %-м уровне значимости
при двух степенях свободы
![]() , следовательно, гипотеза
, следовательно, гипотеза ![]() отклоняется: связь между возрастом и частотой посещения ресторана и кафе следует признать доказанной на 5 %-м уровне значимости.
отклоняется: связь между возрастом и частотой посещения ресторана и кафе следует признать доказанной на 5 %-м уровне значимости.
5. Оценка существенности параметров
линейной регрессии и корреляции
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю: ![]() и, следовательно, фактор x не оказывает влияния на результат y.
и, следовательно, фактор x не оказывает влияния на результат y.
Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений величины y от ее среднего значения ![]() на «объясненную» и «необъясненную» компоненты:
на «объясненную» и «необъясненную» компоненты:
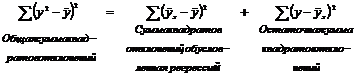
Общая сумма квадратов отклонений индивидуальных значений результативного признака y от своего значения ![]() вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор x и прочие факторы. Если фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси OX и
вызвана влиянием множества причин. Условно разделим всю совокупность причин на две группы: изучаемый фактор x и прочие факторы. Если фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси OX и ![]() . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то y связан с x функционально, и остаточная сумма квадратов равна нулю. В этом случае общая сумма квадратов совпадает с суммой квадратов отклонений, обусловленной регрессией.
. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то y связан с x функционально, и остаточная сумма квадратов равна нулю. В этом случае общая сумма квадратов совпадает с суммой квадратов отклонений, обусловленной регрессией.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс, как обусловленный влиянием фактора x, т. е. регрессией y по x, так и вызванный действием прочих причин (необъясненная вариация). Пригодность линии регрессии для последующего прогноза зависит от того, какая часть общей вариации признака y приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет много больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор x оказывает существенное воздействие на результат y. Это равносильно тому, что коэффициент детерминации ![]() будет приближаться к 1.
будет приближаться к 1.
Любая сумма квадратов отклонений связана с числом степеней свободы, т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из n возможных ![]() требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
![]()
требуется ![]() независимых отклонений, ибо по совокупности из n единиц после расчета среднего уровня свободно варьируют лишь
независимых отклонений, ибо по совокупности из n единиц после расчета среднего уровня свободно варьируют лишь ![]() - число отклонений. Например, имеем ряд значений y: 1, 2, 3, 4, 5. Среднее значение равно 3 и тогда n отклонений от среднего составят: -2; -1; 0; 1; 2. Так как
- число отклонений. Например, имеем ряд значений y: 1, 2, 3, 4, 5. Среднее значение равно 3 и тогда n отклонений от среднего составят: -2; -1; 0; 1; 2. Так как 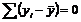 , то свободно варьируют лишь 4 отклонения, а пятое может быть определено, если предыдущие 4 известны.
, то свободно варьируют лишь 4 отклонения, а пятое может быть определено, если предыдущие 4 известны.
При расчете факторной суммы квадратов ![]() используются теоретические (расчетные) значения результативного признака
используются теоретические (расчетные) значения результативного признака ![]() , найденные по линии регрессии:
, найденные по линии регрессии: ![]() .
.
В линейной регрессии ![]() . В этом нетрудно убедиться, обратившись к формуле линейного коэффициента корреляции:
. В этом нетрудно убедиться, обратившись к формуле линейного коэффициента корреляции: ![]() . Отсюда
. Отсюда ![]() ,
,
где ![]() – общая дисперсия признака y,
– общая дисперсия признака y,
![]() – факторная дисперсия, т. е. обусловленная регрессией.
– факторная дисперсия, т. е. обусловленная регрессией.
Соответственно сумма квадратов отклонений, обусловленных линейной регрессией, составит:
![]()
Поскольку при заданном объеме наблюдений по x и y факторная сумма квадратов при линейной регрессии зависит только от одной константы – коэффициента регрессии b, то данная сумма квадратов имеет одну степень свободы. К этому же выводу придем, если рассмотрим содержательную сторону расчетного значения признака y, т. е. ![]() . Значение
. Значение ![]() определяется по уравнению линейной регрессии:
определяется по уравнению линейной регрессии: ![]() .
.
Но параметр a можно определить как ![]() . Подставив это выражение параметра a в линейную модель, получим:
. Подставив это выражение параметра a в линейную модель, получим:
![]() .
.
Отсюда видно, что при заданном наборе переменных y и x расчетное значение ![]() является в линейной регрессии функцией только одного параметра – коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
является в линейной регрессии функцией только одного параметра – коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
Поскольку существует балансовое равенство между числом степеней свободы общей, факторной и остаточной сумм квадратов, то число степеней свободы остаточной суммы квадратов при линейной регрессии составит ![]() , т. е.
, т. е. 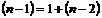 . Итак имеем два балансовых равенства:
. Итак имеем два балансовых равенства:
![]() ,
,
![]() .
.
Поделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений или, что то же самое, дисперсию D на одну степень свободы. Определение дисперсии на одну степень свободы приводит их к сравнимому виду. Сопоставляя факторную и остаточную дисперсии на одну степень свободы, найдем величину F-отношения:
![]() .
.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для опровержения ее необходимо, чтобы факторная дисперсия превышала остаточную в несколько раз. Разработаны (английским статистиком Снедекором) таблицы критических значений F-отношений при разных уровнях существенности нулевой гипотезы и различном числе степеней свободы. Табличное значение F-критерия – это максимальное значение отношения дисперсий, которое может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признается достоверным (отличным от 1), если оно больше табличного. В этом случае отбрасывается нулевая гипотеза об отсутствии связи признаков и делается вывод о существенности этой связи.
Если же значение F-критерия окажется меньше табличного, то вероятность нулевой гипотезы выше заданного уровня (например, 0,05) и она не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым.
В рассматриваемом примере:
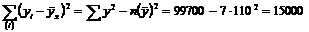 (общая сумма квадратов);
(общая сумма квадратов);
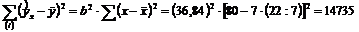 (факторная сумма квадратов);
(факторная сумма квадратов);
![]() ;
;
![]() ;
;
![]() ;
;
![]() .
.
Критические значения F-критерия для уровней значимости ![]() и
и ![]() :
:
для ![]()
![]() ; для
; для ![]()
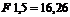 .
.
Поскольку ![]() превышает табличные значения при 5-и и 1 %-м уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
превышает табличные значения при 5-и и 1 %-м уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
Значение F-критерия связано с коэффициентом детерминации r. Факторную сумму квадратов отклонений можно представить как ![]() , а остаточную сумму квадратов – как
, а остаточную сумму квадратов – как 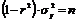 .
.
Тогда значение F-критерия можно получить, исходя из формулы:
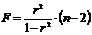 .
.
В нашем примере 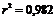 . Тогда
. Тогда 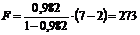 (некоторое несовпадение результатов связано с ошибками округления).
(некоторое несовпадение результатов связано с ошибками округления).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
