

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Приведём статистику по построенной модели.
Dependent Variable: INLF | |||
Method: ML - Binary Probit | |||
Sample: 1 753 | |||
Included observations: 753 | |||
Descriptive statistics for explanatory variables | |||
Mean | |||
Variable | Dep=0 | Dep=1 | All |
C | 1.000000 | 1.000000 | 1.000000 |
AGE | 43.28308 | 41.97196 | 42.53785 |
EDUC | 11.79692 | 12.65888 | 12.28685 |
EXPER | 7.461538 | 13.03738 | 10.63081 |
EXPERSQ | 103.3938 | 234.7196 | 178.0385 |
HUSHRS | 2311.791 | 2233.465 | 2267.271 |
KIDSLT6 | 0.366154 | 0.140187 | 0.237716 |
UNEM | 8.726154 | 8.545561 | 8.623506 |
Standard Deviation | |||
Variable | Dep=0 | Dep=1 | All |
C | 0.000000 | 0.000000 | 0.000000 |
AGE | 8.467796 | 7.721084 | 8.072574 |
EDUC | 2.181995 | 2.285376 | 2.280246 |
EXPER | 6.918567 | 8.055923 | 8.069130 |
EXPERSQ | 196.7098 | 270.0434 | 249.6308 |
HUSHRS | 609.8817 | 582.9088 | 595.5666 |
KIDSLT6 | 0.636900 | 0.391923 | 0.523959 |
UNEM | 3.221086 | 3.033328 | 3.114934 |
Observations | 325 | 428 | 753 |
Для порядка приведём таблицу предсказаний модели для стандартной границы отсечения. Видим, что наша модель даёт существенно большую точность распознавания чем самая примитивная модель (всегда работать или всегда не работать).
Dependent Variable: INLF | ||||||
Method: ML - Binary Probit | ||||||
Sample: 1 753 | ||||||
Included observations: 753 | ||||||
Prediction Evaluation (success cutoff C = 0.5) | ||||||
Estimated Equation | Constant Probability | |||||
Dep=0 | Dep=1 | Total | Dep=0 | Dep=1 | Total | |
P(Dep=1)<=C | 205 | 82 | 287 | 0 | 0 | 0 |
P(Dep=1)>C | 120 | 346 | 466 | 325 | 428 | 753 |
Total | 325 | 428 | 753 | 325 | 428 | 753 |
Correct | 205 | 346 | 551 | 0 | 428 | 428 |
% Correct | 63.08 | 80.84 | 73.17 | 0.00 | 100.00 | 56.84 |
% Incorrect | 36.92 | 19.16 | 26.83 | 100.00 | 0.00 | 43.16 |
Total Gain* | 63.08 | -19.16 | 16.33 | |||
Percent Gain** | 63.08 | NA | 37.85 | |||
Estimated Equation | Constant Probability | |||||
Dep=0 | Dep=1 | Total | Dep=0 | Dep=1 | Total | |
E(# of Dep=0) | 189.33 | 134.79 | 324.12 | 140.27 | 184.73 | 325.00 |
E(# of Dep=1) | 135.67 | 293.21 | 428.88 | 184.73 | 243.27 | 428.00 |
Total | 325.00 | 428.00 | 753.00 | 325.00 | 428.00 | 753.00 |
Correct | 189.33 | 293.21 | 482.53 | 140.27 | 243.27 | 383.54 |
% Correct | 58.25 | 68.51 | 64.08 | 43.16 | 56.84 | 50.94 |
% Incorrect | 41.75 | 31.49 | 35.92 | 56.84 | 43.16 | 49.06 |
Total Gain | 15.09 | 11.67 | 13.15 | |||
Percent Gain | 26.55 | 27.03 | 26.79 |
Однако такая таблица может дать гораздо меньше информации, чем график точности предсказаний модели в зависимости от выбора границы отсечения [1].
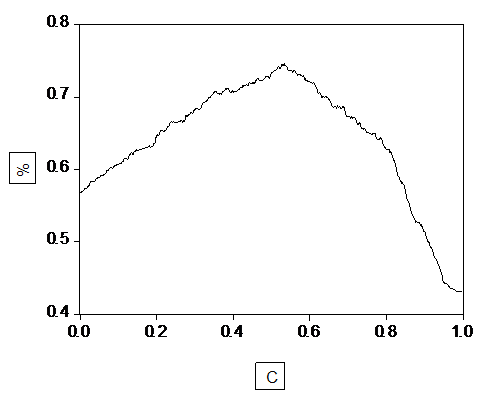
Модель хорошая, что лишний раз подтверждают тесты.
Dependent Variable: INLF | ||||||||
Method: ML - Binary Probit | ||||||||
Sample: 1 753 | ||||||||
Included observations: 753 | ||||||||
Andrews and Hosmer-Lemeshow Goodness-of-Fit Tests | ||||||||
Grouping based upon predicted risk (randomize ties) | ||||||||
Quantile of Risk | Dep=0 | Dep=1 | Total | H-L | ||||
Low | High | Actual | Expect | Actual | Expect | Obs | Value | |
1 | 0.0041 | 0.1969 | 64 | 66.8248 | 11 | 8.17516 | 75 | 1.09551 |
2 | 0.1972 | 0.3014 | 54 | 56.3072 | 21 | 18.6928 | 75 | 0.37930 |
3 | 0.3024 | 0.4187 | 49 | 47.9787 | 26 | 27.0213 | 75 | 0.06034 |
4 | 0.4253 | 0.5228 | 48 | 40.1619 | 28 | 35.8381 | 76 | 3.24398 |
5 | 0.5229 | 0.6075 | 29 | 32.8512 | 46 | 42.1488 | 75 | 0.80337 |
6 | 0.6076 | 0.6805 | 25 | 26.6595 | 50 | 48.3405 | 75 | 0.16027 |
7 | 0.6841 | 0.7481 | 27 | 21.4295 | 49 | 54.5705 | 76 | 2.01668 |
8 | 0.7481 | 0.8273 | 16 | 15.7079 | 59 | 59.2921 | 75 | 0.00687 |
9 | 0.8281 | 0.8936 | 9 | 10.6498 | 66 | 64.3502 | 75 | 0.29787 |
10 | 0.8937 | 0.9817 | 4 | 5.54834 | 72 | 70.4517 | 76 | 0.46611 |
Total | 325 | 324.119 | 428 | 428.881 | 753 | 8.53030 | ||
H-L Statistic: | 8.5303 | Prob. Chi-Sq(8) | 0.3835 | |||||
Andrews Statistic: | 11.4125 | Prob. Chi-Sq(10) | 0.3263 |
4. Построение logit–модели

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
