


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Метод простого скользящего среднего (simple moving average) состоит в том, что расчет показателя на прогнозируемый момент времени ится путем усреднения значений этого показателя за несколько предшествующих моментов времени.
Обратимся к заданному временному ряду.
Для вычисления прогнозируемого объема продаж на четверг поступим следующим образом. Возьмем фактические данные за три предыдущих дня – понедельник, вторник и среду – и найдем их среднее арифметическое:
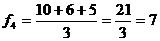 .
.
Прогнозируемый объем продаж на пятницу вычисляется аналогичным образом по реальным показателям за три предшествующих дня – вторник, среду и четверг:
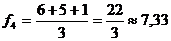 .
.
Подобным же образом рассчитываются прогнозы на субботу, воскресенье и очередной понедельник.
Полученные вычисления представлены в таблице:
t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
x | 10 | 6 | 5 | 11 | 9 | 8 | 7 | - |
f | - | - | - | 7 | 7,33 | 8,33 | 9,33 | 8 |
Для общего случая расчетная формула выглядит так:
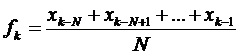 ,
,
или
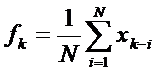 , (1)
, (1)
Где
xk-i – реальное значение показателя в момент времени tk-i;
N – число предшествующих моментов времени, используемых при расчете;
fk - прогноз на момент времени tk.
Замечание. В рассматриваемом примере N = 3.
Метод взвешенного подвижного (скользящего) среднего
Метод взвешенного подвижного (скользящего) среднего (weighted moving average). При составлении прогноза методом усреднения часто приходится наблюдать, что влияние используемых при расчете реальных показателей оказывается неодинаковым, при этом обычно более свежие данные имеют больший вес.
Математически метод взвешенного подвижного среднего можно записать так:
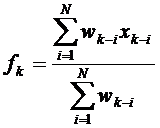 ,
,
Где
xk-i – реальное значение показателя в момент времени tk-i;
N – число предшествующих моментов времени, используемых при расчете;
fk - прогноз на момент времени tk;
wk-i – вес, с которым используется показатель xk-I при расчете.
Вес – всегда положительное число. В случае, когда все веса одинаковы, мы получаем формулу (1).
Для расчетов обратимся к исходному временному ряду, считая, что при составлении прогноза на завтрашний день объем сегодняшних продаж мы возьмем с весом 60, вчерашних – с весом 30, а позавчерашних – с весом 10.
Имеем:
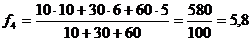 ;
;
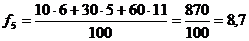 ;
;
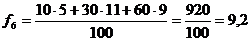 ;
;
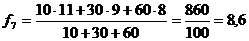 ;
;
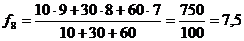 .
.
Результаты расчетов приведены в таблице:
t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
x | 10 | 6 | 5 | 11 | 9 | 8 | 7 | - |
f | - | - | - | 5,8 | 8,7 | 9,2 | 8,6 | 7,5 |
Метод экспоненциального сглаживания
При расчете методом экспоненциального сглаживания учитывается отклонение предыдущего прогноза от реального показателя, а сам расчет проводится по следующей формуле:
,
где
xk-i – реальное значение показателя в момент времени tk-i;
fk - прогноз на момент времени tk;
α – постоянная сглаживания.
Замечание. Значение постоянной α, подчиненной условию 0< α<1, определяет степень сглаживания и обычно выбирается универсальным методом проб и ошибок.
Для расчетов вновь обратимся к исходному временному ряду, положив α= 0,2 и считая, что прогноз на понедельник равен 8.
Тогда
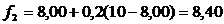 ,
,
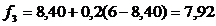 ,
,
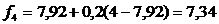 ,
,
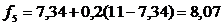 ,
,
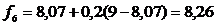 ,
,
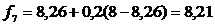 ,
,
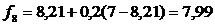 .
.
Результаты расчетов приведены в таблице:
t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
x | 10 | 6 | 5 | 11 | 9 | 8 | 7 | - |
f | - | 8,4 | 7,92 | 7,34 | 8,07 | 8,26 | 8,21 | 7,93 |
Замечание. Следует иметь в виду, что при решении реальной задачи прогнозирования временной ряд складывается постепенно и реальное значение показателя на рассчитываемый момент времени нам заранее неизвестно. Тем не менее, прежде чем заглянуть в будущее посредством одного из указанных выше методов, обычно проводятся расчеты с полным временным рядом, описывающий некоторый промежуток времени в прошлом. Это делается для того, чтобы
- подобрать подходящее значение N и сравнить результаты прогноза с реальными данными (метод простого скользящего среднего);
- подобрать подходящие значения N и весов и сравнить результаты прогноза с реальными данными (метод взвешенного скользящего среднего);
- подобрать подходящие значения постоянной сглаживания α и сравнить результаты прогноза с реальными данными (метод экспоненциального сглаживания).
Метод проецирования тренда.
Основной идеей метода проецирования (линейного) тренда является построение прямой, которая «в среднем» наименее уклоняется от массива точек (ti,xi), i= 1, 2, …, n, заданного временным рядом.
Эта прямая ищется в следующем виде: x = at + b,
где a и b – постоянные, подлежащие определению.
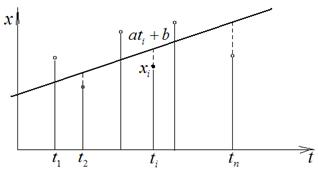
Чтобы найти коэффициенты a и b, поступают так:
Для каждого значения ti переменной t, пользуясь формулой x= at + b, вычисляют соответствующее значение переменной x:
ati + b, i= 1, 2, …, n,
находят разность
ati + b- xi i= 1, 2, …, n,
которую затем возводят в квадрат (чтобы не думать о знаке):
(ati + b- xi)2,_ i= 1, 2, …, n,
и, складывая, в итоге получают:
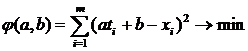 .
.
Функция φ(a, b) принимает минимальное значение в том случае, когда величины a и b удовлетворяют следующей линейной системе:
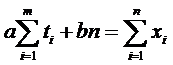 ,
,
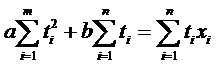 .
.
Эта система всегда имеет единственное решение.
Рассмотрим конкретный пример, вновь обратившись к заданному временному ряду.
Составим вспомогательную таблицу:
ti | xi | ti xi | ti2 |
1 2 3 4 5 6 7 | 10 6 5 11 9 8 7 | 10 12 15 44 45 48 49 | 1 4 9 16 25 36 49 |
|
|
|
|
В этом случае система уравнений для отыскания a и b записывается в следующем виде:
28a + 7b = 56,
140a + 28b = 223.
Решая систему получаем:
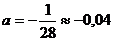 ,
, 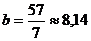 .
.
Тем самым
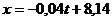
- уравнение искомого тренда.
Расчет показателя на следующий день проводится так:
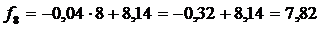 .
.
Каузальные методы прогнозирования
В случае значительных требований к точности прогноза и при наличии большого массива данных используются каузальные, или причинно-следственные, модели прогнозов, в которых прогнозируемая величина является функцией большого числа переменных. Если связи между этими переменными удается описать математически корректно, то точность каузального прогноза может оказаться достаточно высокой. Но как правило, требует больших объемов данных и существенно больших интеллектуальных, временных и финансовых затрат, чем анализ временных рядов.
Многомерные регрессионные методы (модели), посредством которых регрессионная зависимость между величинами устанавливается по статистическим данным, являются наиболее распространенными количественными методами прогнозирования. Простейшее представление о регрессионных моделях дает описанный выше метод проецирования тренда, в котором регрессионная зависимость устанавливается между прогнозируемым показателем и одной переменной – временем. Многомерные модели линейной регрессии можно рассматривать как линейное обобщение этого метода.
Эконометрические методы (модели) дают количественное описание закономерностей и взаимосвязей между экономическими объектами и процессами и разрабатываются для прогнозирования динамики экономики. Типичная эконометрическая модель представляет собой систему из тысяч уравнений, решение которых требует мощных вычислительных средств.
Компьютерная имитация. С появлением современных ЭВМ уровень сложности математических моделей, при помощи которых можно делать правильные прогнозы о динамике процессов, существенно вырос. Появились модели, способные создавать «иллюзию реальности». Называемые имитационными, эти модели являются как бы промежуточным звеном между реальностью и обычными математическими моделями. Имитационные модели находятся на пределе возможностей вычислительной техники. (и системного программирования).
Замечание. Всегда существуют процессы настолько сложные, что они не поддаются изучению математическими методами. Это не означает, однако, что они непознаваемы. Просто их рассматривают гуманитарными методами и средствами искусства – столь ж необходимыми методами изучения реальности, как и математические методы. А подвижная граница между гуманитарными и математическими методами изучения реальности происходит как раз по имитационным моделям в том понимании того термина, о котором идет речь здесь.
Качественные методы прогнозирования.
При отсутствии количественных данных, или когда количественная модель получается слишком дорогой, используются качественные методы прогнозирования, которые строятся на основе разного рода экспертных оценок.
К качественным методам относятся: дельфийский метод, изучение рынка, метод консенсуса, мнение сбытовиков, историческая аналогия.
Дельфийский метод, или метод экспертных оценок, представляет собой процедуру, позволяющую приходить к согласию группе экспертов из самых разных, но взаимосвязанных областей. Работа над составлением прогноза этим методом организуется так: каждому эксперту независимо рассылается вопросник по поводу рассматриваемой проблемы, ответы экспертов и их мнения кладутся в основу подготовки следующего вопросника, вновь рассылаемого экспертам, и так далее до тех пор, пока эксперты не приходят к согласию (при условии запрета на открытие дискуссии между экспертами).
Изучение рынка, или модель ожидания потребителя. Прогноз строится на основании разнообразных опросов потребителей и последующей статистической обработки.
Метод консенсуса, или мнение жюри, заключается в соединении и усреднении мнений группы экспертов в процессе «мозгового штурма».
Историческая аналогия обычно используется в тех случаях, когда нужно дать прогноз продажи товара, по своим характеристикам близкого к выпущенному ранее (например, его модификации).
ТЕМА 7. Иерархии и приоритеты.
План темы.
1. Общее описание метода анализа иерархий.
2. Основные этапы метода анализа иерархий.
3. Шкалирование.
4. Индекс согласованности.
Иерархии представляют собой определенный вид системы, основанный на предположении, что ее элементы могут сгруппироваться в несвязанные множества. При этом элементы каждой группы находятся под влиянием элементов некоторой другой вполне определенной группы и в свою очередь оказывают влияние на элементы третьей группы. Считается, что элементы в каждой группе иерархии, называемой уровнем, независимы.
Цель метода анализа иерархий - обоснование выбора наилучшей из предлагаемых альтернатив, характеристики которых являются векторами с разнородными, в том числе и с нечетко определенными, отдельными компонентами.
Суть метода анализа иерархий заключается в поэтапном решении следующих взаимосвязанных частных задач:
- построение иерархической структуры показателей (признаков);
- оценивание значимости отдельных частных показателей для каждого уровня иерархии;
- сравнение имеющихся альтернатив и выбор наилучшей из них.
В результате должна быть выражена относительная степень (интенсивность) взаимодействия элементов в иерархии. Метод анализа иерархии включает процедуры синтеза множественных суждений, базирующихся на результатах парных сравнений, которые затем выражаются численно, оценки приоритетности (важности) критериев (отдельных показателей), а также оценки альтернативных решений и нахождения наилучшего из них. Полученные результирующие значения являются оценками в шкале отношений, что соответствует жестким оценкам.
Исходным материалом, на основании которого ЛПР может получить достаточное, четкое и ясное представление о превосходстве одного элемента над другим, являются интуиция и субъективные оценки, несмотря на то, что суждения и их интенсивность характеризуют выражение внутренних чувств и склонностей конкретных экспертов.. Суждения расширяют рамки общения, укрупняя элементы, имеющиеся на определенном уровне иерархии.
Изложенное дает представление об основных принципах метода анализа иерархий. Подробнее эти принципы будут изложены в дальнейшем, при детальном рассмотрении процедур.
Метод анализа иерархий включает следующие основные этапы, значимость которых различна для разных задач и ситуаций.
1. Описание проблемы и определение цели исследований.
2. Построение иерархии, начиная с вершины (цели с точки зрения управления), через промежуточные уровни (критерии, от которых зависят последующие уровни), к самому нижнему уровню (который обычно является перечнем альтернатив).
3. Построение матриц влияния элементов верхнего (предыдущего) уровня на элементы нижнего (следующего) уровня (для каждого из нижних уровней) по одной матрице для каждого элемента, примыкающего сверху уровня. В полной простой иерархии любой элемент воздействует на каждый элемент примыкающего сверху уровня. Элементы каждого уровня сравниваются друг с другом относительно степени их воздействия на элемент предыдущего уровня и получают квадратную матрицу суждений. Реальные иерархические структуры весьма редко бывают полными простыми иерархиями и их, в ряде случаев, целесообразно декомпозировать на подуровни.
Парные сравнения проводятся в терминах определения степеней доминирования (предпочтения) одного из элементов над другим, для чего используется система шкалирования.
4. На этапе 3 для получения каждой матрицы требуется n(n--1)/2 суждений (парных сравнений). Результатом этапа 3 (сравнения значимости влияния элементов следующего уровня на элементы предыдущего уровня) является набор квадратных матриц N1, N2, , Nk с элементами (aij, i, j = 1, 2,…, n), где k число элементов предыдущего уровня иерархии,- n число элементов следующего уровня иерархии. Если иерархическая структура не является полной простой иерархией, то возможно уменьшение количества сравнений, т. е. упрощение процесса получения результатов парных сравнений.
Следует заметить, что в данном случае речь идет о коллективном обсуждении и формировании матриц парных сравнений. Случай, когда эксперты формируют собственные наборы матриц и, к тому же обладают различной квалификацией (степенью значимости) рассмотрен далее в п. 3.
5. После проведения всех парных сравнений для элементов соседних уровней (получения набора матриц) следует вычислить весовые коэффициенты дуг. Для каждой из матриц Ni определяется нормализованный вектор локальных приоритетов, со следующими компонентами:
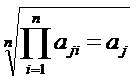 , (3.1)
, (3.1)
где n размерность матрицы;- aji элемент - j-ой строки матрицы. Таким образом, матрице Ni сопоставляется вектор ai .
Нормирование компонент осуществляется путем деления каждой компоненты вектора ai на сумму всех компонент этого вектора:
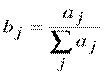 . (3.2)
. (3.2)
Нормированный вектор bi соответствует весовым коэффициентам дуг, соединяющих i-й элемент предыдущего уровня со всеми элементами следующего уровня. Если ввести в рассмотрение матрицу влияний элементов нижнего уровня на элементы предыдущего уровня Bl, где l номер уровня иерархии, то векторы- bi будут являться ее столбцами.
6. После получения данных (обработки матриц суждений Ni на вторую компоненту и т. д. Полученные числа суммируются и получается величина-по формулам (3.1) и (3.2)) следует определить их согласованность. Степень согласованности для каждой матрицы приближенно вычисляется следующим способом: суммируется каждый столбец матрицы суждений, и сумма первого столбца умножается на величину первой компоненты нормализованного вектора приоритетов, сумма второго столбца на вторую компоненту и т. д. Полученные числа суммируются и получается величина-
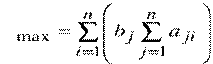 . (3.3)
. (3.3)
Используя отклонение ![]() от n, находят индекс согласованности (ИС), сравнивая который с соответствующими средними значениями для случайных элементов, получают отношение согласованности (ОС). (Подробно получение оценок согласованности приведено далее).
от n, находят индекс согласованности (ИС), сравнивая который с соответствующими средними значениями для случайных элементов, получают отношение согласованности (ОС). (Подробно получение оценок согласованности приведено далее).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
