
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· Транслирует адрес в микропрограммную память.
· Инкрементирует адрес.
· Реализовывает операцию безусловного перехода (адрес перехода может содержаться либо в микрокоманде, либо в регистре)
· Реализовывает операцию 2-х направленного условного перехода.
Рассмотрим, как происходит работа схемы. Изначально по шине данных в регистр команд записывается команда. После этого она передаётся в ПНА. На выходе, в секвенсор передаётся адрес первой микрокоманды. Секвенсор передаёт микрокоманду из входа D на дешифратор, который декодирует её и формирует набор управляющих сигналов. Напомним, что набор управляющих сигналов есть суть работы устройства управления. Также из секвенсора, из входа A, на мультиплексор поступает адрес следующей команды, после маскирования с флагами поступающими либо из регистра состояния (результат, накопленный на предыдущих итерациях), либо непосредственно из вне (например, от внешних устройств) и передаётся на вход секвенсора. В случае если необходимо совершить переход, то адрес перехода передаётся с выхода секвенсора на его вход, для этого существует отдельная шина (внимание на рисунок). Для синхронизации работы, в схеме присутствует формирователь синхроимпульсов. От формирователя синхроимпульсов есть управляющие линии ко всем устройствам схемы, но чтобы не загромождать рисунок, они попросту опущены.
Итак, этапы работы данной схемы модно обозначить как:
1)Формирование адреса микрокоманды.
2)Чтение микрокоманды.
3)Исполнение микрокоманды.
В данную схему можно ввести конвейер. Для этого нужно ввести регистр микрокоманд. Если установить регистр микрокоманд сразу после блока микропрограммной памяти, то можно будет начинать формирование адреса следующей команды, в момент отправки на дешифратор предыдущей микрокоманды. Если ввести регистр адреса микрокоманды, на шине между ПНА и секвенсором, то станет возможным начинать формирование адреса следующей микрокоманды уже в момент считывания. Также можно будет начинать считывание микрокоманды по сформированному адресу, когда предыдущая будет находиться на дешифраторе.
При включении питания, первое, что необходимо сделать, это :
1)Обнулить регистр микрокоманд.
2)Подать по каналу I нулевого адреса.
Для нормальной работы микропрограммная память должна содержать следующие команды:
· Чтение микрокоманды (тоже является микрокомандой).
· Обнуление адреса.
Виды микропрограммного управления:
1. Горизонтальные – количество разрядов равно количеству функциональных сигналов.
· Быстродействие – максимальное.
· Производительность – максимальная.
· Затраты оборудования – максимальные

2. Вертикальные - формирование функциональных сигналов в двоичной системе счисления (нужно меньше разрядов).
· Быстродействие - невысокое (нужно время на дешифрацию).
· Производительность – минимальная (по 1-му функциональному сигналу).
· Затраты оборудования – много меньше, чем в горизонтальной.
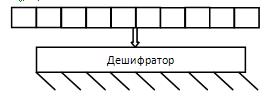
3. Смешанная.
Для того чтобы рассматривать этот вид микропрограммного управления, нам понадобиться понятие несовместимости команд. Несовместимость операции – физическая невозможность одновременного выполнение некоторого заданного набора операции. Различают два вида несовместимости: функциональная (несовместимость, грозящая выходом устройства из строя – физическая несовместимость) и алгоритмическая (теоретически, одновременно использовать можно, но практически это не нужно).
Так вот, необходимо всю совокупность МОП разделить на несовместимые группы. Дальше необходимо организовать между группами горизонтальное управление, а внутри группы вертикальное.
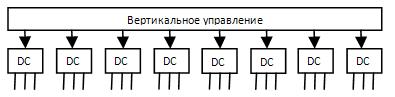
· Быстродействие – среднее.
· Производительность – не хуже, чем у горизонтального.
· Затраты оборудования – средние.
Данные вариант является золотой серединой в плане характеристик, но его существенным недостатком является сложность настройки.
4. 2-х уровневое микропрограммное управление.
В устройстве управления нет регистра микрокоманды и регистра адреса микрокоманды, но на выходе памяти микрокоманд, есть память нанокоманд. Внутри микрокоманды нанокоманда может встречаться несколько раз, поэтому можно сказать, что в памяти микрокоманд, расположен горизонтальный набор нанокоманд. Затраты оборудования примерно как у смешанного, но за счёт лишнего блока, получается лишнее считывание из памяти. Конечно, этот недостаток можно обойти, за счёт введение конвейера, но конвейер обладает рядом своих проблем (ветвление и т. д.). Данный вариант используется в архитектуре NetBurnst.
12)Понятие прерывания программ. Типы прерываний. Характеристики, структуры систем прерываний и их сравнительная оценка.
Прерывание программы – это способность ЭВМ временно прекращать выполнение текущей программы при возникновении какого-либо события, вызывать программу обработки этого события, а затем возвращаться к выполнению прерванной программы.(понятия: прерываемая программа, прерывающая программа)
Типы прерываний
trap – внутренние прерывания или синхронные прерывания, или программные, или исключения (особые ситуации: деление на 0, переполнение), возникают всегда в одном месте.
interrupt – внешние или асинхронные прерывания, связаны с организацией в/в.
Характеристики:
· Общее кол-во запросов на прерывания
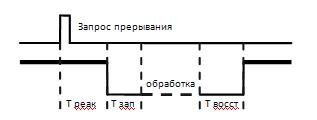
· Время реакции – tр время м/ду появлением запроса на прерывание и началом выполнения прерывающей программы
· Время обслуживания – равно суммарному расходу времени на запоминание и восстановление состояния программы
tобсл = tзап + tвосст
· Глубина прерывания – max число программ, которые могут прервать друг друга. Системы с большой глубиной прерываний обеспечивают более быструю реакцию на срочные запросы.
Принцип прерывания программы:
Если 2 прерывания идут подряд:
1. Система с единичной глубиной прерываний
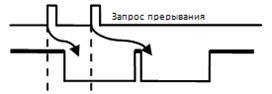
2. Система с произвольный глубиной прерываний (но, обычно повторное прерывание с одним и тем же номером отбрасывается)
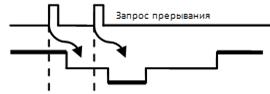
Структуры систем прерываний:
Структуры различают по способу передачи запроса в ЦП и способу идентификации источника.
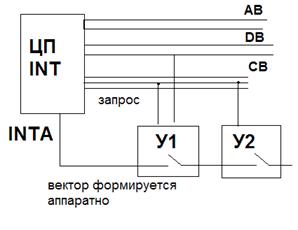
1. Цепочечная (с одной линией запроса)
В состав шины управления входит всего одна линия запросов. Одна программа обрабатывает все запросы, последовательно опрашивая все устройства в порядке их внутренней нумерации.
«-» – последовательный опрос (для большого количества устройств). T передачи вектора = T опроса устройств
«+» – простота реализации

2. Структура с одной линией запроса и последовательной цепочкой сигналов подтверждения
Есть ещё одна линия – линия подтверждения прерывания INT A (1- битовая). Если устройство посылает запрос, то оно разрывает эту линию. CPU, получив вектор, посылает сигнал для замыкания цепи линии подтверждения, далее устройство снимает вектор и в CPU начинает обработку прерываний.
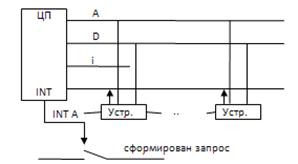
Вектор – ID источника запроса. Возникает проблема конфликта векторов (каждый завод дает собственные ID устройствам). Технология Plug & Play разрешает данную проблему (устройство должно поддерживать данную технологию), самостоятельно распределяя вектора (вектор – косвенный адрес обработчика).
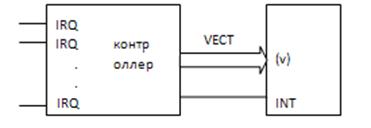
3. С индивидуальными линиями запроса.
Поддерживается столько устройств, сколько линий запроса прерываний и по идее столько входов должен иметь процессор. Требуется наличие контроллера прерываний (PIC).
PIC имеет индивидуальный вход для каждого запроса. Формирует 1 бит запроса прерывания и вектор. PIC может быть встроен в CPU.
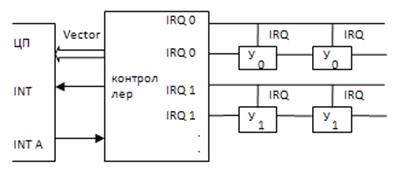
4. Смешанная
Используется для большого количества устройств. Совмещаются второй и третий тип.
13) Способы обнаружения запросов, распознавания причин прерывания и способы формирования начального адреса прерывающей программы.
Выяснить: 1) источник запроса
2) какая ситуация возникла в этом запросе (причина)
Источник запроса прерывания распознается через вектор прерываний. Два разных устройства не могут формировать одинаковые векторы. Вектор поступает по линии управления и код вектора по шине данных.
Vector – косвенный адрес обработчика прерываний; двоичный код, уникальный для каждого из устройств.
В цепочечной структуре:
Как найти обработчик прерывания: формирование обработчика прерываний у Intel
Вектор суммируется с регистром базы – это определяет дескриптор шлюза, а там указывается адрес обработчика.
14)Понятие допустимого момента прерывания. Обработка прерываний на уровне команд и на уровне микрокоманд. Схемы. Способы возврата из прерываний
Есть два способа организации прерывания программы:
1. Обработка на уровне команд.
Конвейер сбрасывается после завершения последней команды (после завершения прерывания команда перезапускается)
2. Обработка на уровне микрокоманд
Конвейер сбрасывается после завершения последней микрокоманды. Время реакции больше. (после завершения прерывания микрокоманда перезапускается)
Различия:
· Внутренние прерывания можно обрабатывать только на уровне микрокоманд
· Внешние прерывания можно прерывать обоими способами.
· Для обработки прерывания на уровне команд требуется запомнить адрес следующей команды и регистр флагов
· Для обработки прерывания на уровне микрокоманды необходимо запомнить, дополнительно к перечисленному выше, ещё и состояние всех регистров (и программно доступные и программно недоступные). Т. е. нужна дополнительная память.
Классификация:
· Внешнее прерывание – interrupt – уровень команд
· Внешняя авария – abort – уровень микрокоманд
· Команда – trap – уровень команд
· Внутреннее прерывание – exception – уровень микрокоманд
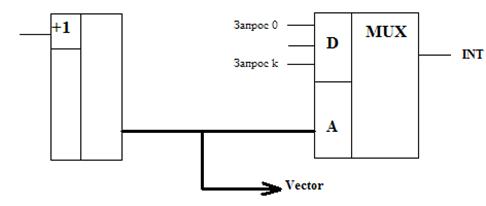
Реализация прерываний на уровне команд
Прерывание поступает в секвенсор следующим образом: один из признаков, подаваемых на MUX, является признаком запроса прерываний на секвенсор. На вход адреса может передаваться такое значение (за счет признака), которое будет интерпретироваться не как адрес для выборки команд, а как запрос на прерывание с конкретным номером.
Реализация прерываний на уровне микрокоманд
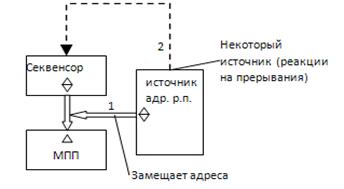
· На вход секвенсора(Секвенсор – формирует последовательность адресов) подается адрес команды. Секвенсор преобразует адрес команды в последовательность микрокоманд. По ветке 2 идут внешние прерывая, по ветке 1 идут внутренние прерывания. Секвенсор и источник синхронизированы так, что при генерации микрокомандного прерывания адрес микропрограммы от секвенсора замещается адресом обработчика прерываний от источника (адрес мк от секвенсора запоминается). После обработки прерывания, на секвенсор поступает запомненный адрес мк, с которого он должен продолжить работу. При командном прерывании (ветка 2) секвенсор сбрасывается и начинает обрабатывать прерывание; после обработки прерывания, секвенсор возвращается к недообработанной команде, адрес которой хранится в регистре команд.
Следует отметить, что при прерываниях не работают конвейерные структуры, все команды выполняются последовательно. При вхождении прерывания на уровне команд конвейер сбрасывается и после обработки прерывания начинает заполняться с нуля.
15)Организация вхождения в прерывающую программу. Таблица векторов прерываний.
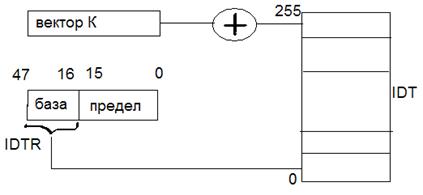
Поиск обработчика ведется по вектору прерываний (вектор – косвенный адрес обработчика). Реализуется он с помощью хранящейся в ОП таблицы векторов прерывания, где содержатся адреса программ обработки прерываний. Входом в таблицу служит вектор прерывания, Начальный адрес таблицы (база) обычно задается неявно, то есть под таблицу отводится вполне определенная часть памяти. В старых компьютерах (до Pentium) таблица векторов занимала начало адресного пространства, в современных компьютерах место таблицы строго не фиксировано, начало таблицы задается с помощью базы. Таблица векторов должна занимать непрерывный участок памяти.
Рассмотрим этапы работы с прерыванием.
Поиск обработчика прерывания:
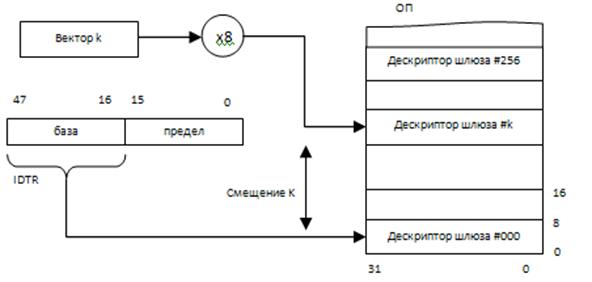
IDTR – Interrupt descriptor table register.
Предел – адрес последнего дескриптора.
База – начальный адрес таблицы.
Дескриптор шлюза прерывания:

P – признак присутствия сегмента в памяти
DPL – уровень привилегий (0-3)
* - тип шлюза: 0 – шлюз прерывания, 1 – шлюз ловушки.
D – размер шлюза: 1-32 бита, 0-16 бит.
Вызов обработчика прерывания:
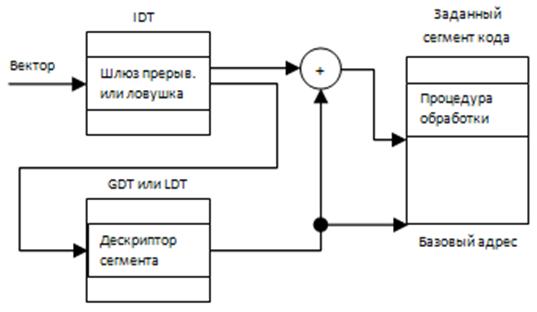
GTD –глобальная таблица дескрипторов
LTD – локальная таблица прерываний
Кроме адреса обработчика нужно знать причину: она может передаваться через регистр (так можно определить процедуру обработки).
16)Прерывания в IA – 32, IA – 64.
Возврат зависит от того, на каком уровне обрабатывалось прерывание.
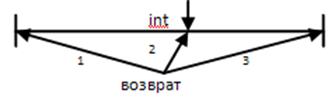
1. Возврат с перезапуском
2. С продолжением
3. С подавлением
Возврат с подавлением используется редко (не используется при обычных прерываниях) Если в программе пользователя есть привилегированные операции (например в машинах разделения времени – физ. I/O) то возврат с подавлением.
Intel – использует возврат с перезапуском;
Motorolla 68K – с подавлением.
В перезапуске есть одна тонкость – нужен спец анализ на вид прерывания: внешнее или внутреннее. Надо учитывать точку возврата. Если содержимое регистров не изменилось, то возврат с перезапуском возможен, если изменилось то нет.
При микро прерывании надо запомнить адрес новой МК (вых SEQ, МПП)
Если INT на уровне команд, то нужно запомнить
1. указатель команд (IP)
2. Длина команды (той кот была прервана) нужна, при «возврате с перезапуском», т. к. адрес след МК операции генерир. 1, 2 такта.
3. Триггер работа-остановка (остановка – выполнение пустой программы)
4. Маска прерывания
5. Информация о распределении и защите памяти
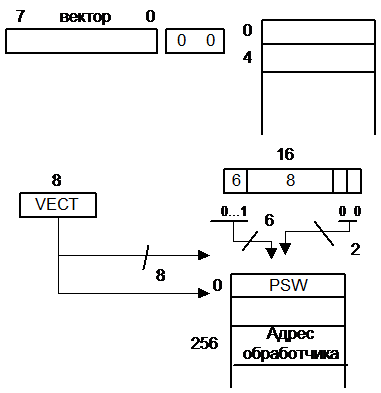
Это все оформляется как слово состояния процессора (ССП, PSW). В начале прерывания запомним ССП, а обработчик запоминает всю остальную инф-ию, которая нужна.
1.1Если ССП запоминается в ОП, то в ячейке с фиксированными адресами.
VECT à адрес à CCП
àадрес обработчика
0……..0 | V ect | - адрес, где ССП |
0……..1 | V ect | - адрес обработчика |
1 байт
Недостаток: повторное прерывание от одного обработчика запрещено, т. к. ССП будет потеряно
2.1 Адреса обработчика и ССП не связаны между собой, ССП помещается в стек, vect à адрес обработчика
Достоинство: Может рассматриваться и повторное прерывание по одному и тому же вектору.
Запоминание PSW (слово состояние программы).
1.2 В ОП памяти. Для формирования адресов используется вектор прерывания.
Существует таблица PSW «старых» и «новых» программ.
Недостатки:
Нет возможности вложенных прерываний по одному вектору
Неперемещаемость таблиц (можно исправить).
2.2 Использование стека.
Прерывания IA-32
Аппаратные прерывания
 Процессор определяет необходимость обработки внешнего прерывания по наличию сигнала на одном из контактов INTR# или NMI#. При появлении сигнала на линии INTR# внешний контроллер прерываний (например, 8259A) должен предоставить процессору вектор (номер) прерывания. С линией NMI# всегда связано прерывание с номером 2. В процессорах Pentium+ эти линии могут быть сконфигурированы на использование APIC (Advanced Programmable Interrupt Controller), тогда они называются LINT0 и LINT1 и информация по ним передается в виде сообщений в специальном формате.
Процессор определяет необходимость обработки внешнего прерывания по наличию сигнала на одном из контактов INTR# или NMI#. При появлении сигнала на линии INTR# внешний контроллер прерываний (например, 8259A) должен предоставить процессору вектор (номер) прерывания. С линией NMI# всегда связано прерывание с номером 2. В процессорах Pentium+ эти линии могут быть сконфигурированы на использование APIC (Advanced Programmable Interrupt Controller), тогда они называются LINT0 и LINT1 и информация по ним передается в виде сообщений в специальном формате.
Следует отметить, что появление сигналов на некоторых других контактах процессора также прерывает работу процессора. Однако обработка этих событий отличается от механизма обработки прерываний и исключений, описываемого в этом разделе. К таким сигналам относятся: RESET# и INIT# (аппаратный сброс), SMI# (переход в режим системного управления) и некоторые другие.
Прерывания, которые генерируются при поступлении сигнала на вход INTR#, называют маскируемыми аппаратными прерываниями. Бит IF в регистре флагов позволяет заблокировать (замаскировать) обработку таких прерываний.
Прерывания, генерируемые сигналом NMI#, называют немаскируемыми аппаратными прерываниями. В процессорах Pentium+ немаскируемое прерывание может быть сгенерировано при получении специального сообщения по шине APIC. Немаскируемые прерывания не блокируются флагом IF. Пока выполняется обработчик немаскируемого прерывания процессор блокирует получение немаскируемых прерываний до выполнения инструкции IRET, чтобы исключить одновременную обработку нескольких немаскируемых прерываний. Рекомендуется вызывать этот обработчик через шлюз прерывания, тогда на время его выполнения будут также заблокированы маскируемые прерывания.
Прерывания всегда обрабатываются на границе инструкций, т. е. при появлении сигнала на контакте INTR# или NMI# процессор сначала завершит выполняемую в данный момент инструкцию (или итерацию при наличии префикса повторения), а только потом начнет обрабатывать прерывание. Помещаемый в стек обработчика адрес очередной инструкции позволяет корректно возобновить выполнение прерванной программы.
Несмотря на возможность спекулятивного выполнения, присущую архитектуре P6+, в прерванной программе сохраняется порядок выполнения инструкций, заложенный программистом. Это обеспечивается механизмом "отката" (retirement phase).
Программные прерывания
С помощью инструкции INT n (n - номер прерывания) можно сгенерировать прерывание с любым номером 0...255. Такие прерывания называют программными. Состояние бита IF в регистре флагов не влияет на возможность генерации программных прерываний.
Хотя номер прерывания в этой инструкции может быть любым, следует отметить, что, например, при использовании вектора 2 для вызова обработчика немаскируемого  прерывания внутреннее состояние процессора будет отличаться от того, которое бывает при обработке аппаратного немаскируемого прерывания. Аналогично, попытка вызвать обработчик исключения с помощью этой инструкции может оказаться неудачной, т. к. при возникновении большинства исключений в стек включается код ошибки, а при генерации программного прерывания этого не происходит. Обработчик исключения извлекает из стека код ошибки, а в случае программного прерывания из стека будет ошибочно извлечен адрес возврата, что нарушит целостность стека и в конечном итоге, скорее всего, приведет к исключению
прерывания внутреннее состояние процессора будет отличаться от того, которое бывает при обработке аппаратного немаскируемого прерывания. Аналогично, попытка вызвать обработчик исключения с помощью этой инструкции может оказаться неудачной, т. к. при возникновении большинства исключений в стек включается код ошибки, а при генерации программного прерывания этого не происходит. Обработчик исключения извлекает из стека код ошибки, а в случае программного прерывания из стека будет ошибочно извлечен адрес возврата, что нарушит целостность стека и в конечном итоге, скорее всего, приведет к исключению
Прерывания IA-64
При прерывании в IA-64 выдача исключений последовательная.
Аналогично IA-32 прерывания в IA-64 делятся на 4 типа:
1. Авария (Abort) - жесткий сброс от схем контроля
2. Ошибка (Fault) - возникает до завершения инструкции
3. Ловушка (Trap) - возникает после завершения инструкции
4. Прерывание (Interrupt) - асинхронные внешние события (от периферии или платформы). "Мягкий сброс".
К уровню платформы относятся прерывания от схем контроля, но возникшую ошибку можно исправить.
 IIP - специальный управляющий регистр, используемый при прерывании. В нем сохраняется на время обработки прерывания состояние указателя IP. Помимо IIP существуют другие регистры для аналогичных целей (IPSR для PSR и т. д.)
IIP - специальный управляющий регистр, используемый при прерывании. В нем сохраняется на время обработки прерывания состояние указателя IP. Помимо IIP существуют другие регистры для аналогичных целей (IPSR для PSR и т. д.)
Исполнялась инструкция А, исполнялась инструкция B. Реакция не прерывание:
:
Исполняется инструкция Х обработчика прерываний, Y. Восстановление состояния RFI:
Далее исполняется инструкция В.
1. Вначале при прерывании происходит переключение с банка регистров прикладной программы к банку регистров ОС.
2. ОС вызывает процедуры обработчиков прерываний.
3. Происходит возврат и переключение банков регистров в исходное состояние.
Прерывания в Itanium делятся на 2 типа:
1. IVA-based - обрабатываемые по вектору
2. PAL-based - уровень абстракции платформы
Преррывания 2 типа обрабатываются внутрикристальными средствами. Микропрограммный обработчик может и несообщить ОС о возникшем прерывании. "Процессор живет своей жизнью".
17) Приоритетное обслуживание прерываний
Первый вопрос, который стоит обсудить, как установить порядок выполнения между прерываниями, если одновременно их пришло несколько? Ответ прост: нужно установить приоритеты. Приоритеты подразделяют на два класса:
· Приоритеты между запросами, которые устанавливают дисциплину обслуживания для запросов пришедших в один момент времени, в течений времени реакции.
· Приоритеты текущей программы – отвечают на вопрос: можно ли прерывать программу? Данный механизм реализуется при помощи маски.
Теперь рассмотрим структуры систем прерываний:
1. Цепочечная структура:
Основной данной структуры, является структура с последовательным опросом.

Как видно, в состав шины управления входит одна линия запросов. Из этого следует, что существует всего одна программа обработки. Она обрабатывает все запросы от устройств и производит их опрос. Внутренние приоритеты устройств входящих устройств равна нумерации устройства. Можно пользоваться следующим правилом: чем выше приоритет тем ближе к ЦП находится устройство. Представленную структуру часто называют «структурой с программной обработкой». Можно рассмотреть модернизированную версию этой структуры.
2. Цепочечная структура с линией подтверждения INTA.
В схему, приведённую выше, нудно добавить однобитовую линию, как показано на рисунке:
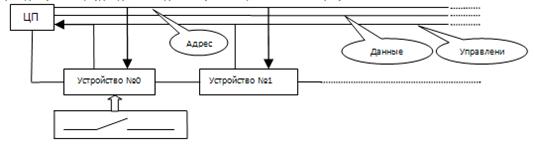
Идея введения линии INTA следующая: если устройство выставляет запрос, то оно разрывает линию подтверждения INTA (обратите внимание на ключ, который ассоциирован с устройством). То есть устройство размыкает цепь и посылает запрос в ЦП. ЦП организует проверку, на предмет, какое из устройств находиться в разомкнутом состоянии. Если несколько устройств находятся в разомкнутом состояний, то они будут выполняться в порядке своего подключения
Рассмотрим некоторые определения необходимые для понимания дальнейшего материала.
Вектор прерывания – идентификатор источника запроса прерывания. В качестве источника прерывания может выступать, к примеру, схема или ПЗУ. Можно дать ещё одно определение вектора прерывания. Вектор – косвенный адрес обработчика прерываний. Этот адрес передаётся по шине данных, так как это единственная двух направленная шина. Этот адрес является адресом в таблице обработчиков прерывания.
Возможны конфликты векторов, это возникает в случае, если вектора различных устройств используют одинаковые коды прерываний.
3.Структура с индивидуальными линиями запроса (радиальная структура).
В этой структуре сколько устройств столько линий запроса прерывании и по идей столько входов должен иметь процессор.
Такая структура требует наличия устройства - контроллера прерываний (PIC). PIC имеет индивидуальный вход для каждого запроса. Формирует 1 бит запроса прерывания и вектор.

PIC может быть встроен в ЦП.
Схема формирования вектора:
1. В простейшем случае там стоит счётчик, который последовательно опрашивает все входы и при достижении искомого входа, содержимое счётчика есть вектор.
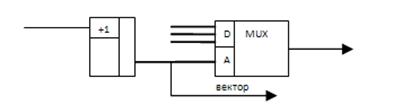
2. Система с жёсткими приоритетами (приоритетный шифратор):
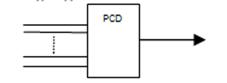
Приоритет устанавливаются порядками подключения устройств к PCD. Если на схеме сигнал с 0-вым приоритетом, то остальные игнорируются, аналогично, если на входе i-ый сигнал, то сигналы от [i+1,n] отбрасываются.
18)Понятие слова состояния программы (ССП), структура ССП. Методы запоминания и восстановления ССП.
Состоянием процессора (программы) после данного такта или после выполнения данной команды, строго говоря, следует считать совокупность состояний в соответствующий момент времени всех запоминающих элементов устройства – триггеров, регистров, ячеек памяти. Однако не вся эта информация исчезает или искажается при переходе к очередной команде или другой программе. Поэтому из всего многообразия информации о состоянии процессора (программы) отбираются наиболее существенные её элементы, как правило, подверженные изменениям при переходе к другой команде или программе. Совокупность значений этих информационных элементов получила название вектора состояния процессора (программы). ССП в каждый момент времени должен содержать информацию, достаточную для продолжения выполнения программы или повторного пуска программы с точки, соответствующей моменту формирования данного ССП. При этом предполагается, что остальная информация, характеризующая состояние программы, например содержимое регистров, или сохраняется, или может быть восстановлена программным путем по копии, сохраненной в памяти. ССП формируется после выполнения каждой команды в соответствующем регистре.
При обработке на уровне команд сохраняется как мин следующая информация:
1. Указатель команд.(IP)
2. Длина той команды, которая была прервана (в байтах).
3. Состояние триггера «работа-останов».
4. Маска прерываний.
5. Информация о распределении и защите памяти.
Как уже отмечалось, не вся информация исчезает при переходе к другой программе. Это утверждение распространяется и на прерывания. При этом можно организовать запоминание информации так, чтобы обработчик соответствующего прерывания сохранял все необходимое при данном конкретном прерывании (то есть, запоминал только то, что точно изменится в результате обработки прерывания).
Методы запоминания ССП:
1. В ОП ячейках с фиксированными адресами. Vector→Адрес→ССП→Адрес обработчика. Повторное прерывание от одного и того же источника запрещаются, т. к. будет потеряно ССП.
2. В стеке. В любом стеке есть указатель стека. В конце стоит команда перехода по SP. Поэтому условной единицей длины в этом случае будет 1.У этой конструкции нет ограничений, а значит, чаще используется. Глубина прерываний определяется размером стека.
3. В суперЭВМ применяется следующий способ: существует набор блоков регистров, куда переносится вся информация о программе.
19)Назначение, функции структуры контроллеров прерываний. Примеры.
На аппаратном уровне прерывания работают следующим образом. Когда устройство ввода-вывода заканчивает работу, оно инициирует прерывание (при условии, что прерывания разрешены ОС). Для этого устройство выставляет сигнал на выделенную устройству специальную линию шины – линия запроса. В структуре системы прерываний «с индивидуальными линиями запроса» (радиальная структура) сколько устройств, столько и линий запроса прерываний, а значит нужно, чтобы процессор должен иметь столько же входов запроса прерываний. На практике поступают так: между линиями запроса и процессором есть промежуточное звено – контроллер прерываний (сокращение PIC). Его назначение в следующем: он должен формировать для процессора 1 бит запроса прерывания INT и Vector. PIC имеет индивидуальный вход для каждой линии запроса.

PIC (контроллер) может быть встроен в процессор.
Функции контроллера.
· запоминание запросов
· формирование сигнала INT
· формирование запрета прерываний
· маскирование прерываний – то есть запрет обработки некоторых запросов. Пример схемной реализации:
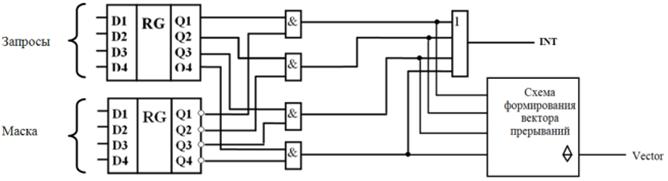
· формирование Vector
· прием подтверждений о том, что CPU обработал прерывание
По способам опроса устройств можно выделить следующие структуры контроллеров:
1) Последовательный опрос – счетчик непрерывно считает и последовательно опрашивает устройства (в качестве счетчика может быть регистр сдвига, в котором по кругу бегает «1»). Реализует «круговую систему приоритетов».
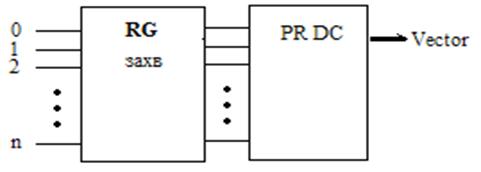
2) Приоритетный опрос – система с жесткими приоритетами. Требует приоритетный шифратор (PR DC). Приоритеты устанавливаются порядком подключения устройств к контроллеру.
20)Классификация, характеристики запоминающих устройств. Структура памяти ЭВМ.
Память ЭВМ имеет иерархическую структуру. Это связано с противоречивыми требованиями предъявляемыми к памяти. Увеличивая объём мы уменьшаем быстродействие (скорость доступа), и наоборот, увеличивая скорость мы уменьшаем её объём.
Рассмотрим набор требований предъявляемых к ЗУ:
· Быстродействие - память не должна тормозить ЦП.
· Энергонезависимость.
· Стоимость – необходимо ввести перерасчёт памяти представив её в единицах условных на бит.
· Радиационная стойкость.
· Большой объём.
Иерархическая организация памяти позволяет наращивать её объём путём введения новых уровней в иерархии, но каждый новый уровень требует дополнительного управления, а следовательно дополнительные ресурсы ЦП.
Рассмотрим иерархию ЗУ:
1. Регистры.
2. СОЗУ (Кэш L1).
3. СОЗУ (Кэш L2 и L3).
4. ОЗУ
5. Дисковая КЭШ память
6. Магнитные диски RAID
7. Оптические диски.
8. Магнитная лента.
В данной иерархии память классифицирована (расположена в порядке) сверху вниз увеличению ёмкости, но уменьшению быстродействия.
Для дальнейшего рассуждения нам понадобиться ввести несколько дополнительных определений:
· Произвольный доступ к памяти – доступ к памяти, при котором время поиска не зависит от положения информации, то есть остаётся постоянным. Таким типом доступа обладают регистры, СОЗУ, ОЗУ, дисковая кэш-память.
· Прямой доступ к памяти (DAM – Direct Access Memory) – время поиска меняется от минимального до максимального значения. Также этот вид доступа называется циклическим (применяется для организации поиска на жёстком диске). Среднее время доступа можно оценить как время полуоборот диска носителя.
· Последовательный доступ - возможен только последовательный доступ к ячейкам памяти. Используется в оптических дисках и магнитных лентах.
· Ассоциативная память – поиск нужного блока или ячейки осуществляется не по адресу, а по признаку. Ассоциативный поиск реализован аппаратно (примером ассоциативной памяти является КЭШ).
· Динамическая память – память движется относительно запоминающей среды (примером такой памяти является ЦМД – цилиндрические запоминающие домены).
Классификация:
1. Физическая природа элементов, хранящих информацию. (Наиболее известные: полупроводники, магнитная поверхность, оптические.)
2. По характеру участия в вычислительных процессах
- внешние
- основные
- оперативные
- сверхоперативные
3. По способу доступа к единицам информации
- с последовательным доступом (магнитная лента)
- с прямым доступом (HDD)
- с произвольным доступом
Сверх ОП как с произвольным так и с последовательным доступом.
4. По способу поиска информации
- адресные ЗУ
- безадресные ЗУ (стек и ассоциативные ЗУ)
5. По кратности записи информации
- с перезаписью
- без перезаписи
21)Способы организации оперативной памяти ЭВМ.
1-й способ: Массив ячеек (плохой вариант)
Преимущества:
· Можно делать память переменного объема
· Можно выиграть на времени дешифрации адреса
Недостатки:
· Большие затраты на поиск свободного пространства при фрагментации
· Ненадежная (при физическом повреждении полностью выходит из строя)
· Дорогая при производстве (при больших объемах памяти)
2-й способ: Многоблочная
Преимущества:
· Можно организовать параллельную работу блоков
· Надежная (при физическом повреждении блока другие блоки продолжают работать)
· Дешевле при производстве (при больших объемах памяти)
· Защита от несанкционированного выхода программы за выделенный блок.
Недостатки:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
