
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
· Затраты на дешифрацию адреса

Помимо податливости к наращиванию емкости, блочное построение памяти обладает еще одним достоинством — позволяет сократить время доступа к информации. Это возможно благодаря потенциальному параллелизму, присущему блочной организации. Большей скорости доступа можно достичь за счет одновременного доступа ко многим банкам памяти. Одна из используемых для этого методик называется расслоением памяти. В ее основе лежит так называемое чередование адресов (address interleaving), заключающееся в изменении системы распределения адресов между банками памяти.
У каждого блока есть два регистра: RGA (регистр адреса, который хранит адрес в блоке) и RGD (регистр данных, который хранит либо результат чтения, либо данные для записи). Адрес ячейки запоминается в индивидуальном регистре адреса, и дальнейшие операции по доступу к ячейке в каждом блоке протекают независимо. При большом количестве блоков среднее время доступа к ОП сокращается почти в В раз (В — количество блоков), но при условии, что ячейки, к которым производится последовательное обращение относятся к разным блокам. Если же запросы к одному и тому же блоку следуют друг за другом, каждый следующий запрос должен ожидать завершения обслуживания предыдущего. Такая ситуация называется конфликтом по доступу. При частом возникновении конфликтов по доступу метод становится неэффективным.
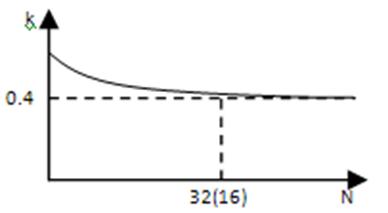
Коэффициент расслоения – количество адресов, которое ОП может принять без задержки
Относительный коэффициент расслоения = коэффициент расслоения / количество блоков
22)Назначение, структурная организация КЭШ-памяти. Место КЭШа в структуре процессора.
Кэш-память – статическая память (а значит дорогая: в 10 раз дороже динамической и в 10 раз быстрее + более энергопотребляемая), внутренняя память CPU (а значит расположена близко к нему). В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий элемент динамического ОЗУ способен хранить информацию только в течение достаточно короткого промежутка времени, после которого информацию нужно восстанавливать заново, иначе она будет потеряна. Динамические ЗУ, как и статические, энергозависимы. Роль запоминающего элемента в статическом ОЗУ исполняет триггер. Запоминающий элемент динамической памяти значительно проще. Он состоит из одного конденсатора и запирающего транзистора.
Кэш память имеет малый объем. Состоит из нескольких уровней: 1, 2, 3 (часто говорят и о 4-ом) по технологическим причинам: производители просто добавляют новые уровни кэша в кристалл, а не наращивают его объем в имеющихся уровнях + более объемный кэш еще дороже. НО: несколько уровней сложнее в пользовании + нагрев платы (а значит снижение частоты). Среди плюсов многоуровневой организации – живучесть.
Кэш никогда не подключается к системной шине, только к локальным шинам. Это обеспечивает большую производительность, но возникает проблема в охлаждении. Она не увеличивает общий объем памяти компьютера (что верно на 99%).
Пока динамическая память существенно дешевле статической кэш будет жить в компьютерах. Однако, если просто заменить динамическую память на статическую, то быстродействие не прыгнет вверх, что обусловлено ограничениями накладываемыми архитектурой компьютера: системная шина – частота и пропускная способность. Одна из главных характеристик кэша – вероятность удачного обращения (емкость кэша << емкости ОП). Часть ОП перемещается в кэш. Сейчас вероятность удачного обращения доходит до 95%. Различают вероятности удачного обращения по записи и по чтению (и соответствующие эффективности). При чтении нужно обратиться сначала в кэш, если там информации нет, то обращаемся в ОП. При этом нужно обязательно записать в считанное в кэш. Исходя из выше сказанного можно вычислить эффективное время чтения информации:
![]()
Эта формула не совсем точна: так как можно параллельно считывать и из ОП, и из кэша (если из кэша – удачно, то запрос в ОП - блокируем).
Сейчас он достигает 3.92.
Существует 2 вида реализации кэша:
1) Фон-неймановская – кэш данных и кода объединены (более экономически выгодно).
2) Гарвардская - кэш данных и кода разделены. (а может быть и так: кэша кода мало, а кэш данных – не используется => надо исходить из тех задач, которые будут ставиться перед ВМ).
Информация в кэше хранится блоками. Размер блока – 4 или 8 слов (чаще 4). На размер блока влияет несколько факторов. С одной роны, чем больше блок, тем выше вероятность удачного обращения, но как только происходит ветвление или безусловный переход, то получаем издержки. То есть чем больше блок, тем больше вероятность того, что блок придется менять. Кроме того, есть ограничения по размеру блока: с увеличением его размера увеличивается количество шин для чтения/записи. Возможен компромисс: блочная передача – механизм передачи в последовательности адрес – данные – данные – данные – … – конец блока.
Кроме кэша команд и данных существует адресный кэш: он хранит адресную информацию отдельными словами (не машинными, а «адресными»). Буфер TLB – буфер быстрого преобразования адреса – это и есть организация адресного кэша.
Кэш – ассоциативная память, где в качестве тега используется адрес, то есть адрес – ключ, а вместе с ним хранятся данные.
Способы отображения памяти:
1. полностью ассоциативного кэш.
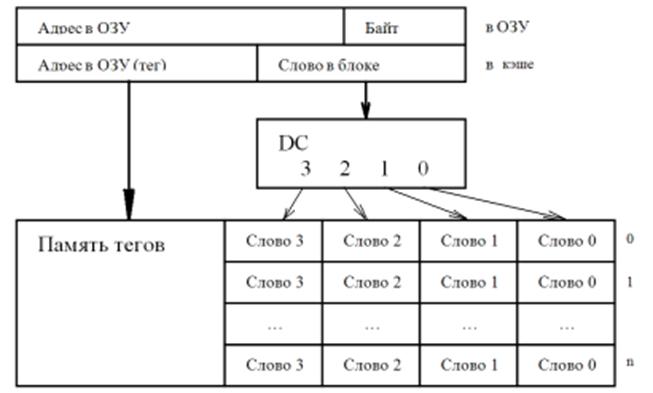
2. Кэш с прямым отображением в памяти.
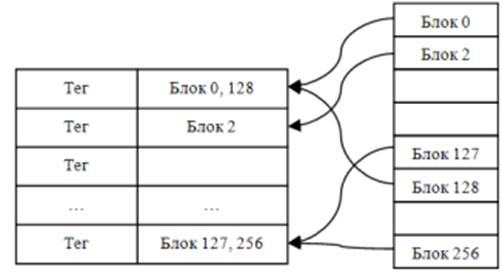
Во втором случае адрес в кэше должен быть таким:

Чем больше разрядов под индекс (#блока), тем больше блоков то есть под индекс много разрядов не надо. Поиск идет так: тег → перебираются блоки. Структура кэш-памяти с прямым отображением в памяти в режиме чтения:
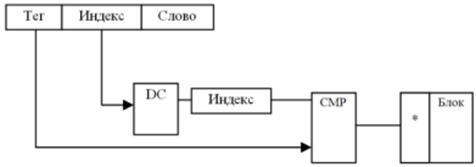
Минус такого подхода: один единственный блок из множества отображаемых, хранится в кэше, остальные недоступны, так как на входе один индекс, а значит вероятность удачного обращения много меньше, чем в остальных подходах.
Место кэша в структуре CPU:
1 – устройство преобразования виртуальных адресов
2 – кэш
1.
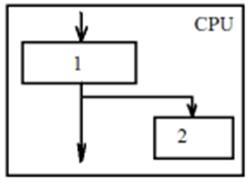
· Кэш работает с физическими адресами
· Медленно, поскольку тратится время на преобразование адреса
· При прерываниях или переключениях программ не надо отменять содержимое кэша, так как физические адреса в разных программах не могут совпадать. После возврата старая информация может сохраниться
2.

· Кэш работает с виртуальными адресами
· Быстро, поскольку не тратится время на преобразование адреса
· При прерываниях или переключениях программ необходимо отменять содержимое кэша, так как виртуальные адреса в разных программах могут совпадать.
23)Алгоритмы свопинга и замещения информации в КЭШе.
Запись в кэш-память может быть осуществлена из двух источников:
· Из процессора.
· Из ОП.
Запись в кэш со стороны процессора осуществляется в случае, если необходимо модифицировать данные, которые уже содержатся в кэше. С другой стороны, если процессор не нашёл необходимых данных в кэше, то идёт обращение к ОП, с последующей записью информации из оперативной памяти в кэш (что и объясняет наличие второго источника).
В момент, когда кэш заполнится, необходимо выбрать кандидата на замещение. Основная цель стратегии замещения — удерживать в кэш-памяти строки, которым наиболее вероятны обращения в ближайшем будущем, и заменять строки, доступ к которым произойдет в более отдаленном времени или вообще не случится.
Наиболее эффективным является алгоритм замещения на основе наиболее давнего использования (LRU — Least Recently Used), при котором замещается та строка кэш-памяти, к которой дольше всего не было обращения. Наиболее известны три способа аппаратурной реализации этого алгоритма. В первом из них с каждой строкой кэш-памяти ассоциируют счетчик. К содержимому всех счетчиков через определенные интервалы времени добавляется единица. При обращении к строке ее счетчик обнуляется. Таким образом, наибольшее число будет в счетчике той строки, к которой дольше всего не было обращений, и эта строка — первый кандидат на замещение. Второй способ реализуется с помощью очереди, куда в порядке заполнения строк кэш-памяти заносятся ссылки на эти строки. При каждом обращении к строке ссылка на нее перемещается в конец очереди. В итоге первой в очереди каждый раз оказывается ссылка на строку, к которой дольше всего не было обращений. Именно эта строка прежде всего и заменяется. Оба способа дают наиболее адекватную оценку, но цена этому является привлечения большого количества дополнительной памяти (либо на хранение счётчиков, либо на поддержание и хранение очереди). Последний вариант, даёт приближённую оценку, но крайне не требовательный с точки зрения памяти. Он заключается в том, что с каждой записью ассоциировано два бита, обозначим их W и A. Бит W, будем называть битом когерентности с ОП. Изначально бит W устанавливается в 0. Как только процессор модифицирует в ассоциированные с флагом данные, то этот бит устанавливается в 1. Использование бита W позволяет выявить те слова в кэше, которые не были модифицированы процессором, а следовательно и копирования их в ОП, при замещении блоков не требуется. Этот подход является основой для алгоритма флаговой обратной записи, рассмотренного ниже. Бит А, устанавливается в 1, как только происходит обращение к блоку. Причем как только биты А, всех блоков установлены в 1, то все они сбрасываются на 0, кроме того, который инициировал данное событие. Замещение идёт в блок, у которого A и W установлены в 0. То есть обращения к данному блоку со стороны процессора не было после копирования блока в кэш. В случае если таких флагом нет, то алгоритмически выгодно, выбрать блоки с битом W установленным в 0. Так как при этом не нужно будет обновлять данные в ОП. Как видно третий случай самый экономичный с точки зрения памяти, но даёт результат менее адекватный по отношению к предыдущим случаям. То есть может произойти замена блока, к которому часто происходят запросы на операцию чтения, но его биты A и W установлены в 0.
Другой возможный алгоритм замещения — алгоритм, работающий по принципу «первый вошел, первый вышел» (FIFO — First In First Out). Здесь заменяется строка, дольше всего находившаяся в кэш-памяти. Алгоритм легко реализуется с помощью рассмотренной ранее очереди, с той лишь разницей, что после обращения к строке положение соответствующей ссылки в очереди не меняется.
Еще один алгоритм — замена наименее часто использовавшейся строки (Lr и Least Frequently Used). Заменяется та строка в кэш-памяти, к которой было меньше всего обращений. Принцип можно воплотить на практике, связав каждую строку со счетчиком обращений, к содержимому которого после каждого обращения добавляется единица. Главным претендентом на замещение является строка, счетчик которой содержит наименьшее число.
Простейший алгоритм — произвольный выбор строки для замены. Замещаемая строка выбирается случайным образом. Реализовано это может быть, например с помощью счетчика, содержимое которого увеличивается на единицу с каждым тактовым импульсом, вне зависимости от того, имело место попадание или промах. Значение в счетчике определяет заменяемую строку в полностью ассоциативной кэш-памяти или строку в пределах модуля для множественно-ассоциативной кэш-памяти. Данный алгоритм используется крайне редко. Среди известных в настоящее время систем с кэш-памятью наиболее встречаемым является алгоритм LRU.
Как было сказано, в процессе вычислений ЦП может не только считывать имеющуюся информацию, но и записывать новую, обновляя тем самым содержимое кэш-памяти. С другой стороны, многие устройства ввода/вывода умеют напрямую обмениваться информацией с основной памятью. В обоих вариантах возникает ситуация, когда содержимое строки кэша и соответствующего блока ОП перестает совпадать. В результате на связанное с основной памятью устройство вывода может быть выдана «устаревшая» информация, поскольку все изменения в ней, сделанные процессором фиксируются только в кэш-памяти, а процессор будет использовать старое содержимое кэш-памяти вместо новых данных, загруженных в ОП из устройства ввода.
Для разрешения первой из рассмотренных ситуаций (когда процессор выполняет операцию записи) в системах с кэш-памятью предусмотрены методы обновления основной памяти, которые можно разбить на две большие группы: метод сквозной записи (write through) и метод обратной записи (write back).
По методу сквозной записи прежде всего обновляется слово, хранящееся в основной памяти. Если в кэш-памяти существует копия этого слова, то она также обновляется. Если же в кэш-памяти отсутствует нужная копия, то либо из основной памяти в кэш-память пересылается блок, содержащий обновленное слово (сквозная запись с отображением), либо этого не делается (сквозная запись без отображения).
Главное достоинство метода сквозной записи состоит в том, что когда строка в кэш-памяти назначается для хранения другого блока, то удаляемый блок можно не возвращать в основную память, поскольку его копия там уже имеется. Метод достаточно прост в реализации. К сожалению, эффект от использования кэш-памяти (сокращение времени доступа) в отношении к операциям записи здесь отсутствует.
Определенный выигрыш дает его модификация, известная как метод буферированной сквозной записи. Информация сначала записывается в кэш-память и в специальный буфер, работающий по схеме FIFO. Запись в основную память производится уже из буфера, а процессор, не дожидаясь ее окончания, может сразу же продолжать свою работу. Конечно, соответствующая логика управления должна заботиться о том, чтобы своевременно «опустошать» заполненный буфер. При использовании буферизации процессор полностью освобождается от работы с ОП. Согласно методу обратной записи, слово заносится только в кэш-память. Если соответствующей строки в кэш-памяти нет, то нужный блок сначала пересылается из ОП, после чего запись все равно выполняется исключительно в кэш-память, При замещении строки ее необходимо предварительно переслать в соответствующее место основной памяти. Для метода обратной записи, в отличие от алгоритма сквозной записи, характерно то, что при каждом чтении из основной памяти осуществляются две пересылки между основной и кэш-памятью. У рассматриваемого метода есть разновидность — метод флаговой обратной записи. Когда в какой-то строке кэша производится изменение, устанавливается связанный с этой строкой бит изменения A (флажок). При замещении строка из кэш - памяти переписывается в ОП только тогда, когда ее флажок установлен в 1. Ясно, что эффективность флаговой обратной записи несколько выше. Таким образом, первым кандидатом на замещения являются блоки у которых бит активности установлен в 0, так как не требуется копирования содержимого КЭШа в ОП.
Теперь рассмотрим ситуацию, когда в основную память из устройства ввода минуя процессор, заносится новая информация и неверной становится копия, хранящаяся в кэш-памяти. Предотвратить подобную несогласованность позволяют два приема. В первом случае система строится так, чтобы ввод любой информации в ОП автоматически сопровождался соответствующими изменениями в кэш-памяти. Для второго подхода «прямой» доступ к основной памяти допускается только через кэш-память.
24)Страничная организация памяти. Организация, хранение, использование страничных таблиц. Стратегия замещения страниц.
В современных схемах управления памятью не принято размещать процесс в оперативной памяти одним непрерывным блоком.
В самом простом и наиболее распространенном случае страничной организации памяти (или paging) как логическое адресное пространство, так и физическое представляются состоящими из наборов блоков или страниц одинакового размера. При этом образуются логические страницы (page), а соответствующие единицы в физической памяти называют физическими страницами или страничными кадрами (page frames). Страницы (и страничные кадры) имеют фиксированную длину, обычно являющуюся степенью числа 2, и не могут перекрываться. Каждый кадр содержит одну страницу данных. При такой организации внешняя фрагментация отсутствует, а потери из-за внутренней фрагментации, поскольку процесс занимает целое число страниц, ограничены частью последней страницы процесса.
Логический адрес в страничной системе – упорядоченная пара (p, d), где p – номер страницы в виртуальной памяти, а d – смещение в рамках страницы p, на которой размещается адресуемый элемент. Заметим, что разбиение адресного пространства на страницы осуществляется вычислительной системой незаметно для программиста. Поэтому адрес является двумерным лишь с точки зрения операционной системы, а с точки зрения программиста адресное пространство процесса остается линейным.
Описываемая схема позволяет загрузить процесс, даже если нет непрерывной области кадров, достаточной для размещения процесса целиком. Но одного базового регистра для осуществления трансляции адреса в данной схеме недостаточно. Система отображения логических адресов в физические сводится к системе отображения логических страниц в физические и представляет собой таблицу страниц, которая хранится в оперативной памяти. Иногда говорят, что таблица страниц – это кусочно-линейная функция отображения, заданная в табличном виде.
Интерпретация логического адреса показана на рисунке Если выполняемый процесс обращается к логическому адресу v = (p, d), механизм отображения ищет номер страницы p в таблице страниц и определяет, что эта страница находится в страничном кадре p', формируя реальный адрес из p' и d.
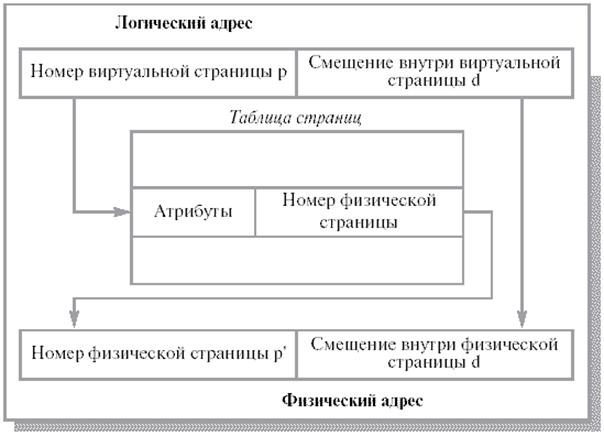
Таблица страниц (page table) адресуется при помощи специального регистра процессора и позволяет определить номер кадра по логическому адресу. Помимо этой основной задачи, при помощи атрибутов, записанных в строке таблицы страниц, можно организовать контроль доступа к конкретной странице и ее защиту.
Отметим еще раз различие точек зрения пользователя и системы на используемую память. С точки зрения пользователя, его память – единое непрерывное пространство, содержащее только одну программу. Реальное отображение скрыто от пользователя и контролируется ОС. Заметим, что процессу пользователя чужая память недоступна. Он не имеет возможности адресовать память за пределами своей таблицы страниц, которая включает только его собственные страницы.
Для управления физической памятью ОС поддерживает структуру таблицы кадров. Она имеет одну запись на каждый физический кадр, показывающий его состояние.
Отображение адресов должно быть осуществлено корректно даже в сложных случаях и обычно реализуется аппаратно. Для ссылки на таблицу процессов используется специальный регистр. При переключении процессов необходимо найти таблицу страниц нового процесса, указатель на которую входит в контекст процесса.
ИЗ ЛЕКЦИЙ:
Адресное пространство бывает: пользовательское(уровень ОП, вирт. память) и компьютера.
Вирт. АП (ОП) => Физ. АП (ОП и Жест. Диск)
Виртуальная память (ее емкость) – емкость ОП, состоит из емкости всех ЗУ (ОП и HDD)
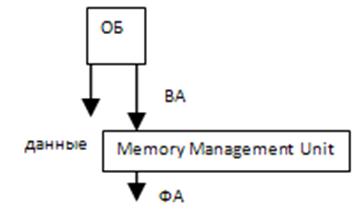
Процессор формирует всегда виртуальные адреса. MMU – устройство управления памятью, преобразующее виртуальные адреса в физические. Механизм виртуальной памяти реализуется через страничную организацию при этом вся память (В и Ф) делится на страницы одного размера. Средние потери при страничной организации ОП на программу – 0,5 страницы. Таблицы страниц могут располагаться: в ОП, но уменьшается производительность из-за частого обращения к ОП, поэтому хранят в кэше.
См. Рис: Атрибут (дескриптор страницы) содержит ее ФА.
Дескриптор страницы – одно слово.
Размер страницы от 1 КБ до 16 КБ (распространен 4 КБ) Чем меньше размер страницы, тем меньше потери памяти, однако больше размер таблицы. Обмен между HDD и ОП происходит страницами. Для каждого процессора дескриптор страницы имеет свой формат, но есть общие свойства: есть бит присутствия P: 1 – если страница в ОП; 0 – если нет
Если P=0, то возникает страничное прерывание. В страничной организации памяти используется TLB – буфер быстрого преобразования адресов, где хранятся дескрипторы страниц, которые загр. в ОП.

У каждой таблицы в дескрипторе хранятся биты: активности, изменения, защиты.
При страничном прерывании необходимо заместить страницу в памяти:
1) Удаляется страница, которая дольше всего находится в ОП
2) Удаляется страница, которая меньше всех находилась в ОП
3) FIFO
LIFO (3 и 4 требуют подсчета времени пребывания в ОП)
25) Странично-сегментная организация памяти. Формирование физических адресов. Особенности сегментно-страничной организация памяти в архитектуре IA – 32..
Для страничной организации в чистом виде существует проблема сложности управления структурами переменного размера, по сути это означает две вещи: полную ответственность программиста за динамические массивы и т. п.; сосуществование стека, кода и данных в одном линейном адресном пространстве влечет опасность конфликтов между ними.
Для сегментной организации в чистом виде существуют проблемы с эффективностью использования памяти:
· Переменный размер сегмента приводит к сильной фрагментации свободного пространства после серий подкачек/откачек. Появляется необходимость периодической дефрагментации.
· Усложнение алгоритмов замещения.
· Размер сегмента может быть очень большим и (на диск)\(с диска) он перемещается полностью.
· При замещении всегда вытесняется равный или больший по размеру сегмент.
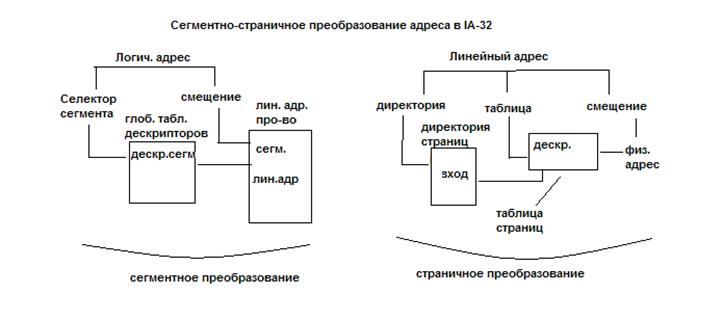
Решением проблемы служит сегментно-страничная организация памяти. В ней размер сегмента выбирается не произвольно, а задается кратным размеру страницы, даже если одна из страниц сегмента заполнена частично. Возникает иерархия в организации доступа к данным, состоящая из трех ступеней: сегмент > страница > слово. Этой структуре соответствует иерархия таблица служащих для перевода виртуальных адресов в физические. В сегментной таблице программы перечисляются все сегменты данной программы с указанием начальных адресов страниц, относящихся к каждому сегменту. Количество страничных таблиц равно числу сегментов и любая из них определяет расположение каждой из страниц сегмента в памяти, которые в общем случае располагаются не подряд а произвольно в физ. памяти, при этом часть страниц может находиться в ОП, остальные — во внешней памяти. Структуру виртуального адреса и процесс преобразования его в физический адрес иллюстрирует рис. 1.

Рис. .1. Преобразование адреса при сегментно-страничной организации памяти
Производительность такой организации ниже в 3 раза (из – за 3х обращений к памяти). Основной + данного метода – при разбиении сегмента на страницы нет нужды загружать в ОП весь сегмент, т. о. программа написанная для большой ОП будет работать и с маленькой, но медленнее.
У Intel используются RG – ы, в которые при обращении к ОП копируется таблица сегментов и страничная таблица, когда её задача становится активной.
Сегментно – страничная организация памяти в МП Intel.
Виртуальная память в Pentium состоит из дескрипторных таблиц LDT и GDT (локальные и глобальная). Каждая программа имеет собственную LDT. GDT разделяется всеми программами. Для доступа к сегменту используется селектор, загруженный в сегментный регистр (CS, DS, SS, ES, GS). В свою очередь селектор сегмента разделен на поля.
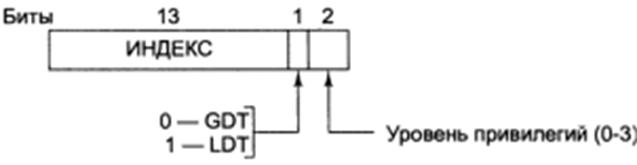
рис.2 селектор Pentium.
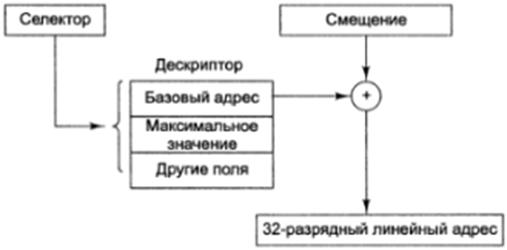
рис 3 Преобразование пары селектор-смещение в линейный адрес.
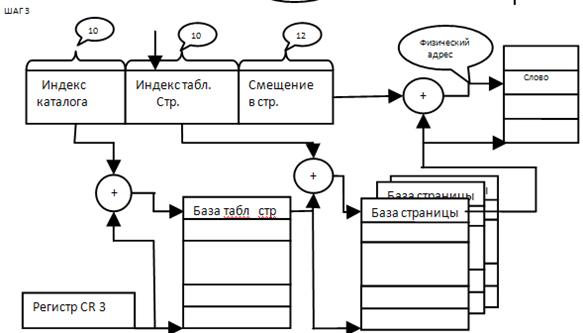
Разбиение сегмента на страницы в intel-процессорах включается установкой специального бита в регистре CR3. если разбиение на страницы включено (сегментно-страничная память) то линейный адрес рассматривается как виртуальный. При этом для сокращения числа дескрипторов (т. к. даже маленькому сегменту придется содержать 1миллион дескрипторов страниц) используют двухуровневое отображение: адрес содержит поля для индексации внутри каталога страниц, внутри таблицы страниц и окончательное смещение адресуемого слова. Каждая программа содержит в специальном регистре адрес каталога страниц (PDE).
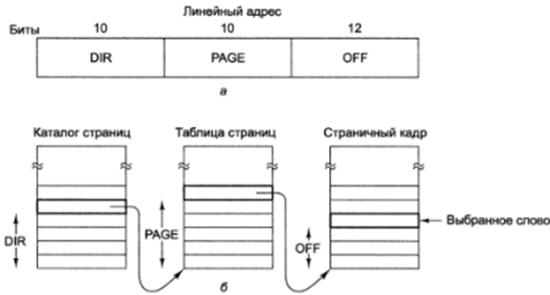
рис 4 Отображение линейного адреса на физический
Элементы каталога страниц содержат указатели на таблицу страниц. Диспетчер памяти Pentium содержит средства для быстрого поиска недавно использовавшихся полей DIR-PAGE.
Поскольку каждая задача может иметь до 16к селекторов (рис 2), а смещение ограничено размером сегмента до 4ГБайт, то логическое адресное пространство может достигать 64 терабайт.
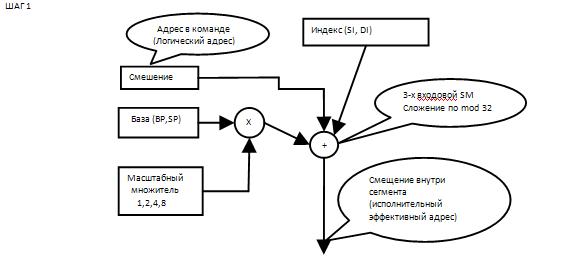
Логический адрес (виртуальный) состоит из адреса сегмента и смещения. Смещение формируется суммированием (Intel Base Displacement Scale 1,2,4,8) – в эффективный адрес.
Линейный адрес образуется сложением базового адреса сегмента с эффективным адресом. Базовый адрес сегмента образуется содержимым используемого селекторного регистра сдвигом на 4 влево реальном режиме.
При включении страничной переадресации она преобразует линейный адрес физическими блоками по 4 Кбайта (у Pentium размер блока может быть и 4Мбайт).
Примечание: см. билет 23. Сегментно-страничная организация памяти в IA-32.
Сегментно-страничная организация памяти в IA
Сегменты, в отличие от страниц, могут иметь переменный размер. Идея сегментации изложена во введении. При сегментной организации виртуальный адрес является двумерным как для программиста, так и для операционной системы, и состоит из двух полей – номера сегмента и смещения внутри сегмента. Подчеркнем, что в отличие от страничной организации, где линейный адрес преобразован в двумерный операционной системой для удобства отображения, здесь двумерность адреса является следствием представления пользователя о процессе не в виде линейного массива байтов, а как набор сегментов переменного размера (данные, код, стек...).
Программисты, пишущие на языках низкого уровня, должны иметь представление о сегментной организации, явным образом меняя значения сегментных регистров (это хорошо видно по текстам программ, написанных на Ассемблере). Логическое адресное пространство – набор сегментов. Каждый сегмент имеет имя, размер и другие параметры (уровень привилегий, разрешенные виды обращений, флаги присутствия). В отличие от страничной схемы, где пользователь задает только один адрес, который разбивается на номер страницы и смещение прозрачным для программиста образом, в сегментной схеме пользователь специфицирует каждый адрес двумя величинами: именем сегмента и смещением.
Каждый сегмент – линейная последовательность адресов, начинающаяся с 0. Максимальный размер сегмента определяется разрядностью процессора (при 32-разрядной адресации это 232 байт или 4 Гбайт). Размер сегмента может меняться динамически (например, сегмент стека). В элементе таблицы сегментов помимо физического адреса начала сегмента обычно содержится и длина сегмента. Если размер смещения в виртуальном адресе выходит за пределы размера сегмента, возникает исключительная ситуация.
Логический адрес – упорядоченная пара v=(s, d), номер сегмента и смещение внутри сегмента.
В системах, где сегменты поддерживаются аппаратно, эти параметры обычно хранятся в таблице дескрипторов сегментов, а программа обращается к этим дескрипторам по номерам-селекторам. При этом в контекст каждого процесса входит набор сегментных регистров, содержащих селекторы текущих сегментов кода, стека, данных и т. д. и определяющих, какие сегменты будут использоваться при разных видах обращений к памяти. Это позволяет процессору уже на аппаратном уровне определять допустимость обращений к памяти, упрощая реализацию защиты информации от повреждения и несанкционированного доступа.
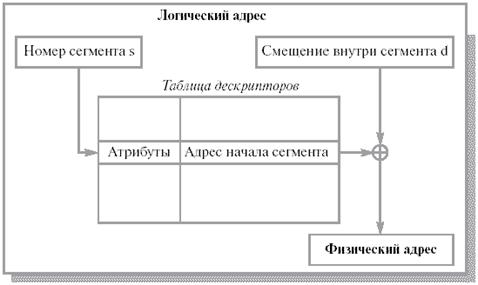
Преобразование логического адреса при сегментной организации памяти
Аппаратная поддержка сегментов распространена мало (главным образом на процессорах Intel). В большинстве ОС сегментация реализуется на уровне, не зависящем от аппаратуры.
Хранить в памяти сегменты большого размера целиком так же неудобно, как и хранить процесс непрерывным блоком. Напрашивается идея разбиения сегментов на страницы. При сегментно-страничной организации памяти происходит двухуровневая трансляция виртуального адреса в физический. В этом случае логический адрес состоит из трех полей: номера сегмента логической памяти, номера страницы внутри сегмента и смещения внутри страницы. Соответственно, используются две таблицы отображения – таблица сегментов, связывающая номер сегмента с таблицей страниц, и отдельная таблица страниц для каждого сегмента.
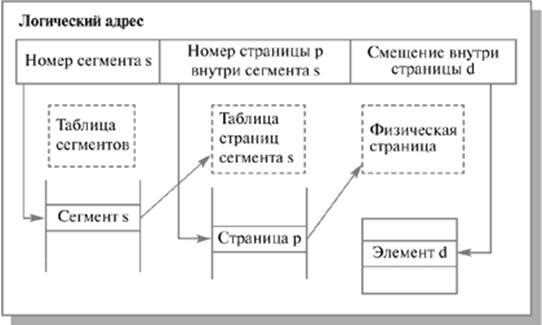
Упрощенная схема формирования физического адреса при сегментно-страничной организации памяти
Сегментно-страничная и страничная организация памяти позволяет легко организовать совместное использование одних и тех же данных и программного кода разными задачами. Для этого различные логические блоки памяти разных процессов отображают в один и тот же блок физической памяти, где размещается разделяемый фрагмент кода или данных.
ИЗ ЛЕКЦИЙ:
Сегментные регистры в IA-32: регистр кода, регистр стека, регистр данных + доп. сегм. для данных
!!!Сегментное преобразование присутствует всегда и отключено быть не может, а страничное может быть отключено.
Формирование адреса в IA-32
1)формирование адреса в ВАП
2)сегментное преобразование
3) страничное преборазование
Сегментно-страничная организация являетя комдинацией двух сегментной и страничной, которые по отдельности обладают своими недостатками. В сегментно-страничная организация памяти размер сегмента выбирается не произвольно, а задается кратным размеру страницы, даже если одна из страниц сегмента заполнена частично. Возникает иерархия в организации доступа к данным, состоящая из трех ступеней: сегмент > страница > слово. Этой структуре соответствует иерархия таблица служащих для перевода виртуальных адресов в физические. В сегментной таблице программы перечисляются все сегменты данной программы с указанием начальных адресов страниц, относящихся к каждому сегменту. Рассмотрим Процесс
Преобразование логического адреса в линейный
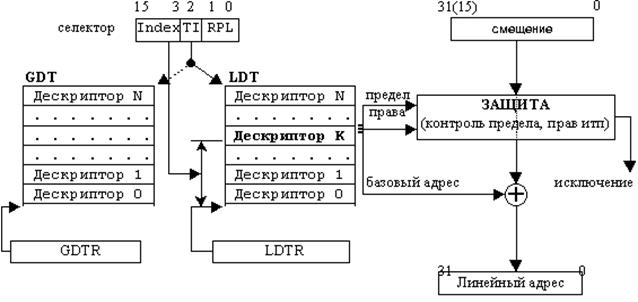
Логический адрес состоит из двух элементов: селектор сегмента и относительный адрес (смещение). Селектор сегмента может либо находиться непосредственно в коде команды, либо в одном из сегментных регистров. Смещение также может либо непосредственно находиться в коде команды, либо вычисляться на основе значений регистров общего назначения.
Для вычисления линейного адреса процессор выполняет следующие действия:
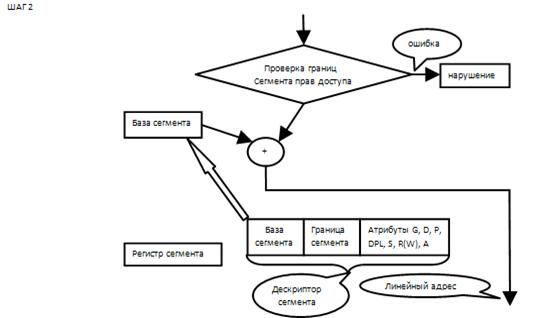
использует селектор сегмента для нахождения дескриптора сегмента;
анализирует дескриптор сегмента, контролируя права доступа (сегмент доступен с текущего уровня привилегий) и предел сегмента (смещение не превышает предел);
добавляет смещение к базовому адресу сегмента и получает линейный адрес.
Если страничная трансляция отключена, то сформированный линейный адрес считается физическим и выставляется на шину процессора для выполнения цикла чтения или записи памяти.
Селектор - это 16-битный идентификатор сегмента. Он содержит индекс дескриптора в дескрипторной таблице, бит определяющий, к какой дескрипторной таблице производится обращение (LDT или GDT), а также запрашиваемые права доступа к сегменту.
Формат селектора:

Index выбирает один из 8192 дескрипторов в таблице дескрипторов. Процессор умножает значение этого индекса на восемь (длину дескриптора) и добавляет результат к базовому адресу таблицы дескрипторов. Таким образом получается линейный адрес требуемого дескриптора.
TI - индикатор таблицы определяет таблицу дескрипторов, на которую ссылается селектор: TI=0 означает глобальную дескрипторную таблицу (GDT), а TI=1 - используемую в настоящий момент локальную дескрипторную таблицу (LDT).
RPL - запрашиваемый уровень привилегий (Requested Privilege Level). Используется механизмом защиты.
Для вычисления линейного адреса используются специальные структуры - дескрипторы. Дескриптор - это 8-байтная единица описательной информации, распознаваемая устройством управления памятью в защищенном режиме, хранящаяся в дескрипторной таблице. Дескриптор сегмента содержит базовый адрес описываемого сегмента, предел сегмента и права доступа к сегменту. В защищенном режиме сегменты могут начинаться с любого линейного адреса (который называется базовым адресом сегмента) и иметь любой предел вплоть до 4Гбайт
Формат дескриптора:
Базовый адрес сегмента (Base Address) определяет место сегмента внутри линейного 4Гбайтного адресного пространства. Процессор объединяет три фрагмента базового адреса для формирования одного 32-разрядного значения.
Предел сегмента (Segment Limit) определяет размер сегмента. Задает максимальное (для сегментов стека - минимальное) смещение в сегменте, обращение по которому не вызывает нарушения общей защиты. Процессор связывает две части поля границы для формирования 20-разрядного результата. Затем он интерпретирует поле границы одним из двух способов в зависимости от состояния бита гранулярности: в единицах байт для определения границы до 1Мбайт (G=0); в единицах страниц по 4Кбайт для определения границы до 4Гбайт (G=1), при загрузке поле границы сдвигается влево на 12 бит и младшие биты выставляются в 1.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
