
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Основные принципы построения ЗВМ.
2. Архитектуры процессоров и их сравнительная оценка. Процессоры CISC, RISC, VLIW, MISC и их особенности.
3. Основные характеристики ЭВМ.
4. Способы организации работы процессоров (последовательный, параллельный, конвейерный и т. д.).
5. Конвейерные структуры процессоров. Конвейер команд.
6. Факторы, снижающие производительность конвейерных структур и методы борьбы с ними.
7. Суперконвейерные, суперскалярные процессоры. Гиперпотоковая технология.
8. Классификация, структуры, функции устройств управления.
9. Структуры команд ЭВМ. Адресность ЭВМ. Место адресного сопроцессора в структуре ЭВМ.
10.Схемно-логические устройства управления, принципы построения.
11.Структура, функционирование микропрограммных устройств управления. Виды микропрограммного управления (МПУ) и их сравнительная оценка.
12.Понятие прерывания программ. Типы прерываний. Характеристики, структуры систем прерываний и их сравнительная оценка.
13.Способы обнаружения запросов, распознавания причин прерывания и способы формирования начального адреса прерывающей программы.
14.Понятие допустимого момента прерывания. Обработка прерываний на уровне команд и на уровне микрокоманд. Схемы. Способы возврата из прерываний
15.Организация вхождения в прерывающую программу. Таблица векторов прерываний.
16.Прерывания в IA – 32, IA – 64.
17.Приоритетное обслуживание прерываний.
18.Понятие слова состояния программы (ССП), структура ССП. Методы запоминания и восстановления ССП.
19.Назначение, функции структуры контроллеров прерываний. Примеры.
20.Классификация, характеристики запоминающих устройств. Структура памяти ЭВМ.
21.Способы организации оперативной памяти ЭВМ.
22.Назначение, структурная организация КЭШ-памяти. Место КЭШа в структуре процессора.
23.Алгоритмы свопинга и замещения информации в КЭШе.
24.Страничная организация памяти. Организация, хранение, использование страничных таблиц. Стратегия замещения страниц.
25.Странично-сегментная организация памяти. Формирование физических адресов. Особенности сегментно-страничной организация памяти в архитектуре IA – 32..
26.Защита информации в ЭВМ. Защита оперативной памяти.
27.Архитектура и виды ввода-вывода в ЭВМ. Способы организации адресного пространства ввода-вывода. Технология plug & play.
28.Программно – управляемый ввод-вывод. Ввод-вывод по прерываниям.
29.Ввод-вывод с прямым доступом к памяти.
30.Структура и функции контроллера ПДП.
31.Сопроцессоры (каналы) ввода–вывода: назначение структуры, режимы работы. Основное отличие сопроцессора ввода–вывода и контроллера ПДП.
32.Принципы организации контроля функционирования ЭВМ. Классификация методов контроля. Контроль оперативной памяти.
33.Аппаратные методы контроля арифметических и логических операций.
34.Интерфейсы ЭВМ и систем. Классификация, основные понятия.
35.Принципы организации интерфейсов, структура связей, функциональная организация.
36.Принципы построения, схемы цифро-аналоговых преобразователей код–напряжение. Факторы, влияющие на погрешность ЦАП.
37.Принципы хранения и размещения информации на магнитных и оптических дисках.
38.Алгоритмы работы, схема аналого-цифровых преобразователей напряжение–код.
1) Основные принципы построения ЗВМ.
В рамках изложения под ЭВМ будем понимать однопроцессорную машину. Многопроцессорную машину будем называть системой.
В основе любого компьютера лежат два основополагающих принципа:
· Принцип микропрограммного управления (принцип Беббиджа – 1833г): управления процессом вычислений осуществляется за счёт алгоритмически организованной последовательности микрокоманд, «зашитых» на уровне оборудования. Суть: автоматизация процесса вычислений.
· Принцип Фон-Неймана (1954г.): организация хранения программы во внутренней памяти машины. Суть: автоматизация управления вычислениями. У Неймана программа храниться в линейном адресном пространстве. Команда и данные с точки зрения хранения в памяти не различимы, то есть хранятся в единой области памяти. На практике этот принцип верен для ОП, но в кэш-памяти существует классификация: кэш-команд и кэш-данных.
Выделим основные составляющие ЭВМ: процессор, подсистема памяти, система ввода-вывода, средства позволяющие объединить ЭВМ (сетевые средства).
В зависимости от способа соединения перечисленных устройств, можно выделить три варианта структуры:
1) Архитектура ввода-вывода:
2) ![]()
2) Архитектура магистрального доступа:
3) Архитектура с разделяемой ОП:

Первый тип организации представляет собой устаревшую модель, так как периферийные устройства (ПУ) обращаются к ОП через запросы к процессору, то появляются дополнительные издержки на управления и организацию работы такой системы. Второй тип организации системы учитывает недостаток предыдущего варианта и предоставляет возможность каждому ПУ обращаться к ОП минуя ЦП посредствам магистрали общего пользования, которую будем называть системной шиной. На рисунке представлен случай, когда каждое устройство имеют различный приоритет. Наивысший приоритет на рисунке имеют ОП, затем следует ПУ 0 и т. д.. Ещё одним достоинством приведённой системы является её открытость, то есть возможность наращивания дополнительных периферийных устройств. Недостатком такой системы является тот факт, что запросы от ПУ обрабатывает сам процессор, что несёт за собой дополнительные временные издержки. Третий случай, учитывает этот недостаток путём введения дополнительного устройства сопроцессора ввода-вывода (СПВВ). Теперь доступ к ОП и вычислительную мощность необходимую для работу ПУ предоставляет СПВВ. Узким местом является системная шина, соединяющая ЦП и ОП, ОП и СПВВ, ЦП и СПВВ. Она достаточно длинная и поддерживать её высокую частоту сложно и дорого. По модели присоединения дополнительных компонентов система также является открытой, а по принципу присоединения ПУ, может быть использовано параллельное соединение (представлено на рисунке) или магистральное (представлено во втором случае).
2)Архитектуры процессоров и их сравнительная оценка. Процессоры CISC, RISC, VLIW, MISC и их особенности.
Рассмотрим составные части ЦП для простейшего случая:
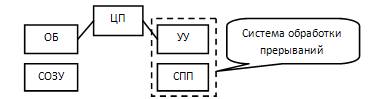
Рассмотрим некоторые составные части приведённой схемы:
· ОБ (Операционный блок) – можно рассматривать как АЛУ(арифметико-логическое устройство)
· УУ (Устройство управления) – организация управления системы.
· СОЗУ(Сверхоперативное запоминающее устройство) – можно рассматривать как набор регистров.
· СПП – система прерываний программы.
По архитектуре системы команд процессоры можно классифицировать следующим образом:
· CISC (Complicated Instruction Set Computer) - компьютер с полным набором команд.
· RISC (Reduced Instruction Set Computer) – компьютер с сокращённым набором команд.
Рассмотрим, более подробно каждую из приведённых архитектур:
1) CISC. Сравнительно небольшое количество регистров использующихся для обработки данных. Команды обработки данных могут иметь формат регистр-память, память-память. При проектировании не накладываются ограничения на время исполнения команд. Переменная длина команд (так как возможен вариант пересылки непосредственно в память). Данную архитектуру имели все первые компьютеры.
2) RISC. Проектирование данной архитектуры велось на базе эффекта 80/20. Данный эффект можно трактовать как примерно 80% команд используют лишь 20% процентов команд процессора CISC типа. Имеется большое количество регистров общего типа РОН. Команды обработки имеют только формат RR. Набор команд должен быть удобен для трансляции с языков высокого уровня. Поскольку команды простые, результат должен вычисляться за один такт (накладывается ограничение на длину команд). Программы транслированные в систему RISC получаются длиннее за счёт ограниченного количества команд. Структуры RISC являются конвейерными, так как многие операции выполняются, к примеру, за один длинный такт можно разделить на короткие такты за счёт конвейера.
Ещё одной из современных архитектур является архитектура IA 64, рассмотрим ей особенности. Во первых, это не RISC, а EPIC (явно выраженный параллелизм при исполнений команд). Основу всего этого в следующем:
· Внутри этого процессора есть мультикристальный компилятор и последовательность выполнения команд происходит не на лету а заранее.
· Это 64-разрядный процессор.
· Команды обработки данных имеют формат RR, в итоге команды короткие и 64 разрядов более чем достаточно. Разработчики взяли 128 разрядов и записали три команды. Такой 128-битовый код будем называть связкой. Связка реализована, как три команды по 41 разряду, и 5 разрядному шаблону. Шаблон определяет расшифровку кода команд, так как одна и та же команда может быть по разному интерпретирована.
Мультикристальный компилятор формирует связки для организации ветвлений и прочих переходов. Также он формирует схемы предикатов (что то вроде блок-схемы выполнения программы), чтобы не выполнять программу на лету.
3)Основные характеристики ЭВМ.
Архитектура ЭВМ - это многоуровневая иерархия аппаратурно-программных средств, из которых строится ЭВМ. Каждый из уровней допускает многовариантное построение и применение. Конкретная реализация уровней определяет особенности структурного построения ЭВМ.
Структуру ЭВМ определяет следующая группа характеристик:
технические и эксплуатационные характеристики ЭВМ (быстродействие и производительность, показатели надежности, достоверности, точности, емкость оперативной и внешней памяти, габаритные размеры, стоимость технических и программных средств, особенности эксплуатации т. д.);
характеристики и состав функциональных модулей базовой конфигурации ЭВМ; возможность расширения состава технических и программных средств; возможность изменения структуры;
состав программного обеспечения ЭВМ и сервисных услуг (операционная система или среда, пакеты прикладных программ, средства автоматизации программирования).
К основным характеристикам ЭВМ относятся:
Быстродействие это число команд, выполняемых ЭВМ за одну секунду.
Сравнение по быстродействию различных типов ЭВМ, не обеспечивает достоверных оценок. Очень часто вместо характеристики быстродействия используют связанную с ней характеристику производительность.
Производительность это объем работ, осуществляемых ЭВМ в единицу времени.
Применяются также относительные характеристики производительности. Фирма Intel для оценки процессоров предложила тест, получивший название индекс iCOMP (Intel Comparative Microprocessor Performance). При его определении учитываются четыре главных аспекта производительности: работа с целыми числами, с плавающей запятой, графикой и видео. Данные имеют 16- и 32-разрядной представление. Каждый из восьми параметров при вычислении участвует со своим весовым коэффициентом, определяемым по усредненному соотношению между этими операциями в реальных задачах. По индексу iCOMP ПМ Pentium 100 имеет значение 810, а Pentium .
Емкость запоминающих устройств. Емкость памяти измеряется количеством структурных единиц информации, которое может одновременно находится в памяти. Этот показатель позволяет определить, какой набор программ и данных может быть одновременно размещен в памяти.
Емкость оперативной памяти (ОЗУ) и емкость внешней памяти (ВЗУ) характеризуются отдельно. Этот показатель очень важен для определения, какие программные пакеты и их приложения могут одновременно обрабатываться в машине.
Надежность это способность ЭВМ при определенных условиях выполнять требуемые функции в течение заданного периода времени (стандарт ISO (Международная организация стандартов) 2382/14-78).
Высокая надежность ЭВМ закладывается в процессе ее производства. Применение сверхбольших интегральных схем (СБИС) резко сокращают число используемых интегральных схем, а значит, и число их соединений друг с другом. Модульный принцип построения позволяет легко проверять и контролировать работу всех устройств, проводить диагностику и устранение неисправностей.
2 характеристики:
- наработка на отказ
- наработка на сбой (вероятность неверного результата – вычислить сложно)
Точность это возможность различать почти равные значения (стандарт ISO - 2382/2-76).
Точность получения результатов обработки в основном определяется разрядностью ЭВМ, а также используемыми структурными единицами представления информации (байтом, словом, двойным словом).
Достоверность это свойство информации быть правильно воспринятой.
Достоверность характеризуется вероятностью получения безошибочных результатов. Заданный уровень достоверности обеспечивается аппаратурно-программными средствами контроля самой ЭВМ. Возможны методы контроля достоверности путем решения эталонных задач и повторных расчетов. В особо ответственных случаях проводятся контрольные решения на других ЭВМ и сравнение результатов.
Закон Гроша:
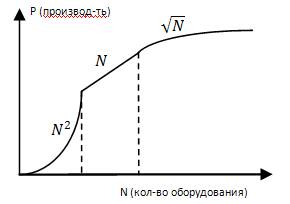
А) чем больше оборудования, тем больше затраты на организацию работы системы
Б) чем больше оборудования, тем меньше надежность системы
Операционные ресурсы – перечень того, что компьютер может делать
- система счета (система обработки разрядов)
- система связи (HDD, CD – последовательная, магнитные диски – параллельная и последовательная)
- система команд компьютера (включая способы адресации)
- способы представления данных (прямой, обратный, дополнительный код или код прямого замещения; формат данных – фиксированная точка, плавающая точка)
4)Способы организации работы процессоров (последовательный, параллельный, конвейерный и т. д.).
Последовательная обработка
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки аппаратного прерывания.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора.
Параллельная обработка
В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса:
SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных
MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных.
SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных.
MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных
В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными.
Конвейерная обработка
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
получение и декодирование инструкции (Fetch)
адресация и выборка операнда из ОЗУ (Memory access)
выполнение арифметических операций (Arithmetic Operation)
сохранение результата операции (Store)
После освобождения k-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в n ступеней займёт n единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени
Суперскалярная обработка
Способность выполнения нескольких машинных инструкций за один такт процессора. Появление этой технологии привело к существенному увеличению производительности.
5)Конвейерные структуры процессоров. Конвейер команд.
Конвейер команд – это совмещение во времени отдельных операций (этапов) рабочего цикла.

Классический вариант исполнения — последовательный. В этом случае используется конвейерный способ исполнения команд. Для последовательного способа характерна следующая структура:
Чтобы создать конвейер, ФБ(функциональный блок) нужно разбить на несколько независимых. Каждый ФБ(функциональный блок) должен иметь собственное УУ и должно существовать одно центральное.
Можно поставить между блоками дополнительные буферные регистры, это позволит сгладить неравномерность поступления команд по времени. Лучшим выходом будет, если буферный регистр заменить заменит последовательностью регистров, образующих стек типа FIFO.
Есть 2 типа конвейеров:
· синхронные – каждому блоку выделяется определенное время на обработку. (в случае, если обработка не завершена, берутся новые данные)
· асинхронные (с управлением данными). Инициализация блока осуществляется входными данными.
Опережающая выборка команд (принцип трубопровода – т. е. одновременно выполняются несколько команд, каждая с запаздыванием в 1 операцию):
6)Факторы, снижающие производительность конвейерных структур и методы борьбы с ними.
1. Может случится так, что 1 блок нужен 2-м командам, следовательно такие боки нужно дублировать.
2. Существует проблема ветвления
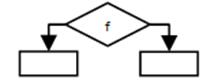
f – признак, отвечающий за направление перехода. Признак вычисляется раньше, чем обрабатываются данные, и чем больше ступеней конвейера, тем больше признаков ветвления необходимо вычислить. Как следствие – увеличение накладных расходов на организацию работы конвейера.
Выходы:
1. если ветвей 2, то можно создать 2-направленный конвейер и, когда посчитан признак, то выбрать нужный результат, но окончательно проблема не решается (ветвей может быть больше, чем 2). На линейных участках необходимо занять остальные направления – распараллелить.
2. Предсказание переходов. Если цикл выполняется 9 раз, 10-й – выход: 9 раз попадаем, 1 – промах.
Распараллелить можно независимые команды. Различают 2 вида независимости:
1. Один и тот же код выполняет действия но с различными данными.

Если результат нужен другому боку раньше, чем он попадет в 1-й.
2. Разные команды выполняют действия над одними данными.
A*B+C – пока умножение не закончится сложение выполнять нельзя.
Для того, чтобы повысить производительность конвейера используют неупорядоченное выполнение команд (произвольное выполнение независимых команд). Анализ команд процессор производит «на лету».
Проблема: например, по 2-м веткам результат записывается в 1 и тот же регистр.
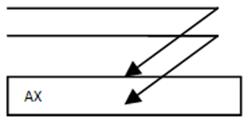
Для решения проблемы был придуман механизм переименования регистров, т. е. присвоение одинаковых логических имен разным физическим регистрам.
7)Суперконвейерные, суперскалярные процессоры. Гиперпотоковая технология.
Суперскалярность - архитектура вычислительного ядра, использующая несколько декодеров команд, которые могут нагружать работой множество исполнительных блоков. Планирование исполнения потока команд является динамическим и осуществляется самим вычислительным ядром.
Плата CRAY T3E-136/ac
Если в процессе работы команды, обрабатываемые конвейером, не противоречат друг другу, и одна не зависит от результата другой, то такое устройство может осуществить параллельное выполнение команд. В суперскалярных системах решение о запуске инструкции на исполнение принимает сам вычислительный модуль, что требует много ресурсов. В более поздних системах, таких как Эльбрус-3 и Itanium, используется статпланирование, т. е. параллельные инструкции объединяются компилятором в широкую команду, в которой все инструкции заведомо параллельные.
Исторически первыми суперскалярными процессорами были советские Эльбрусы[1]
Процессоры, поддерживающие суперскалярность:
§ Pentium, AMD Duron, AMD ATHLON и другие более поздние процессоры с архитектурой x86
§ Последние процессоры с архитектурами SPARC, ARM, MIPS
Появление в структуре процессора более одного конвейера делает этот процессор суперскалярным. Как правило, в суперскалярных процессорах в первую очередь увеличивают количество целочисленных конвейеров, так как статистика показывает, что в обычных пакетах прикладных программ для ПЭВМ около 80% команд - целочисленные, 15% - команды условных переходов, и только небольшой процент команд является командами с плавающей запятой.
Суперскалярные процессоры
У полноценной конвейеризации, есть одно несомненное достоинство: она настолько сложна, что, единожды реализованная, позволяет легко построить на ее основе целый ряд интересных новшеств. Для начала заметим, что коль уж у нас есть очереди готовых к исполнению инструкций и мы знаем взаимозависимости между ними по данным, есть техника переименования регистров, позволяющая разным инструкциям одновременно задействовать одни и те же регистры для разных целей, и, наконец, есть надежно работающая система сброса конвейера, то мы можем:
- Запускать на исполняющие устройства сразу несколько инструкций (если они не зависят друг от друга и могут быть безболезненно выполнены одновременно). Переупорядочивать независящие друг от друга инструкции так, как сочтем нужным.
Процессоры, использующие первую технику, называются суперскалярными. К примеру, сугубо теоретически, по числу исполнительных устройств, Pentium 4 может выполнять семь инструкций за такт, а Athlon 64 - девять.
Суперконвеерные процессоры
Процессоры в которых для повышения производительности повышается тактовая частота.
Гиперпотоковые и мультиядерные процессоры
В процессорах Pentium 4 (начиная с частоты 3,06 ГГц) и Хеоп применяется гиперпотоковая (hyperthreading) технология: один физический процессор одновременно может выполнять два потока инструкций х86. Для фон-неймановской машины это означает, что физический процессор (микросхема, устанавливаемая в сокет) имеет два комплекта архитектурных (прикладных и системных) регистров. В каждом комплекте имеется, естественно, свой указатель инструкций, «идущий» по своему потоку. Таким образом, речь идет о двух логических процессорах, физически расположенных на одном кристалле микросхемы. Эти логические процессоры совместно используют ряд общих микроархитектурных блоков физического процессора (вторичный кэш, исполнительные блоки арифметико-логического устройства). Такое разделение позволяет повысить эффективность функционирования исполнительных блоков: один даже «гиперконвейер» Pentium 4, исполняющий инструкции х86, плотно загрузить их работой не может. Конечно, логические процессоры не являются полностью независимыми — иногда приходится ожидать освобождения ресурса, занятого соседом.
Следующий шаг в этом направлении — мультиядерные процессоры, в которых на одном кристалле объединены общей шиной несколько функционально-законченных процессоров. В них каждое ядро обладает собственным кэшем L2 (и, естественно, кэшем данных L1 и кэшем трасс). Размер кэша L2 каждого ядра может достигать 1-2 Мбайт. Интерфейс системной шины у двух ядер может быть как общим, так и раздельным. Двухъядерный процессор, предназначенный для использования в относительно небольших системах (размером до четырех ядер), фактически, является двумя отдельными процессорами, каждый со своим интерфейсным блоком. Их интерфейсные сигналы объединяются в общую системную шину на системной плате. Процессоры для более крупных систем содержат общий блок интерфейса системной шины, поскольку объединение на одной шине интерфейсов более чем двух процессоров для высокоскоростных шин вызывает ряд трудностей.
Заметим, что мультипроцессорные кристаллы в RISC-архитектурах начали применять намного раньше, причем в более мощных вариантах (с интегрированным контроллером памяти).
8)Классификация, структуры, функции устройств управления.
Любое цифровое устройство можно рассматривать как состоящее из двух блоков – операционного и управляющего. Любая команда, операция или процедура, выполняемая в операционном блоке, описывается некоторой микропрограммой и реализуется за несколько тактов, в каждом из которых выполняется одна или несколько микроопераций. Для реализации команды, операции или процедуры (микропрограммы) необходимо на соответствующие управляющие входы операционного блока подать определенным образом распределенную последовательность сигналов. Каждый управляющий функциональный сигнал поступает в начале некоторого такта на соответствующий вход АЛУ, вызывая в этом такте выполнение в АЛУ определенной микрооперации.
Часть цифрового вычислительного устройства, предназначенная для выработки последовательностей управляющих функциональных сигналов, называется управляющим блоком или управляющим устройством. Генерируемая управляющим устройством последовательность управляющих сигналов задается поступающими на входы устройства кодом операции, сигналами из операционного блока, несущими информацию об особенностях операндов, промежуточных и конечного результатов операции, а также синхросигналами, задающими границы тактов.
Классифицировать УУ можно по различным признакам: по уровню централизации, по типам длительности тактов в УУ, по реализации хранения алгоритмов микроопераций.
По уровню централизации:
· Централизованные (УУ – один в ВМ(выч. машине))
· Децентрализованные (в каждом блоке – свой УУ)
· Смешанные (1+2 – конвейеров лучше)
По типам длительности тактов:
· Синхронизованные. Длительность такта = const.
· Асинхронные. И длительность такта и цикла – переменные. Это обеспечивает самое высокое быстродействие, но возникают сложности в настройке.
Для организации:
· Используют признак завершения операции.
· Группируют микрооперации – по признаку длительности (в каждой группе – свое время выполнения).
· Синхронно – асинхронные. Длительность такта = const, длительность цикла – переменная (из-за разного количества тактов)
По реализации хранения алгоритмов микроопераций:
· УУ с жесткой, или схемной, логикой (схемно – логические). Для каждой операции, задаваемой кодом операции команды, строится набор комбинационных схем, которые в нужных тактах возбуждают соответствующие управляющие сигналы.
· УУ с хранимой в памяти логикой (микропрограммные УУ). Каждой выполняемой в операционном устройстве операции ставится в соответствие совокупность хранимых в памяти слов – микрокоманд, содержащих каждая информацию о микрооперациях, подлежащих выполнению в течение одного машинного такта, и указание (в общем случае зависящее от значений входных сигналов), какое должно быть выбрано из памяти следующее слово (следующая микрокоманда). Последовательность микрокоманд, выполняющих одну машинную команду или отдельную процедуру, образует микропрограмму. Обычно микропрограммы хранятся в специальной памяти микропрограмм (управляющей памяти). Такая память является постоянной – каждое слово задает правило формирования на один такт.
9)Структуры команд ЭВМ. Адресность ЭВМ. Место адресного сопроцессора в структуре ЭВМ.
Рассмотрим структуры команды:
![]()
![]()
На рисунке:
· КОП – код операции.
· Адресное поле – некоторое количество разрядов предназначенных для хранения адресов операндов.
Разрядность ПК может отличаться друг от друга. В рамках команды могут отличаться методы адресации операндов. Длины команд могут быть различны. Из всего этого следует перечень характеристик, которые должны быть отражены в КОП:
· Действие, которое необходимо совершить.
· Длина команды (необходимо для того, что было возможно вычислить адрес следующей).
· Способ адресации.
Все команды можно разбить на 5 основных групп:
1. Основные (команды обработки).
2. Команды пересылки (команды обмена между процессором и ОП). Примечание: в CISC, таких команд может и не быть (причиной этому является возможность непосредственного обращения к памяти).
3. Команды управления (может привлекаться ОБ, а может и не привлекаться).
4. Команды ввода-вывода (может отсутствовать в случае организации адресного пространства ввода-вывода с отображением в ОЗУ, вместо них используются команды пересылки).
5. Системные команды (управление ресурсами системы, работа в сети).
Под адресностью ЭВМ понимают количество адресов в команде. Но в таком контексте, команда формата RR является двухадресной. Будем пользоваться конкретизированным определением: адресностью ЭВМ называется величина равная количеству адресов ОП. В данном контексте команда формата RR имеет нулевую адресность.
Существует специализированный тип ЭВМ относящихся к типу безадресных (или стековых) ЭВМ. В формате команды нет адресов, но по-прежнему, есть КОП. Адрес следующей команды, это всегда адрес в вершине стека. В таких ЭВМ при вычислениях используется обратная польская запись (вспоминаем язык LISP). Пример обратной польской записи: выражение A+B, будет записано, как AB+.
На практике, для научно-технических расчётов лучше 1-2 адресные ЭВМ, для экономических расчётов 2-3 адресные. В реализации взяли среднее значение – 2-х адресные ЭВМ.
10)Схемно-логические устройства управления, принципы построения.
Схемно–логические УУ представляют собой логические схемы, вырабатывающие распределенные во времени управляющие функциональные сигналы. В отличие от управляющих устройств с хранимой в памяти логикой (микропрограммные УУ) у этих устройств можно изменить логику работы только путем переделывания их схем. Типичная схема схемно–логического УУ показана на рисунке ниже. В состав схемы входят регистр кода операции, являющийся частью регистра команд, счетчик тактов, дешифратор тактов и дешифратор кода операции, а также схемы образования управляющих функциональных сигналов.
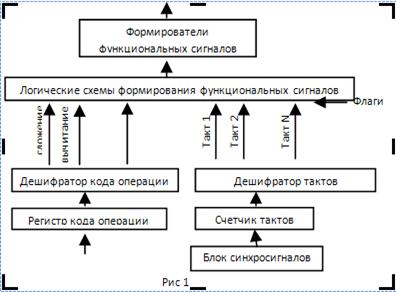
На счетчик тактов поступают сигналы от блока синхросигналов, и счетчик с каждым сигналом меняет свое состояние. Состояния счетчика представляют собой номера тактов, изменяющиеся от 1 до n. Дешифратор тактов формирует на i-ом выходе единичный сигнал при i-ом состоянии счетчика тактов, т. е. во время i-го такта. Дешифратор кода операции вырабатывает единичный сигнал на j-м выходе, если исполняется j-я команда.
Логические схемы формирования управляющих функциональных сигналов для каждой команды возбуждают формирователи функциональных сигналов для выполнения требуемых в данном такте микроопераций.
Принцип построения логических схем образования управляющих сигналов поясняется на рисунке 2. Здесь показан фрагмент схемы, обеспечивающей выработку управляющего сигнала υk в i–м и n–м тактах выполнения j–й команды.
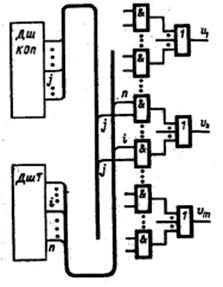
Рис 2. (ДшКОП – дешифратор Кода операции, ДшТ – дешифратор тактов)
В общем случае значения управляющих сигналов зависят еще и от оповещающих сигналов, отражающих ход вычислительного процесса. Для реализации этих зависимостей элементы, представленные на рис 2, берутся многоходовыми и на них заводятся требуемые сигналы логических условий.
Серьезным недостатком рассмотренной схемы является одинаковое число тактов для всех команд. Это требует выравнивания числа тактов исполнения команд по наиболее «длинной» команде, что ведет к непроизводительным затратам времени. Чтобы устранить этот недостаток, схемы строят с использованием нескольких счетчиков тактов. Схема формирования тактовых сигналов (датчик тактовых сигналов) может строится на основе использования регистра сдвига, по которому двигается одна 1 (регистр с «бегущей единицей»), что не требует использования дешифратора.
Существует 4 пути проектирования схемно – логических УУ:
1. На основе интерпретации микропрограмм конечными автоматами (КА). Работу операционного блока можно описать микропрограммой, например, на языке микроопераций или в виде графа. По микропрограмме строится соответствующий управляющий автомат типа Мура или Мили. КА ведет за собой применение синхронных триггеров.
2. Использование описания поведения последовательных схем (логических).
3. Построение по временным диаграммам.
4. Использование эвристических методов.
Преимущества схемно – логических УУ:
· Быстрее микропрограммных.
· Проще для простых алгоритмов.
Недостатки схемно – логических УУ:
· Нерегулярная структура (каждый раз её приходится проектировать заново).
· Немодернизуемость.
11)Структура, функционирование микропрограммных устройств управления. Виды микропрограммного управления (МПУ) и их сравнительная оценка.
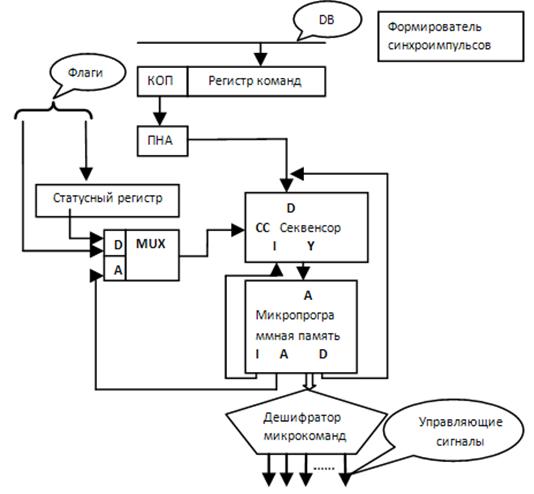
Рассмотрим, каждый из функциональных блоков, представленных на рисунке:
(КОП – код операции)
· Секвенсор – формирует последовательность адресов.
· ПНА (Преобразователь начального адреса) – формирует адрес первой микрооперации команды.
· Микропрограммная память – память, содержащая микрокоманды.
Рассмотрим, какие функции должен выполнять секвенсор для нормальной работы схемы:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
