
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Таким образом, переменная имеет две количественные характеристики — адрес и значение — и две качественных — имя и тип.
Объявление переменных
Чтобы в памяти была выделена область под переменную, за ней было закреплено имя и тип, переменную нужно объявить (так же — продекларировать). Синтаксис объявления переменных в Си таков:
[модификатор1 [модификатор2...]] <тип> <имя переменной1>[=<значение1>] [,<имя переменной2>[=<значение>]…];
Модификатор — это некая дополнительная характеристика переменной. Модификаторы бывают разные, например, модификатор register сообщает компилятору, что переменную по возможности надо хранить не в памяти, а в регистре. Другие модификаторы будут рассмотрены позднее.
Инициализация переменной — это запись в неё какого-либо значения сразу при объявлении. Если память была просто выделена, то в ней может храниться что угодно — всё, что осталось от работы других программ. Такие значения, которые никак не соответствуют логике выполнения программы, называются мусором. Иногда от мусора нужно избавиться, тогда переменная инициализируется.
Обязательными являются только тип и имя хотя бы одной переменной.
Escape-последовательность
Escape-последовательность — это несколько символов, трактуемые как один. В языке Си все escape-последовательности начинаются с символа \, после которого обязательно должен следовать какой-то другой. В одиночку этот символ смысла не имеет. Наиболее распространённые escape-последовательности в Си таковы:
Символ | Значение |
\n | Переход на новую строку (от англ. new) |
\t | Табуляция (от англ. tab) |
\v | Вертикальный отступ (от англ. vertical) |
\b | Возврат на один символ назад (от англ. backspace) |
\r | Возврат в начало строки (от англ. rewind) |
\\ | Символ \ |
\' | Символ ' |
\" | Символ " |
\0 | Нуль-символ (символ с кодом 0) |
2)Арифметические операторы языка СИ, приоритет операций
Арифметические операторы
Арифметические операторы позволяют выполнять с переменными простейшие математические действия. Несмотря на то, что на низком уровне операции с целыми и с дробными числами выглядят по-разному, в языках высокого уровня они имеют одинаковый синтаксис для всей типов данных.
Оператор | Значение | Пример |
<переменная1>=<переменная2> | Присваивание. В переменную1 записывается значение перменной2. Переменная1 при этом не изменяется. | a=b; |
<переменная>++[2] | Инкремент – прибавление 1 к переменной. | a++; |
<переменная>-- | Декремент – вычитание 1 из переменной. | b--; |
<переменная1>+<переменная2> | Сложение – сумма переменной1 и переменной2. | c=a+b; |
<переменная1>-<переменная2> | Вычитание – разность перменной1 и переменной2. | a=c-b; |
-<переменная> | Унарный минус – меняет знак переменной на противоположный | a=-b; |
<переменная1>*<переменная2> | Умножение – результат перемножения перменной1 и переменной2. | a=b*c; |
<переменная1>%<переменная2> | Остаток – взятие остатка от деления переменной1 на перменную2. | a=b%c; |
<переменная1>/<переменная2> | Деление – деление переменной1 на переменную2. | e=f/g; |
<переменная1><бинарный оператор>=<переменная2> | Составное присваивание. Эквивалентно <переменная1>=<переменная1><бинарный оператор><переменная2> | a+=3; то же, что и a=a+3; |
3)Логические и побитовые операторы, правила вычисления
Логические операторы
В языке Си нет логического типа данных. Однако есть соглашение, по которому переменная любого типа, равная 0, в логических операциях будет трактоваться как ЛОЖЬ, а имеющая любое значение, не равное 0 — как ИСТИНА.
Оператор | Значение | Пример |
!<переменная> | Логическое НЕ. Если переменная была равна 0, то!<переменная> имеет ненулевое значение (обычно 1). Иначе – ноль. | a=!b; |
<переменная1>&&<переменная2> | Логическое И. Если обе переменные не равны 0, то имеет значение 1, в противном случае 0. | a=b&&c; |
<переменная1>&<переменная2> | Побитовое И. Применяет логическую функцию И ко всем парам соответствующих бит. | a=b&c; |
<переменная1>||<переменная2> | Логическое ИЛИ. Если хотя бы одна переменная не равно 0, то имеет значение 1, в противном случае 0. | a=b||c; |
<переменная1>==<переменная2> | Равно – операция сравнения. Если переменная1 равна переменной2, то имеет значение 1, в противном случае 0. | a=b==c; |
<переменная1>!=<переменная2> | Не равно – операция сравнения. Если переменная1 равна переменной2, то имеет значение 0, в противном случае 1. | a=b!=c; |
<переменная1>><переменная2> | Больше – операция сравнения. Имеет значение 1, если переменная1 больше переменной2, в противном случае 0. | a=b>c; |
<переменная1>>=<переменная2> | Больше или равно – операция сравнения. Имеет значение 1, если переменная1 больше или равна переменной2, в противном случае 0. | a=b>=c; |
<переменная1><<переменная2> | Меньше – операция сравнения. Имеет значение 1, если переменная1 меньше переменной2, в противном случае 0. | a=b<c; |
<переменная1><=<переменная2> | Меньше или равно – операция сравнения. Имеет значение 1, если переменная1 меньше или равна переменной2, в противном случае 0. | a=b<=c; |
Поразрядные операторы
Иногда возникает необходимость работать с числом не как с единым значением, а как с набором независимых бит. Для этого существуют поразрядные операторы.
Оператор | Значение | Пример |
~<переменная> | Побитовое НЕ, дополнение до 1. Каждый бит переменной изменяется на противоположный. Логически это означает, что получается число, равное <максимальное значение данного типа>-<переменная> . Корректно работает с целочисленными данными. | a=~b; |
<переменная1>&<переменная2> | Побитовое И. Применяет логическую функцию И ко всем парам соответствующих бит. | a=b&c; |
<переменная1>|<переменная2> | Побитовое ИЛИ. Применяет логическую функцию ИЛИ ко всем парам соответствующих бит. | a=b|c; |
<переменная1>^<переменная2> | Побитовое ИСКЛЮЧАЮЩЕЕ ИЛИ – Применяет логическую функцию ИСКЛЮЧАЮЩЕЕ ИЛИ ко всем соответствующим парам бит. | a=b^c; |
<переменная1><<<переменная2> | Арифметический[3] сдвиг вправо. Все биты числа сдвигаются вправо на количество позиций, равное переменной2. Правые биты заполняются нулями, если исходное число положительное, единицами – если отрицательное. Эта операция эквивалентна умножению на 2<переменнная2>[4]. Корректно работает с целочисленными данными. | a=a<<b; |
<переменная1>>><переменная2> | Арифметический сдвиг влево. Все биты числа сдвигаются влево на количество позиций, равное переменной2. Левые биты заполняются нулями. Эта операция эквивалентна взятию целой части от деления на 2<переменнная2>. Корректно работает с целочисленными данными. | a=b>>c; |
4)Функции в языке СИ, функция main
Функции в языке Си: понятие, свойства
В языке Си функцией называется абсолютно любая подпрограмма, в отличие от многих других языков, которые разделяют понятие функции и процедуры/подпрограммы.
Итак, функция — это подпрограмма, которая к качестве результата своей работы (возможно, одного из результатов) имеет некое значение. Говорят, что это значение функция возвращает. Синтаксис объявления функций в Си такой:
<тип> <имя>([<тип> <аргумент>[, <тип> <аргумент2]…]) {<тело функции>}
То есть, сначала тип возвращаемого значения, потом имя функции, а после него в скобках типы и имена передаваемых функции аргументов, аргументы разделяются запятыми.
Если не требуется, чтобы функция вообще что-то возвращала, то ей назначают тип void.
Внутри функции должен стоять специальный оператор return <переменная> , сразу после которого функция прекращает своё выполнение и возвращает значение переменной. В функциях типа void этот оператор не нужен, но без операндов может присутствовать, чтобы принудительно прервать выполнение функции.
Функция может быть вызвана только после того места, где была определена. Это не всегда удобно, поэтому есть специальное средство, для того чтобы этого избежать — прототип функции. Прототип содержит в себе тип функции, её имя и список типов аргументов. Например, такое объявление:
void foo(int, void*);
Функция main
Программа на языке Си состоит из одних только функций. Чтобы она могла начать работу, существует специальное зарезервированное имя функции main, которую вызывает операционная система. Функция main имеет тип int. Она возвращает код ошибки. Поэтому в конце функции main нужно ставить строку
return 0;
5)Условный оператор
Условный оператор
Для того, чтобы сделать участок кода выполняемым только при выполнении некого условия, существует условный оператор, который записывается так: if(<условие>) <оператор>. Под условием понимается любое логическое выражение, переменная или константа. Оператор, который может быть как простым, оканчивающимся точкой с запятой, так и блочным, заключённым в фигурные скобки, будет выполнен только в том случае, если условие истинно.
6)метки и переходы, достоинства и недостатки
Метки и переходы, достоинства и недостатки
Безусловный переход представляет собой сообщение процессору о том, что следующую инструкцию в памяти надо искать по указанному адресу, а не следом за текущим. Как же узнать адрес, по которому надо переходить? Когда программировали в машинных кодах, его приходилось рассчитывать вручную. Но уже первые ассемблеры предоставили абстракцию, называемую метками. Метка ? это собственное имя строки кода программы. При компиляции адрес строки с меткой рассчитывается автоматически и подставляется всюду, где использовано имя метки.
Строке назначается метка <имя метки>:
Безусловный переход goto<имя метки>;
Хорошо оформленный код из циклов и условных операторов понятен даже при беглом взгляде на него. А конструкции из переходов требуют детального и вдумчивого разбора.
Нельзя делать переходы между разными функциями. С большой степенью вероятности это приведёт к краху программы во время выполнения.
Цикл с предусловием
while(condition)
{
//тело
}
//продолжение программы
Цикл с постусловием
do
{
//тело цикла
}
while(condition);
7)Цикл со счетчиком, операторы break и continue
Циклы со счетчиком
В общем виде цикл со счётчиком записывается так: for(<инициализация>; <условие>; <выражение-счётчик>) <тело цикла> .
Оператор break
Этот оператор немедленно прекращает выполнение цикла, если он выполнен, то программа продолжается с того места, где заканчивается цикл.
Оператор continue
Завершает текущую итерацию, но не завершает при этом цикл
8)Переключатели
switch(i)
{
case 1:
//обработка первого варианта
break;
case 2:
//обработка второго варианта
break;
case 3:
//обработка третьего варианта
break;
default:
//обработка варианта по умолчанию
}
//продолжение программы
9)массивы и указатели, адресная арифметика
Массив
Часто приходится иметь дело с большими наборами однотипных данных. Для работы с подобными данными в языке Си существуют массивы. Массив — это последовательность переменных одного типа в памяти. Переменные следуют последовательно, поэтому по имени доступна только первая из них, остальные задаются смещением от неё, называемым индексом.
Объявляется массив точно так же, как и обычная переменная, только после имени в квадратных скобках ставится требуемое количество элементов. Например:
int a, b[10], c;
Инициализация массива:
float d[5]={1.5, 2.6, 3.7, 4.8, 5.9};
Был объявлен массив из пяти переменных типа float, которым сразу были назначены конкретные значения. Если массив инициализируется при объявлении, то количество элементов можно не писать, оно очевидно из количества элементов, которыми он инициализируется:
char e[]={'H', 'e', 'l', 'l', 'o'};
Обращение к элементам
Имя массива — это указатель на его первый элемент. Например, в случае массива char e[]={'H', 'e', 'l', 'l', 'o'};, e имеет тип char*. Чтобы получить букву 'H' нужно написать *e. Поскольку этот массив — это последовательность байт, к адресу первого элемента достаточно прибавить 1, чтобы получить адрес следующего элемента. То есть, *(e+1) имеет значение 'e', а *(e+2) — 'l'.
Адресная арифметика
Но что если размер элемента массива больше одного байта? Казалось бы, тогда e+1 укажет не на второй элемент массива, а на второй байт первого элемента. Однако в языке Си действует правило: если к указателю прибавляется какое-то число i, то на самом деле к нему прибавляется размер переменной, на которую ссылается указатель, умноженный на i. Такое правило называется адресной арифметикой.
Таким образом, в любом случае обращение к i-тому элементу некого массива a выглядит как *(a+i). В частности, обращение к первому элементу массива — это *(a+0). Следует обратить внимание: такое уже было при нумерации бит в байте, теперь при нумерации элементов массива — зачастую порядковые номера в программировании начинаются с нуля.
Синтаксис
Существует и более удобная форма записи индекса в массиве. Конструкция *(a+i) эквивалентна такой: a[i]. Причём совершенно неважно, какая из этих букв означает массив, а какая индекс. Раз эквивалентны *(a+i) и *(i+a), то эквивалентны и a[i] и i[a].
10)Структуры и объединения
Структуры
Структура (struct) — это композитный тип данных, представляющий собой набор из независимых переменных. Переменные, из которых составлена структура, называются её полями или элементами Каждое поле имеет свой тип и имя. Элементом структуры может быть переменная какого угодно типа, кроме самой структуры.
Объявление
Объявляется структура следующим образом:
struct /*имя структуры*/
{
/*поля структуры*/
} /*объявляемые переменные данного типа*/;
Имя структуры является необязательным параметром, но если его написать, то в дальнейшем эта структура будет существовать как самостоятельный тип данных, и переменные можно будет объявлять следующим образом:
struct /*имя структуры*/ /*объявляемые переменные*/;
Использование же безымянных структур является крайне редким явлением.
Сразу во время объявления структуры можно объявить и переменные, которые будут иметь такой тип. После переменных или, если их нет, после закрывающей фигурной скобки ставится точка с запятой.
Структуры лучше объявлять вне функций, поскольку это позволяет делать функции, возвращающие значение структурного типа.
Обращение
После того, как были объявлены переменные структурного типа, к их полям надо обращаться. Для обращения к элементу структуры существует оператор . (точка). Чтобы обратиться к полю нужно написать <имя переменной>.<имя поля>. Следует понимать, что разные переменные одного и того же структурного типа имеют одинаковые имена соответствующих полей.
Структуры и массивы
Массивы в структурах
Элементом структуры может быть и массив. Причём, если это статический массив, размер которого определён одновременно с объявлением структуры, то весь массив будет содержаться непосредственно внутри каждой переменной данного типа. Если же это динамический массив, то структура хранит только указатель на него, сам массив может находиться где угодно.
В любом случае, обращение к элементу массива, являющегося элементом структуры, выглядит так: <имя переменной>.<имя поля-массива>[<индекс>].
Массивы структур
Из структур можно составить массив точно так же, как и из обычных переменных. При этом обращение к полю элемента массивы будет выглядеть так: <имя массива>[<индекс>].<имя поля>.
Объединения
В языке Си существует ещё один композитный тип данных – объединение. Объединение отличается от структуры тем, что все его элементы находятся по одному адресу. При этом тип они могут иметь разный. То есть, объединение позволяет обращаться к одному и тому же набору байт памяти, интерпретируя его различным образом.
Размер объединения равен размеру его самого большого элемента.
Синтаксис объединений такой же, как и структур, но вместо «struct» пишется «union».
Объединения и функции
Объединения позволяют, в частности, делать функции, возвращающие различные значения. Например, у нас есть строка, в которой содержится число. Но мы не знаем – целое оно или с плавающей точкой. Нужна функция, которая будет это определять и возвращать значение числа.
Для начала, создаём такую структуру:
typedef struct
{
char is_float;
union
{
float f;
int i;
} value;
} number;
В зависимости от значения поля is_float, из поля value будет считываться значение f или i.
Функция получится такая:
number aton(char* string)
{
number result;
int i;
for(i=0; string[i]; i++)
{
if(string[i]=='.')
{
result. is_float=1;
result. value. f=atof(string);
return result;
}
}
result. is_float=0;
result. value. i=atoi(string);
return result;
}
Поскольку строка содержит число по условию, то признаком того, что это число с плавающей точкой будет появление в строке символа точки. В случае её появления is_float устанавливается равным 1, а значение записывается как float. Если же в последовательнсоти символов точка не встретилась, то функция работает с ней как с целым числом.
Приёмы программирования на СИ:
1)Строки, библиотечные функции обработки строк
Строки
Особняком среди задач обработки массивов стоит задача обработки текстовой информации. Особенность её в том, что практически никогда нельзя заранее сказать, массив какой длины потребуется для хранения часть текста. Поэтому приходится выделять места заведомо больше. чем нужно, а потом отслеживать, сколько элементов действительно нужно интерпретировать как текст.
К решению этой задачи есть два подхода. Первый подход — в нулевом элементе строки хранить её длину, а саму строку начинать с первого. Этот подход реализован в некоторых языках программирования, в частности, в Паскале. Второй подход, который реализуется в языке Си и применяется большинством операционных систем — это так называемая нуль-терминированная строка. В этом подходе применяется свойство кодировки ASCII (и большинства других) — в ней нет символа с кодом 0. Поэтому конец нужной последовательности можно обозначить этим кодом. Не символом '0', код которого 49, а символом с кодом 0, так называемым NULL-символом.
Строковые константы
Объявление строки ничем не отличается от объявления массива символов, но для инициализации строк есть специальное средство. Если просто объявлять массив, то нужно писать так:
char c[]={'H', 'e', 'l', 'l', 'o', 0};
Но строку можно объявить и проще:
char c[]="Hello";
Последовательность символов, заключённая в двойные кавычки, автоматически будет разбита на элементы, а в её конец добавлен NULL-символ. Такая последовательность называется строковой константой.
Примеры работы со строками
Вывод строки на экран
void print(char* string)
{
int i;
for(i=0; string[i]; i++) putchar(string[i]);
}
Цикл выполняется до тех пор, пока не равен нулю текущий элемент строки.
Подсчёт длины строки
int len(char* string)
{
int i=0;
while(string[i]) i++;
return i;
}
Работа со строковыми константами
Возьмём функцию вывода строки на экран. Самый логичный способ её применения такой:
char str[]="Hello";
print(str);
Однако, ей не обязательно передавать переменную. Можно передать и строковую константу непосредственно:
print("Hello\n");
В этом случае в статической памяти создаётся строка "Hello\n", собственного имени она при этом не имеет, и указатель на неё передаётся функции. Читать её можно как обычную строку, а с её изменением могут возникнуть и проблемы — это зависит от того, разрешает ли операционная система запись в статическую память.
Библиотечные функции обработки строк
Стандартная библиотека содержит, в зависимости от версии, до 30 функций обработки символьных строк. Большинство из них описаны в заголовочном файле string. h
Длина строки
strlen(char* string) считает длину строки string. Завершающий нуль-символ не считается.
Копирование
strcpy(char* dst, char* src) копирует символы из src в dst, с начала и до завершающего нуль-символа. Если приёмник короче источника, возникает ошибка.
Сравнение
strcmp(char* str1, char* str2) – сравнение строк. Если строки равны (все символы одинаковые), возвращает 0. Возвращает 1, если str1 больше str2, и -1 если меньше. Отношения больше-меньше определяются на основе лексикографического порядка.
Конкатенация
strcat(dst, src) добавляет символы src в конец dst. При переполнении буфера dst возникает ошибка.
Форматный ввод-вывод
В файле stdio. h, помимо printf и scanf, описаны различные производные от них. В том числе, sprintf и sscanf. От printf и scanf они отличаются тем, что ввод и вывод осуществляют не в консоль, а в строку, идущую у них первым аргументом. Строка формата является вторым аргументом, в остальном отличий нет.
Преобразование строки в число
Не всегда для преобразования строки в число требуются все возможности sscanf. Для простых случаев в stdlib. h описана функция atoi(char* string) (от ASCII to int), которая возвращает число, записанное в переданной её строке. Если эта строка числом не является, функция возвращает 0.
Для типа long long int существует функция atoll, а для вещественного двойной точности – atof.
2)Многомерные массивы
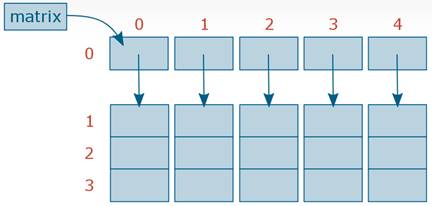
Элементом массива может быть что угодно. В частности — другой массив. Массив массивов — это двухмерный массив, то есть матрица. Объявляется двухмерный массив в языке Си, например, так:
int matrix[10][5]; //Был объявлен массив элементов типа int размером 10 на 5.
При этом matrix будет иметь тип int** — указатель на указатель на int. matrix[n], где n — какое-то число — это одномерный массив элементов типа int. И только matrix[n][m] — это элемент типа int. Если при объявлении добавить больше индексов, то получится массив большей размерности, никаких ограничений тут нет.
Массивы строк
Если у нас есть двухмерный массив элементов типа char, и каждый из одномерных массивов, из которых он составлен, представляет собой последовательность символов ASCII, оканчивающуюся нуль-символом, то мы можем интерпретировать его как массив строк.
a
|
V
[a[0]]->['H'|'e'|'l'|'l'|'o'|'\n'|0|...]
[a[1]]->['W'|'o'|'r'|'l'|'d'|0|...]
[a[2]]->['B'|'y'|'e'|'\v'|0|...]
Но интереснее другой случай. Вспомним, что как не существует символа с кодом 0, так и не существует нулевого адреса в памяти. Поэтому нулём можно обозначить не только конец последовательности символов, но и конец последовательности указателей, создать из них некое подобие строки. Отсюда приходим к идее некой «строки строк»: последовательности указателей на строки, конец которой обозначен нулевым указателем.
a
|
V
[a[0]]->['H'|'e'|'l'|'l'|'o'|'\n'|0|...]
[a[1]]->['W'|'o'|'r'|'l'|'d'|0|...]
[a[2]]->NULL
Аргументы функции main
Рассмотренная нами «строки строк» имеет очень важное применение — она является аргументом функции main.
Когда программу запускают командой из консоли, после её имени можно написать что-то ещё. Это «что-то» называется аргументами командной строки[1]. Одним аргументом считается одно слово — последовательность символов, не содержащая пробелов, либо последовательность любых символов, заключённая в двойные кавычки. Чтобы main приняла аргументы, её надо объявить так:
int main(int argc, char** argv).
argc (от англ. argument counter) — это количество аргументов командной строки. Первым аргументом всегда является имя программы, а потому argc не бывает меньше 1.
argv (от англ. argument vector) — это собственно массив строк, каждая из которых содержит в себе один аргумент. Последним элементом элеметом этого массива является указатель NULL.
Например, рассмотрим такую программу:
int main(int argc, char** argv)
{
int i;
for(i=0; i<argc; i++)
{
print(argv[i]);
putchar('\n');
}
return 0;
}
Если программа называется printarg и была вызвана следующим образом: ./printarg arg1 "this is arg2" arg3, то её вывод будет выглядеть следующим образом:
printarg
arg1
this is arg2
arg3
argc тогда будет иметь значение 4, а массив argv выглядеть примерно так:
argv
|
V
[argv[0]]->['p'|'r'|'i'|'n'|'t'|'a'|'r'|'g'|0]
[argv[1]]->['a'|'r'|'g'|'1'|0]
[argv[2]]->['t'|'h'|'i'|'s'|' '|'i'|'s'|' '|'a'|'r'|'g'|'2'|0]
[argv[3]]->['a'|'r'|'g'|'3'|0]
[argv[4]]->NULL
Воспользовавшись свойством argv, условие i<argc можно переписать и в другом виде: argv[i].
3)Битовые маски
Другой путь работы с двоичными данными – это битовые маски.
Рассмотрим пример: нам надо поменять регистр всех букв в строке. «Лобовой» пусть решения – писать конструкции такого вида:
if(string[i]='a') {string[i]='A'; continue;}
if(string[i]='A') {string[i]='a'; continue;}
И так для каждой буквы. Решения подобного вида называются брутфорс-решениями (от англ. brute force – грубая/тупая сила), обладают крайне низкой эффективностью (в данном случае: если встретится буква z, то придётся перебирать весь латинский алфавит), и их применение является крайне нежелательным.
Если же рассмотреть таблицу символов ASCII, то можно заметить, что все символы верхнего регистра лежат в диапазоне от 0x41 до 0x5A, а нижнего – от 0x61 до 0x7A и расположены они в одинаковом (алфавитном) порядке. Это значит, что младшие тетрады у символов верхнего и нижнего регистра одинаковые, отличаются только старшие.
Верхний регистр | 416=01002 | 516=01012 |
Нижний регистр | 616=01102 | 716=01112 |
Видно, что у символов верхнего регистра второй бит старшей тетрады равен 0, а у нижнего – 1. Поэтому достаточно изменить его значение на противоположное, чтобы изменить регистр.
Вспомним теперь свойства операции ИСКЛЮЧАЮЩЕЕ ИЛИ: x^1=~x, x^0=x. То есть, чтобы изменить значение одного бита числа на противоположное, нужно применить к нему операцию побитовое ИСКЛЮЧАЮЩЕЕ ИЛИ с числом, у которого все биты равны 0, кроме того, который нужно изменить. Иными словами, достаточно ко всем элементам строки применить такую операцию:
string[i]^=0x20;
Регистр букв при этом изменится.
Если в вычислениях используется не значение числа, а его битовое представление, то такое число и называется битовой маской.
4)Библиотечные функции ввода-вывода
В заголовочном файле stdio. h (от standart input/output) находится много функций, которые сильно упрощают задачу взаимодействия программы с пользователем.
Printf
Для вывода самой разнообразной информации на экран используется функция printf. Её первым аргументом является так называемая строка формата – последовательность. состоящая из символов, которые будут выведены на экран без изменений, и символов, которые определяют, в каком формате будут выведены остальные аргументы.
В простейшем случае использование printf выглядит так:
#include <stdio. h>
int main()
{
printf("\tHello world!\n");
return 0;
}
Результатом работы этой программы будет строка "Hello world!", выведенная с отступом от края экрана, и перевод курсора на следующую строку.
Другие аргументы printf являются необязательными. Как реализуются подобные функции, будет сказано позднее, пока же просто следует запомнить, что printf «умеет» определять, сколько аргументов ей передано.
Управляющие последовательности
Чтобы выводить с помощью printf различные значения, в строку формата вводят так управляющие последовательности. Управляющая последовательность – это последовательность символов, начинающаяся с символа '%', которая при работе printf замещается значением переменной, причём формат, в котором это значение будет записано, зависит от вида управляющей последовательности. Обычно аргументов printf, кроме форматной строки, столько же, сколько в ней управляющих последовательностей. Последовательности замещаются переменными в том порядке, в котором они следуют аргументами printf.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
