
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
void print_bt(bintree* tree)
{
if(!tree) return;
output(tree->data);
print_bd(root->left);
print_bd(root->right);
}
Если эту функцию вызвать для дерева, изображённого на рисунке, она выведет:
1
2
3
4
5
6
7
8
9
10
11
Предполагается, что функция output определена так:
void output(int data)
{
printf("%d\n", data);
}
Улучшенный вывод на экран
Нашу функцию вывода дерева можно «украсить» следующим образом:
void print_bt_m(bintree* tree, int deep)
{
if(!tree) return;
printf("%*d\n", deep, tree->data);
print((tree->left), ++deep);
--deep;
print((tree->right), ++deep);
--deep;
}
При рекурсивном вызове этой функции для потомка значение переменной deep увеличивается, а при возврате – уменьшается. Таким образом, с точностью до переданного при первом вызове значения, deep равно расстоянию от текущего элемента до корня. Поэтому вывод этой функции будет выглядеть так:
1
2
3
4
5
6
10
11
Это позволяет нагляднее отразить структуру дерева.
Удаление потомка
Непосредственно удалить элемент в бинарном дереве невозможно: указателя на его предка нет, а потому записать туда пустое дерево вместо удалённого нельзя. Но можно удалить левого или правого потомка данного элемента. При этом, по определению дерева, должны быть удалены и все его потомки. Алгоритм получается такой:
Удаление пустого дерева невозможно. Удалить потомков удаляемого элемента. Освободить память, выделенную под элемент, и записать в предка указатель NULL.Если такой алгоритм применить к элементу, не имеющему потомков, то при выполнении шага 2 функция перейдёт к пустым деревьям, после чего будет осуществлён переход к шагу 3. Если у элемента есть потомки, то функция будет спускаться вниз по дереву до тех пор, пока не дойдёт до элементов, не имеющих потомков, удалит их и вернётся на уровень назад.
Реализовать это можно следующим образом:
#define RM_LEFT 1
#define RM_RIGHT 2
#define RM_ALL 3
void rm_r_bt(bintree *tree, char flag)
{
if(!tree) return; //Невозможность обработки пустого дерева
if(flag&RM_LEFT) //Если нужно удалить левого потомка
{
rm_r_bt(tree->left, RM_ALL); //Удаляем потомков
//Потомков нет, можно удалять элемент
free(tree->left);
tree->left=NULL;
}
if(flag&RM_RIGHT) //если нужно удалить правого потомка
{
rm_r_bt(tree->right, RM_ALL); //Удаляем потомков
//Потомков нет, можно удалять элемент
free(tree->right);
tree->right=NULL;
}
}
Остановимся подробнее на поле flag, управляющем тем, какие элементы будут удалены. Это поле — битовая маска, у которой используются первые два бита. Если flag равен RM_LEFT, то нулевой бит равен 1, а первый — 0. Если RM_RIGHT — то, наоборот, нулевой равен 0, а первый — 1. При поставленном RM_ALL оба бита равны 1. Несложно заметить, что, рассматривая биты по отдельности, при установленном RM_ALL мы увидим установленными как RM_LEFT, так и RM_RIGHT, это логично и удобно. Собственно, получить значение RM_ALL можно, выполнив операцию RM_LEFT|RM_RIGHT.
Узнать, установлен ли флаг, позволяет операция поразрядного И со значением, которые мы хотим проверить. Результатом операции flag&RM_RIGHT будет ненулевое значение (логическая единица) тогда и только тогда, когда первый бит числа flag равен 1. А результатом операции flag&RM_LEFT является 1 только если нулевой бит flag равен 1.
10)Графы
Общие понятия
Граф и гиперграф
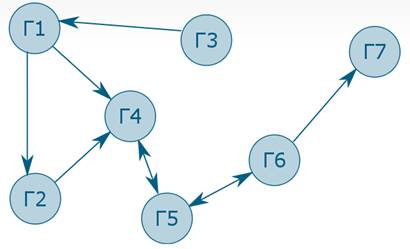
Граф представляет собой набор из элементов, называемых вершинами, и связей, представляющих собой упорядоченные наборы из вершин. Это очень широкое определение, поэтому у него выделяют много частных случаев. Граф, у которого все связи состоят только из двух вершин, обычно и называют графом, а если вершин в связи произвольное число – гиперграфом.
Орграф и неограф
Связь представляет собой упорядоченный набор вершин, а потому наличие связи из вершины A в вершину B вовсе не гарантирует наличие связи из B в A. Граф, в котором для любых двух вершин A и B из наличия связи A-B следует наличие связи B-A и наоборот, называют неографом. Общий же случай называется орграфом.
Мультиграф
Граф, в котором может существовать несолкько одинаковых связей, то есть, между двумя вершинами может быть несколько связей, называется мультиграфом. Любой неоргаф по сути является мультиграфом.
Путь
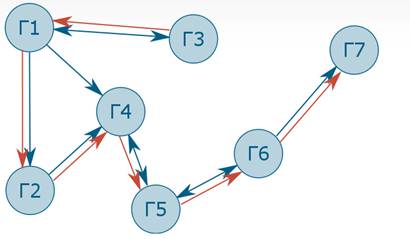
Путём между вершинами A и B называется конечная последовательность вершин, начинающаяся с A и заканчивающаяся на B последовательность вершин, такая что между любыми двумя стоящими последовательно вершинами в ней есть связь.
Эйлеров путь
Эйлеровым путём называется путь, который не содершит однаковых связей.
Гамильтонов путь
Гамильтоновым путём называется путь, который не содершит одинаковых вершин.
Цикл
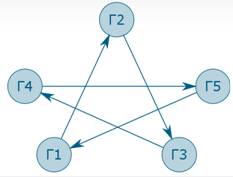
Циклом называется путь, первый и последний элементы которого совпадают.
Связный граф
Связным называется граф, между любыми двумя вершинами которого существует путь.
Основные приёмы при реализации на языке Си
Хранение
Существует много способов хранения графов, мы рассмотрим только самый простой. Граф бует состоять из структур, содержащих данные и набор указателей на элементы, с которыми данный элемент связан.
Из произвольности количества связей следует, что хранить указатели надо либо в динамическом массиве, либо в связном списке. Что лучше – однозначно сказать нельзя. Функции работы со связным списком сложнее реализовать, но, работая с массивом, надо всегда хранить и передавать между функциями его длину. То есть, в случае работы с динамическими массивами элемент графа выглядит следующим образом:
typedef struct VERTEX
{
void* data;
int degree;
struct VERTEX** edges;
} vertex;
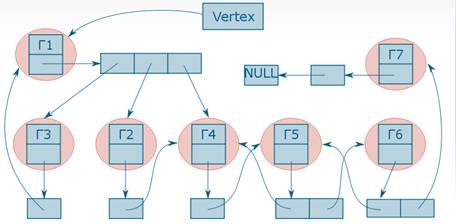
Представление графа в ОП
В этой структуре поле data содержит указатель на хранящиеся в ней данные, degree показывает количество связей элемента и одновременно длину динамического массива, а rib – указатель на динамический массив указателей на другие элементы графа.
Остановимся на этой реализации, поскольку она требует меньшего количества кода, чем на связных списках.
Обработка
При обработке будет полагать, что работаем со связным неориентированным графом.
Обход графа
Для начала предположим, что у нас уже есть граф, и нам нужна функция, которая, переходя по связям, побывает в каждом его элементе, сделает с ними какие-то действия или просто сохранит какие-то данные об элементах.
Для обхода графа простой рекурсии недостаточно – если в графе есть циклы, то она будет бесконечно по нему перемещаться.
Итак, функция обхода графа должна поочередно перейти по всем указателям массива edges, указывающим на элементы, в которые ещё ни разу не был совершён переход. Для этого она должна записывать все элементы, в которых была:
int in(vertex **array, int len, vertex* item)
{
int i;
if(!array) return 0;
for(i=0; i<len; ++i) if(array[i]==item) return 1;
return 0;
}
vertex** add(vertex** array, int* len, vertex* item)
{
array=(vertex**)realloc(array, ((len+1)*sizeof(vertex*)));
array[len]=item;
++(*len);
return array;
}
vertex** traversal(vertex** visited, int* len, vertex* current)
{
int i;
if(in(visited, *len, current)) return visited;
else add(visited, len, current);
for(i=0; i<*len; ++i)
{
if(!in(visited, *len, (current->rib[i])))
visited=traversal(visited, len, (current->rib))
}
return visited;
}
Обход осуществляет функция traversal, in и add – вспомогательные функции. Функция in определяет, есть ли элемент item в массиве array длиной len. Она работает корректно и в том случае, если ей передадут не массив, а NULL – тогда возвращается 0. add добавляет элемент item в массив array длины len, увеличивая при этом len на 1. Поскольку realloc при получении NULL работает как malloc, add корректно работает и с пустым массивом (NULL). Но поскольку при этом указатель изменяется, функция должна его возвратить. В противном случае она возвращает указатель без изменений.
Функция traversal хранит указатели на элементы, в которые уже заходила, в массиве visited длины len. При вызове первым делом она проверяет, не заходила ли она уже в переданный ей элемент current. Если заходила – то выполнение тут же прекращается. Если нет – то текущий элемент записывается в массив visited. Далее рассматриваются связи элемента: для каждой из них, если она не связывает элемент с уже посещённым, рекурсивно вызывается traversal.
При первоначальном вызове функции в качестве массива посещённых элементов ей передаётся NULL – ведь она ещё ни одного не посетила – с длины соответственно 0. Но поскольку эта функция работает с указателем, ей надо передать не просто ноль, а адрес целочисленной переменной со значением 0. Тот факт, что мы рассматриваем связный граф, гарантирует, что, начав обход с произвольного элемента, можно попасть в любой другой. А значит – ей можно передать любой элемент графа, всё равно он будет весь обойдён.
Рассмотрим теперь, что traversal возвращает. Из-за необходимости изменить NULL на какой-то конкретный указатель при записи первого элемента эта функция сделана возвращающей указатель на получаемый массив посещённых элементов. А поскольку она обойдёт все элементы, то по завершении обхода функция возвратит массив указателей на все элементы графа.
Работать с таким массивом, разумеется, проще, чем с графом непосредственно. При обработке графа часто может возникнуть необходимость последовательно обратиться ко всем его элементам. Это может понадобиться, например, для вывода графа на экран, поиска элемента по заданному значению поля данных и других задач. В таком случае, вместо того чтобы каждый раз производить обход графа, который в случае больших размеров последнего может занять длительное время, можно просто перебрать все указатели массива.
Вывод на экран
Предположим, у нас есть функция output, выводящая данные, находящиеся в поле data на экран. В случае, если данные представляют собой целое число, эта функция выглядела бы примерно так:
void output(void* data) {printf("%d\n", *((int*)data);}
Однако данные могут быть намного сложнее, и соответственно их вывод будет организован по-другому. Поэтому будет рассмотрен общий случай, где для вывода используется некая функция output:
void printgraph(vertex** array, int len)
{
int i;
for(i=0; i<len; ++i) output((*array[i]).data);
}
Очевидно, что такая функция намного проще и быстрее, чем обход графа.
Добавление вершины
Теперь надо понять, как создавать и удалять элементы. Эти задачи не такие тривиальные, как может показаться. Основные сложности вызываются условием связности графа. Связность очень сильно упрощает обход графа и поиск путей между элементами, но усложняет добавление и удаление элементов.
Кроме вырожденного случая графа из одного элемента, любой элемент должен иметь хотя бы одну связь с другим. Это разбивает добавление на два случая: создание первого элемента и добавление элемента к уже существующим. В первом случае в принципе достаточно выделить память под один элемент, заполнить все его поля нулями и записать указатель на него в массив указателей на элементы графа. Из определения графа вовсе не следует, что каждый его элемент должен иметь собственное имя или идентификационный номер. Но поскольку мы работаем не в графическом режиме, где отображение таких пустых элементов не составило бы труда, а в текстовом, каждый элемент должен иметь имя (или номер), причём уникальное. Под имя можно либо выделить специальное поле в структуре элемента, либо использовать для него поле data. Это вовсе не должно означать, что данные, хранящиеся в элементе, будут состоять только из его имени: ведь data может указывать и на структуру, одним из полей которых является имя или номер элемента, а другие поля составляют собственно данные. Поэтому будет лучше, если создание безымянных элементов будет запрещено, а при создании имя должно будет введено пользователем.
Иначе выглядит добавление элемента к уже существующим. В этом случае таким же обязательным как имя является хотя бы одна связь с другим элементом. Но пользователь не может ввести указатель на элемент, он может ввести его имя. Поэтому надо реализовать функцию, которая будет принимать имя элемента, искать его в массиве указателей и возвращать указатель на элемент с введённым именем. Поскольку в данном случае идёт работа с данными, вводимыми пользователем, совершенно необходимой является обработка ситуации отсутствия требуемого элемента в графе. Найдя нужный указатель, нужно записать его в массив связей создаваемого элемента. Но нельзя забывать и вторую характеристику нашего графа – неориентированность, требующую взаимность всех ссылок. Поэтому надо не только добавить найденный указатель к связям создаваемого элемента, но и добавить указатель на создаваемый элемент к связям найденного элемента.
Удаление элемента
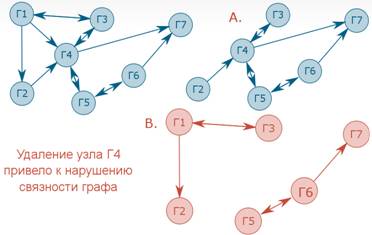
Больше сложностей вызывает удаление элемента. Если через элемент проходит единственный путь к какому-то участку графа, то после его удаления граф будет разбит на две части, что нарушит связность. А потому перед удалением надо сделать соответствующую проверку. Грубо говоря, необходимо «представить», как будет выглядеть обход графа после удаления элемента: если удастся обойти все оставшиеся элементы, то удаление разрешается, а если только часть графа – то запрещено. Говоря строго, нужно совершить обход графа, не заходя в элемент, который мы собираемся удалить. Если его удаление не нарушит связность графа, то количество пройденных элементов будет меньше только на один, а если нарушит – то traversal не обойдёт большее число элементов. Значит, мы должны передать traversal в качестве аргумента visited не NULL, а динамический массив из одного элемента – того, который нужно удалить. Длина его, разумеется, при этом будет 1, а не 0. Обход можно начинать с любого другого элемента. А потом достаточно просто посмотреть на изменённое значение длины. Если она будет равна текущей (именно текущей, а не на 1 меньше – функции изначально была передана единица вместо нуля!), значит, граф останется связным и после удаления элемента, и эту операцию можно продолжить. А если длина окажется меньше нужной, то удаление осуществлять нельзя, об этом надо сообщить пользователю, чтобы он мог принять соответствующие меры (определить дополнительные связи для элементов), и прекратить выполнение функции.
Собственно удаление состоит из трёх этапов. На первом этапе нужно удалить все ссылки на данный элемент. Найти их несложно: их могут содержать только элементы, на которые удаляемый ссылается. Чтобы удалить последний элемент динамического массива, достаточно с помощью realloc уменьшить его размер на 1. Если же удаляется элемент, стоящий не на последней позиции, то нужно, начиная с этой позиции, сдвинуть все элементы на одну позицию влево, и только после этого уменьшать размер массива. И в том, и в другом случае нельзя также забывать о необходимости уменьшить параметр len. Для выполнения этих действий лучше всего написать отдельную функцию.
Второй этап состоит в освобождении памяти, выделенной под поля элемента: data и rib ссылаются на участки динамической памяти, которые с точки зрения функции free никак с самим элементом не связаны. Если удалить элемент прежде, чем поля, то выделенная под них память так и останется с точки зрения операционной системы в распоряжении программы, хотя в самой программе указатель на неё безвозвратно утерян. Такая ситуация называется утечкой памяти, а алгоритм, который её допускает, считается ошибочным. Поэтому нельзя забыть, что перед удалением элемента удаляются все его поля, лежащие в динамической памяти.
И, наконец, на третьем этапе, когда элемент уже ни с чём не связан, к нему самому можно применить функцию free.
11)Файлы в языке Си
В языке Си функции работы с фалом находятся в библиотеке stdio. В качестве файловой переменной там определена структура FILE, причём это не имя структуры, а тип данных. Так как функции, обрабатывающие файлы, могут изменять файловую переменную, они всегда используют указатель на неё, который так и называется – файловый указатель.
Открытие и закрытие файла
Для открытия файла служит функция fopen, продекларированная следующим образом:
FILE *fopen(char *name; char *mode);
Эта функция возвращает файловый указатель, либо NULL, если открыть файл не получилось, а принимает name – строку с именем файла или путём к нему и mode – строку с режимом открытия. Существуют следующие режимы открытия:
Режим | Назначение |
"r" | Только чтение, открытие несуществующего файла невозможно. |
"r+" | Чтение и запись, открытие несуществующего файла невозможно. |
"w" | Запись в пустой файл. Если файл не существует, то он создаётся, а если существует, то вся информация в нём стирается. |
"w+" | Чтение и запись со стиранием при открытии. Если файл не существует, то он создаётся. |
"a" | Запись в конец – запись всегда осуществляется только после последнего байта файла. |
"a+" | Запись в конец с возможностью чтения. |
Закрытие файла выполняет функция fclose, принимающая в качестве единственного аргумента файловый указатель.
Побайтовый ввод
Несмотря на то, что каждый файл представляет собой массив байт, он не является массивом с точки зрения языка Си, а потому доступ к его элементам по индексу невозможен. Но существует аналог индекса – это указатель текущей позиции, хранящийся в файловой переменной. Считывание одного байта из текущей позиции выполняет функция getc, продекларированная следующим образом:
int getc(FILE* fp);
Считав значение, из файла fp, она увеличивает значение текущей позиции на 1. Это может привести к ситуации выхода за границу существующего файла, такую ситуацию надо корректно обрабатывать. Поэтому getc имеет тип int, и если файл кончился, то она ничего из него не считывает, а возвращает некоторое значение, которое не может быть значением одного байта. Это значение представляет собой константу EOF, продекларированную в stdio. Следует помнить, что EOF не является значением, находящимся в файле и считываемым из него, это только результат обработки ошибки.
Определение конца файла
Не всегда удобно считывать значения из файла и проверять, не равно ли значение EOF. Поэтому существует функция feof:
int feof(FILE* fp);
Если из фала можно считывать, то она возвращает значение 0, а если достигнут конец файла, то ненулевое значение.
Побайтовый вывод
Для записи одного символа в файл используется функция putc:
int putc(int value, FILE* fp);
Эта функция записывает value в текущую позицию, а затем увеличивает её значение на 1, причём запись будет осуществлена, даже если достигнут конец файла: его размер будет автоматически увеличен. Она возвращает записанное значение, либо EOF, если записать не удалось.
Изменение позиции в файле
Для принудительного изменения значения текущей позиции служит функция fseek:
int fseek(FILE* fp, long int offset, int origin);
Она увеличивает значение текущей позиции файлового указателя fp на величину offset (в том числе и отрицательную), а origin определяет, откуда ведётся отсчёт. Этим аргументом могут быть три константы, определённые в stdio:
- SEEK_SET – отсчёт ведётся от начала файла. SEEK_CUR – отсчёт ведётся от текущей позиции. SEEK_END – отсчёт ведётся от конца файла, причём в сторону увеличения размера: если указано положительное значение offset, то файл расширяется до необходимого размера, а пустые поля заполняются нулями.
Режимы "a" и "a+" при открытии файла устанавливают текущую позицию на конец файла, туда же она устанавливается при каждом вызове функции записи, в независимости от того, где она была до вызова функции.
Получение позиции
Функция int ftell(FILE* fp); возвращает текущую позицию файлового указателя.
Сброс буфера
Буфер сбрасывается автоматически при закрытии файла и при необходимости обратиться к данным, лежащим вне его, но может возникнуть и необходимость сбросить его принудительно. Для этого служит функции fflush, единственным аргументом которой является файловый указатель, для которого осуществляется сброс.
Форматный ввод-вывод
Для работы с файлами существуют и функции форматного ввода-вывода – fprintf и fscanf. Они аналогичны printf и scanf, за тем исключением, что первым их аргументом является файловый указатель, а строка формата – вторым. Они перемещают текущую позицию на количество считанных или записанных символов.
Бинарные и текстовые файлы
Форматный ввод-вывод позволяет, в том числе, считывать из файла строки. Но это связано с определённым затруднением: в UNIX-подобных ОС переход на новую строку обозначается символом '\n', а в DOS и Windows – парой символов "\n\r". Функции форматного ввода-вывода по умолчанию меняют '\n' на "\n\r", если программа запускается в DOS, и наоборот – если в UNIX. Но в случае файла, не являющегося текстовым, это приведёт к потере данных. Поэтому в таком случае нужно к строке режима открытия добавить букву 'b' (от англ. binary – двоичный, в противоположность текстовому), которая отключит это преобразование.
Работа с директориями
Теоретически, поскольку директория является файлом, работать с ней тоже можно как с обычным файлом, извлекая из неё список содержащихся в ней файлов. На практике такие решения окажутся системно-зависимыми, так как реализованы директории в разных системах немного по-разному, и сложными. К тому же, не факт, что операционная система позволит открыть директорию как файл.
Поэтому в каждой системе или компиляторе, удовлетворяющем стандарту POSIX, есть свои реализации набора функций, имеющих одинаковые прототипы, служащих для работы с директориями.
Заголовочные файлы
Чтобы работать с директориями, нужно подключить к программе следующие заголовочные файлы:
#include <sys/types. h>
#include <dirent. h>
Открытие и закрытие директории
Чтобы избежать путаницы между файлами и директориями, файловый указатель на директорию имеет тип DIR*.
Возвращает такой указатель, открывая директорию с указанными именем, функция opendir:
DIR *opendir(char *name);
Для закрытия директории служит функция closedir:
int closedir(DIR *dir);
Она возвращает 0 в случае успешного выполнения, либо код ошибки.
Считывание имени файла
Директория состоит из последовательности имён файлов, содержащихся в ней, и информации о них. Считать информацию о файле, находящуюся на текущей позиции файлового указателя, и установить его в начало следующей записи позволяет функция readdir:
struct dirent *readdir(DIR *dir);
Структура dirent, указатель на которую возвращает функция, в разных системах может быть определена по-разному. Но в любом случае, она будет иметь поле d_name, в котором будет храниться читанное имя файла.
Обычно она также содержит поле d_type, которое характеризует тип считанного файла. Например, если оно имеет значение DT_DIR, то считанный файл является директорией, а если DT_REG – обычным файлом.
Считывание позиции файлового указателя
Текущую позицию файлового указателя считывает функция telldir:
off_t telldir(DIR *dir);
Изменение позиции файлового указателя
Для изменения позиции файлового указателя есть две функции.
Функция seekdir устанавливает файловый указатель на переданную позицию, считая от начала директории:
void seekdir(DIR *dir, off_t offset);
Функция rewinddir устанавливает файловый указатель в начало директории:
void rewinddir(DIR *dir);
12)Указатель на функцию
Функция представляет собой последовательность байт в статической памяти, а потому на неё можно объявить указатель. Для работы с переменной по указателю достаточно знать, сколько байт считывать и как их интерпретировать. Функцию же определяет её тип, а также порядок и типы принимаемых аргументов – такая информация называется 'интерфейсом функции.
Объявление указателя
<тип функции> (*<имя указателя>)([типы аргументов]);
Создание нового типа данных
Объявляется указатель на функцию не очень удобным образом, поэтому лучше с помощью typedef определить имя нового типа:
typedef double(*trig)(double);
Был определён новый тип данных trig. После этого можно определять переменные нового типа:
trig a;
Этот код эквивалентен такому:
double (*a)(double);
Присваивание значения
Имя функции по сути является указателем на неё. Поэтому, если мы хотим, чтобы в указателе a типа trig лежал адрес синуса, надо написать так:
a=sin;
Обращение к функции по указателю
Раз имя функции – это указатель на неё, то верно и обратное – указатель на функцию является её именем. Например:
trig a;
double val, arg=M_PI;
a=sin;
val=a(arg);
Этот код вычислит значение синуса пи.
Функции, возвращающие указатель на функцию
С указателем на функцию можно делать всё то, что и с обычным указателем, в том числе, его может возвращать функция. Если уже объявлен тип данных trig, то прототип функции, принимающей символьную строку и возвращающей указатель на тригонометрическую функцию, будет выглядеть так:
trig function(char*);
Здесь становятся очевидны преимущества определения через typedef, поскольку без него этот прототип будет таким:
double(*function(char*))(double);
А это значительно сложнее как для понимания, так и для отладки.
В качестве примера можно привести функцию, осуществляющую простейший анализ передаваемой ей строки – выбор между тремя тригонометрическими функциями:
trig function(char *name)
{
if(!strcmp(name, "sin")) return sin;
if(!strcmp(name, "cos")) return cos;
if(!strcmp(name, "tan")) return tan;
return NULL;
}
С помощью этой функции можно написать программу, которая будет вычислять значения вводимой пользователем функции во вводимой точке:
int main()
{
char string[4];
double x;
while(1)
{
if(!scanf("%s %lf", string, &x)) return;
if(!function(string)) return;
printf("%s(%f)=%f\n", string, x, function(string)(x));
}
return 0;
}
Видно, что возвращаемое значений функции function используется точно так же, как и имя функции: если после него написать в скобках аргументы, то она будет возвращать соответствующее значение.
Указатель на функцию как аргумент функции
Указатель на функцию может быть и аргументом функции. Классическим примером такой функции является функция, приближённо вычисляющая производную в заданной точке. Приближённо – потому что компьютер работает с конкретными числовыми значениями, и вычислить производную как предел он не может[1]. Но производную можно приближённо вычислить как отношение приращения функции к приращению аргумента, причём приращение аргумента вводится пользователем. Задача оценки величины приращения при заданном значении необходимой точности вычисления производной лежит в области математического анализа, мы же считаем, что нужное значение уже известно. Тогда функция вычисления производной будет предельно проста:
double derivative(double x, double dx, trig f)
{
return ((f(x+dx)-f(x))/dx);
}
Здесь x – точка, в которой вычисляется производная, dx – приращение аргумента, f – функция, для которой осуществляются вычисления. Если тип данных trig не был объявлен, то прототип функции будет выглядеть так:
double derivative(double, double, double(*)(double));
А сама функция соответственно:
double derivative(double x, double dx, double(*f)(double))
{
return ((f(x+dx)-f(x))/dx);
}
Эти две функции позволяют написать простую программу, которая будет вычислять производную вводимой функции:
int main(int argc, char* argv[])
{
double x, dx;
if(agrc!=4)
{
printf("Syntax error! Type \"%s <function> <argument> <increment>\"\n", argv[0]);
return 0;
}
sscanf(argv [2], "%lf", &x);
sscanf(argv[3], "%lf", &dx);
printf("%s'(%f)=%f\n", argv[1], x, derivative(x, dx, function(argv[1])));
return 0;
}
Первый аргумент при вызове программы – это имя функции (sin, cos или tan), второй – точка, для которой считается производная, третий – приращение аргумента.
13)Функции с переменным числом аргументов
Общие сведения о работе функций
Передача аргументов
Аргументы функциям можно передавать разными способами, но чаще всего они передаются через стек. Перед вызовом функции они туда кладутся в порядке, обратном тому, в котором следуют в списке аргументов. С учётом того, что стек растёт в сторону младших адресов, получается, что по младшему адресу расположен первый аргумент, а по старшему – последний. После этого в стек кладётся адрес возврата, и осуществляется переход к коду функции.
Начало функции
Стек в программе один, поэтому использовать его надо осторожно. Функция должна после своей работы вернуть его к тому виду, в котором он ей поступил. Это же верно и в отношении регистров. Для этого функция первым делом сохраняет в стеке значение регистра ebx, чтобы потом записать туда значение указателя на вершину стека. После этого со стеком можно делать практически что угодо, нужно только не терять значение ebx.
Обращение к аргументам
Неудобно, каждый раз обращаясь к аргументам функции, доставать их из стека. Поэтому их адреса высчитываются непосредственно из значение ebx: известно, что по адресу, указанному в ebx лежит сохранённое значение самого ebx, после него идёт адрес возврата, а затем аргументы. Чтобы обратиться к n-ному аргументу, нужно обратиться по адресу, лежащем в ebx и сложенному с суммой размеров ebx, адреса возврата и всех предыдущих аргументов.
Конец функции
В конце функции нужно вернуть стек в изначальное положение. Для этого указатель на вершину стека восстанавливается из ebx, затем из стека восстанавливается значение самого ebx. После этого в стеке остаётся адрес возврата и аргументы – то, что было там до работы функции. Можно осуществлять переход по адресу возврата.
Функции с переменным числом аргументов в языке Си
Синтаксис объявления
Все аргументы функции делятся на обязательные и необязательные.
Обязательные – это те, которые явно прописываются при объявлении функции и доступны в ней по именам. Для обязательных аргументов компилятор осуществляет проверку правильности – количество и типы.
Необязательные аргументы могут следовать только после обязательных и в объявлении функции заменяются многоточием. Например, printf объявляется так:
int printf(char *format, ...);
Необязательные аргументы не доступны по именам, их адреса надо вычислять. Само по себе многоточие значит только то, что компилятор не будет проверять, что стоит на его месте в каждом конкретном вызове функции, и положит в стек всё, что передано.
Поскольку аргументов может быть сколько угодно, нужно как-то сообщить функции их количество. Самый просто путь – иметь обязательный параметр argc, в явном виде указывающий это количество. Но есть и другие пути, такие как форматная строка или список аргументов, заканчивающийся нулём.
Вычисление адресов аргументов вручную
Раз аргументы лежат в стеке последовательно, а адрес последнего обязательного аргумента можно узнать с помощью оператора взятия адреса, то самым очевидным способом взятия значений необязательных аргументов является их вычисление на основе адреса последнего обязательного.
Например, нужно написать функцию, которая вычисляет среднее арифметическое о переданных аргументов типа int. Первым аргументом является счётчик аргументов argc, остальными – числа, среднее которых нужно вычислять.
Поскольку типы всех аргументов одинаковые, адрес i-того аргумента равен &argc+i. Таким образом, функция выглядит так:
double average_i(int argc, ...)
{
int i;
double result=0;
for(i=1; i<argc; i++) result+=*(&argc+i);
result/=(argc-1);
return result;
}
Однако, если надо работать с аргументами разных типов, то возникает проблема: по правилам адресной арифметики их адреса будут вычислять так, будто они все одного типа.
Средства stdarg
Для работы со сложными наборами аргументов существуют макросы, описанные во входящем в стандартную библиотеку Си файле stdarg. h.
Для хранения указателя на текущий аргумент там описан типа данных va_list.
Макрос va_start(<указатель на аргумент>, <имя обязательного аргумента>) устанавливает указатель на аргумент на начало аргумента, следующего сразу после переданного. Например, чтобы установить указатель arg_ptr на начало аргумента, следующего после argc, надо написать va_start(arg_ptr, argc);.
Макрос va_arg(<указатель на аргумент>, <тип аргумента>) считывает из текущей позиции аргумент указанного типа и возвращает его значение. Значение указателя при этом увеличивается на размер считанного значения, иными словами, указатель переставляется на следующий аргумент.
Макрос va_end(<указатель на аргумент>) должен быть вызван, когда использование указателя на аргумент больше не нужно.
Например, функция, которая вычисляет среднее арифметическое аргументов типа double, будет выглядеть так:
double average_d(int argc, ...)
{
int i;
double result=0;
va_list arg_ptr;
va_start(arg_ptr, argc);
for(i=1; i<argc; i++) result+=va_arg(arg_ptr, double);
va_end(arg_ptr);
result/=(argc-1);
return result;
}
14)Работа компилятора Си
1. Препроцессорная обработка
2. Компиляция
a) Синтаксический анализ и Лексические ошибки
b) Семантический анализ -
b1) Ошибки в реализации алгоритма
b2) Распределение регистров
3. Ассемблирование
4. Компоновка
Препроцессорная обработка
Первой стадией обработки кода на Си является препроцессорная обработка. Её особенностью является то, что препроцессор рассматривает весь текст, кроме своих директив, как совершенно бессмысленный и бесструктурный набор символов, не производится анализа обрабатываемого текста. Именно поэтому аргументами макросов могут быть любые данные от отдельных символов до всего текста программы. Препроцессору можно передать и текст, не имеющий отношения не только к языку Си, но даже и к программированию вообще – ошибок это не вызовет, а если в тексте встретятся правильно написанные препроцессорные директивы, то они будут корректно обработаны. Тем не менее, обычно препроцессору передают код на языке Си, и на выходе получается также код на Си, только уже без директив.
Компиляция
После препроцессорной обработки начинается собственно компиляция, которая в свою очередь подразделяется на две стадии.
Синтаксический анализ
Первой стадией компиляции является синтаксический (лексический) анализ. На этой стадии компилятор выявляет, из каких лексем – минимальных единиц языка, имеющих смысл для компилятора – состоит текст: выявляются операторы, переменные, вызовы функций и так далее. На этом же этапе происходит удаление так называемого синтаксического сахара – конструкций, не являющихся самостоятельными лексемами, но включёнными в язык для удобства (например, квадратные скобки для обращения к элементам массива). Текст программы при этом преобразуется в промежуточный формат компилятора, который никакими стандартами не регламентируется и зависит от конкретной реализации.
Лексические ошибки
При лексическом анализе выявляются все синтаксические ошибки – участки кода, которые вообще не могут быть распознаны как лексемы. Примером синтаксической ошибки может быть не поставленная в нужном месте точка с запятой. Чаще всего такая ошибка делает бессмысленным только оператор, после которого она была пропущена, и следующий за ним, поэтому синтаксический анализ продолжается дальше, чтобы была возможность сразу сообщить программисту обо всех ошибках, которые присутствуют в тексте. Однако дальнейшей обработке текст не подвергается.
Семантический анализ
Вторым этапом компиляции является семантический анализ – преобразование созданного в ходе синтаксического анализа набора лексем в код на языке ассемблера. Каким образом это будет осуществляться, целиком зависит от языка программирования. Язык Си отличается от многих других тем, что всем его лексемам можно однозначно сопоставить коды на ассемблере, независимо от контекста. Поэтому семантический анализ компилятор выполняет за один проход по коду. Этим и обусловлен тот факт, что в самом языке нет ничего лишнего, все сложные операции осуществляют библиотечные функции – в Си нет ничего, что делало бы процесс компиляции кода сложным и неочевидным. За это свойство Си иногда называют «языком среднего уровня». Помимо собственно преобразования кода, семантический анализ решает ещё две задачи.
Ошибки в реализации алгоритма
Первая задача – это поиск ошибок в реализации алгоритма, таких как недопустимые преобразования типов, неправильные вызовы функций и прочих.
Распределение регистров
Вторая задача – это распределение регистров. Обращение к регистрам процессора идёт значительно быстрее, чем к оперативной памяти, а потому переменные лучше хранить именно в них. Если переменных меньше, чем регистров, то проблемы нет никакой. Но когда переменных больше, чем регистров, нужно определить, хранение каких именно переменных в регистрах больше всего ускорит работу программы, а какие можно оставить в оперативной памяти. Эта задача и называется распределением регистров.
Ошибки времени выполнения
В целом, результатом компиляции является код на языке ассемблера. Он обладает важным свойством – он не содержит ошибок, которые может выявить компилятор. Но это не гарантирует, что он не содержит ошибок вообще. Самым «опасным» видом ошибок являются ошибки при работе с памятью, которые очень сложно отследить. Попытки многократно освободить одну и ту же область динамической памяти, обращения по адресам, не входящим в адресное пространство программы, запись по адресу NULL – всё это приводит к аварийному завершению работы программы, причём обнаружены подобные ошибки могут быть только при работе программы, а потому их поиск и исправление – задача программиста.
Ассемблирование
После компиляции программа ассемблируется. Результатом ассемблирования является объектный файл. Он содержит информацию в машинном коде, однако запустить его невозможно: как и в коде, создаваемом компилятором, в объектном файле все обращения в функциям записаны как переходы по символьным меткам, а не по адресам, кодов же библиотечных функций объектный файл не содержит вовсе. Тем не менее, он является почти готовой программой, именно объектными файлами являются все библиотеки.
Компоновка
Создание исполняемого файла из объектного происходит на последнем этапе – компоновке (линковке). Линковка заключается в добавлении к файлу всех необходимых библиотечных функций, которые берутся в готовом виде из соответствующих объектных файлов библиотек, вычислении адресов всех меток, соответствующих замен переходов по меткам на переходы по адресам и добавления заголовка файла. Заголовок файла представляет собой записанную в самое начало файла служебную информацию, необходимую для его открытия. Практически всегда заголовок содержит информацию о формате файла и его размере, остальная информация зависит от характера содержимого
15)Методы сборки ----- Make-файлы
Так как многие программы состоят из многих десятков и сотен файлов, каждый из которых зависит друг от друга, то в UNIX-системах используются утилиты типа make(gmake) для обработки специальных Makefile. По сути эти файлы являются специальными скриптами, обрабатывая которые утилита собирает проект. MakeFile можно создавать как ручную, так и с использование специальных утилит.
Первые, и самые старейшие - это скрипты configure. После вызова скрипт просматривает систему на наличие необходимых для сборки библиотек и генерирует Makefile учитывая все зависимости, находящиеся системе, или же выдает ошибку, если какой-либо зависимости на хватает. Создание configure-файлов трудоемкое занятие, поэтому для из создания используются autotools и libtool.
Так же MakeFile с учетом зависимостей может быть создан утилитой cmake, которая аналогична autotools, но генерирует не configure-файл, а сразу MakeFile.
Ну и конечно же MakeFile можно создать вручную. Рассмотрим синтаксис простейшего MakeFile. Допустим у нас есть директория, в которой находится файлы ll. h, ll. c, main. c. При этом main. c зависит от ll. h и ll. c, а ll. c зависит от ll. h. Создадим в той же директории файл Makefile (команда touch Makefile). Откроем его и добавим туда основные цели сборки и зависимости:
main: main. o ll. o #исполняемый файл и его зависимости
ll. o: ll. h ll. c #объектный файл библиотеки связанного списка
main. o: main. c ll. h #объектный файл main
Теперь у нас есть цели, но нет правил сборки. Добавим их. Правила сборки каждой цели пишутся под строкой с целью и обязательно табулируются.
main: main. o ll. o
gcc main. o ll. o - o main
ll. o: ll. h ll. c
gcc - с ll. c - o ll. o
main. o: main. c ll. h
gcc - с main. с - o main. o
Теперь может попробовать выполнить сборку. напишем в терминале make. Утилита подхватит файлик и скомпилирует нам наш проект. Однако допустим нам надо добавить какие-нибудь флаги компиляции. Добавлять это в каждое правило сборки не логично. Лучше ввести переменную CFLAGS и задать в ней все необходимое. Перепишем наш Makefile так.
CFLAGS = - Wall - Wextra - O3
main: main. o ll. o
gcc $(CFLAGS) main. o ll. o - o main
ll. o: ll. h ll. c
gcc - с $(CFLAGS) ll. c - o ll. o
main. o: main. c ll. h
gcc - с $(CFLAGS) main. с - o main. o
Теперь при компиляции нам будут выводиться Warnings. Теперь добавим кроме цели сборки, цель для удаления полученных бинарных файлов. Обычно её называют [b]clean[/b], мы назовем так же. Команда rf производит удаление. Чтобы она не задавала много глупых и не нужных вопросов, добавим параметр - f, а для того случая, если какого-то файла не будет в директории, в конце припишем > /dev/null Тогда команда не выдаст ошибки.
CFLAGS = - Wall - Wextra - O3
main: main. o ll. o
gcc $(CFLAGS) main. o ll. o - o main
ll. o: ll. h ll. c
gcc - c $(CFLAGS) ll. c - o ll. o
main. o: main. c ll. h
gcc - c $(CFLAGS) main. c - o main. o
clean:
rm - f *.o main > /dev/null
Ну и наконец, чтобы привести наш файл к завершенному виду надо добавить цель сборки all. Это название обычно используют для сборки по умолчанию.
CFLAGS = - Wall - Wextra - O3
all: main
main: main. o ll. o
gcc $(CFLAGS) main. o ll. o - o main
ll. o: ll. h ll. c
gcc - c $(CFLAGS) ll. c - o ll. o
main. o: main. c ll. h
gcc - c $(CFLAGS) main. c - o main. o
clean:
rm - f *.o main > /dev/null

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
