
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Теоретическая база:
1) Машина Тьюринга
Существует много различных архитектур ЭВМ, операционных систем, языков программирования. Поэтому когда встаёт вопрос о принципиальной разрешимости задачи, нельзя привязываться к конкретным условиям. Для этих целей существует абстракция, называемая Машиной Тьюринга. Эта машина состоит из бесконечной ленты, разделённой на ячейки, по которой движется управляющее устройство. Управляющее устройство может считать символ, хранящийся в ячейке, и в зависимости от того, каким будет этот символ, переместиться вправо или влево, или остаться на месте, но при этом записать в ячейку новое значение. Конкретные правила движения управляющего устройства определяются алгоритмом, реализуемым данной машиной Тьюринга.
Полнота по Тьюрингу
Тезис Чёрча-Тьюринга гласит, что любая функция, которая может быть вычислена физическим устройством, может быть вычислена машиной Тьюринга. А потому если какая-то задача не может быть решена с помощью машины Тьюринга, она не может быть решена вообще. Разумеется, никто не занимается решением практических задач с помощью моделей машины Тьюринга, для практических задач существуют языки программирования. Отсюда появляется понятие полноты по Тьюрингу: тьюринг-полным языком называется язык, всем элементам которого можно поставить в соответствие алгоритмы для машины Тьюринга.
Все применяемые на практике языки программирования являются, а естественные языки не являются тьюринг-полными. Таким образом, можно сформулировать понятие программирования как процесс перевода задачи с неполного по Тьюрингу языка на тьюринг-полный.
Фон-неймановская архитектура
|
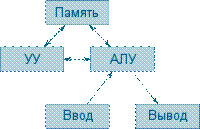
Существует много различных архитектур вычислительных машин, такие как троичные, аналоговые, пневматические вычислительные машины и многие другие. На практике же подавляющее большинство вычислительных машин относятся к фон-неймановской архитектуре. Фон-неймановской машиной называют ЭВМ, построенную по следующим критериям:
Состоит из арифметико-логического устройства (АЛУ), устройства управления (УУ), запоминающего устройства, устройств ввода-вывода. АЛУ и УУ, объединённые в центральный процессор (ЦП), определяют действия, подлежащие выполнению, считывая команды из оперативной памяти (ОЗУ). Машина работает в двоичном коде.Программы и данные хранятся в одном и том же пространстве памяти.
Языки высокого уровня
Далеко не всегда для написания программы требуется иметь полный контроль над процессором. Чаще всего на первый план выходят такие задачи, как быстрое написание читаемого и переносимого кода. Для этих целей были созданы языки высокого уровня.
Язык программирования высокого уровня – это язык программирования, в который введены не очевидные и часто неоднозначные в машинном коде смысловые конструкции. Перевод текста на языке высокого уровня в машинный код осуществляет специальная программа, называемая компилятором. Грамматика языка высокого уровня определяется не особенностями ЭВМ, а тем, какие классы задач предполагается решать на данном языке.
2)Парадигмы программирования, суть процедурного программирования
Императивный и декларативный подход
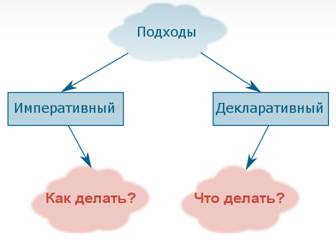
Все языки программирования делятся на две группы: декларативные и императивные:
- Программа на императивном языке программирования с математической точки зрения представляет собой общее решение поставленной задачи, иными словами, ответ на вопрос «как делать?». Это последовательность команд, которые должен выполнить исполнитель. Программа на декларативном языке программирования является сочетанием формализованной в рамках языка программирования задачей и всех необходимых для её решения теорем, проще говоря, ответ на вопрос «что делать?». Конкретную последовательность выполняемых действий выполняет компилятор, или чаще интерпретатор – программа, в реальном времени выполняющая код программы без его преобразования в машинный код.
Поскольку интерпретаторы декларативных языков сами решают поставленные задачи, возникает вопрос, какими методами им пользоваться. Языки, работающие в рамках аппарата дискретной математики, называют функциональными, а работающие с математической логикой – логическими.
Подпрограмма
Основным средством упрощения как написания, так и последующего чтения программ является разбиение исходной большой задачи на множество более мелких подзадач. И если решением общей задачи будет программа, то решением каждой из мелких подзадач – подпрограмма. В наиболее общем случае подпрограмма — это поименованный участок кода программы, перейти к выполнению которого можно из любой точки программы, и после выполнения которого происходит возврат в исходную точку. Опционально подпрограмма может иметь одно или несколько значений, передаваемых ей перед запуском и называемых аргументами (иногда параметрами), а также какое-то значение (одно), являющееся результатом выполнения подпрограммы, которое она после своего выполнения возвращает в место, откуда была вызвана. Обычно подпрограмму, возвращающую значение, называют функцией.
3) Представление числовой информации в двоичном коде
Представление целых беззнаковых чисел
Проще всего эта проблема решается для случая целых беззнаковых (то есть, все данные имеют только один знак, который поэтому можно опустить) чисел. Перевод такого числа из десятичной системы в двоичную можно осуществить с помощью целочисленного деления по следующему алгоритму:
Если текущее число меньше 2, то записать его в младший разряд результата, выполнение прекратить. Иначе, разделить текущее число с остатком на 2. Остаток записать в младший разряд результата. Применить пункт 1 к частному.Это можно наглядно продемонстрировать с помощью деления «уголком».
Представление целых знаковых чисел
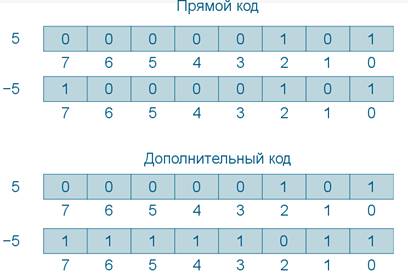
Итак, представление целых беззнаковых чисел в двоичном коде проблемы не составляет. Возникает вопрос, что делать с целыми знаковыми числами. Первое и очевидное решение – это использовать старший бит двоичного числа для хранения знака: 0, если знак «+» и 1, если знак «-». Подобное решение называют прямым кодом. Например, для случая 8-разрядной системы, 6510=, а -6510=. Однако данная система создаёт серьёзную проблему: a+b-a+(-b). Действительно: 110010=0, а +=, что абсурдно. Значит, нужно на уровне процессора отдельно определять операции сложения и вычитания, всегда следить за тем, чтобы вычисления производились с числами одного знака. Знак же результата определять путём сравнения исходных чисел.
Дополнительный код
Существует другое, не вполне очевидное на первый взгляд, но очень эффективное решение – дополнительный код. Чтобы изменить знак числа в дополнительном коде, нужно выполнить такую операцию? a=a+1, где черта над буквой – знак инверсии, замены всех нулей единицами, а единиц нулями. 6510=, а?6510=. Попробуем сложить эти два числа – получим 1 , то есть, 256. Вспомним, однако, что мы работаем с 8-разрядной системой, а число 1 в ней записать невозможно. Поэтому старший бит 1 выйдет за границы числа, и в итоге останется , что является верным. Интересно заметить, что старший бит числа по-прежнему отвечает за знак, а потому можно использовать его значение для того, чтобы узнать знак числа. Но уже нельзя использовать простую инверсию старшего бита для смены знака. Тем не менее, такое небольшое усложнение операции смены знака ведёт к огромному упрощению остальных операций – их можно производить, не задумываясь о знаке, результат всегда будет верным.
Представление чисел с фиксированной запятой
Следующим этапом усложнения типов представляемых данных является представление десятичных дробей. Исторически первым явилось решение представлять их в формате с фиксированной запятой (точкой) [1]. При этом определённое количество бит числа отдаётся под целую часть, а остальные разряды – под дробную. Несложно заметить, что такое представление данных является во многом искусственным, поскольку достаточно домножить все вводимые данные на 2число бит дробной части, чтобы полностью избавиться от необходимости применения записи с фиксированной запятой. К тому же, такая запись сильно ограничивает диапазон возможных значений чисел.
Представление чисел с плавающей запятой

На практике применяется метод записи чисел в формате с плавающей запятой (точкой). Этот формат представляет собой компьютерную реализацию экспоненциальной записи чисел. Представление чисел с плавающей точкой определяется стандартом IEEE . В соответствии с этим стандартом, разряды, выделенные для представления числа, делятся на три поля: S, E и M. Поле S представляет собой один бит, отвечающий за знак числа (0, если «+» и 1, если «−»). Поле E — это набор бит, количество которых зависит от конкретного типа данных, выделенный под экспоненту[2]. Проблема хранения отрицательных значений экспоненты решается следующим образом: к реальному значению экспоненты добавляется число 2(число бит экспоненты)-1. Например, в случае восьмиразрядной экспоненты, =−12710, а =210. Поле M представляет собой набор бит, выделенный под мантиссу. Мантисса в компьютере имеет важную особенность: всегда верно неравенство 1≤M<2. За счёт этого её целая часть всегда равна 1, а потому при вычислениях отбрасывается. Таким образом, мантисса представляет собой целое беззнаковое. Стандартом IEEE предусмотрено три типа чисел с плавающей точкой:
- В 32-битном типе, называемом так же вещественным одинарной точности, под мантиссу выделены биты с 0 по 22, под экспоненту — с 23 по 30, 31 — под знак. Этот тип позволяет хранить числа от -3,4∙1038 до 3,4∙1038. В 64-битном типе, называемом так же вещественным двойной точности, под мантиссу выделены биты с 0 по 51, под экспоненту — с 52 по 62, 63 — под знак. Этот тип позволяет хранить числа от -1,79∙10308 до 1,79∙10308. В 80-битном типе, называемом так же вещественным расширенной точности, под мантиссу выделены биты с 0 по 63, под экспоненту — с 64 по 78, 79 — под знак. Этот тип позволяет хранить числа от -1,18∙104392 до 1,18∙104392.
Вычисления с плавающей точкой осуществляет математический сопроцессор.
Возникает вопрос — какова точность этих вычислений? Запишем для каждого типа минимальное по модулю представимое в нём число. Для 32-битного это будет 1,8∙10-38, для 64-битного — 2,23∙10-308, для 80-битного — 3,37∙10-4392. Соответственно, любое число, которое по модулю меньше этих чисел, компьютер не сможет отличить от нуля. Так возникает понятие машинного нуля. Ясно, что погрешность вычислений не может быть меньше машинного нуля. Но на самом деле она ещё больше. Существует понятие машинный эпсилон – это минимальное число, для которого неравенство 1+ε≠1, с точки зрения компьютера, верно. Доказано, что числа a и b неразличимы для компьютера, если 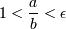
Помимо собственно вещественных чисел, тип с плавающей точкой позволяет кодировать два специальных обозначения: если экспонента равна своему максимальному значению, а мантисса равна нулю, то такой код считается бесконечностью со знаком. Если экспонента равна своему максимальному значению, а мантисса — не ноль, то такой код считается «не числом» (обозначается NaN). Это специальное значение, которое возвращают функции, когда их вызывают с аргументами, для которых они не определены. Например, NaN получится при попытке делить на ноль или извлечь квадратный корень из отрицательного числа.
4) Представление символьной информации в двоичном виде, кодировки
Представление текстовой информации
В принципе, перечисленных методов хватает, чтобы закодировать что угодно, поскольку любую информацию можно привести к числовой. Однако стоит рассмотреть один очень важный частный случай – текстовую информацию. Изначально требовалось кодировать только буквы латинского алфавита, цифры, а также небольшой набор спецсимволов. Для этого вполне хватает 128 различных значений, поэтому была создана 7-битная кодировка ASCII. Поскольку минимальной адресуемой единицей является байт (8 бит), старшие биты ASCII-кодов просто оставались нулевыми. Важной особенностью ASCII является то, что цифры от 0 до 9, буквы от a до z и от A до Z расположены по порядку, причём буквы верхнего и нижнего регистров отличаются только значением пятого бита. Однако с развитием компьютерной техники возникла необходимость кодировать больше символов, в том числе, другие алфавиты. Решение в данном случае очевидно – заполнять коды с единичным старшим битом. Но неоднозначен вопрос, каким образом это делать. Поэтому возникло огромное количество кодовых страниц – вариантов заполнения верхней части таблицы символов. Среди кириллических кодовых страниц особо следует выделить две: CP-1251 (Windows-1251) и KOI8-R. CP-1251 была создана в начале 90х годов при русификации операционных систем Windows. По причине большого распространения последних, эта кодовая страница является наиболее часто употребляемой. KOI8-R – это кодировка, возникшая в то время, когда была ещё очень распространена 7-битная ASCII, и не было гарантии, что большинство компьютеров будут отображать 8-битную кодировку корректно. Поэтому, KOI8-R построена таким образом, что при потере старшего бита русские буквы превращаются в их английские фонетические аналоги, что оставляло возможность прочитать текст. KOI8-R является стандартом де-факто 8-битной кодировки в Unix-подобных операционных системах.
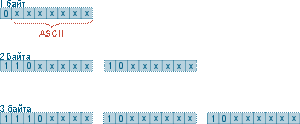
UTF-8
Естественно, что применение большого количества кодовых страниц приводило к сложностям в работе с текстами. Поэтому возникла идея создать кодировку, в которой бы отображались любые символы, которые только могут потребоваться при работе с текстом. Такой кодировкой стал изобретённый в 1991 году Юникод. В Юникоде зарезервировано 1 114 112 позиций для символов, на данный момент используется всего около 90000. Сам по себе Юникод кодировкой не является, это набор символов, на основе которого составляются кодировки. Одной из таких кодировок является UTF-8. Она не имеет постоянной разрядности, число байт, которое будет распознаваться как один символ, зависит от того, какой вид имеет считываемая последовательность:
Где x – какой-то бит. Несложно заметить, что представление однобайтовых символов UTF-8 совпадает с представлением символов ASCII, а потому любой текст в ASCII корректно отображается в UTF-8, а текст в UTF-8, состоящий только из символов ASCII, корректно отображается в ASCII.
Существует также кодировка UTF-32, в которой под каждый символ в любом случае выделяется 4 байта. Она не экономична с точки зрения расхода памяти для большинства текстов, но значительно удобнее в обработке. Есть и промежуточный вариант — совместимая с UTF-8 кодировка UTF-16, в которой под символ выделяется от 2 до 4 байт.
5)Структура оперативной памяти, порядок следования байт
Оперативная память
Основным накопителем информации, используемым в программировании, является оперативная память. Оперативная память представляет собой набор однобайтовых ячеек, каждой из которых присвоен свой индивидуальный номер, называемый адресом. Нумерация начинается с 1, поскольку номер ячейки памяти 0 зарезервирован как «пустой» адрес. На самом деле, в реальном адресном пространстве работает только операционная система. Для прикладных программ операционные системы реализуют плоскую (линейную) модель памяти (flat). В этой модели памяти каждая программа «видит», что ей предоставлена вся память, которая только может существовать в рамках данной архитектуры (4 гигабайта в архитектуре x86 и 1048576 терабайт[3] в архитектуре x64). Это достигается за счёт применения двух основных инструментов: файл подкачки и виртуальное адресное пространство.

Файл подкачки (swap) – это место на жёстком диске, выделенное для записи информации, не помещающейся в оперативную память. Операционная система перехватывает все обращения к памяти от прикладных программ и переадресует их таким образом, чтобы запросы от разных программ попадали в непересекающиеся области оперативной памяти или файла подкачки, если оперативная память закончилась. Таким образом, программа даже не может определить, идёт ли обращение в оперативную память, или в файл подкачки. Это называется виртуальным адресным пространством.
Виды оперативной памяти
Нецелесообразно рассчитывать сразу всё адресное пространство для каждой из задач, которых могут быть десятки. Поэтому изначально каждой программе выделяется минимум памяти. В связи с этим возникают различные виды памяти.
Статическая память — это область, в которой хранится сама программа в машинном коде и все константы, определённые в ней. Теоретически, программа может выполнять запись в неиспользуемый в данный момент участок собственного кода, что при большом мастерстве программиста позволяло делать самомодифицирующийся код. Однако в настоящее время имеются тенденции к включению в операционные системы систем защиты от записи в статическую память. Это вызвано тем, что в основном самомодифицируеющемся кодом обладают компьютерные вирусы, тогда как большинство остальных программ можно и нужно писать без применения этой технологии — она сильно снижает переносимость программ.
Стек
В общем случае стек представляет собой способ организации данных. Это набор значений, в который значение можно «положить» и из которого значение можно «взять», причём берутся значения в порядке обратном к тому, в котором они клались, этот принцип называется LIFO — Last In, First Out.
Интересующий нас стек также называется стеком вызовов. Это резервируемый для каждой программы участок оперативной памяти, для которого определены два адреса — дно стека, адрес самого первого элемента, после которого уже нельзя ничего из стека взять, и вершина стека — адрес последнего положенного элемента. Растёт стек в сторону младших адресов, то есть, дно стека имеет самый большой адрес, а когда в стек кладётся значение, значение вершины стека уменьшается.
Стек используется для двух важных целей. Во-первых, это хранение данных. Если Программе для своей работы потребуется известное число байт, то это место резервируется именно в стеке. Потом доступ к этим данным можно будет получить и по непосредственному адресу.
Во-вторых, стек применяется для хранения адресов возврата. При вызове подпрограммы требуется каким-то образом запомнить, откуда надо продолжить выполнение программы после завершения подпрограммы. Для этого адрес, идущий сразу за инструкцией перехода к подпрограмме, записывается в стек и называется адресом возврата. Стек применяется для хранения адресов возврата потому, что это позволяет делать несколько вызовов подпрограмм одной из другой, при этом порядок возврата будет корректным.
Таким образом, под стек выделяется столько места, сколько нужно программе для хранения данных, плюс запас на адреса возврата.
Динамическая память
Если же программе требуется ещё память, то она посылает запрос операционной системе, которая выбирает в оперативной памяти незанятый участок и начинает переадресовать запросы программы на него. При этом участок помечается как занятый, и адресация других программ на него невозможна. Как только программе этот участок памяти становится ненужным, она посылает запрос операционной системе, и он снова помечается как свободный. Такая схема называется динамическим распределением памяти, а память, выделенная таким способом – динамическая память.
Порядок следования байтов
Минимальной адресуемой единицей в оперативной памяти является байт. Поэтому когда число представляет собой несколько байт, возникает вопрос, в каком порядке их записывать.
Big-endian
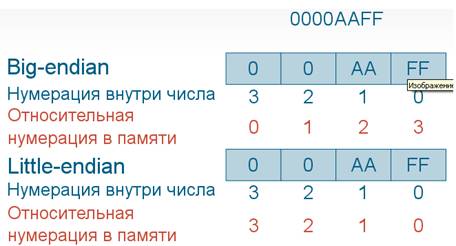
Наиболее естественным способом представляется взять число, разбить его на участки по 8 бит и, не меняя их порядка, записать в память. Адресом значения из нескольких байтов считается адрес его младшего байта. Но при этом нумерация байтов внутри числа идёт с конца, то есть для числа AAFF младшим байтом будет FF, а старшим — AA. Если же число в таком виде записать в память, то по младшему адресу будет находиться AA, а по старшему — FF, иными словами, число будет храниться «задом наперёд». Такой порядок хранения называется big-endian.
Little-endian
Если же числа при чтении и записи в память разворачивать, то многие вычисления упростятся. Возьмём четырёхбайтное число 0000AABB. Если его записать в память в порядке big-endian, а потом считать как двухбайтовое, то получится 0000. Если же его записать в little-endian, то оно будет выглядеть как BBAA0000, и при считывании как двухбайтового превратится в AABB, что соответствует истинному значению числа. Аналогичное верно и для других комбинаций. Поэтому little-endian является очень распространённым способом записи.
6)Этапы создания ПО
1)Постановка ТЗ
2)Выбор средств решения
3)Решение
4)Реализация
5)Отладка
6)Внедрение
7)Техническая поддержка
8)Реализация
9)Оптимизация по памяти
10)Оптимизация по времени выполнения
11) Оптимизация распараллеливания
Задачи, с которыми приходилось сталкиваться во время изучения данного курса, для своего решения требовали только знаний языка Си и базовых навыков в создании алгоритмов. На практике же приходится иметь дело с совершенно противоположной ситуацией: не вполне внятное с технической точки зрения задание и никаких указаний относительно его выполнения. Поэтому знание языка программирования и даже умение писать на нём хорошо оптимизированные и стабильно работающие программы – это важный, но не решающий элемент технологии создания программного обеспечения.
Постановка ТЗ
Первым этапом создания ПО является постановка технического задания (ТЗ). ТЗ представляет собой подробное и однозначное описание того, как программа должна работать. По сути, ТЗ – это полное описание программы как чёрного ящика. Чёрный ящик в информатике – это термин, означающий систему, о внутреннем устройстве которой неизвестно ничего, но у которого есть входы и выходы информации, зависимости между которыми можно изучать. Самым тривиальным примером чёрного ящика является библиотечная функция: про её реализацию неизвестно ничего, есть только её прототип. Чёрным ящиком является и программа с точки зрения пользователя, не знакомого с её исходным кодом. Описать программу как чёрный ящик – значит чётко себе представлять, как будет выглядеть работа пользователя с ней. Но ТЗ – это не просто описание работы программы. ТЗ обязательно должно состоять из математически разрешимых задач, тогда как задание, получаемое от заказчика, может из них и не состоять. Например, задача подавления голоса на фонограмме. Строгого математического решения она не имеет, поскольку звук, издаваемый речевым аппаратом человека, ничем не отличается от любого другого. Но можно воспользоваться каким-нибудь его свойством, которое даст приближённое решение для большинства случаев. Например, можно воспользоваться тем, что чаще всего голос записывается одинаково на оба стереоканала, а инструменты – несимметрично, или предположить, что все инструменты звучат строго на частотах, равных частотам музыкальных нот, а голос – нет. Тогда ТЗ будет заключаться в написании программы, удаляющей одинаковые в обоих каналах частотные составляющие, либо удаляющей все составляющие, не равные частотам нот. И то, и другое – уже разрешимые задачи. Поэтому постановка ТЗ считается самым сложным этапом разработки ПО. Она требует от человека знаний как в предметной области, так и в математике и умения учитывать человеческий фактор: какие-то допущения могут неверными с математической точки зрения, а человеком, далёким от математики, восприниматься как верные и совершенно естественные.
Выбор средств решения
Вторым этапом является выбор средств решения задачи. Это не значит, что сразу после постановки ТЗ нужно определить среду разработки и набор используемых библиотек. Нужно определить парадигму, в рамках которой будет решаться задача, поскольку решения, сделанные в рамках разных парадигм, будут различаться даже в общих чертах. Нужно также определить, какие ресурсы будет требовать программа, какими возможностями пользоваться можно, а какими нет.
Решение
После выбора средств решения начинается собственно решение. Если используются декларативные языки, то решение заключается в строгой математической формализации задачи и теорем, которые могут понадобиться для её решения. Если используются императивные языки, то разрабатывается алгоритм решения. Но в процедурном и объектно-ориентированном программировании подходы в разработке алгоритма разные. В ООП разработка начинается с описания всех объектов, которые могут встретиться при решении задачи, и методов работы с ними. Таким образом, к моменту, когда надо приступать к решению задачи, уже имеется мощный набор средств для её решения, который позволит сделать это решение простым и красивым.
Метод пошаговой детализации
Противоположный подход, называемый методом пошаговой детализации, применяется в процедурном программировании. Суть этого метода в том, что сначала алгоритм разрабатывается в самых общих чертах, абстрагировано от его возможной реализации. Иными словами, за элементарные принимаются действия, которых заведомо нет среди средств предполагаемого языка программирования. После этого необходимо написать алгоритмы уже для этих действий. Таким образом, задача разбивается на множество подзадач, которые в свою очередь также могут быть разбиты. В итоге получается большой набор несвязанных между собой несложных задач, решение которых можно поручить большой команде программистов, не обладающих знаниями в предметной области, поскольку поручаемые им задания от неё далеко абстрагированы. После получения решений подзадач требуется объединить их в одно решение задачи, постепенно поднимаясь к уровню первоначальной задачи. И чем выше задача расположена в этой пирамиде, тем более глубокими знаниями в предметной области, и вообще квалификацией, должен обладать программист.
Реализация
Следующим этапом является реализация разработанного алгоритма на конкретном языке программирования. На этом этапе уже нет никакой абстракции от языка и доступных библиотек, всё должно быть сделано в рамках существующих средств. Этот этап тесно связан с предыдущим, поскольку на каком-то уровне разбиения задачи уже может быть нецелесообразным абстрагирование от языка.
Отладка
После написания программы идёт её тестирование и отладка. Тестирование – это решение с помощью программы задач, решения которых известны заранее, с целью проверки правильности её написания. Алгоритм – это математическое понятие, а потому, формализовав исходную задачу, можно строго доказать верность алгоритма её решения. Но это будет дольше и сложнее всех остальных этапов, вместе взятых, а потому применяется только в теории алгоритмов, а не для прикладных задач. Поэтому считается, что если программа корректно обрабатывает как предположительно сложные для обработки наборы входных данных, так и среднестатистические, то и все остальные данные она, скорее всего, обработает корректно. С формально точки зрения это совершенно неверно, но на практике почти повсеместно приходится делать такое допущение: если что-то верно для большинства случаев, то оно считается верным для всех случаев. Тестирование выявляет так называемые ошибки времени выполнения – те ошибки, которые не обнаруживаются при компиляции. Процесс локализации и исправления таких ошибок называется отладкой. Для отладки существуют специальные программы – отладчики. Отладчик позволяет пошагово выполнять программу, отслеживая значения регистров, переменных, выполняемые системные вызовы и прочее. Отладчик гарантированно позволяет узнать, в каком месте программа аварийно завершается, но не всегда возможно понять, какому оператору в исходном коде программы соответствует выявленная отладчиком процессорная инструкция, особенно при высоких уровнях оптимизации. Поэтому, помимо отладчиков, существуют профилировщики, автоматизирующие процесс отладки программы. Профилировщики выполняют множество задач по анализу программы, в числе прочего: анализ утечек памяти, определение частоты использования различных участков кода (эта информация может использоваться, чтобы сильнее всего оптимизировать часто используемые участки и выделить редко используемые в подключаемую только при необходимости библиотеку), анализ ресурсов, используемых при работе программы, выявление бесконечных циклов и многое другое.
Внедрение
После того, как программа успешно пройдёт все тесты, начинается работа по её внедрению. Например, если речь идёт об Open Source приложении, то внедрение будет представлять собой добавление её в основные репозитории, чтобы её было проще устанавливать.
Техническая поддержка
Последним этапом является техническая поддержка и модификация. Бывает, что какую-то ошибку можно выявить только при очень длительной работе или при каких-то ситуациях, которые не были рассмотрены при тестировании. Тогда об ошибках разработчик может узнать только от пользователя. Тогда, узнав об ошибке, разработчики выпускают специальную программу, называемую патчем, которая исправляет установленную ошибку в уже установленной программе. Периодически также могут выходить новые версии программы – с внесёнными исправлениями, более оптимизированные, обладающие дополнительными функциями. Помимо изменения программы, разработчик также может оказывать пользователям помощь в настройке и использовании программы, называемую технической поддержкой. Причём чаще всего поддержка проприетарных программных продуктов бесплатная и является дополнительным аргументом для привлечения возможного покупателя, а поддержка open source программ платная и является одним из основных источников дохода компаний, разрабатывающих ПО.
Оптимизация
Одну и ту же задачу часто можно решить с помощью разных алгоритмов, не говоря уже о том, что алгоритм можно реализовать разными способами. Зачастую выбор между средствами решения диктуется простотой и распространённостью средств, необходимых для их реализации. Но для требовательных к ресурсам алгоритмов важно минимизировать расход какого-либо ресурса: времени, памяти, количества обращений к внешним ресурсам и т. п.
Процесс изменения характеристик алгоритма без изменения результатов его работы называется оптимизацией.
При оптимизации обычно один параметр улучшается за счёт ухудшения другого. Чаще всего оптимизация бывает по памяти и по времени выполнения.
Оптимизация по памяти
Раньше, когда процессоры ускорялись очень легко – обычным повышением тактовой частоты – а наращиванию памяти препятствовала низкая разрядность процессора и файловой системы, оптимизировать программы приходилось в основном по памяти.
Оптимизация по памяти означает написание алгоритмов с минимальным числом переменных, минимальным размером самого кода. Участки кода, повторяющие хотя бы несколько раз, выделяли в подпрограммы.
Оптимизация по времени выполнения
Сейчас ограничения на рост количества памяти практически сняты, и теоретический предел сильно превышает технически достижимый а данный момент. В то же время производительность процессоров растёт черезвычайно медленно. Поэтому в основном приходится оптимизировать алгоритмы по времени выполнения.
Типичный пример оптимизации по времени выполнения – динамическое программирование. За счёт сохранения результатов промежуточных вычислений уменьшается время выполнения, но требуется дополнительная память для хранения этих результатов.
Другие приёмы оптимизации по времени выполнения основаны на минимизации затрат времени на переходы и вызовы функций.
Inline-функкци
Если время выполнения функции соизмеримо с временем, затрачиваемым на её вызов, то она делается inline-функцией. Inline-функция – это функция, код которой подставляется во все места, где вызывается. Таким образом, не тратится время на переход. При этом код функции существует и отдельно, чтобы к нему можно было обратиться по указателю.
В языке Си для объявления inline-функции перед её объявлением надо написать слово inline. Например:
inline int add(int a, int b) {return a+b;}
Развёртка циклов
Оптимизацией занимается не только программист, но и компилятор. В частности, циклы, число итераций которых известно заранее, переписываются им в виде последовательности инструкций, не содержащей переходов.
Оптимизация распараллеливания
Повышение производительности современных процессоров в значительной мере достигается за счёт параллельной работы нескольких ядер. Поэтому программы стоит писать так, чтобы они легко разбивались на несколько подзадач, которые можно выполнять параллельно.
Например, стоит задача занести в массив array длины len числа, являющиеся членами арифметической прогрессии с первым членом a1 и разностью d. Эту задачу можно решить так:
array[0]=a1;
for(i=1; i<len: i++) array[i]=array[i-1]+d;
Все итерации такого цикла нужно выполнять последовательно, так как значение, которые будет получено в следующей итерации, зависит от предыдущего.
Но этот цикл можно переписать иначе:
for(i=0; i<len; i++) array[i]=a1+(i-1)*d;
В таком виде значение, полученное в текущей итерации, однозначно определяется её номером, так как зависит только от этого номера и констант a1 и d, определённых ранее. Поэтому итерации можно выполнять как угодно. В многопроцессорной или кластерной системе это позволит выделить различным исполнителям различные участки задачи, чтобы они выполнялись параллельно, тем самым получив увеличение скорости выполнение во столько раз, сколько исполнителей содержится в системе, считая, что у них одинаковая производительность.
Основы языка СИ:
1)Переменные и типы данных, escape-последовательности
Переменные и типы данных
При написании программ неудобно обращаться к объектам в памяти по непосредственным адресам. Чтобы хранить данные в языках высокого уровня есть переменные. Переменная — это поименованная область оперативной памяти. Отсюда следует характеристика переменной — это её адрес. Но одного адреса недостаточно, чтобы узнать, что хранится по нему: ведь неизвестно, сколько байт требуется считать и как их интерпретировать. Поэтому другим неотъемлемым качеством переменной является её тип. Тип данных определяет, сколько байт надо считывать с указанного адреса, и как их интерпретировать. Если мы имеем адрес и тип данных, то мы можем говорить о значении — результате интерпретации считанных байтов.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
