
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Поскольку любая последовательность символов, начинающаяся со знака %, трактуется как управляющая, чтобы вывести этот знак на экран, его надо написать два раза: %%.
В общем виде управляющая последовательность выглядит так:
%[<флаги>][<ширина>][.<точность>][<размер>]<тип>
Флаги
В необязательном поле «флаги» могу стоять следующие символы:
Символ | Значение |
'-' | Выравнивание по левому краю в рамках указанной ширины (по умолчанию – по правому краю). Если ширина не указана - игнорируется. |
'+' | Указывать знак числа, даже если это плюс. |
'0' | Заполнять нулями свободное пространство слева от выводимого значения, до ширины, указанной в поле «ширина». Если указана точность или не указана ширина, этот флаг игнорируется. |
Ширина
В необязательном поле «ширина» указывается минимальное количество символов, которые будут зарезервированы под вывод. Если требуется больше символов – выделяется больше, если меньше – оставшиеся по умолчанию заполняются пробелами. Если в поле «ширина» стоит знак '*', то в качестве значения ширины будет взят аргумент printf, стоящий перед выводимой величиной.
Точность
В необязательном поле «точность» указывается максимальное количество знаков для строк, минимальное количество знаков для целых чисел или максимальное количество знаков поле запятой для чисел с плавающей точкой.
Тип
Поле «тип» является обязательным, в нём указывается способ интерпретации входных данных. Есть следующие типы:
Тип | Значение |
'd', 'i' | Целое десятичное |
'o' | Восьмеричное беззнаковое |
'x', 'X' | Целое шестнадцатеричное, x выводит буквы в нижнем регистре, а X – в верхнем |
'f' | С плавающей точкой |
"lf" | С плавающей точкой двойной точности |
'e' | Экспоненциальная форма записи числа с плавающей точкой |
'c' | Выводится символ, ASCII-код которого равен значению переменной |
's' | Строка |
'p' | Указатель |
Возвращаемое значение
printf имеет тип int и возвращает число реально выведенных символов. Если произошла ошибка – возвращает отрицательное число.
scanf
Для считывания символов с клавиатуры используется функция scanf. Первым её аргументом является форматная строка, а последующими – указатели на переменные, в которые нужно записать считанные значения.
Управляющие последовательности
Управляющие последовательности scanf очень похожи на последовательности для printf, но с некоторыми отличиями.
Тип i отличается от d. d интерпретирует считываемое число как десятичное, а i – в зависимости от его вида. Если число начинается с 0x, то как шестнадцатеричное, а если с 0 – как восьмеричное.
s интерпретирует как строку только последовательность символов, не содержащую пробелов.
c с явно указанной шириной считывает не один символ, а последовательность символов, причём она может содержать пробелы.
Если управляющие последовательности разделены пробелами, то scanf игнорирует любое количество пробелов, разделяющее вводимые значения.
Возвращаемое значение
scanf возвращает число, равное числу аргументов, которые действительно были корректно считаны.
Перенос строки
scanf после своей работы оставляет в буфере клавиатуры символ переноса строки. Если в программе для ввода используется только scanf, то в этом нет ничего страшного, эти символы она игнорирует. Но если помимо scanf используется getchar, то сразу после использования scanf нужно убрать из буфера ненужный символ, для этого после неё пишется getchar:
scanf("%e", &number);
getchar();
5)Работа с динамической памятью
Функции для работы с динамической памятью определены в файле stdlib. h.
Выделение памяти
malloc
Функция malloc (от англ. memory allocation) запрашивает у операционной системы место в динамической памяти. Сколько байт будет запрошено, определяется её единственным аргументом типа int. Она имеет тип void* – безтиповый указатель. Этот указатель представляет собой только адрес в памяти, без указания типа данных, которые там находятся. Чтобы что-то сделать с этим указателем, его надо преобразовать в указатель на конкретный тип. Например, мы хотим создать массив c длиной в 500 элементов. Это делает следующий код:
char* c;
c=(char*)malloc(500);
В первой строке объявляется указатель на переменную типа char, который пока никуда не указывает. Во второй строке запрашивается 500 байт динамической памяти. Безтиповый указатель на первый байт этой последовательности преобразовывается в указатель типа char* и записывается в переменную c. Теперь с c можно обращаться как с обычным массивом. Массив, находящийся в динамической памяти называется динамическим массивом. В случае, если выделить память не удалось (сбой, нехватка памяти…), указатель имеет значение NULL. В реальных программах следует писать код, обрабатывающий ситуацию получения нулевого указателя.
sizeof
Но что если мы хотим выделить место под переменные размером в несколько байт? Для этого есть оператор sizeof(<тип>). Он возвращает значение длины переменной данного типа в байтах. Например, sizeof(int)==4 в большинстве архитектур. Тогда, чтобы выделить место под массив из элементов типа int, следует написать так:
int* a;
a=(int*)malloc(500*sizeof(int));
realloc
Функция realloc (от англ. reallocation) изменяет размер участка выделенной по данному адресу памяти. Первым аргументом ей передается указатель на участок, который требуется изменить, а вторым – требуемый размер в байтах. Например:
a=(int*)realloc(a, (600*sizeof(int));
c=(char*)realloc(c, (10*sizeof(char));
Функция realloc может как увеличивать, так и уменьшать объём выделенной памяти. При увеличении объёма существующие элементы массива не изменяются, при уменьшении удаляются только последние. Если передать функции realloc указатель NULL, то она будет работать как malloc.
Освобождение памяти
Функция free нужна чтобы избавиться от данного участка динамической памяти, когда он станет не нужен. Её единственным аргументом является указатель, выделенная под который память будет освобождена. Адрес, записанный в указатель, после этого станет недоступен программе, а попытка обратиться к нему приведёт к аварийному завершению работы. Поэтому сразу после использования free рекомендуется присваивать указателю значение NULL. Например:
free(a);
a=NULL;
6)Рекурсия в языке Си
Алгоритм является частным случаем определения, поэтому код функции можно с полным правом считать определением понятия, которое она вычисляет, в терминах языка Си.
Отсюда следует, что в языке Си рекурсией следует называть ситуация, в которое функция вызывает саму себя. Существует и ещё один вид рекурсии — косвенная рекурсия — вызов функцией другой функции, которая вызывает первую.
Надо отметить, что условие выхода из рекурсии должно следовать раньше, чем рекурсивный вызов, иначе процессор «не увидит» это условие.
Рекурсивный и итерационный подход к решению задач
В принципе, любую задачу, решаемую с помощью рекурсии, можно решить и без неё, обходясь только циклами. С одной стороны, рекурсия обычно вызывает лишний расход памяти, необходимой для хранения адресов возврата. С другой, рекурсивные решения зачастую гораздо более наглядны. Рассмотрим, как одни и те же задачи можно решать разными способами.
Числа Фибоначчи
Рекурсивное решение задачи вычисления чисел Фибоначчи напрашивается из определения:
int fib_r(int n)
{
return(n==1||n==2)?1:fib_r(n-1)+fib_r(n-2);
}
Теперь проанализируем эту задачу. Чтобы посчитать любое число Фибоначчи нужно знать только два предыдущих. Если мы хотим посчитать значение третьего числа, то достаточно просто сложить известные значения первого и второго. Для четвёртого же числа достаточно знать только значения третьего и второго, первого уже нет. Отсюда, составляем такую функцию:
int fib_i(int n)
{
int prev=1, prevprev=1, cur, i;
if(n<3) return 1;
for(i=3; i<=n; i++)
{
cur=prev+prevprev;
prevprev=prev;
prev=cur;
}
return cur;
}
Теперь оценим, насколько эти функции требовательны к ресурсам.
В итерационной функции цикл в любом случае будет пройден n-2 раз[1], а количество памяти, которое она требует, вообще не зависит от переданного значения[2].
В рекурсивной функции уже наблюдается очень сильная зависимость поведения от переданного значения. Для первого и второго числа она будет вызвана один раз, для третьего — два, для четвёртого — четыре. Для всех последующих чисел функция будет вызвана 2 раза и столько, сколько нужно для вычисления всех предыдущих. То есть, количество вызовов C функции fib_r для числа n будет равно:
- C1=1 C2=1 C3=2 C4=4 Для n>4 Cn=Cn-1+Cn-2+2
С учётом того, что время выполнения и расход памяти для одного вызова функции одинаков при любых переданных значениях, получим, что расход памяти и время выполнения растут быстрее[3] самой последовательности Фибоначчи! Это очень плохие характеристики. Уже для 42ого числа Фибоначчи количество вызовов превысит 800 тысяч. Поэтому алгоритмы, имеющие такие характеристики, считаются практически бесполезными, так как работают в чрезвычайно узком диапазоне значений. Хотя, у многих таких алгоритмов показатели можно улучшить, об этом будет сказано чуть позднее.
Сортировка массива
Пусть нам дан массив известной длины из элементов типа int. Надо сделать так, чтобы все элементы в нём были упорядочены по убыванию.
К решению задач подобного вида, называемых задачами сортировки, существует огромное количество подходов. Рассмотрим простейший, который вряд-ли имеет практический смысл, но очень нагляден.
Для начала определим аксиому — массив, состоящий только из одного элемента, отсортирован всегда. Заметим, что любой подмассив[4] отсортированного массива также отсортирован. Наконец, первый элемент отсортированного по убыванию массива всегда больше или равен любому другому элементу. Этого достаточно, чтобы составить такую функцию сортировки:
void sort_r(int* array, int len)
{
int i, temp;
if (len==1) return;
for(i=1; i<len; i++)
{
if(array[i]>array[0])
{
temp=array[i];
array[i]=array[0];
array[0]=temp;
}
}
sort_r(++array, --len);
}
Эта функция находит наибольший элемент массива, меняет его местами с нулевым и запускает саму себя для подмассива, начинающегося уже с первого элемента.
Заметим теперь, что работа этой функции для разных подмассивов отличается только тем, с какого элемента начинается обработка. Значит, её можно переписать и в таком виде:
void sort_i(int* array, int len)
{
int i, j, temp;
if(len==1) return;
for(j=0; j<len; j++)
{
for(i=(j+1); i<len; i++)
{
if(array[i]>array[j])
{
temp=array[i];
array[i]=array[j];
array[j]=temp;
}
}
}
}
Сравним эти функции. И та, и другая сначала проходит массив длины len, потом длины len-1, потом len-2 и так до 2. Иными словами, количество обращений к элементам массива равно len+(len-1)+(len-2)+...+2. Это арифметическая прогрессия, сумма которой равна (len+2)*(len/2) или 0,5len2+len. То есть, при больших len время работы пропорционально квадрату len.
Но при этом расход памяти итерационной функции от длины массива не зависит, а рекурсивная тратит одинаковое количество памяти на обработку каждого из len подмассивов. То есть, расход памяти у неё прямо пропорционален длине массива.
Итак, для большинства задач рекурсивные функции тратят больше ресурсов, чем итерационные. Хотя, есть и такие, на которых рекурсия и циклы показывают одинаковые результаты. Но при этом рекурсивные решения обычно бывают очень наглядными и красивыми. Поэтому выбор между рекурсией и циклами — это всегда компромисс между эффективностью и простотой.
Оптимизация хвостовой рекурсии
Из приведённых выше примеров рассмотрим две функции: вычисление факториала и сортировка массива. Обе эти функции являются рекурсивными, но между ними есть принципиальное отличие, становящееся заметным при детальном рассмотрении процесса их выполнения.
Рассмотрим функцию вычисления факториала:
int fact(int n)
{
return i==1?1:fact(n-1)*n;
}
Получив результат рекурсивного вызова, эта функция затем умножает его на переданный агрумент n. Грубо говоря, рекурсивный вызов находится в середине функции, и после его завершения ещё остаётся код, который нужно выполнить.
Но совершенно иная ситуация с сортировкой массива:
void sort_r(int* array, int len)
{
int i, temp;
if (len==1) return;
for(i=1; i<len; i++)
{
if(array[i]>array[0])
{
temp=array[i];
array[i]=array[0];
array[0]=temp;
}
}
sort_r(++array, --len);
}
Мало того, что здесь рекурсивный вызов находится в самом конце функции, так его результат, к тому же, вообще никому не нужен по причине отсутствия такового.
Немного приблизимся к тому, как же работает процессор. Вызов функции на машинном уровне осуществляется сохранением в стеке адреса возврата и перехода по адресу функции. Возврат же из функции -- извлечением адреса возврата из стека и переходом по нему.
Распишем это в неком Си-подобном псевдокоде, где определены следующие функции:
- push_ret() -- положить в стек адрес возврата. pop_ret() -- извлечь из стека адрес возврата. goto
<адрес> -- перейти по полученному адресу
Функция вычисления факториала будет выглядеть так:
//аргумент лежит в n
//результат будет записан в result
//i -- промежуточный буфер
fact:
if(1==n)
{
result = 1;
goto pop_ret();
{
else
{
i = n;
n = n-1;
push_ret();
goto fact;
result = result*i;
goto pop_ret();
}
Тот факт, что строка result = result*i; стоит между рекурсивным вызовом goto fact; и возвратом результата goto pop_ret(), обязывает нас после завершения "спуска" по значениям n начать "подъём".
Но рассмотрим функцию сортировки массива:
//указатель на массив в array
//длина массива в len
sort_r:
int i, temp;
if (len==1) goto pop_ret();
for(i=1; i<len; i++)
{
if(array[i]>array[0])
{
temp=array[i];
array[i]=array[0];
array[0]=temp;
}
}
array++;
len--;
puch_ret();
goto sort_r;
goto pop_ret();
Здесь мы видим, что в конце по сути просто так адрсе сначала кладётся в стек, а замет из него извлекается. Рекурсивный вызов стоит в самом конце функции, после него в функции ничего не происходит, только возврат. Такая рекурсия называется хвостовой.
Несложно заметить, что никаких скачков по адресам здесь ненужно вообще. Вот и уберём их:
//указатель на массив в array
//длина массива в len
sort_r:
int i, temp;
if (len==1) goto pop_ret();
for(i=1; i<len; i++)
{
if(array[i]>array[0])
{
temp=array[i];
array[i]=array[0];
array[0]=temp;
}
}
array++;
len--;
goto sort_r;
Вместо того, чтобы класть в стек адрес возврата, просто начнём выполнение функции сначала. И вот чудо: в функции, хоть она и по-прежнему вызывает себя, пропали все операции записи в стек. А это значит, что функция перестала тратить лишнюю память, получив линейный её расход.
Этот процесс называется оптимизацией хвостовой рекурсии. Его выполняет компилятор. Разумеется, не в псевдокоде (повторяю: код выше лишь похож на язык Си, но им не является!), а на языке ассемблера.
Таким образом, вполне допустимо использовать хвостовую рекурсию там, где можно применить циклы, но рекурсия удобнее.
7)Динамическое программирование
Причин у высокой требовательности рекурсивных алгоритмов две. Во-первых, это расход памяти под передаваемые аргументы адреса возврата и переменные. С этим ничего не поделаешь, но и увеличить расход памяти это может не более, чем на величину, прямо пропорциональную количеству вызовов.
Серьёзной же проблемой являются лишние вычисления. Рассмотрим функцию вычисления чисел Фибоначчи. Она сначала считает n-1 число, а потом заново начинает считать n-2, хотя оно уже было посчитано при первом вычислении. И так для каждого числа. Отсюда и получается такое время выполнения — основная масса вычислений идёт впустую. Но есть приём, называемый динамическим программированием, который позволяет избавиться от лишних вычислений.
Динамическое программирование — это сохранение результатов промежуточных вычислений для их дальнейшего использования.
Рекурсивная функция вычисления чисел Фибоначчи считает каждое число по много раз. Значит, нужно каждое вычисленное значение каким-то образом сохранять, а перед началом вычислений смотреть, не было ли текущее значение посчитано раньше. Логичнее всего для этой цели использовать массив, индексами в котором будут номера чисел Фибоначчи, а значениями элементов — сами числа. Соответственно, перед тем, как возвращать значение, функция должна заносить его в массив. Как же проверить, было ли значение вычислено раньше? В общем случае, пришлось бы создавать массив структур, состоящих из собственно значения и поля is_calculated, которое было бы равно 1, если значение посчитано, и 0 — если в нём мусор. Но в данном случае можно воспользоваться тем свойством, что число Фибоначчи не может быть равным 0: перед запуском функции инициализировать его нулями, а в функции просто смотреть значение.
Получается такая функция:
int fib_d(int n, int* values)
{
if((n==1)||(n==2)) return (values[n]=1);
if(values[n]) return values[n];
return (values[n]=(fib_d(n-1, values)+fib_d(n-2, values)));
}
Перед её запуском необходимо сделать следующее:
values=(int*)malloc(sizeof(int)*(n+1));
for(i=0; i<n; ++i) values[i]=0;
val=fib(n, values);
Насколько эта функция эффективна? Она вычисляет значение каждого числа только 1 раз, поэтому для вычисления n-ного числа нужно n запусков. Каждый запуск занимает одинаковое время, отсюда следует, что время выполнения и расход памяти прямо пропорциональны значению. Итерационная функция обладала лучшими показателями — у неё расход памяти был константным. тем не менее, полученный линейный расход памяти также приемлем. При этом функция, несмотря на использование динамического программирования, получилась короче и яснее итерационной.
Применять динамическое программирование следует осознано. Во-первых, оно применимо только к детерминированным функциям — таким, значения которых однозначно определяются набором аргументов. Например, функции, внутри которых происходит ввод значений с клавиатуры или другого устройства, или использующие псевдослучайные числа, к таким не относятся, поскольку для одинаковых наборов аргументов могут дать разные значения, запоминать эти значения бесполезно. Во-вторых, при вычислении значения функции действительно должны происходить лишние вычисления. Например, при вычислении факториала их нет вообще, и поэтому запоминать значения нет смысла использованы они не будут.
8)Связные списки
Односвязный список
Общее определение
Простейшей рекурсивной структурой данных является односвязный список. Определяется он следующим образом:
- Односвязным списком является пустой список, который не содержит ничего: [] (списки в формальном определении заключаются в квадратные скобки). Односвязным списком является элемент, называемый головой, и стоящий после него односвязный список, называемый хвостом: [x|L], где x — элемент, а L — какой-то список (прямая черта служит для разделения элементов).
Элементом списка может быть что угодно — число, указатель, даже другой список. Список является упорядоченной структурой данных, то есть, порядок элементов в нём фиксированный.
Например, [1|3|'a'|10] — это список, потому что его можно представить в таком виде: [1|[3|['a'|[10|[]]]]]. Строго говоря, второе представление и является единственно верным, первое — это только сокращённая запись.
Реализация на языке Си
Язык Си не позволяет задавать рекурсивные структуры напрямую, но поскольку элементом структуры может быть указатель на неё, списки можно реализовать через них.
Пустым списком будем считать указатель NULL. А непустым — указатель на такую структуру:
typedef struct ONE_WAY_LIST
{
int data;
struct ONE_WAY_LIST* tail;
} one_way_list;
Поле data — это данные, хранящиеся в списке. Разумеется, они могут быть заменены на любые другие. А tail — хвост списка.
В памяти такие списки будут выглядеть примерно так:

Создание
Функция создания односвязного списка длины len будет выглядеть следующим образом:
one_way_list *create_ow(int len)
{
one_way_list *first, *current; //указатель на первый и на текущий элемент нам нужны
по отдельности
int i;
if(!len) return NULL; //список нулевой длины — это пустой список, его и возвращаем
fisrt=(one_way_list*)malloc(sizeof(one_way_list)); //создаём первый элемент
first->data=input(); //заполняем поле head первого элемента
current=first; //выставляем указатель текущего элемента в начало
for(i=1; i<len; i++)
{
current->tail=(one_way_list*)malloc(sizeof(one_way_list)); //создаём хвост
списка
if(current->tail) current=current->tail; else break; //если хвост был создан
— переходим к его обработке
current->data=input(); //заполняем поле data первого элемента хвоста
}
current->tail=NULL; //хвостом последнего элемента делаем пустой список
return first;
}
Под функцией input в данном случае подразумевается любая функция, которая выделяет в динамической памяти место, заполняет его информацией и возвращает указатель на него.
Можно наглядно показать рекурсивную структуру списка, переписав функцию создания в рекурсивном виде. Для этого нужно определить следующие положения:
- Создание списка нулевой длины — это возврат указателя NULL. Создание списка ненулевой длины — это создание головы (одного элемента) и создание хвоста.
Получается такая функция:
one_way_list *create_ow_r(int len)
{
one_way_list *result;
if(!len) return NULL;
result=(one_way_list*)malloc(sizeof(one_way_list));
result->data=input();
result->tail=create_ow_r(--len);
return result;
}
Вывод на экран
Чтобы вывести связный список на экран, надо пройти по всем его элементам и для каждого задействовать функцию вывода output:
void print_ow(one_way_list* list)
{
one_way_list *current=list; //устанавливаем указатель на текущий элемент
while(current) //пока не дошли до конца....
{
output(current->data); //выводим голову
current=current->tail; //переходим к обработке хвоста
}
}
Вид функции otput для разных данных разный. Например, для целых чисел она выглядит так:
output(int data)
{
printf("%d\n", data);
}
Функцию вывода можно переписать и в рекурсивном виде:
void print_ow_r(one_way_list *list)
{
if(!list) return; //пустой список не выводится
output(list->data); //вывели голову
print_ow_r(list->tail); //выводим хвост
}
Вставка элемента
Одно из самых замечательных свойств списка — возможность вставки элемента в произвольную точку, не думая об остальных элементах.
Существуют три возможных случая:
Добавление элемента к пустому списку — создание нового списка из одного элемента. Добавление элемента в конец списка: нужно в последний элемента записать указатель на новый, а в новый — NULL. Добавление элемента между элементами A и B: в A нужно записать указатель на новый, а в новый — указатель на B, который был в A.В принципе, два последних случая можно объединить в один, поскольку третий превращается во второй, если указатель на B равен NULL.
Получаем такую функцию:
one_way_list *insert_ow(one_way_list *current, int data)
//Принимаем указатель на элемент, после которого нужно вставить новый, и данные, которые надо записать
{
one_way_list *temp=current;
if(!current) //Если пытаемся вставить элемент в пустой список — создаём новый
{
temp=(one_way_list*)malloc(sizeof(one_way_list)); //Выделяем место под новый элемент
temp->data=data; //Записываем в него переданные данные
temp->tail=NULL; //Делаем хвост из пустого списка
return temp; //Возвращаем указатель на полученный список
}
temp=current->tail; //Сохраняем указатель на хвост
current->tail=(one_way_list*)malloc(sizeof(one_way_list)); //Выделяем место под новый элемент
current->tail->data=data; //Записываем в него переданные данные
current->tail->tail=temp; //Возвращаем хвост на место, но уже после вставленного элемента
return current; //Возвращаем указатель на исходный элемент
}
Поиск первого вхождения элемента
Чтобы найти первое вхождение элемента в список, нужно обходить по очереди все элементы, пока не встретится нужный. Если он так и не встретился — возвращается NULL:
one_way_list* search_first(one_way_list *first, int data)
{
one_way_list *current=first;
if(!first) return NULL; //В пустом списке искомого элемента точно нет
while(current) //Пока не дошли до последнего элемента...
{
if(compare(current->data, data)) return current; //Если нашли нужный элемент — возвращаем указатель на него
current=current->tail; //Переходим к следующему элементу
}
return NULL; //Если ничего не нашли — возвращаем NULL
}
Под функцией compare понимается определённая для нужного типа данных функция, возвращающая 0 при неравенстве элементов, и 1 при равенстве. В случае целых чисел она выглядит так:
char compare(int num1, int num2)
{
return num1==num2;
}
Поиск всех вхождений элемента
Если нужно найти не только первое, но и возможные последующие вхождения элемента, то нужно возвращать уже не указатель на элемент, а массив указателей. Чтобы не беспокоиться о хранении его длины, его имеет смысл делать нуль-терминированным:
one_way_list **search_all(one_way_list* first, int data)
{
one_way_list *current=first;
one_way_list ** result=NULL;
int len=0; //для промежуточных вычислений счётчик длины массива понадобится
while(current)
{
if(compare(current->data, data)) //если нашли нужный
{
len++; //увеличиваем счётчик длины массива
result=(one_way_list**)realloc(result, (len*sizeof(one_way_list*))); //увеличиваем массив
result[len-1]=current; //записываем последним элементом найденный указатель
}
current=current->tail; //переходим к обработке хвоста
}
result=(one_way_list**)realloc(result, ((len+1)*sizeof(one_way_list*))); //увеличиваем массив
result[len+1]=NULL; //и пишем последним элементом завершающий NULL
return result;
}
Удаление
Поскольку список находится в динамической памяти, когда он становится ненужным, его надо удалить. После завершения программы вся выделенная ей динамическая память освобождается, однако злоупотреблять этим свойством не рекомендуется.
void wipe_ow(one_way_list* first)
{
oneway *temp=first;
while(first)
{
temp=first->tail;
free(first);
first=temp;
}
}
Двусвязный список
Односвязный список не всегда удобен в обработке: требуется постоянно хранить указатель на голову списка, а его потеря ведёт к потере части списка. От этого недостатка избавлена другая структура — двусвязный список, каждый элемент которого хранит указатель не только на следующий, но и на предыдущий элемент:
typedef struct BIDIRECTIONAL
{
void* data;
struct BIDIRECTIONAL* next;
struct BIDIRECTIONAL* prev;
} bidirectional;
Нахождение первого элемента
Двусвязный список удобен тем, что указатель на его первый элемент можно получить, имея только указатель на любой из элементов, таким циклом:
while(current->prev) current=current->prev;
Удаление элемента
Другое его несомненное преимущество — можно удалить элемент, зная только указатель на него, тогда как в односвязном цикле для удаления нужно знать указатель на предыдущий элемент.
Процедура удаления элемента из двусвязного списка разбивается на три случая:
- Удаление единственного элемента. Достаточно просто освободить всю выделенную под него память (включая память, выделенную под данные) и возвратить NULL, чтобы при использовании функции можно было понять, что список удалён. Удаление первого элемента. В поле prev второго элемента записать NULL и возвратить указатель на него, поскольку он теперь первый. Удаление любого другого элемента. В поле next предыдущего элемента надо записать указатель на следующий, а в поле prev следующего — указатель на предыдущий. Затем освободить ненужную память.
Получается такая функция:
bidirectional *delete_bd(bidirectional *item, bidirectional *list) //Получаем подлежащий удалению элемент и голову списка
{
bidirectional *temp;
if(!item) return list; //Результатом удаления пустоты из списка будет исходный список
if(!list) return NULL; //Из пустого списка ничего не удалишь
if(!(item->prev)&&!(item->next)) //Случай единственного элемента
{
free(item->data); //Освобождаем память, выделенную под данные
free(item); //Освобождаем память, выделенную под элемент
return NULL; //Получился пустой список — его и возвращаем
}
if(!(item->prev)) //Случай первого элемента
{
temp=item->next; //Сохраняем указатель на элемент, который станет первым
free(item->data); //Освобождаем память, выделенную под данные
free(item); //Освобождаем память, выделенную под элемент
return temp; //Возвращаем указатель на новый первый элемент
}
//Общий случай
item->next->prev=item->prev; //Записываем в следующий элемент указатель на предыдущий
item->prev->next=item->next; //Записываем в предыдущий элемент указатель на следующий
//Элемент отсоединён от списка, можно удалять
free(item->data); //Освобождаем память, выделенную под данные
free(item); //Освобождаем память, выделенную под элемент
return list; //Возвращаем голову списка
}
Создание списка
Функция создания двусвязного списка будет выглядеть так:
bidirectional* create_bd(int len)
{
bidirectional *current;
int i;
current=(bidirectional*)malloc(sizeof(bidirectional));
current->prev=NULL;
current->data=NULL;
for(i=1; i<len; ++i)
{
current->next=(bidirectional*)malloc(sizeof(bidirectional));
if(current->next) current->next->prev=current; else break;
current->next->data=input();
current=current->next;
}
current->next=NULL;
while(current->prev) current=current->prev;
return current;
}
9)Бинарные деревья
Примером структуры, определение и обработка которой практические невозможна без применения рекурсии, является бинарное дерево.
Общее определение
Бинарным деревом является:
- Пустое дерево. Элемент, называемый корнем, и два непересекающихся[6] дерева, называемых потомками: левое и правое.
Элемент, потомками которого являются только пустые деревья, называется листом, а имеющий в потомках хотя бы одно непустое дерево — ветвью. Элемент, потомком которого является данный, называется его предком.
Реализация на языке Си
По аналогии со списками, работать с деревьями мы будем с помощью указателей. Определять дерево будет такая структура:
typedef struct BINTREE
{
int data;
struct BINTREE* left;
struct BINTREE* right;
} bintree;
Пустым деревом будет считаться указатель NULL.
Например, дерево, данные в котором представляют собой целые числа, может быть расположено в памяти следующим образом:
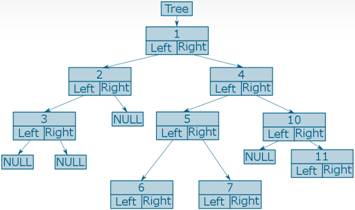
Для работы с деревьями существует несколько полезных алгоритмов.
Обход дерева
Есть задача: побывать в каждом элементе дерева и что-либо с ним сделать. При этом, дан указатель только на корень дерева.
Подобные задачи — пройти по всем элементам структуры данных, имея в начале указатель только на один из них — называются задачами обхода этой структуры данных.
Для списка задача обхода решалась тривиально: переходом к следующему или к предыдущему элементу. В случае же деревьев решений существуют много, отличаются они порядком посещения элементов. Рассмотрим простейшее решение:
- Обход пустого дерева невозможен. Обход непустого дерева — это действия с его корнем, обход левого поддерева и обход правого поддерева.
Получится такая функция:
void traversal_bt(bintree* tree)
{
if(!tree) return;
/*действия с корнем*/
traversal_bt(tree->left);
traversal_bt(tree->right);
}
Вывод на экран
Из функции обхода дерева элементарным образом получается функция вывода на экран:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
