


Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
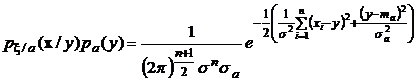 .
.
При вычислении интеграла заметим, что 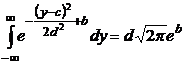 .
.
Поэтому, если привести показатель экспоненты к полному квадрату и воспользоваться приведенным свойством, то в результате интегрирования получим:
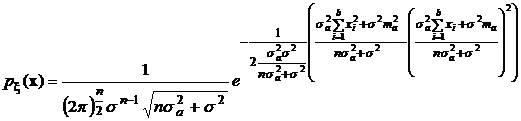 .
.
Условная плотность распределения примет вид:
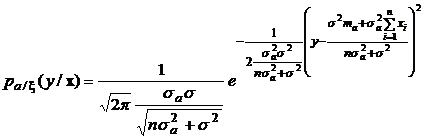 .
.
Как видим, это плотность распределения гауссовской случайной величины с математическим ожиданием 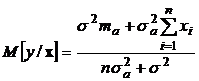 и дисперсией
и дисперсией 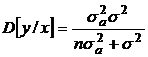 .
.
Таким образом, оптимальная оценка параметра ![]() имеет вид:
имеет вид:
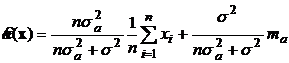 .
.
Заметим, что оценка есть весовая сумма выборочного среднего и априорного математического ожидания оцениваемого параметра. Сумма весов выборочного среднего и априорного математического ожидания равна единице (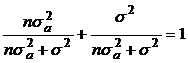 ).
).
Если априорная дисперсия оценки мала ![]() , то оценка в основном сосредоточена около априорного математического ожидания. Наблюдения в этом случае неинформативны. И, наоборот, при большой априорной дисперсии
, то оценка в основном сосредоточена около априорного математического ожидания. Наблюдения в этом случае неинформативны. И, наоборот, при большой априорной дисперсии ![]() оценка в основном определяется данными наблюдений (сосредоточена около выборочного среднего).
оценка в основном определяется данными наблюдений (сосредоточена около выборочного среднего).
4.2.2. Простая функция потерь
Пусть при оценке одного параметра функция потерь имеет вид (рис. 18). Эта функция потерь называется простой.
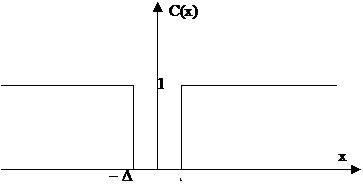
Рис. 18
Тогда оптимальная оценка должна находиться из решения следующей экстремальной задачи:
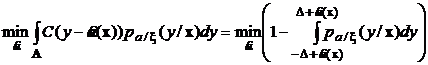 .
.
Заметим, что при малых значениях величины ![]() интеграл можно записать в виде (рис. 19):
интеграл можно записать в виде (рис. 19):
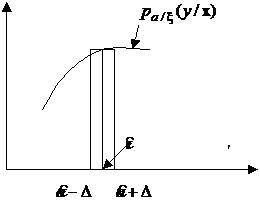
Рис. 19
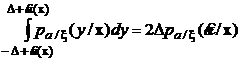 .
.
Поэтому оптимальная оценка параметра ![]() определяется как решение следующей экстремальной задачи:
определяется как решение следующей экстремальной задачи:
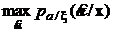 . (10)
. (10)
Заметим, что функция ![]() называется апостериорной плотностью распределения параметра
называется апостериорной плотностью распределения параметра ![]() , поэтому оценка, определяемая выражением (10) называется оценкой по критерию максимума апостериорной плотности вероятности.
, поэтому оценка, определяемая выражением (10) называется оценкой по критерию максимума апостериорной плотности вероятности.
Учтем, что 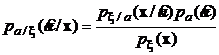 , поэтому оценку по максимуму апостериорной плотности вероятности можно записать также в виде:
, поэтому оценку по максимуму апостериорной плотности вероятности можно записать также в виде:
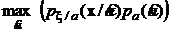 (11)
(11)
Здесь 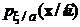 - называется функцией правдоподобия, а
- называется функцией правдоподобия, а ![]() - априорной плотностью распределения оцениваемого параметра.
- априорной плотностью распределения оцениваемого параметра.
Заметим, что оценка по максимуму апостериорной плотности вероятности может быть найдена путем поиска максимума любой монотонно возрастающей функции от апостериорной плотности вероятности. Очень часто в качестве такой функции берут натуральный логарифм:
 .
.
Рассмотрим предыдущий пример поиска оценки параметра распределения. В качестве критерия оптимизации возьмем критерий максимума апостериорной плотности вероятности.
Апостериорную плотность для этого случая мы уже находили. Она является гауссовской с математическим ожиданием . Максимум такой плотности будет в точке ее математического ожидания. Следовательно, оптимальная оценка по критерию максимума апостериорной плотности вероятности и по критерию минимума среднего риска при квадратичной функции потерь для этого случая совпадают.
Таким образом, в тех случаях, когда математическое ожидание есть точка максимума апостериорной плотности вероятности, оценки по критерию среднего риска при квадратичной функции потерь и максимума апостериорной плотности вероятности равны. В противном случае получаются разные алгоритмы оценок.
Заметим, что выбор функции потерь является не математической задачей, а задачей статистика, формирующего математическую модель явления, связанную с обработкой наблюдаемых данных.
4.2.3. Оценки максимального правдоподобия
Рассматривая критерий максимума апостериорной плотности вероятности (11) заметим, что если в окрестности максимума этой плотности априорная плотность оцениваемого параметра практически постоянна (от ![]() не зависит), то оптимальная оценка может быть получена по критерию:
не зависит), то оптимальная оценка может быть получена по критерию:
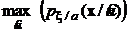 .
.
Этот критерий поиска оптимальной оценки имеет самостоятельное значение в математической статистике и называется критерием максимума правдоподобия.
Этот критерий может использоваться, когда нельзя считать оцениваемый параметр случайной величиной, что требуется по критерию среднего риска и максимума апостериорной плотности вероятности.
В общем случае функцию правдоподобия будем записывать не в виде условной плотности, что справедливо, когда оцениваемый параметр является случайной величиной, а в параметрическом виде: ![]() .
.
Для упрощения вычислений, связанных с получением максимально правдоподобной оценки можно использовать любую монотонно возрастающую функцию от функции правдоподобия. Очень часто используют натуральный логарифм.
При выполнении некоторых, достаточно общих, условий оценки максимального правдоподобия состоятельны, асимптотически эффективны и асимптотически нормально распределены. Последнее означает, что
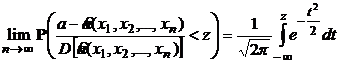 .
.
Если для параметра ![]() существует эффективная оценка, то метод максимального правдоподобия дает именно эту оценку.
существует эффективная оценка, то метод максимального правдоподобия дает именно эту оценку.
В качестве примера найдем максимально правдоподобную оценку математического ожидания по выборочному гауссовскому вектору, который мы рассматривали в предыдущих разделах.
Функция правдоподобия в этом случае имеет вид:
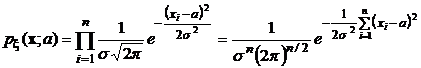 .
.
Оценку максимального правдоподобия найдем максимизируя логарифм функции правдоподобия, который сводится к задаче:
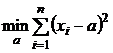 .
.
Найдем производную по ![]() и приравняем ее нулю, получим уравнение:
и приравняем ее нулю, получим уравнение:
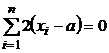 .
.
Очевидно, что решением данного уравнения является:
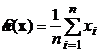 .
.
Таким образом, оценка максимального правдоподобия математического ожидания нормально распределенного выборочного случайного вектора совпадает с выборочным математическим ожиданием.
Нетрудно показать, что эта оценка несмещенная ![]() , и дисперсия ее равна:
, и дисперсия ее равна:
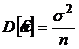 .
.
Таким образом, эта оценка является состоятельной.
Пример 2
Пусть ![]() — выборочный случайный вектор, компоненты которого независимы, одинаково распределены по закону Пуассона с неизвестным параметром
— выборочный случайный вектор, компоненты которого независимы, одинаково распределены по закону Пуассона с неизвестным параметром ![]() :
:
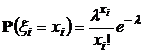 .
.
Здесь ![]() — принимают неотрицательные целые значения 0, 1,…,k,…
— принимают неотрицательные целые значения 0, 1,…,k,…
Найти максимально правдоподобную оценку параметра ![]() .
.
Решение задачи
Функция правдоподобия в данном случае имеет вид:
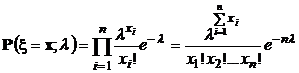 .
.
Оценку максимального правдоподобия найдем максимизируя логарифм функции правдоподобия по параметру ![]() :
:
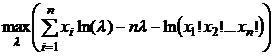 .
.
Последнее слагаемое от ![]() не зависит и его можно не учитывать при поиске максимума.
не зависит и его можно не учитывать при поиске максимума.
Из математического анализа известно, что необходимым условием экстремума дифференцируемой функции является равенство нулю ее производной:
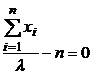 .
.
Из этого уравнения находим оценку параметра:
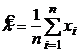 .
.
Найдем математическое ожидание оценки и ее дисперсию.
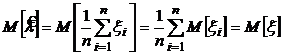 .
.
Математическое ожидание случайной величины, распределенной по закону Пуассона, равно:
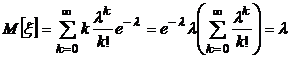 .
.
Таким образом, оценка параметра ![]() является несмещенной.
является несмещенной.
Дисперсия оценки равна:
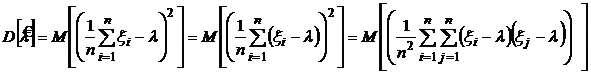 .
.
Так как случайные величины ![]() независимые, то
независимые, то
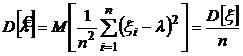 .
.
Таким образом, оценка максимального правдоподобия является состоятельной оценкой параметра ![]() .
.
Пример 3 [3]
При помощи n различных приборов получены n измерений случайной величины ![]() . В предположении, что
. В предположении, что ![]() имеет нормальное распределение, а дисперсия i-того измерения известна и равна
имеет нормальное распределение, а дисперсия i-того измерения известна и равна ![]() , найти максимально правдоподобную оценку математического ожидания (m) случайной величины
, найти максимально правдоподобную оценку математического ожидания (m) случайной величины ![]() и вычислить дисперсию этой оценки.
и вычислить дисперсию этой оценки.
Решение задачи
Выборочный вектор ![]() , где компоненты вектора независимые гауссовские, имеющие одинаковое математическое ожидание m и различные дисперсии
, где компоненты вектора независимые гауссовские, имеющие одинаковое математическое ожидание m и различные дисперсии ![]() .
.
Функция правдоподобия в этом случае равна:
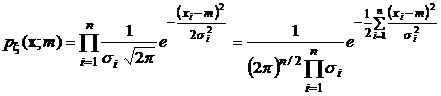 .
.
Максимум по m этой функции будет достигаться в той точке, где достигается
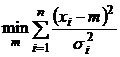 .
.
Дифференцируя по m и приравнивая результат дифференцирования нулю получим уравнение для оценки:
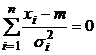 .
.
Откуда получаем максимально правдоподобную оценку математического ожидания:
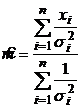 .
.
Покажем, что эта оценка несмещенная.
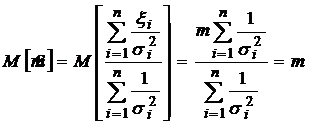 .
.
Найдем дисперсию этой оценки.
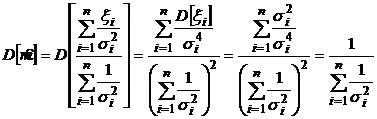 .
.
4.2.4. Доверительные интервалы и доверительная вероятность
При статистической обработке результатов наблюдений часто необходимо не только найти оценку неизвестного параметра, но и охарактеризовать точность этой оценки. С этой целью вводится понятие доверительного интервала.
Определение. Доверительным интервалом для параметра ![]() называется интервал
называется интервал ![]() со случайными границами, содержащий истинное значение параметра с заданной вероятностью
со случайными границами, содержащий истинное значение параметра с заданной вероятностью ![]() , то есть
, то есть 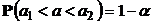 .
.
Число ![]() называется доверительной вероятностью, а значение
называется доверительной вероятностью, а значение ![]() уровнем значимости. Статистики
уровнем значимости. Статистики 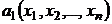 и
и 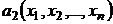 , определяемые по выборке называются соответственно нижней и верхней границами доверительного интервала.
, определяемые по выборке называются соответственно нижней и верхней границами доверительного интервала.
Длина доверительного интервала, характеризующая точность оценивания, зависит от объема выборки и доверительной вероятности. При уменьшении объема выборки длина доверительного интервала увеличивается и наоборот. Также, чем больше доверительная вероятность, тем больше должен быть объем выборки для сохранения той же длины доверительного интервала.
Выбор доверительной вероятности определяется конкретными условиями задачи оценивания. Обычно используются значения 0,9, 0,95, 0,99.
Чтобы найти доверительный интервал для оцениваемого параметра ![]() необходимо знать закон распределения оценки
необходимо знать закон распределения оценки ![]() . Этот закон распределения зависит от значения оцениваемого параметра
. Этот закон распределения зависит от значения оцениваемого параметра ![]() .
.
Рассмотрим построение доверительного интервала в задаче поиска максимально правдоподобной оценки математического ожидания по выборочному вектору с гауссовскими одинаково распределенными компонентами. Предполагается, что дисперсия компонент известна.
Максимально правдоподобной оценкой в этом случае является выборочное среднее:
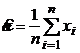 .
.
Подставляя вместо реализаций выборочного случайного вектора его компоненты, получим, что оценка является случайной величиной, функционально связанной с компонентами выборочного случайного вектора:
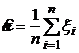 .
.
Нетрудно видеть, что закон распределения случайной величины ![]() гауссовский, как результат линейного преобразования гауссовского случайного вектора.
гауссовский, как результат линейного преобразования гауссовского случайного вектора.
Математическое ожидание и дисперсия ![]() равны:
равны:
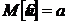 , .
, .
Найдем такое значение ![]() , при котором выполняется равенство:
, при котором выполняется равенство: 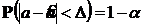 . Доверительный интервал в этом случае равен
. Доверительный интервал в этом случае равен ![]() . Длина доверительного интервала равна
. Длина доверительного интервала равна ![]() .
.
Заметим, что 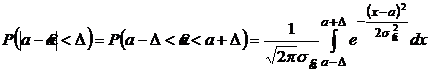 .
.
Заменой переменных ![]() этот интеграл можно привести к виду:
этот интеграл можно привести к виду:
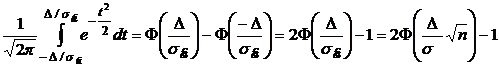 .
.
Здесь 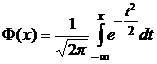 - интеграл вероятностей. Также учтено, что
- интеграл вероятностей. Также учтено, что ![]() .
.
Параметр ![]() находим из уравнения:
находим из уравнения:
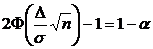 .
.
Решая это уравнение, получим
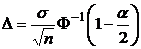 .
.
Здесь 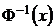 — функция, обратная
— функция, обратная ![]() .
.
Заметим, что значение ![]() , для которого выполняется равенство:
, для которого выполняется равенство: 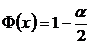 (обозначается
(обозначается ![]() ), называется квантилью нормального распределения уровня
), называется квантилью нормального распределения уровня ![]() .
.
Таким образом, доверительный интервал для оценки математического ожидания равен:
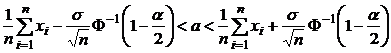 .
.
Пусть уровень значимости ![]() . Тогда по таблице квантилей нормального распределения найдем
. Тогда по таблице квантилей нормального распределения найдем 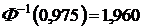 и длина доверительного интервала составляет:
и длина доверительного интервала составляет: ![]() .
.
4.3. Проверка статистических гипотез
Ранее мы рассматривали задачу оценки параметра распределения генеральной совокупности по наблюдениям. Во многих случаях возникает задача не оценки, а проверки предположений относительно тех или иных свойств распределения генеральной совокупности. Эти предположения называются гипотезами. Например, гипотеза о том, что математическое ожидание равно нулю или оно не равно нулю или это математическое ожидание равно заранее заданному значению и т. д.
При статистической обработке результатов наблюдений количество рассматриваемых гипотез может быть любым. На практике наибольший интерес представляет задача проверки двух гипотез относительно свойств распределения генеральной совокупности.
Задачу проверки гипотез в соответствии с теорией статистических решений можно свести к задаче оценки параметров, если предположить, что множество возможных значений параметра дискретно и равно двум для задачи проверки двух гипотез.
Итак, пусть в статистической задаче оценки параметров оцениваемый параметр принимает всего два значения: ![]() . Очевидно, что и возможных значений оценки также всего два:
. Очевидно, что и возможных значений оценки также всего два: ![]() .
.
Функция потерь ![]() в этом случае может быть представлена в табличном виде и называется матрицей потерь:
в этом случае может быть представлена в табличном виде и называется матрицей потерь:
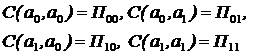 .
.
Здесь П00 и П11 — потери за счет правильных решений; П01 и П10 — потери за счет ошибочных решений. Ясно, что П00<П01 и П11<П10.
Как и для задачи оценки параметров, средний риск имеет вид:
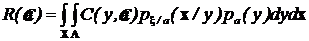 .
.
Заметим, что оцениваемый параметр представляет собой дискретную случайную величину и ее плотность распределения имеет вид:
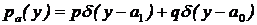 .
.
Здесь: ![]() .
. ![]() — представляет собой априорную вероятность гипотезы Н1:
— представляет собой априорную вероятность гипотезы Н1: ![]() , а
, а ![]() — априорную вероятность гипотезы Н0:
— априорную вероятность гипотезы Н0: ![]() .
.
Подставляя априорную плотность в средний риск, и проведя интегрирование, получим:
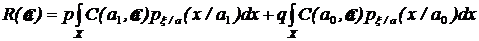 .
.
Рассмотрим, что собой представляет оценка ![]() . Это функция, отображающая элемент выборочного пространства Х в элемент множества
. Это функция, отображающая элемент выборочного пространства Х в элемент множества ![]() . По существу любая такая функция разбивает выборочное пространство Х на два не пересекающихся множества
. По существу любая такая функция разбивает выборочное пространство Х на два не пересекающихся множества 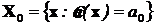 и
и 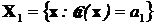 . Причем
. Причем 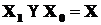 .
.
Таким образом, средний риск можно записать в виде:
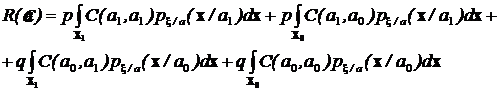 .
.
Учитывая, что ![]() , а также значения матрицы потерь, получим:
, а также значения матрицы потерь, получим:
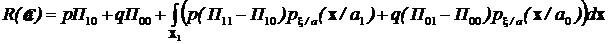 .
.
Минимизировать средний риск выбором функции ![]() означает выбрать такое множество Х1, чтобы соответствующий интеграл был минимальным. Заметим, что подынтегральная функция знакопеременная, поэтому область интегрирования выберем так, чтобы в этой области подынтегральная функция была отрицательна:
означает выбрать такое множество Х1, чтобы соответствующий интеграл был минимальным. Заметим, что подынтегральная функция знакопеременная, поэтому область интегрирования выберем так, чтобы в этой области подынтегральная функция была отрицательна:
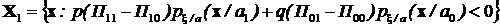 .
.
Заметим, что П11<П10, следовательно, это неравенство можно записать в виде:
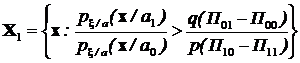 .
.
Таким образом, правило принятия решений можно записать так:
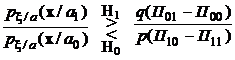
Суть алгоритма заключается в следующем: по наблюдениям 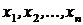 вычисляется величина
вычисляется величина 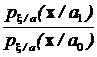 и полученное число сравнивается с заранее вычисленным порогом
и полученное число сравнивается с заранее вычисленным порогом 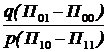 . Если вычисленное значение больше порога, принимается решение, что верна гипотеза Н1, в противном случае принимается решение, что верна гипотеза Н0.
. Если вычисленное значение больше порога, принимается решение, что верна гипотеза Н1, в противном случае принимается решение, что верна гипотеза Н0.
Определение. Функция 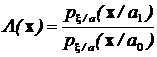 называется отношением правдоподобия.
называется отношением правдоподобия.
Для использования приведенного выше алгоритма проверки гипотез нужно знать априорные вероятности гипотез p и q, а также задать матрицу потерь.
Во многих случаях разумное определение этих параметров вызывает большие затруднения и встает задача определения порога из каких-либо других соображений.
4.3.1. Критерий Неймана-Пирсона
При проверке гипотез возможны как правильные, так и ошибочные решения. В теории статистических решений всем этим решениям приписываются соответствующие потери, которые в конечном итоге определяют порог сравнения в алгоритме проверки гипотез. Принято ошибочные решения классифицировать следующим образом.
Ошибкой первого рода называется ошибка, состоящая в том, что гипотеза Н0 отклоняется в то время как она верна.
Ошибкой второго рода называется ошибка, состоящая в том, что принимается гипотеза Н0, хотя в действительности верна гипотеза Н1.
Вероятность ошибки первого рода называется уровнем значимости и обозначается символом ![]() , а вероятность ошибки второго рода обозначается символом
, а вероятность ошибки второго рода обозначается символом ![]() .
.
Заметим, что, зная вероятности ошибочных решений, легко вычислить вероятности правильных решений. Так вероятность правильного решения о принятии гипотезы Н0 равна 1–![]() , а вероятность принять правильное решение о том, что верна гипотеза Н1 равна 1–
, а вероятность принять правильное решение о том, что верна гипотеза Н1 равна 1–![]() .
.
В статистических задачах желательно применить такой алгоритм принятия решений, чтобы вероятность правильного решения о принятии гипотезы Н1 была максимальной при условии, что вероятность ошибки первого рода не более заданной величины — уровня значимости. Такой критерий поиска решающего правила называется критерием Неймана-Пирсона.
Вероятность ошибки первого рода можно определить как вероятность следующего события:
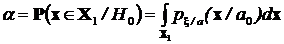 .
.
Вероятность правильного решения о том, что верна гипотеза Н1:
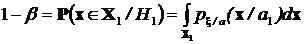 .
.
Нужно выбрать множество Х1 таким образом, чтобы величина ![]() была максимальной при условии, что величина
была максимальной при условии, что величина ![]() не превышает заданное значение
не превышает заданное значение ![]() .
.
Пусть 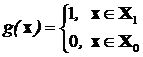 — произвольная решающая функция, которую и надо найти.
— произвольная решающая функция, которую и надо найти.
Тогда задачу поиска оптимальной по критерию Неймана-Пирсона решающей функции можно записать в виде следующей задачи на условный экстремум:
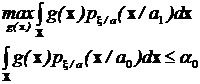 .
.
Данная задача с использованием множителей Лагранжа может быть записана в виде задачи на безусловный экстремум:
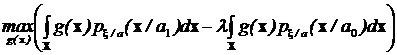 .
.
После того как оптимальная функция ![]() будет найдена, параметр
будет найдена, параметр ![]() находится из уравнения:
находится из уравнения: ![]() .
.
Из определения функции g(x) экстремальная задача может быть записана в виде:
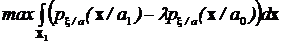
Решение этой задачи мы уже обсуждали и сводится оно к выбору такого множества Х1, чтобы интеграл достигал максимума. Это будет в том случае, если в область интегрирования (множество Х1) включить только те х, для которых подынтегральное выражение положительно.
Таким образом,
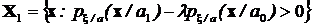 .
.
Нетрудно видеть, что и в этом случае алгоритм проверки гипотез сводится к вычислению отношения правдоподобия и сравнению его с некоторым порогом ![]() :
:
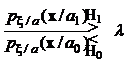 .
.
Порог ![]() выбирается таким образом, чтобы вероятность ошибки первого рода не превышала заданной величины
выбирается таким образом, чтобы вероятность ошибки первого рода не превышала заданной величины ![]() .
.
Заметим, что с порогом можно сравнивать любую монотонно возрастающую функцию от отношения правдоподобия. Неравенство необходимо преобразовывать до тех пор, пока не получится наиболее простого в вычислительном отношении алгоритма.
Пример 1
Проверяется партия деталей, изготовленная на станке - автомате в количестве n штук. Отклонения от номинального размера составляют величины ![]() . Считается, что отклонение от номинального размера есть гауссовская случайная величина с известной дисперсией
. Считается, что отклонение от номинального размера есть гауссовская случайная величина с известной дисперсией ![]() . При исправном станке математическое ожидание отклонений от номинала равно нулю, а если станок неисправен, то равно m>0. Найти алгоритм проверки гипотезы Н0 – станок исправен, против альтернативы Н1 - станок неисправен. Уровень значимости равен
. При исправном станке математическое ожидание отклонений от номинала равно нулю, а если станок неисправен, то равно m>0. Найти алгоритм проверки гипотезы Н0 – станок исправен, против альтернативы Н1 - станок неисправен. Уровень значимости равен ![]() . Чему равна вероятность ошибки второго рода?
. Чему равна вероятность ошибки второго рода?
Решить задачу при следующих численных данных: число наблюдений n=100, дисперсия 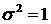 , уровень значимости
, уровень значимости ![]() , m=0,3 сумма наблюдаемых значений равна
, m=0,3 сумма наблюдаемых значений равна 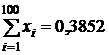 .
.
Решение задачи
Вначале найдем плотности распределения выборочного случайного вектора по гипотезам Н1 и Н0.
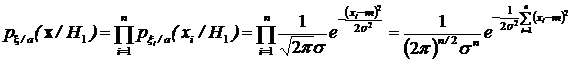 .
.
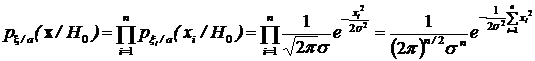 .
.
Тогда отношение правдоподобия равно:
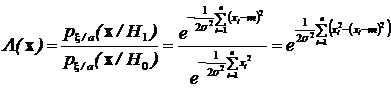 .
.
Алгоритм проверки гипотез заключается в сравнении отношения правдоподобия (или любой монотонной функции от него) с некоторым порогом.
В качестве такой функции удобно взять натуральный логарифм:
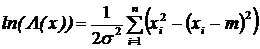
![]() l.
l.
Преобразуем это неравенство, учитывая, что порог ![]() произвольный и будет выбран позднее исходя из заданной ошибки первого рода, а m>0.
произвольный и будет выбран позднее исходя из заданной ошибки первого рода, а m>0.
После приведения подобных и отнесения всех констант, не зависящих от наблюдений, в порог, получим следующий алгоритм:
![]()
![]() l.
l.
Исходя из требуемого уровня значимости, найдем порог ![]() .
.
Для того чтобы найти порог, вычислим вероятность ошибки первого рода. Эта ошибка получается в том случае, если случайная величина ![]() , равная сумме компонент выборочного случайного вектора x, превысит порог, хотя верна гипотеза Н0. Вероятность такого события равна:
, равная сумме компонент выборочного случайного вектора x, превысит порог, хотя верна гипотеза Н0. Вероятность такого события равна:
 .
.
Заметим, что сумма гауссовских случайных величин есть гауссовская случайная величина. Поэтому случайная величина ![]() - гауссовская. Необходимо только найти ее математическое ожидание и дисперсию.
- гауссовская. Необходимо только найти ее математическое ожидание и дисперсию.
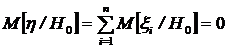 ,
, 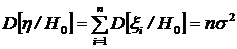 .
.
Таким образом, 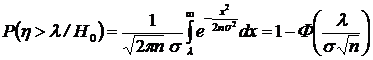 .
.
Порог находится из уравнения:
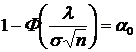
Решая это уравнения, получим
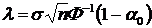
Найдем вероятность ошибки второго рода ![]() . По определению
. По определению
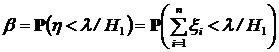 .
.
Найдем математическое ожидание и дисперсию ![]() по гипотезе
по гипотезе ![]() .
.
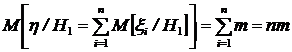 .
. ![]() , так как дисперсия случайной величины не зависит от математического ожидания.
, так как дисперсия случайной величины не зависит от математического ожидания.
Таким образом,
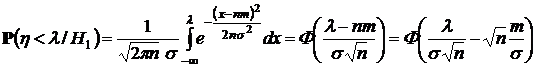 . (12)
. (12)
Так как ![]() , то подставляя это значение в выражение (12), получим:
, то подставляя это значение в выражение (12), получим:
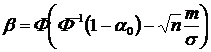 .
.
Из этого выражения следует, что вероятность ошибки второго рода тем меньше, чем больше число испытаний n и отношение ![]() .
.
Подставляя числовые значения, получим:
![]() .
.
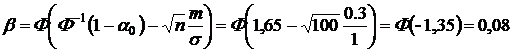 .
.
Таким образом, при данных наблюдениях принимается решение, что верна гипотеза ![]() — станок исправен, так как
— станок исправен, так как 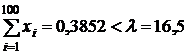 . При этом вероятность принять неисправный станок за исправный (вероятность ошибки второго рода) равна 0,08.
. При этом вероятность принять неисправный станок за исправный (вероятность ошибки второго рода) равна 0,08.
И только в том случае, если сумма наблюдений превысит порог 16,5 принимается решение, что верна гипотеза Н1 — станок неисправен. При этом вероятность принять исправный станок за неисправный (вероятность ошибки первого рода) равна ![]() .
.
Библиографический список
[1]. Колмогоров понятия теории вероятностей. — М.: Наука, 1974. — 356 с.
[2]. , Овчаров вероятностей и ее инженерные приложения. — М.: Наука, 1988. — 480 с.
[3]. Сборник задач по математике для втузов. Ч. 3. Теория вероятностей и математическая статистика: Учебное пособие для втузов/ Под ред. . — М.: Наука, 1990. — 428 с.
[4]. , Шилов функции и действия над ними. — М.: Физматгиз, 1959. — 470 с.
[5]. Введение в мвтематическую статистику. — М.: Наука, 1976. — 520 с.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 |
