
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Межгрупповая дисперсия ![]() характеризует систематическую вариацию результативного порядка, обусловленную влиянием признака-фактора, положенного в основание группировки. Она равна среднему квадрату отклонений групповых (частных) средних
характеризует систематическую вариацию результативного порядка, обусловленную влиянием признака-фактора, положенного в основание группировки. Она равна среднему квадрату отклонений групповых (частных) средних ![]() , от общей средней
, от общей средней ![]() :
:
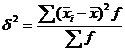 , (5.31)
, (5.31)
где ![]() - численность единиц в группе.
- численность единиц в группе.
Внутригрупповая (частная) дисперсия ![]() , отражает случайную вариацию, т. е. часть вариации, обусловленную влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она равна среднему квадрату отклонений отдельных значений признака внутри группы
, отражает случайную вариацию, т. е. часть вариации, обусловленную влиянием неучтенных факторов и не зависящую от признака-фактора, положенного в основание группировки. Она равна среднему квадрату отклонений отдельных значений признака внутри группы ![]() от средней арифметической этой группы
от средней арифметической этой группы ![]() , (групповой средней) и может быть исчислена как простая дисперсия или как взвешенная дисперсия по формулам, соответственно:
, (групповой средней) и может быть исчислена как простая дисперсия или как взвешенная дисперсия по формулам, соответственно:
![]() ; (5.32)
; (5.32)
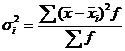 . (5.33)
. (5.33)
На основании внутригрупповой дисперсии по каждой группе, т. е. на основании ![]() можно определить общую среднюю из внутригрупповых дисперсий:
можно определить общую среднюю из внутригрупповых дисперсий:
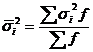 . (5.34)
. (5.34)
Согласно правилу сложения дисперсий общая дисперсия равна сумме средней из внутригрупповых и межгрупповой дисперсий:
![]() . (5.35)
. (5.35)
Пользуясь правилом сложения дисперсий, можно всегда по двум известным дисперсиям определить третью - неизвестную, а также судить о силе влияния группировочного признака.
Очевидно, чем больше доля межгрупповой дисперсии в общей дисперсии, тем сильнее влияние группировочного признака (квалификашюнного разряда) на изучаемый признак (количество изготавливаемых изделий).
Поэтому в статистическом анализе широко используется эмпирический коэффициент детерминации (![]() )- показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии результативного признака и характеризующий силу влияния группировочного признака на образование общей вариации:
)- показатель, представляющий собой долю межгрупповой дисперсии в общей дисперсии результативного признака и характеризующий силу влияния группировочного признака на образование общей вариации:
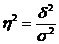 . (5.36)
. (5.36)
Эмпирический коэффициент детерминации показывает долю вариации результативного признака ![]() под влиянием факторного признака
под влиянием факторного признака ![]() (остальная часть общей вариации
(остальная часть общей вариации ![]() обуславливается вариацией прочих факторов). При отсутствии связи эмпирический коэффициент детерминации равен нулю, а при функциональной связи - единице.
обуславливается вариацией прочих факторов). При отсутствии связи эмпирический коэффициент детерминации равен нулю, а при функциональной связи - единице.
Эмпирическое корреляционное отношение - это корень квадратный из эмпирического коэффициента детерминации:
![]() ,
,
оно показывает тесноту связи между группировочным и результативным признаками.
Эмпирическое корреляционное отношение ![]() , как и
, как и ![]() , может принимать значения от 0 до 1.
, может принимать значения от 0 до 1.
Если связь отсутствует, то корреляционное отношение равно нулю, т. е. все групповые средние будут равны между собой, межгрупповой вариации не будет. Значит, группировочный признак никак не влияет на образование общей вариации.
Если связь функциональная, то корреляционное отношение будет равно единице. В этом случае дисперсия групповых средних равна общей дисперсии (![]() ), т. е. внутригрупповой вариации не будет. Это означает, что группировочный признак целиком определяет вариацию изучаемого результативного признака.
), т. е. внутригрупповой вариации не будет. Это означает, что группировочный признак целиком определяет вариацию изучаемого результативного признака.
Чем значение корреляционного отношения ближе к единице, тем теснее, ближе к функциональной зависимости связь между признаками.
Для качественной оценки тесноты связи на основе показателя эмпирического корреляционного отношения можно воспользоваться соотношениями Чэддока:
![]() 0,1-0,3 0,3-0,5 0,5-0,7 0,7-0,9 0,9-0,99
0,1-0,3 0,3-0,5 0,5-0,7 0,7-0,9 0,9-0,99
Сила Слабая Умеренная Заметная Тесная Весьма тесная
связи
4.6. Выборочное наблюдение
Выборочное наблюдение - это такое несплошное наблюдение, при котором отбор подлежащих обследованию единиц осуществляется в случайном порядке, отобранная часть изучается, а результаты распространяются на всю исходную совокупность.
Наблюдение организуется таким образом, что эта часть отобранных единиц в уменьшенном масштабе репрезентирует (представляет) всю совокупность.
Совокупность, из которой производится отбор, называется генеральной, и все ее обобщающие показатели - генеральными.
Совокупность отобранных единиц именуют выборочной совокупностью, н все ее обобщающие показатели - выборочными.
Принципы выборочного наблюдения:
- обеспечение случайности (равной возможности попадания в выборку) отбора единиц
- достаточное число единиц выборочной совокупности
Основная задача выборочного наблюдения в экономике состоит в том, чтобы на основе характеристик выборочной совокупности (средней и доли) получить достоверные суждения о показателях средней и доли в генеральной совокупности.
Ошибки репрезентативности присущи только выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную. Они представляют собой расхождение между значениями показателей, полученных по выборке, и значениями показателей этих же величин, которые были бы получены при проведенном с одинаковой степенью точности сплошном наблюдении, т. е. между величинами выборных и соответствующих генеральных показателей.
По методу отбора различают повторную и бесповторную выборки.
При повторной выборке общая численность единиц генеральной совокупности в процессе выборки остается неизменной.
Ту или иную единицу, попавшую в выборку, после регистрации снова возвращают в генеральную совокупность, и она сохраняет равную возможность со всеми прочими единицами при повторном отборе единиц вновь попасть в выборку ("отбор по схеме возвращенного шара"). Повторная выборка в социально-экономической жизни встречается редко. Обычно выборку организуют по схеме бесповторной выборки.
При бесповторной выборке единица совокупности, попавшая в выборку, в генеральную совокупность не возвращается и в дальнейшем в выборке не участвует; т. е. последующую выборку делают из генеральной совокупности уже без отобранных ранее единиц ("отбор по схеме невозвращенного шара").
По степени охвата единиц совокупности различают большие и малые (п<30) выборки.
Основные характеристики параметров генеральной и выборочной совокупностей обозначаются символами:
N - объем генеральной совокупности (число входящих в нее единиц);
_ n - объем выборки (число обследованных единиц);
х - генеральная средняя (среднее значение признака в 0 2генеральной совокупности);
~
х - выборочная средняя;
р - генеральная доля (доля единиц, обладающих данным значением признака в общем числе единиц генеральной совокупности);
w - выборочная доля;
s2- генеральная дисперсия (дисперсия признака в генеральной совокупности);
S2- выборочная дисперсия того же признака;
s - среднее квадратическое отклонение в генеральной совокуп-
ности;
S - среднее квадратическое отклонение в выборке.
При случайном повторном отборе средние ошибки теоретически рассчитывают по следующим формулам:
для средней количественного признака
![]()
для доли (альтернативного признака)
![]()
Поскольку практически дисперсия признака в генеральной совокупности s2 точно неизвестна, на практике пользуются значением дисперсии S2 , рассчитанным для выборочной совокупности на основании закона больших чисел, согласно которому выборочная совокупность при достаточно большом объеме выборки достаточно точно воспроизводит характеристики генеральной совокупности. В теории вероятностей доказано, что генеральная дисперсия выражается через выборную следующим соотношением:
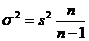
Так как n/(n -1) при достаточно больших n - величина, близкая к единице, то можно принять, что ![]() , а следовательно, в практических расчетах средних ошибок выборки можно использовать формулы (6.5) и (6.6).
, а следовательно, в практических расчетах средних ошибок выборки можно использовать формулы (6.5) и (6.6).
При случайном бесповторном отборе в приведенные выше формулы расчета средних ошибок выборки необходимо подкоренное выражение умножить наn/N)), поскольку в процессе бесповторной выборки сокращается численность единиц генеральной совокупности.
Следовательно, для бесповторной выборки расчетные формулы средней ошибки выборки примут такой вид:
для средней количественного признака
![]()
для доли (альтернативного признака)
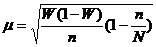
Так как n всегда меньше N, то дополнительный множиn/N) всегда будет меньше единицы. Отсюда следует, что средняя ошибка при бесповторном отборе всегда будет меньше, чем при повторном. В то же время при сравнительно небольшом проценте выборки этот множитель близок к единице ( например, при 5 %-ной выборке он равен 0,95; при 2 %-ной - 0,98 и т. д.). Поэтому иногда на практике пользуются для определения средней ошибки выборки формулами без указанного множителя, хотя выборку и организуют как бесповторную. Это имеет место в тех случаях, когда число единиц генеральной совокупности неизвестно или безгранично, или когда n очень мало по сравнению с N, и по существу, введение дополнительного множителя, близкого по значению к единице, практически не повлияет на значение средней ошибки выборки.
Выборочные средние и относительные величины распространяют на генеральную совокупность с учетом предела их возможной ошибки.
В каждой конкретной выборке расхождение между выборочной средней и генеральной может быть меньше средней ошибки выборки ц., равно ей или больше ее.
Причем каждое из этих расхождений имеет различную вероятность (объективную возможность появления события). Поэтому фактические расхождения между выборочной средней и генеральной можно рассматривать как некую предельную ошибку, связанную со средней ошибкой и гарантируемую с определенной вероятностью Р.
Предельную ошибку выборки для средней при повторном отборе можно рассчитать по формуле:
![]()
где t - нормированное отклонение - "коэффициент доверия", зависящий от вероятности, с которой гарантируется предельная ошибка выборки;
m - средняя ошибка выборки.
Аналогичным образом может быть записана формула предельной ошибки выборки для доли при повторном отборе:
![]()
При случайном бесповторном отборе в формулах расчета предельных ошибок выборки необходимо умножить подкоренное выражение наn/N)).
Формула предельной ошибки выборки вытекает из основных положений теории выборочного метода, сформулированных в ряде теорем теории вероятностей, отражающих закон больших чисел.
На основании теоремы (с уточнениями ) с вероятностью, сколь угодно близкой к единице, можно утверждать, что при достаточно большом объеме выборки и ограниченной генеральной дисперсии выборочные обобщающие показатели (средняя, доля) будут сколь угодно мало отличаться от соответствующих генеральных показателей.
Таким образом, величина предельной ошибки выборки может быть установлена с определенной вероятностью.
Значения функции Ф(1) при различных значениях ( как коэффициента кратности средней ошибки выборки, определяются на основе специально составленных таблиц. Приведем некоторые значения*, применяемые наиболее часто для выборок достаточно большого объема ( n>= ЗО):
t 1,000 1,960 2,000 2,580 3,000
Ф(t) 0,683 0,950 0,954 0,990 0,997
Предельная ошибка выборки отвечает на вопрос о точности выборки с определенной вероятностью, значение которой определяется коэффициентом (в практических расчетах, как правило, заданная вероятность не должна быть менее 0,95). Так при t = 1 предельная ошибка составит ![]() .
.
Следовательно, с вероятностью 0,683 можно утверждать, что разность между выборочными и генеральными показателями не превысит одной средней ошибки выборки. Другими словами, в 68,3% случаев ошибка репрезентативности не выйдет за пределы ±![]() . При t=2 с вероятностью 0,954 она не выйдет за пределы ±2
. При t=2 с вероятностью 0,954 она не выйдет за пределы ±2![]() , при t = 3с вероятностью 0,997 - за пределы ±3
, при t = 3с вероятностью 0,997 - за пределы ±3![]() и т. д.
и т. д.
Выборочное наблюдение проводится в целях распространения выводов, полученных по данным выборки, на генеральную совокупность.
Одной из основных задач является оценка по данным выборки исследуемых характеристик (параметров) генеральной совокупности.
Предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы.
При проектировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки очень важно правильно определить численность ( объем ) выборочной совокупности, которая с определенной вероятностью обеспечит заданную точность результатов наблюдения. Формулы для определения необходимой численности выборки п легко получить непосредственно из формул ошибок выборки:
для средней количественного признака
![]()
для доли (альтернативного признака)
![]()
Эти формулы показывают, что с увеличением предполагаемой ошибки выборки значительно уменьшается необходимый объем выборки.
Для расчета объема выборки нужно знать дисперсию. Она может быть заимствована из проводимых ранее обследований данной или аналогичной совокупности, а если таковых нет, тогда для определения дисперсии надо провести специальное выборочное обследование небольшого объема.
4.6. Статистическое изучение рядов динамики
Ряд динамики (или динамический ряд) представляет собой ряд расположенных в хронологической последовательности числовых значений статистического показателя, характеризующих изменение общественных явлений во времени.
В каждом ряду динамики имеются два основных элемента: время t и конкретное значение показателя (уровень ряда) у.
Уровни ряда - это показатели, числовые значения которых составляют динамический ряд.
Время - это моменты или периоды, к которым относятся уровни.
По времени, отраженному в динамических рядах, они разделяются на моментные и интервальные.
Моментным называется ряд динамики, уровни которого характеризуют состояние явления на определенные даты (моменты времени).
Примером моментного ряда могут служить следующие данные о численности населения, млн чел.:
1970 г. 1980 г. 1990 г. 1991 г. 1993 г. 1994 г. 1995 г.
130,6 138,8 148,2 148,3 148,0 147,9 147,6
Поскольку в каждом последующем уровне содержится полностью или частично значение предыдущего уровня, суммировать уровни моментного ряда не следует, так как это приводит к повторному счету.
Интервальным (периодическим) рядом динамики называется такой ряд, уровни которого характеризуют размер явления за конкретный период времени (год, квартал, месяц).
Примером такого ряда могут служить данные о динамике добычи нефти в Российской Федерации, млн т:
1990 г. 1991 г. 1992 г. 1993 г. 1994 г. 1995 г.
Значения уровней интервального ряда в отличие от уровней моментного ряда не содержатся в предыдущих или последующих показателях, их можно просуммировать, что позволяет получать ряды динамики более укрупненных периодов. Например, суммирование уровней добычи нефти за каждый год по данным, приведенным выше, позволяет определить ее добычу за все шесть лет в целом и в среднем за год.
Интервальный ряд, где последовательные уровни могут суммироваться, можно представить как ряд с нарастающими итогами. При построении таких рядов производится последовательное суммирование смежных уровней. Этим достигается суммарное обобщение результата развития изучаемого явления с начала отчетного периода (месяца, квартала, года и т. д.).
Уровни в динамическом ряду, могут быть представлены абсолютными, средними или относительными величинами.
По расстоянию между уровнями ряды динамики подразделяются на ряды с равностоящими и неравностоящими уровнями по времени.
Статистические данные должны быть сопоставимы по территории, кругу охватываемых объектов, единицам измерения, времени регистрации, ценам, методологии расчета и др.
Сопоставимость по территории предполагает одни и те же границы территории.
Сопоставимость по кругу охватываемых объектов означает сравнение совокупностей с равным числом элементов.
При этом нужно иметь в виду, что сопоставляемые показатели динамического ряда должны быть однородны по экономическому содержанию и границам объекта, который они характеризуют (однородность может быть обеспечена одинаковой полнотой охвата разных частей явления).
Сопоставимость по времени регистрации для интервальных рядов обеспечивается равенством периодов времени, за которые приводятся данные
Для моментных рядов динамики показатели следует приводить на одну и ту же дату.
К показателям ряда динамики относятся: абсолютный прирост, темп роста, темп прироста, абсолютное значение одного процента прироста.
Система средних показателей включает средний уровень ряда, средний абсолютный прирост, средний темп роста, средний темп прироста.
Показатели анализа динамики могут вычисляться на постоянной и переменных базах сравнения. При этом принято называть сравниваемый уровень отчетным, а уровень, с которым производится сравнение, - базисным.
Для расчета показателей анализа динамики на постоянной базе каждый уровень ряда сравнивается с одним и тем же базисным уровнем. В качестве базисного выбирается либо начальный уровень в ряду динамики, либо уровень, с которого начинается какой-то новый этап развития явления. Исчисляемые при этом показатели называются базисными.
Для расчета показателей анализа динамики на переменной базе каждый последующий уровень ряда сравнивается с предыдущие вычисленные таким образом показатели анализа динамики называются цепными.
Условные обозначения:
Y0 - базисный (начальный уровень)
Yi - текущий уровень
![]() - абсолютный прирост
- абсолютный прирост
Tр - темп роста
Тпр - темп прироста
Показатель Цепной Базисный
Абсолютный ![]()
![]()
прирост
Темп роста 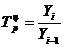
![]()
Темп ![]()
![]()
прироста
Цепные и базисные абсолютные приросты связаны между собой: сумма последовательных цепных абсолютных приростов равна базисному, т. е. общему приросту за весь промежуток времени.
Для характеристики интенсивности, т. е. относительного изменения уровня динамического ряда за какой-либо период времени исчисляют темпы роста (снижения).
Интенсивность изменения уровня оценивается отношением отчетного уровня к базисному.
Показатель интенсивности изменения уровня ряда, выраженный в долях единицы называется коэффициентом роста, а в процентах - темпом роста.
Темп прироста (сокращения) показывает, на сколько процентов сравниваемый уровень больше или меньше уровня, принятого за базу сравнения и вычисляется как отношение абсолютного прироста к абсолютному уровню, принятому за базу сравнения.
При анализе динамики развития следует также знать какие абсолютные значения скрываются за темпами роста и прироста. Сравнение абсолютного прироста и темпа прироста за одни и те же периоды времени показывает, что при снижении (замедлении) темпов прироста абсолютный прирост не всегда уменьшается, в отдельных случаях он может возрастать. Поэтому, чтобы правильно оценить значение полученного темпа прироста, его рассматривают в сопоставлении с показателем абсолютного прироста.
Результат выражают показателем, который называют абсолютным значением (содержанием) одного процента прироста и рассчитывают как отношение абсолютного прироста к темпу прироста за тот же период.
![]()
Абсолютное значение одного процента прироста равно сотой части предыдущего (или базисного) уровня. Оно показывает, какое абсолютное значение скрывается за относительным показателем – одним процентом прироста.
Для обобщающей характеристики динамики исследуемого явления определяют средние показатели: средние уровни ряда и средние показатели изменения уровней ряда.
Методы расчета среднего уровня интервального и моментного рядов динамики различны.
Для интервальных рядов динамики из абсолютных уровней средний за период времени определяется по формуле средней арифметической:
при равных интервалах применяется средняя арифметическая простая:
![]()
где Yi- абсолютные уровни ряда;
n - число уровней ряда. при
Средний уровень моментного ряда динамики с равностоящими уровнями определяется по формуле средней хронологической моментного ряда'.
_ 1/2 * Y1 + Y2 + .....+ Yn-1 + 1/2 * Yn
Y =
n-1
где Y1 ...,Yn - уровни периода, за который делается расчет,
n - число уровней;
В моментном ряду неполном (периоды между моментами неравные) средний уровень находится
![]()
где ![]() - средняя за каждый период между двумя уровнями
- средняя за каждый период между двумя уровнями
t - продолжительность периода, разделяющего два рядом стоящих уровня.
Обобщающий показатель скорости изменения уровней во времени - средний абсолютный прирост (убыль), представляющий собой обобщенную характеристику индивидуальных абсолютных приростов ряда динамики. По цепным данным об абсолютных приростах за ряд лет можно рассчитать средний годовой абсолютный прирост как среднюю арифметическую простую:
![]()
Сводной обобщающей характеристикой интенсивности изменения уровней ряда динамики служит средний темп роста (снижения), показывающий во сколько раз в среднем за единицу времени изменяется уровень ряда динамики.
Средний темп роста (снижения) - обобщенная характеристика индивидуальных темпов роста ряда динамики.
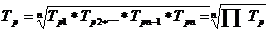
Соответственно при исчислении средних коэффициентов прироста из значений коэффициентов роста вычитается единица:
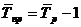
где Тпр - средний темп прироста.
Если уровни ряда динамики снижаются, то средний темп роста будет меньше 100 %, а средний темп прироста - отрицательной величиной. Отрицательный темп прироста представляет собой средний темп сокращения и характеризует среднюю относительную скорость снижения уровня.
4.7. Индексные метод в статистике
Индекс - это обобщающий показатель, используемый для сравнения двух совокупностей, состоящих из элементов, непосредственно не поддающихся суммированию.
Назначение индексов:
- обеспечить сравнение элементов двух совокупностей
- провести анализ изменения одного показателя под влиянием изменения других показателей.
Индексный метод имеет свою символику:
q - количество (объем) какого-либо продукта в натуральном выражении
p - цена единицы товара
z - себестоимость единицы продукции
t - затраты времени на производство единицы продукции (трудоемкость)
w - выработка продукции в стоимостном выражении на одного работника в единицу времени
v - выработка продукции в натуральном выражении на одного работника или в единицу времени
pq - общая стоимость произведенной продукции или общая стоимость проданных товаров или услуг (товарооборот, выручка)
zq - затраты на производство всей продукции
1 - для сравниваемых (текущих) периодов
0 - для периодов, с которыми производится сравнение
По степени охвата элементов совокупности различают индексы:
- индивидуальные
- групповые
- общие
Индивидуальные индексы служат для характеристики изменения отдельных элементов сложного явления.
Применение индивидуальных индексов ограничено, т. к. их вычисление требует высокой степени однородности сравниваемых величин.(хлеб разных сортов)
Общие индексы отражают изменение всех элементов сложного явления.
При этом под сложным явлением подразумевается такая статистическая совокупность, отдельные элементы которой непосредственно не подлежат суммированию.
Если индексы не охватывают все элементы сложного явления, а лишь их часть, то их называют групповыми или субиндексами (индекс продукции по отдельным отраслям промышленности).
Общие индексы могут быть построены двумя способами:
- как агрегатные
- как средние из индивидуальных, которые подразделяются на средние арифметические и средние гармонические
Агрегатный индекс является основной формой индекса. Он агрегатный, т. к. его числитель и знаменатель представляют собой набор - "Агрегат" - непосредственно несоизмеримых и не поддающихся суммированию - сумму произведения двух величин, одна из которых меняется (индексируется), а другая - остается неизменной и в числителе и в знаменателе (вес индекса).
Агрегатный способ исчисления общих индексов в статистике является основным наиболее распространенным, вместе с тем применяется и другой способ расчета общих индексов как средних из соответствующих индивидуальных индексов. К исчислению таких средневзвешенных индексов прибегают тогда, когда имеющаяся в распоряжении информация не позволяет рассчитать общий агрегатный индекс. Так, если неизвестны количества произведенных отдельных видов продукции в натуральных измерителях, но известны индивидуальные индексы и стоимость продукции базисного периода, можно определить средний арифметический индекс физического объема продукции.
Индексы — обобщающие показатели сравнения во времени и в пространстве не только однотипных (одноименных) явлений, но и совокупностей, состоящих из несоизмеримых элементов.
Методики построения и расчета индексов как для временных, так и для пространственных сравнений одинаковы. Не различаются между собой и методы построения индексов различных явлений. Поэтому рассмотрим расчет на примере индексируемых цен (р), объемов продаж (производства) (q), товарооборотов (pq). изменяющихся во времени.
Динамика одноименных явлений изучается с помощью индивидуальных индексов, которые представляют собой известные относительные величины сравнения, динамики или выполнения плана (обязательств):
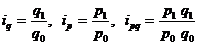
где подстрочное обозначение «О» соответствует уровню базисного периода (с которым сравнивают) или момента времени, «1» — уровню отчетного (сравниваемого) периода или момента времени.
Изменения совокупностей, состоящих из элементов, непосредственно не сопоставимых (например, различных видов продукции), изучают с помощью групповых, или общих, индексов. Последние по методам построения подразделяются на агрегатные индексы и средневзвешенные из индивидуальных индексов.
Формулы агрегатных индексов:
1) физического объема:
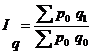
где q - индексируемая величина; р0 – соизмеритель, или вес, который фиксируется на уровне одного и того же периода. В случае индексов объемных показателей весами являются качественные показатели (цена, себестоимость и др.), зафиксированные на уровне базисного периода.
Разница между числителем и знаменателем индекса
![]()
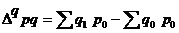
![]()
![]() в данном случае означает абсолютное изменение товарооборота (прирост или снижение) за счет изменения физического объема;
в данном случае означает абсолютное изменение товарооборота (прирост или снижение) за счет изменения физического объема;
2) цен и других качественных показателей:
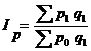 - формула Пааше,
- формула Пааше,
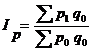 - формула Ласпейреса.
- формула Ласпейреса.
где q — объемы (количества) являются весами, взятыми на одинаковом уровне (отчетном или базисном).
Разница между числителем и знаменателем индексов
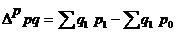 или
или 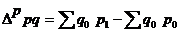
означает:
• в первом случае — абсолютный прирост товарооборота (выручки от продаж) в результате среднего изменения цен или экономию (перерасход) денежных средств населения в результате среднего снижения (повышения) цен;
• во втором случае — условный абсолютный прирост товарооборота, если бы объемы продаж в отчетном периоде совпали с объемами продаж в базисном периоде;
3) товарооборота (выручки от реализации или продаж):
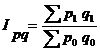
где pq — индексируемое сложное явление, в состав которого входят соизмеримые элементы совокупности. Разница между числителем и знаменателем индекса 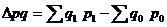 составляет абсолютноe изменение товарооборота за счет совместного действия обоих факторов: цен на продукцию и ее количества.
составляет абсолютноe изменение товарооборота за счет совместного действия обоих факторов: цен на продукцию и ее количества.
Кроме этих форму общие индексы могут быть рассчитаны как средние индексы из индивидуальных:
1) физического объема:
— средний арифметический индекс,
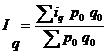
2) цен:
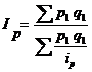 - средний гармонический индекс Пааше,
- средний гармонический индекс Пааше,
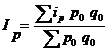 - средний арифметический индекс Ласпейреса.
- средний арифметический индекс Ласпейреса.
Если индексы качественных показателей построены на основе весов, взятых на уровне отчетного периода (например, по формуле Пааше), то рассмотренные выше агрегатные индексы, а также их элементы взаимосвязаны между собой:
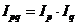 (так называемая мультипликативная модель);
(так называемая мультипликативная модель);
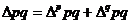 (так называемая аддитивная модель).
(так называемая аддитивная модель).
Если сравнивают друг с другом не два периода (момента), а более, то выделяют цепную и базисную системы индексов.
Цепные и базисные индивидуальные индексы взаимосвязаны между собой:
· произведение цепных индексов равно конечному базисному;
· частное от деления двух смежных базисных индексов равно промежуточному ценному.
Между цепными и базисными общими индексами, построенными на основе постоянных весов, существует взаимосвязь, аналогичная взаимосвязи между индивидуальными индексами.
Индексы, построенные на основе переменных весов, непосредственно перемножать и делить нельзя.
Индексный метод широко применяется также для изучения динамики средних величин и выявления факторов, влияющих на динамику средних. С этой целью исчисляется система взаимосвязанных индексов: переменного, постоянного состава и структурных сдвигов. Индекс переменного состава представляет собой отношение двух взвешенных средних величин с переменными весами, характеризующее изменение индексируемого (осредняемого) показателя.
Индекс переменного состава для любых качественных показателей имеет следующий вид:
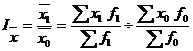
Величина этого индекса характеризует изменение средневзвешенной за счет влияния двух факторов: осредняемого показателя у отдельных единиц совокупности и структуры изучаемой совокупности.
Индекс постоянного (фиксированного) состава представляет собой отношение средних взвешенных с одними и теми же весами (при постоянной структуре). Индекс постоянного состава учитывает изменение только индексируемой величины и показывает средний размер изменения изучаемого показателя (х) у единиц совокупности. В общем виде он может быть записан следующим образом:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
