
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
n N – Число респондентов внутри целевой группы;
n Vn – значение целочисленной или вещественной переменной для респондента n.
Sample%
% опрошенных в анализируемой демографической группе (дем. оси) от общего количества опрошенных целевой аудитории.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики SAMPLE по всей таблице
Sample% (в ячейке) = ![]()
wTotal%
% взвешенного количества опрошенных в анализируемой демографической группе (дем. оси) от общего взвешенного количества опрошенных целевой аудитории.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики wTotal по всей таблице
wTotal % (в ячейке) = ![]()
Row%
% опрошенных в анализируемой демографической группе (дем. оси) от общего количества опрошенных целевой аудитории, расположенных в том же ряду таблицы.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики SAMPLE по РЯДУ.
Row% (в ячейке) = ![]()
Col%
% опрошенных в анализируемой демографической группе (дем. оси) от общего количества опрошенных целевой аудитории, расположенных в той же колонке таблицы.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики SAMPLE по КОЛОНКЕ.
Col% (в ячейке) = ![]()
Row % Weighted
% взвешенного количества опрошенных в анализируемой демографической группе (дем. оси) от общего количества опрошенных целевой аудитории, расположенных в том же ряду таблицы.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики w. total по РЯДУ.
Row% Weighted (в ячейке) = 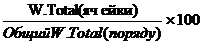
Col% Weighted
% взвешенного количества опрошенных в анализируемой демографической группе (дем. оси) от общего количества опрошенных целевой аудитории, расположенных в той же колонке таблицы.
Обычно используется при построении отчета по нескольким демографическим группам
Рассчитывается как процент от статистики w. total по КОЛОНКЕ.
Col% Weighted (в ячейке) = 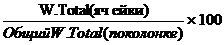
Пример:
Total | Пол | |||
Мужской | Женский | |||
Total | Sample | 5464 | 2445 | 3019 |
wSample | 29236,87 | 13246,67 | 15990,2 | |
Sample % | 100 | 44,75 | 55,25 | |
wTotal % | 100 | 45,31 | 54,69 | |
Row % | 100 | 44,75 | 55,25 | |
Col % | 100 | 100 | 100 | |
Row % Weighted | 100 | 45,31 | 54,69 | |
Col % Weighted | 100 | 100 | 100 | |
15..40 | Sample | 2253 | 1067 | 1186 |
wSample | 11829,38 | 5837,31 | 5992,07 | |
Sample % | 41,23 | 19,53 | 21,71 | |
wTotal % | 40,46 | 19,97 | 20,49 | |
Row % | 100 | 47,36 | 52,64 | |
Col % | 41,23 | 43,64 | 39,28 | |
Row % Weighted | 100 | 49,35 | 50,65 | |
Col % Weighted | 40,46 | 44,07 | 37,47 |
Другие статистики
Duration
Длительность эфирного события ( в формате час : минута : секунда )
При расчете в режиме TOTAL – суммируются длительности отдельных эфирных событий,
В режиме AVERAGE – считается среднее арифметическое
Cost%of Total
Расчет данной статистики производится в зависимости от структуры отчета и расположения медиа-размерностей на осях отчета.
Расчет COST%ofTotal производится по формуле:
![]()
где COST – значение в данной ячейке таблицы рассчитанное обычным способом, COST Total – значение статистики в Total, соответствующем данной ячейке[5].
В случае отсутствия медиа-размерностей на осях X и Y значение статистики считается неопределенным.
Расчет статистики Cost%ofTotal производится полностью аналогичным образом, но на основе статистики Cost вместо статистики TVR.
Статистика Cost%ofTotal вычисляется только для событий типа SPOT, так как для программ стоимость вообще отсутствует, а для брейков в качестве стоимости выдается стоимость ОДНОЙ минуты брейка без учета его продолжительности.
TVR%of Total
Расчет данной статистики производится в зависимости от структуры отчета и расположения медиа-размерностей на осях отчета.
Расчет TVR%ofTotal производится по формуле:
![]()
где TVR – значение в данной ячейке таблицы рассчитанное обычным способом, TVRTotal – значение статистики в Total, соответствующем данной ячейке[6].
В случае отсутствия медиа-размерностей на осях X и Y значение статистики считается неопределенным.
TVR | Cost | TVR % of Total | Cost % of Total | |
CADBURY | 1102,8 | 1722992 | 20,06 | 17.82 |
MARS-RUSSIA | 1861,4 | 2990854 | 33.86 | 30.93 |
NESTLE | 2429,7 | 4881094 | 44.20 | 50.48 |
LUDWIG SCHOKOLADE GMBH & CO. KG | 16,1 | 12625 | 0.29 | 0.13 |
STOLLWERCK | 86,5 | 56795,83 | 1,57 | 0.59 |
NESTLE / STOLLWERCK | 0,3 | 5343,75 | 0.01 | 0.06 |
Total | 5496,8 | 9669704 | 100.00 | 100.00 |
Более строгое определение Cost % of Total и TVR % of Total
Статистики Cost % of Total и TVR % of Total вычисляются как отношение значения статистики Cost/TVR в данной ячейке к значению соответствующей статистики в итоговой ячейке, выраженное в процентах. При этом итоговая ячейка, относительно которой производятся вычисления, определяется следующим образом (см. рисунок):
n Если на оси колонок присутствует хотя бы одна медиа-ось, то берется итоговая ячейка по медиа-оси, ближайшей к области данных;
n Если на оси колонок медиа-оси отсутствуют, то берется итоговая ячейка медиа-оси, расположенной ближе всего к области данных на оси рядов;
n Если ни на оси рядов ни на оси колонок нет медиа-осей, то статистика считается неопределенной.
Из этого определения следует, что статистика пересчитывается автоматически при любом изменении расположения медиа-осей в отчете.
Stand. TVR
Данная статистика представляет собой TVR события, приведенный к некоторой «стандартной» длительности.
Основное назначение новой статистики – удобный и быстрый подсчет «покупаемых» (например, 30-секундных) рейтингов для группы событий (например, отобранных роликов для посткампейна).
«Стандартная длительность» задается в окне настроек Tools\Configure\General поле - Standart duration.
n Для единичного эфирного события расчет производится по формуле:
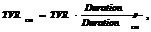
где
§ TVR – соответствующая статистика события,
§ Durationр – реальная длительность события выраженная в секундах,
§ Durationст – стандартная длительность выраженная в секундах (в настоящее время – 30 с).
n Расчет данной статистики для группы событий производится для режима Total как обычная сумма TVRст отдельных событий.
n Расчет статистики для режима AVERAGE производится по следующей формуле:
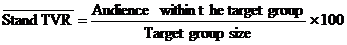
Вычисления в отчетах с временным интервалом длиной более одного дня
Рассматриваются только дни, для которых имеются данные телесмотрения (mdr файлы). Средний день выбирается из дней, ближайших к календарному среднему дню периода.
Вычисления статистик для отдельных событий
Статистики для отдельных событий вычисляются с использованием индивидуальных весов респондентов на день выхода события.
Для вычисления процентных статистик используются размеры генеральной совокупности и целевых групп, рассчитанные по весам респондентов на день выхода события.
Вычисление средних статистик для групп событий
При вычислении средних значений статистик, выраженных в тысячах человек, используется формула:
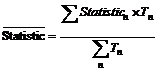 , где
, где
n Statisticn – значение статистики для события n.
n Tn - длительность события n
По этой же формуле рассчитываются средние значения генеральной совокупности и целевых групп, то есть Statisticn в данном случае будет означать размер целевой группы (генеральной совокупности) в день выхода события n.
Процентные статистики вычисляются, как процент от среднего значения целевой группы (генеральной совокупности)
Вычисления статистик для групп событий
Audience, TVR, Размер целевой группы
Суммарные статистики для группы событий вычисляются по формулам:
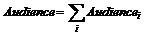
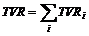
Размер целевой группы вычисляется по формуле:
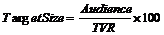
В случае, когда TVR для группы событий равен нулю, вычисляется средний размер целевой группы (см. выше)
Reach, Qualified Reach, Core Audience
Эти статистики вычисляются с использованием весовых переменных среднего дня, затем значения корректируются с использованием алгоритма NBD-коррекции, описанного в справочнике BARB (BARB Television Audience Measurement Reference Manual, Glenthorne House, Hammersmith Grove, London W6, 1993):
Статистические формулы, используемые в расчетах PaloMARS v2.50 с агрегированием
Определение временных интервалов для ТВ событий
Все расчеты для региональных данных (кроме Москвы и Санкт-Петербурга) делаются на основании анализа 15-минутных интервалов, куда попадает каждая из минут анализируемого события (15-минутного агрегирования). При этом 15-минутное агрегирование применяется к данным телесмотрения уже прошедшим минутное агрегирование на этапе подготовки данных для PaloMARS.
Для каждого события при расчете статистик анализируется интервал:
Интервал агрегирования = [Tстарта – 7 min,Tокончания + 7 min], где
Tстарта – время начала события,
Tокончания - время окончания события.
Агрегирование смотрения одной минуты для одного респондента
Для расчетов без агрегирования для респондента в каждую минуту для каждого канала выполняется условие:
![]()
![]()
Для расчетов с агрегированием правило определения смотрения респондентом канала в течение 15 минут выглядит следующим образом.
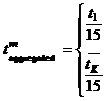 , где
, где
K – количество каналов, которые респондент смотрел в течение 15 минут,
tk – объем смотрения в минутах респондентом k-ого канала в течение 15 минут.
Смотрение респондентом первых (последних) 7 минут суток принимается равным среднему смотрению первых (последних) 15 минут суток.
Важно. Исходя из определения, агрегированная статистика может существовать и не быть равной нулю для минуты отсутствия вещания на технической частоте или логической телекомпании.
Рассмотрим пример. Найдем 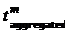 для минуты М. В течение 15 минут [М-7;M+7] респондент смотрел 3 канала, причем (см. рис):
для минуты М. В течение 15 минут [М-7;M+7] респондент смотрел 3 канала, причем (см. рис):
1 канал – 4 минуты (с минуты «М-7» до «М-3»)
2 канал – 7 минут (с минуты «М-3» до «М+4»)
3 канал – 4 минуты (с минуты «М+4» до «М+7»)

Тогда будет иметь следующий вид:
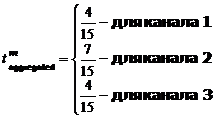 .
.
Агрегированное время смотрения эфирного события одним респондентом
Для каждого эфирного события длительностью более минуты суммарное агрегированное время смотрения для одного респондента считается по формуле:
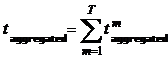 , где
, где
m = 1…T – минуты, которые принадлежат эфирному событию
Aggr. Audience
Агрегированная аудитория эфирного события (выражается в тысячах человек).
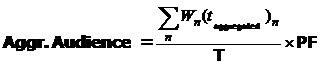 , где:
, где:
n Wn - вес респондента n;
n (t![]() )n - суммарное агрегированное время, потраченное на просмотр события респондентом n;
)n - суммарное агрегированное время, потраченное на просмотр события респондентом n;
n T - длительность события;
n PF – Projection Factor.
Aggr. TVR
Агрегированный рейтинг эфирного события.
Aggr. TVR = 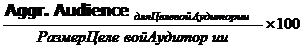
Aggr. Reach
Агрегированный охват (тыс. человек) считается следующим образом.
A) Одно одноминутное событие.
1. Рассчитывается Reach без агрегирования.
2. Рассчитывается TVR, Aggr. TVR.
3. Aggr. Reach рассчитывается из Reach с использованием NBD-коррекции, используя TVR, Aggr. TVR.
Из приведенной методики расчета Aggr.Reach видно, что условие, верное для одной минуты неагрегированных данных, Reach = Audience не должно всегда выполняться для агрегированных из-за применения NBD-коррекции.
В общем случае для одной минуты агрегированных данных:
Aggr. Reach% ≠ Aggr. TVR
B) N одноминутных событий.
1. Рассчитывается неагрегированный Reach![]() (по респондентам базового дня).
(по респондентам базового дня).
2. Reach![]() ,…,Reach
,…,Reach![]() -- охват каждого события (по респондентам базового дня).
-- охват каждого события (по респондентам базового дня).
3. Aggr. Reach![]() ,…, Reach
,…, Reach![]() -- агрегированный охват каждого события (по всем респондентам).
-- агрегированный охват каждого события (по всем респондентам).
4. Reach Frequency Distribution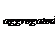 для N событий корректируется с помощью NBD-коррекции с учетом Reach
для N событий корректируется с помощью NBD-коррекции с учетом Reach![]() ,
,  ,
, 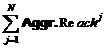 .
.
C) Одно M-минутное событие.
1. Рассчитываем Reach без агрегирования
2. 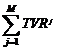 , где
, где ![]() -- рейтинг минуты без агрегирования
-- рейтинг минуты без агрегирования
3. ![]() , где
, где ![]() -- агрегированный рейтинг минуты.
-- агрегированный рейтинг минуты.
4. Reach Frequency Distribution![]() рассчитывается из Reach-Frequency Distribution с использованием NBD-коррекции используя Reach, (1/M)*, (1/M)*
рассчитывается из Reach-Frequency Distribution с использованием NBD-коррекции используя Reach, (1/M)*, (1/M)* ![]() .
.
D) N M-минутных событий
1. Рассчитывается неагрегированный Reach![]() (по респондентам базового дня),
(по респондентам базового дня),
2. Reach![]() ,…,Reach
,…,Reach![]() -- охват каждого события (по респондентам базового дня),
-- охват каждого события (по респондентам базового дня),
3. Aggr. Reach![]() ,…,Reach
,…,Reach![]() -- агрегированный охват каждого события (по всем респондентам).
-- агрегированный охват каждого события (по всем респондентам).
4. Reach Frequency Distribution![]() для N событий корректируется с помощью NBD-коррекции с учетом Reach
для N событий корректируется с помощью NBD-коррекции с учетом Reach![]() ,
, ![]() ,
, 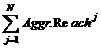 .
.
Расчет остальных агрегированных статистик
Остальные статистики рассчитываются через taggregated , Aggr.Audience, Aggr.TVR
Например, для события длительности T:
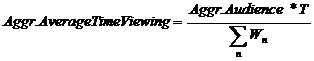 , где
, где ![]() -- вес n-ого респондента;
-- вес n-ого респондента;
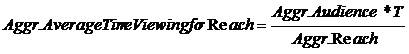 ;
;
Статистики Aggr. OTS, Aggr. GRP рассчитываются с помощью Aggr. TVR, Aggr. Reach.
Описание алгоритма NBD-коррекции
Технология расчета охвата и частотного распределения позволяет получать надежные оценки, частично компенсируя погрешности, вызванные нестабильностью панели.
Расчет охвата для плана производится в два этапа. На первом этапе выполняется расчет только для респондентов, присутствующих в панели в базовый день. Затем эта “сырая” оценка корректируется с помощью специальной вероятностной модели.
Итоговая оценка частотного распределения представляется в виде:
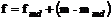 , где:
, где:
2. f — вектор итогового распределения;
3. fmd — “сырая” оценка полученная по выборке базового дня;
4. mmd — модельная оценка распределения для выборки базового дня;
5. m — модельная оценка распределения рассчитанная по всей панели.
Модельные оценки рассчитываются по формуле плотности отрицательного биномиального распределения (NBD).
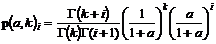 , где
, где
6. i – количество событий в плане;
7. Параметр a рассчитывается по формуле:
![]() , где:
, где:
8. T — GRP рассчитанное для всей панели.
9. Параметры amd и k определяются как решения системы уравнений:
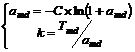 , где
, где
10. ![]() ;
;
11. P0 — взвешенная доля респондентов базового дня, не видевших ни одного события;
12. Tmd — GRP рассчитанное по выборке базового дня.
Существуют несколько исключений, требующих специальной обработки:
Исключение 1. P0=0.
Расчет производится по базовым формулам, но вместо T используется (T–100).
Исключение 2. P0=1 (см. исключение 3 при i=0).
Исключение 3. fmd(i)=1 для некоторых i.
Сначала определяется величина ![]() . Итоговое распределение рассчитывается по формуле:
. Итоговое распределение рассчитывается по формуле:
f(i)=1-|x|, причем
13. Если x<0, то f(i-1)=|x|;
14. Если x>0, то f(i+1)=x.
Все остальные частоты полагаются равными 0.
Исключение 4. План состоит только из одного события (см. исключение 5).
Исключение 5. C³-1
Вместо отрицательного биномиального распределения используется распределение Пуассона.
![]() , где:
, где:
15. ![]() .
.
ОПИСАНИЕ АТРИБУТОВ
Общие атрибуты
TVCompany
Телекомпания (логический канал). На одной технической частоте – техническом канале (атрибут – TV CHANNEL) могут находиться два логических канала – телекомпании (TV COMPANY).
Например, в Москве телекомпании (TV COMLPANY) ТВЦ и МОСКОВИЯ имеют один и тот же технический канал (TV CHANNEL) – 3 канал.
TVCompany description
Описание технического канала (может отсутствовать).
TVCompany ID
Идентификатор телекомпании в БД.
TVChannel
Технический канал – техническая частота.
TVChannel description
Описание технического канала (может отсутствовать).
TVCompany original
Оригинальная телекомпания – телекомпания, на которой транслировался оригинальный выход эфирного события.
Date
Дата.
Формат: дд/мм/гг
Date original
Дата выхода оригинального эфирного события.
Формат: дд/мм/гг
Week day
День недели.
Пример: Понедельник
Duration
Длительность эфирных событий (телепередач, рекламных блоков и роликов).
Формат: чч:мм:сс
Time start
Время начала эфирных событий.
Формат: чч:мм:сс
Time end
Время окончания эфирных событий.
Формат: чч:мм:сс
Start time original
Время начала оригинального эфирного события.
Формат: чч:мм:сс
National channel
Национальная телекомпания - центральная телекомпания, ретрансляцией которой является анализируемая телекомпания.
Для региональных телекомпаний создана служебная “локальная телекомпания”.
Например, анализируемая телекомпания ТВ-6 (Владивосток), для нее национальная телекомпания – ТВ-6.
National channel description
Описание национального канала (может отсутствовать).
Event type
Тип анализируемых эфирных событий (телепередач, рекламных блоков или роликов).
Пример: Programme flights
Event status
Статус события (реальный, виртуальный). Позволяет учесть факт трансляции события в Москве и России.
Пример: Real
Region
Регион, город.
GRP Type
Продаваемая телеканалом аудитория.
GRP description
Описание продаваемой телеканалом аудитории.
Day type
Тип дня (рабочий, выходной, праздничный)
Атрибуты телепередач
Programme
Название телепередачи.
Programme group
Группировка телепередач по рубрикам[7].
Programme genre
Жанр телепередачи – 1-ый более общий уровень классификатора.
Например, Музыкальные программы
Programme category
Категория телепередачи – 2-ой более детальный уровень классификатора.
Например, Музыкально-развлекательная передача.
Programme description
Описание телепередачи (может отсутствовать).
Programme flight start
Время начала телепередачи.
Формат: чч:мм:сс
Programme flight end
Время окончания телепередачи.
Формат: чч:мм:сс
Programme flight duration
Длительность телепередачи.
Формат: чч:мм:сс
Programme flight ID
Идентификационный код выхода анализируемой телепередачи.
Формат: .
Original programme flight ID
Идентификационный код оригинального выхода программы (идентификатор выхода программы в Москве, чьей ретрансляцией является анализируемая программа).
Формат:
Атрибуты рекламных блоков
Break
Название рекламного блока.
Пример: Внутренний рекламный блок 1 (региональный).
Breaks count
Количество рекламных блоков в телепередаче.
Break price per minute
Стоимость одной минуты рекламного блока в у. е.
Формат: 0.00
Break price per GRP point
Стоимость одного пункта рейтинга продаваемой аудитории в ролике стандартной длительности в рекламном блоке в у. е.
Формат: 0.00
Break position
Порядковый номер рекламного блока в телепередаче (для внешних блоков – 0).
Break description
Описание рекламного блока (может отсутствовать).
Пример: рекламный блок внутри передачи, номер соответствует порядку следования.
Break type
Тип рекламного блока – внутренний или внешний (внешний – всегда блок до программы).
Пример: Internal.
Break flight ID
Идентификационный код выхода рекламного блока.
Формат:
Original break flight ID
Идентификационный код оригинального выхода рекламного блока (идентификатор выхода блока в Москве, чьей ретрансляцией является анализируемый блок).
Формат:
Break flight start
Время начала рекламного блока.
Формат: чч:мм:сс
Break flight end
Время окончания рекламного блока.
Формат: чч:мм:сс
Break flight duration
Длительность рекламных блоков
Формат: чч:мм:сс
Атрибуты рекламных роликов
Clip
Название рекламного ролика.
Пример: ORBIT WINTERFRESH (девушка и парень фотографируются).
Clip First issue date
Дата первого выхода рекламного ролика
Clips count
Количество роликов в анализируемом рекламном блоке.
Clip position
Позиция рекламного ролика в блоке (номер по порядку).
Clip price
Стоимость рекламного ролика (рассчитывается из стоимости минуты рекламного блока и длительности ролика).
Формат: 0.00
Clip price per GRP
Стоимость рекламного ролика по GRP (рассчитывается из стоимости одного пункта рейтинга ролика стандартной длительности в рекламном блоке и длительности ролика).
Формат: 0.00
Clip description
Описание рекламного ролика.
Пример: Парень и девушка заходят в фото-автомат, девушка достает две подушечки O. W., они начинают дурачиться перед объективом,
график КНЦ в руке пачка O. W., "Зимняя свежесть и защита от кариеса".
Clip expected duration
Ожидаемая длительность рекламного ролика в сек.
Формат: 30
Clip type
Тип рекламы (рекламный ролик, спонсор, спонсорский ролик, телемагазин).
Clip type description
Описание типа рекламы.
Пример: Основной вид рекламы, имеет фиксированную длительность.
Original spot flight ID
Идентификационный код оригинального выхода рекламного ролика (идентификатор выхода ролика в Москве, чьей ретрансляцией является анализируемая телепередача).
Формат:
Advertiser
Рекламодатель.
Например, PROCTER & GAMBLE.
Advertiser description
Описание рекламодателя.
Например, .
Advertiser list
Список рекламодателей, разместившихся в одном ролике.
Например, PROCTER & GAMBLE, Merloni.
Area
Распространение ролика. Может быть Столичным (только Москва), Провинциальным (регион, кроме Москвы), Межрегиональным (минимум в двух регионах), Национальным (в Москве и еще в одном регионе).
Пример: national
Article Level1
Верхний уровень (1-ый) классификатора товаров и услуг.
Пример: ТОВАРЫ
Article Level2
Второй уровень классификатора товаров и услуг.
Пример: КОНДИТЕРСКИЕ ИЗДЕЛИЯ.
Article Level3
Третий уровень классификатора товаров и услуг.
Пример: ЖЕВАТЕЛЬНАЯ РЕЗИНКА.
Article Level4
Четвертый уровень классификатора товаров и услуг.
Пример: ЖЕВАТЕЛЬНАЯ РЕЗИНКА (РАЗНОЕ).
Brand
Торговая марка (бренд)
Пример: ORBIT.
Brands List
Список торговых марок (брендов) в одном ролике
Пример: Ariel, Indesit.
Brand description
Описание бренда. Может отсутствовать
Model
Модель – подмножество бренда, непосредственное описание товара.
Пример: ORBIT WINTERFRESH ЖЕВАТЕЛЬНАЯ РЕЗИНКА.
Models List
Список моделей в одном ролике
Model description
Описание модели. Может отсутствовать
[1] Если в списке статистик для базы CITEIS отсутствуют их региональные аналоги необходимо:
· В файле MARS. INI в соответствующем DATA SET установить параметр COUNTRY=RUSSIA
· В файле MARS. INI в соответствующем DATA SET добавить строку RegionalExpression= CITY1'I_SCALE
[2] Так же эта статистика может рассчитываться по формуле: TVR* duration (sek)/ 100
[3] Так же эта статистика может рассчитываться по формуле: Aver. Time. View*100/ reach%
[4] [4] Так же эта статистика может рассчитываться по формуле: Aver. Time. View*100/ cum. reach%
[5] Total, соответствующий данной ячейке, выбирается следующим образом. Если на оси X (правый верхний угол таблицы) находится хотя бы одна медиа-размерность, то выбирается Total медиа-размерности, ближайшей к области данных на этой оси, если ось X не содержит медиа-размерностей, то выбирается Total медиа-размерности, ближайшей к области данных на оси Y (нижний левый угол таблицы).
[6] Total, соответствующий данной ячейке, выбирается следующим образом. Если на оси X (правый верхний угол таблицы) находится хотя бы одна медиа-размерность, то выбирается Total медиа-размерности, ближайшей к области данных на этой оси, если ось X не содержит медиа-размерностей, то выбирается Total медиа-размерности, ближайшей к области данных на оси Y (нижний левый угол таблицы).
[7] Делается на основе поставляемых рейт-кардов – если какая-то группа входит в рейт-кард (например, МИР КИНО), она добавляется в список рубрик

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
