
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Функция L называется функцией правдоподобия. Выборочной оценкой параметра b является параметр b. На практике удобнее иметь дело не с самой функцией, а с ее логарифмом, поэтому оценку параметра b можно получить, решая уравнение: ![]()
Если распределение величины у в генерируемой последовательности является нормальным, то вероятность найти у между у и у+dy равна:
![]()
![]()
Функция подобия L достигает максимума, если стоящая в показателе формулы сумма квадратов минимальна
![]()
Где 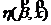 - функция от независимой переменной х любого вида с системой коэффициентов b, постоянных для каждого вида функции и подлежащих определению.
- функция от независимой переменной х любого вида с системой коэффициентов b, постоянных для каждого вида функции и подлежащих определению.
При линейной параметризации:
![]()
где 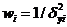 - вектор-столбец весов, о котором сказано ниже; i=1,n – общее число попыток; j=1,p – число факторов в множественной ситуации.
- вектор-столбец весов, о котором сказано ниже; i=1,n – общее число попыток; j=1,p – число факторов в множественной ситуации.
Выражение и есть основная зависимость метода наименьших квадратов – это частный случай метода максимума правдоподобия при нормальном распределении. Для того, чтобы вычислить максимум выражения, следует взять частные производные этого выражения по всем параметрам и приравнять их к нулю, одновременно заменяя значения параметров их выборочными оценками. Полученная система называется системой нормальных уравнений, которая в матричной форме имеет вид:
(X*WX)B=X*WY.
Формула (4.49) отличается от формулы (3.5) только диагональной матрицей весов:
||w1 0 ||
|| w2 ||
W= ||…………………. ||
||0 wn ||
Расшифровка остальных значений дана в гл.3.
Для простейшего случая, когда имеет место парная зависимость вида y=f(x) и линейная параметризация, формула (4.47) принимает вид: ![]() .
.
Соответственно система нормальных уравнений имеет более простой вид:
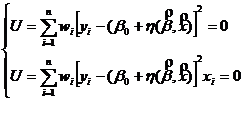
Если каждому фиксированному значению фактора х соответствует только одно наблюдение зависимой переменной у , то дисперсия у отсутсвует и необходимость во взвешивании отпадает, а формула (4.52) приводится к формуле (2.5).
Рассмотрим теперь для простейшего случая парной линейной связи классификацию ситуаций, которые могут иметь место при проведении экспериментов.
Классификацию способов наблюдений, которые не обязательно зависят от воли экспериментатора, а часто обусловлены особенностями объекта наблюдения, для наглядности представим в виде графических схем.
На рис. Изображена экспериментальная ситуация первого типа. Здесь каждому фиксированному значению фактора х соответствует только одно наблюдение зависимой переменной у . Система имеет самый простой вид.
На рис. 18 изображена экспериментальная ситуация второго рода, когда каждому фиксированному значению фактора х соответствует к наблюдений зависимой переменной у , имеющих нормальное распределение, математическое ожидание h и дисперсию ![]() .
.
Для оценки параметров служит система нормальных уравнений со взвешиванием. На рис.19 изображена экспериментальная ситуация третьего типа. Здесь фактор х , так же как и независимая переменная у , измеряются с погрешностями. Вместо одного значения х в каждом опыте имеется к значений фактора х, имеющих нормальное распределение, математическое ожидание h и дисперсию ![]() . Распределение х некоррелировано с распределением у. Для оценка коэффициентов b0,b1 в этой ситуации метод наименьших квадратов малоэффективен, поэтому используют другой частный случай метода максимума правдоподобия.
. Распределение х некоррелировано с распределением у. Для оценка коэффициентов b0,b1 в этой ситуации метод наименьших квадратов малоэффективен, поэтому используют другой частный случай метода максимума правдоподобия.
Эти рассуждения можно распространить на любой вид зависимости у от х и на р-мерное факторное пространство. Изложим основные принципы этого метода. Как уже указывалось, вместо одного фиксированного измерения фактора х имеется совокупность элементарных измерений, для которых, если считать распределение нормальном, известны генеральное среднее x и генеральная дисперсия ![]() , так что можно найти зависящие от статистики уровни для выборочного среднего
, так что можно найти зависящие от статистики уровни для выборочного среднего ![]() и выборочной дисперсии
и выборочной дисперсии ![]() , либо величины оценивают на основании достаточно большой независимой выборки.
, либо величины оценивают на основании достаточно большой независимой выборки.
Этот случай анализа наблюдений называется конфлюэнтным, так если бы совокупность наблюдений фактора х с неизвестной точностью среднего и дисперсии слились в одну точку, то имел бы место обычный регрессивный анализ. Метод максимума правдоподобия может привести задачу конфлюэнтного анализа к методу наименьших квадратов с использованием последовательных приближений. Напомним, что рассматривается простейшая ситуация y=f(x). Разделение этих двух переменных на независимую переменную теряет смысл при случае колебания величин.
Здесь рассматривается также такой, часто встречающийся случай, когда распределения х и у не коррелированны. Плотность вероятности: найти измеряемую точку (центр выборки) в генеральной совокупности около х и у двумерного распределения равна:
![]()
если центром распределения в генеральной совокупности являются точки h и x. Интенсивность источника плотности: вероятности найти событие в точке ![]() пропорциональна длине теоретической кривой и некоторой функции j(x). Полная плотность вероятности: найти событие в точке
пропорциональна длине теоретической кривой и некоторой функции j(x). Полная плотность вероятности: найти событие в точке ![]() определяется интегрированием по дуге кривой:
определяется интегрированием по дуге кривой:
![]()
где элемент дуги кривой: ![]() имеет ту же размерность, что и dx. Функция j(x) представляет собой плотность источников точек, получающихся при измерении, и может быть определена после детального анализа физического смысла плотности вероятности:
имеет ту же размерность, что и dx. Функция j(x) представляет собой плотность источников точек, получающихся при измерении, и может быть определена после детального анализа физического смысла плотности вероятности:
![]()
Функция правдоподобия равна плотности вероятности найти одновременно все точки в тех местах, где они обнаружены, и следовательно (так как измерения независимы), при разных ![]() имеет вид произведения интегралов, взятого по всем наблюдаемым событиям.
имеет вид произведения интегралов, взятого по всем наблюдаемым событиям.
При некоторых условиях, которые обычно выполняются в экспериментах, конфлюэнтную задачу можно свести к последовательности регрессионных задач. Если на участке кривой, находящейся в интервале от  и от
и от ![]() до
до ![]() , наклон и кривизна изменяются мало (кривая достаточно гладкая), то при вычислении интеграла в случае нормального распределения можно ограничиться участком кривой около точки
, наклон и кривизна изменяются мало (кривая достаточно гладкая), то при вычислении интеграла в случае нормального распределения можно ограничиться участком кривой около точки ![]() . Другим условием, позволяющим свести конфлюэнтную задачу к последовательности регрессионных задач, является требование, чтобы точка
. Другим условием, позволяющим свести конфлюэнтную задачу к последовательности регрессионных задач, является требование, чтобы точка ![]() не находилась ближе от конца теоретической кривой, чем на
не находилась ближе от конца теоретической кривой, чем на ![]() .При этих условиях можно представить плотность распределения в виде плотности частного распределения наблюдений yi при фиксированных xi, имеющих вид, близкий к плотности распределения.
.При этих условиях можно представить плотность распределения в виде плотности частного распределения наблюдений yi при фиксированных xi, имеющих вид, близкий к плотности распределения.
На небольшом участке кривой в окрестностях точки ![]() теоретическую кривую можно приближенно представить первыми тремя членами ряда Тейлора:
теоретическую кривую можно приближенно представить первыми тремя членами ряда Тейлора:
![]()
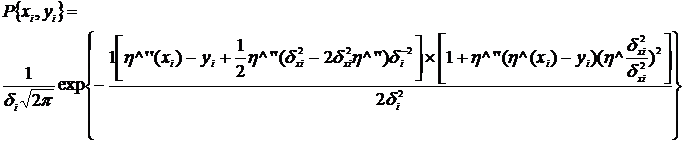
![]()
![]()
- значение первой и второй производной оценки кривой регрессии при x=xi / В формуле (4.58) в качестве ненормальных весов входят
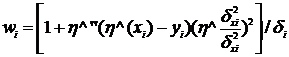
Кроме того, центром распределения для у является сдвинутая оценка кривой регрессии h(х)+ a, где
![]()
Так как производные h^’’ и h^’ и отклонение Lу^=h (x)-y до проведения анализа неизвестны, то на первый может показаться, что возникает ситуация, которая носит название «заколдованный круг». Из этого круга можно выйти с помощью последовательных приближений, используя тот факт, что функция правдоподобия слабее зависит от изменения весов при подборе кривой регрессии, чем от разностей y-h^(x).
Нулевое приближение можно получить, проведя на глаз кривую через экспериментальные точки. Первую производную, получаемую дифференцированием кривой нулевого приближения, подставляют в знаменатель выражения, а вторую производную заменяют нулем и анализируют вновь полученные веса.
Дифференцирование кривой регрессии первого приближения позволяют найти величины h^’,h^’’ и dy, с помощью которых вновь пересчитывают веса и оценивают сдвиги.
Эту процедуру уточнения кривой и весов продолжают до тех пор, пока изменения весов не станут меньше заранее назначенной величины, отражающей точность проводимых расчетов. При достаточно малых ![]() сходимость процесса итерации должна быть достаточно быстрой.
сходимость процесса итерации должна быть достаточно быстрой.
Методика корреляционно-регрессионного анализа.
1. Понятие о корреляционных связях между двумя случайными переменными.
В исследованиях производственного и лабораторного характера часто приходится изучать характер связи между количественными или качественными признаками. Иногда эти связи, называемые функциональными, можно достаточно точно описать методами математического анализа.
При наличии функциональной связи между величинами Х и У, зная значения одной из них можно точно указать значение другой. Однако, гораздо чаще приходится исследовать связи между переменными имеющими вероятностный, «стохастический» характер. В этом случае, если величина У связана с величиной Х вероятностной зависимостью, зная значение Х, нельзя точно указать значение У, а можно только указать ее закон распределения, зависящий от того какое значение приняла величина Х.
Вероятностные связи между случайными величинами многообразны и сложны. Наиболее простой и имеющий важное практическое значение является корреляционная связь, которая между двумя случайными переменными величинами выражается в том, что на одной случайной величины другая реагирует изменением своего математического ожидания. В общем виде связь между двумя случайными величинами Х и У может быть выражена уравнением регрессии:
М(у/х)=f(x) (1)
С помощью (1) можно прогнозировать значение зависимой случайной переменной.
Корреляционный анализ заключается в поисках ответов на вопросы:
1) Существует ли связь между исследуемыми переменными?
2) Какова форма и сила этой силы?
Ответы могут быть получены с помощью коэффициента корреляции rxy и корреляционным соотношением hy, которые обладают следующими важными свойствами:
1. Если rxy=±1, то межу исследуемыми переменными существует функциональная линейная связь вида у=ах+b.
2. Если rxy=0 между Х и У не может существовать линейная корреляционная связь, но возможна нелинейная.
3. Тем ближе rxy к ±1, тем теснее линейная корреляционная связь между Х и У.
4. Если между Q =0, то между Х и У нет корреляционной связи.
5. Если Q=1, то У функционально зависит от Х, то есть всякому значению соответствует одно определенное значение У.
6. Чем ближе Q к 1, тем теснее связь между переменными
7. Если Q= rxy, то между переменными существует только линейная связь.
Вычисление и анализ rxy и hy составляют основу первого этапа анализа взаимосвязи между случайными величинами, который называется корреляционным анализом.
Затем проводится регрессионный анализ, основная цель которого определение аналитического выражения взаимосвязи между исследуемыми прямыми, то есть уравнения регрессии.
Если Qy=|Rxy|, то взаимосвязь представлена в виде
М(у/х)=a0 +a1х, где а1 – коэффициент регрессии.
Если Qy ¹ Rxy, то для поиска уравнения регрессии используются различные нелинейные функции.
Коэффициент корреляции Rxy и Qy являются теоретическими характеристиками взаимосвязи между исследуемыми переменными. Их вычисления базируются на таких теоретических параметрах распределения случайных величин Х и У, как математические ожидания М(х) и М(у), среднеквадратичными отклонениями sх и sу. При корреляционно - регрессивном анализе результатов экспериментальных данных вместо теоретических характеристик Rxy и Qy используются их выборочные: rxy - эмпирический коэффициент корреляции, hху – эмпирическое корреляционное соотношение.
Корреляционный и регрессионный анализ между двумя случайными переменными состоит из пяти этапов:
1. проверка эксперимента;
2. предварительная обработка результатов эксперимента и составление корреляционной таблицы;
3. расчет коэффициента корреляции и корреляционного отношения;
4. проверка гипотезы равенства коэффициентов корреляции корреляционному отношению и вывод уравнения регрессии;
5. анализ уравнения
II. Определим математическое ожидание и дисперсию:
![]()
Для проверки гипотезы об отсутствии расхождений теоретического и статического распределений используется критерий соответствия ![]() (Пирсона). Для этого результаты измерений предварительно разбиваются на интервалы. Определяем минимум и максимум значения величины Х и У. Определяем размах варьирования: C=max-min. Задаются числом интервалов » 10 (с учетом -¥ и +¥). Определяют цену интервала. Подсчитываются частоты попадания наблюдений по каждому интервалу.
(Пирсона). Для этого результаты измерений предварительно разбиваются на интервалы. Определяем минимум и максимум значения величины Х и У. Определяем размах варьирования: C=max-min. Задаются числом интервалов » 10 (с учетом -¥ и +¥). Определяют цену интервала. Подсчитываются частоты попадания наблюдений по каждому интервалу. ![]() определяется из выражения:
определяется из выражения:
![]()
где l – число интервалов;
mi – число результатов измерений, попавших в i–й интервал;
n – число всех результатов измерений;
pi – вероятность попадания в i –й интервал при нормальном законе распределения вероятностей.
По таблице ![]() -распределения определили вероятность того, что найденная величина превзойдет табличное значение
-распределения определили вероятность того, что найденная величина превзойдет табличное значение ![]() , определяемое при надежности (0.95,0.9,0.999).
, определяемое при надежности (0.95,0.9,0.999).
Если ![]() <
< ![]() , то возможно принять гипотезу об отсутствии расхождения теоретического и статического распределения, то есть возможно применение корреляционно-регрессивного анализа.
, то возможно принять гипотезу об отсутствии расхождения теоретического и статического распределения, то есть возможно применение корреляционно-регрессивного анализа.
III. Коэффициент корреляции определяется из соотношения:
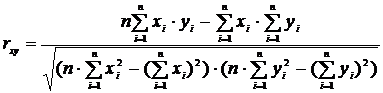
Полученные в результате расчетов коэффициенты корреляции сводятся в таблицу. Однако не всякое значение коэффициентов корреляции является достаточным для статически обоснованных выводов о наличии корреляционной связи между исследуемыми переменными. Для этого производят оценку значимости коэффициентов корреляции.
Приближенный метод:
Можно считать, что ![]() значительно отличается от нуля и связь между исследуемыми факторами реальна, если
значительно отличается от нуля и связь между исследуемыми факторами реальна, если 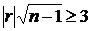 . В противном случае прямолинейная корреляционная связь между исследуемыми величинами не обнаруживается.
. В противном случае прямолинейная корреляционная связь между исследуемыми величинами не обнаруживается.
Уточненный метод:
Приближенный метод может оказаться недостаточным при небольшом числе наблюдений. В этом случае для оценки значимости коэффициентов корреляции предварительно вычисляем:
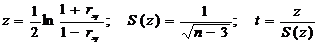
где t – критерий Стьюдента, выбирается по таблице tb в зависимости от числа степеней свободы k=n и установленного уровня доверительной вероятности. Условия значимости коэффициентов корреляции t > tb , то есть коэффициенты корреляции можно считать достоверными.
В случаях криволинейной зависимости между параметрами проводим расчет корреляционного отношения:

где M(Dx/y) – математическое ожидание условной дисперсии, которое является характеристикой рассеивания выходной переменной относительно линии регрессии M(y/x). Dy – дисперсия выходной переменной.
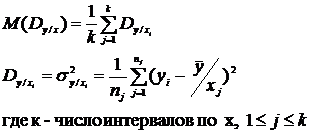
Проверка гипотезы равенства коэффициента корреляции корреляционному отношению необходима для определения характера связи между переменными.
Определяется величина критерием Фишера – F
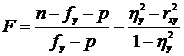
n – число измерений;
p – число определенных параметров в уравнение регрессии (для линейного р=2);
fy - число интервалов признака Х.
Расcчитанное по формуле значение F сравнивается с табличным значением Ft, определяемое в зависимости от степени свободы. Если F £ Ft, то можно считать, что зависимость между исследуемыми величинами приблизительно линейна.
Задача исследования заключается в том, чтобы по результатам наблюдений определить функцию:
![]()
которая является наилучшим приближением к теоретической зависимости между факторами (используем метод наименьших квадратов). После вывода уравнения регрессии необходимо оценить ее пригодность, то есть неодходимо определить можно ли с помощью полученной модели прогнозировать изменение выходного параментра в зависимости от поведения входного.
Определим коэффициенты множественной корреляции (при числе входных факторов более 1).
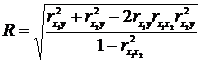
Сводный коэффициент корреляции R всегда заключен между 0 и 1. Если величина у не зависит от величин x1 и x2 , то теоретическое значение R=0, и между величиной у и величинами x1 и x2 нет линейной корреляционной зависимости (но может быть нелинейная) .
Проверка адекватности модели заключается в следующем:
Для раскрытия смысла проверки дадим графическую интерпретацию результатов эксперимента.
|
|





 На корреляционном поле число точек в каждой клетке соответствует частотам, определенных при использовании критерия
На корреляционном поле число точек в каждой клетке соответствует частотам, определенных при использовании критерия Оценка адекватности модели заключается в сравнении общей дисперсии исследуемого признака ![]() с дисперсией, обусловленной получением уравнения регрессии.
с дисперсией, обусловленной получением уравнения регрессии.
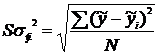
и характеризующей отклонение эмпирической линии регрессии от теоретической. Для сравнения используется критерий Фишера
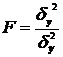
Модель можно считать адекватной, если вычисленное значение будет меньше табличного.
Построение доверительных границ для линии регрессии.
Статические характеристики, полученные в результате обработки экспериментальных данных, являются оценками теоретических параметров, а не самими теоретическими параметрами. Например, ![]() - оценка М(х),
- оценка М(х), ![]() . Уравнение регрессии,
. Уравнение регрессии, ![]() являющаяся оценочным по отношению к теоретическому уравнению
являющаяся оценочным по отношению к теоретическому уравнению ![]() , которе точно указать нельзя, но можно построить доверительную область, в которой лежит линия регрессии. Чтобы построить эту область необходимо использовать критерий Стьюдента:
, которе точно указать нельзя, но можно построить доверительную область, в которой лежит линия регрессии. Чтобы построить эту область необходимо использовать критерий Стьюдента:
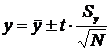
![]()
Получение моделей по результатам активного воздействия на процесс
При изучении процессов обычно поочередно изменяется каждый фактор для определения частного максимума при постоянном значении всех прочих факторов. Число опытов, необходимое для отыскания оптимальных условий процесса, зависит от числа факторов, из взаимного влияния и числа вариаций каждого из них. Минимальное число опытов будет соответствовать предположению, что взаимодействие факторов отсутствует. Максимум – это оптимальное значение любого фактора будет существенно изменяться в зависимости от сочетания всех остальных. Например, при 4 факторах и 5 вариациях, min = 4*5=20, max = 4^5 = 625. Действительно, необходимое число опытов находится в промежутке между min и max.
Методы планирования экспериментов основаны на одновременном изменении многих факторов, причем эти планы допускают последующую обработку данных и получить математическую модель в заданной области экспериментирования.
Применение этих факторов возможно при следующих условиях:
- существует выходной параметр (функция цели) процесса, количественно определяющий его эффективность (возможно при ограничениях, накладываемых на другие выходные параметры);
- функция отклика непрерывна, т. е. при изменении значений факторов функция цели изменяется непрерывно;
- функция отклика одноэкстремальна, т. е. существует одно оптимальное соотношение факторов, при котором функция цели имеет max (min) значение;
- известны все факторы, существенно влияющие на процесс, а факторы планируемые в эксперименте управляемые, т. е. можно изменять их значение по заранее составленному плану;
- результаты опытов воспроизводимы.
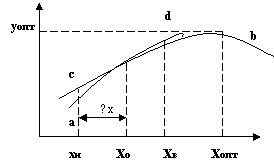 Пусть на процесс влияет только один фактор, что геометрически можно представить в виде кривой ab (называемой одномерной функцией отклика) экстремуму которой соответствует координата уопт и xопт.
Пусть на процесс влияет только один фактор, что геометрически можно представить в виде кривой ab (называемой одномерной функцией отклика) экстремуму которой соответствует координата уопт и xопт.
При планировании опытов уровень фактора xo называется нулевым, ∆x – интервалом варьирования, xн – уровень нижний [колеруется (-)], уровень xв – верхним (+).
При экспериментировании в интервале xo ± ∆x получают уравнение cd, приближенно описывающей кривую ab (ее части).
При двух факторах функция отклика геометрически может быть представлена как поверхность в трехмерном пространстве или в виде уравнения
|
|

|
|
|

|
 |

|
|
|

 На рисунке представлено движение к max поверхности отклика методами однофакторного эксперимента и крутого восхождения (нанесены кривые равного значения параметра оптимизации для двух переменных x1 и x2).
На рисунке представлено движение к max поверхности отклика методами однофакторного эксперимента и крутого восхождения (нанесены кривые равного значения параметра оптимизации для двух переменных x1 и x2).
При классическом методе исследователь вначале фиксирует переменную x1 и двигает из точки O. Изменяя переменную x2, он определяет точку P1, соответствующую экспериментальному значению параметра оптимизации. В точке P1 фиксируется переменная x2 и начинает движение вдоль оси x1, что позволяет найти точку Q1. Затем снова фиксируется x1 и продолжается движение по x2 и т. д. до достижения оптимума.
Более эффективным является план, по которому первоначально определяется направление Q, а более подробное изучение поверхности отклика производится уже в оптимальной области.
В случае большого числа факторов геометрическое представление функции невозможно, а аналитическое выражение
y=f(x1,x2,…,xn)
можно только представить в виде гиперповерхности. Эффективность планирования тем выше, чем больше факторов влияет на процесс.
Опыты должны быть рандомизированы, т. е. производиться в последовательности, которая устанавливается с помощью таблицы случайных чисел или любой процедуры, обеспечивающей случайный порядок проведения опытов. Рандомизация позволяет нивелировать систематические (периодические) воздействия неконтролируемых факторов.
Для упрощения записи условий эксперимента и обработки экспериментальных данных масштабы по осям независимых переменным выбираются (после выбора интервала варьирования), так чтобы верхний уровень соответствовал +1, нижний –1, а основной 0. Это соответствует преобразованию координат
x=(xн-xн,0)/ ∆xн
x – кодированное значение факторов;
xн – натуральное значение факторов;
xн,0 – основной уровень (натуральный);
∆xн – интервал варьирования;
Полный факторный эксперимент (ПФЭ)
ПФЭ позволяет оценивать линейные эффекты взаимодействия при большом числе независимых переменных. В ПФЭ для каждого фактора выбирается определенное число уровней k и затем осуществляются все возможные комбинации уровней. Недостатком ПФЭ является необходимость одновременной подстановки большого числа опытов, так как с ростом числа факторов n число опытов N растет по показательной функции
N=k^n
При варьировании каждого фактора на двух уровнях (+1) и (-1) число возможных комбинаций (опытов)
N=2^n.
Матрица факторного плана составляется по правилу: частота смены знака (уровня) каждого последующего. В таблице приведен план серии опытов для n=3.
N опыта | фактор | Параметр оптимизации | буквенная запись строк | ||
x1 | x2 | x3 | |||
1 | -1 | -1 | -1 | y1 | 1 |
2 | +1 | -1 | -1 | y2 | a |
3 | -1 | +1 | -1 | y3 | b |
4 | +1 | +1 | -1 | y4 | ab |
5 | -1 | -1 | +1 | y5 | c |
6 | +1 | -1 | +1 | y6 | ac |
7 | -1 | +1 | +1 | y7 | bc |
8 | +1 | +1 | +1 | y8 | abc |
Каждый столбец матрицы называется вектор – столбцом, строка – вектор – строка. Иногда для сокращения записи матрицы вводят буквенные обозначения строк. Пусть x1 соответствует a, x2 – b, x3 – c и т. д. Если для матрицы планирования выписать буквы только для факторов, находящихся на верхних уровнях, то каждой строке будет соответствовать единственная комбинация из букв. Опыт со всеми факторами на нижних уровнях обозначаются (1).

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
