
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
разбиение задачи на параллельные фрагменты;
их распределение по ПЭ мультипроцессора;
обмен данными между ними и синхронизацию.
Основной недостаток данного подхода состоит в том, что на программиста возлагается дополнительная нагрузка. Ему необходимо не только запрограммировать задачу, но и позаботиться о ее распараллеливании. Это ведет к снижению производительности труда программиста и, что более существенно, к снижению надежности программ.
Кроме того, при ручном статическом распараллеливании не всегда можно добиться глубокого (предельного) распараллеливания программы - в силу теоретических ограничений возможностей статического анализа. Это общий недостаток всех статических подходов к решению проблемы распараллеливания программ. Более подробный анализ данного обстоятельства приведен в следующем разделе.
Автоматическое статическое распараллеливание
В данном подходе используют распараллеливающий компилятор, который на этапе компиляции (в статике):
пытается обнаружить информационно независимые фрагменты задачи,
оформить их параллельное выполнение, синхронизацию и передачу данных.
Несмотря на то, что применение этого метода несомненно облегчает задачу распараллеливания, статический анализ для многих случаев не способен предусмотреть все сочетания условий, которые могут возникнуть в процессе выполнения программы. Это является следствием алгоритмической неразрешимости данной проблемы для общего случая.
Данный недостаток ведет к снижению эффективности выполнения прикладной программы и, как следствие, снижению производительности вычислительной системы в целом.
Еще одним недостатком статического подхода (и ручного, и автоматического) является зачастую возникающая необходимость проводить распараллеливание программы заново в случае изменения конфигурации системы (например, изменения числа процессоров) и/или в случае изменения входных данных, которое часто приводит к изменению загрузки отдельных процессоров или процессорных элементов.
Автоматическое динамическое распараллеливание
В данном подходе фрагменты программы, которые могут быть выполнены параллельно, обнаруживаются системой (операционной средой параллельного выполнения) в динамике-в процессе выполнения программы.
Это позволяет проводить балансировку загрузки отдельных процессорных элементов, составляющих вычислительную систему и, как следствие, без изменения исполнять системные и прикладные программы на вычислительных установках различной конфигурации (адаптируемость к изменению конфигурации).
Реализация данного варианта распараллеливания позволяет рассчитывать на достижение более глубокой степени параллелизма, так как в общем случае только в динамике возможно определить, когда и сколько параллельных ветвей возникнет в процессе счета, какие информационные связи будут установлены между ними и какая синхронизация между ними потребуется для их корректного выполнения.
10. Анализ алгоритмов на предмет выделения параллельных гранул
Гранулы параллелизма
Различают различные подходы к определению размера (вычислительной сложности) тех параллельных фрагментов, на которые разбивается программа:
Крупноблочное (large grained) распараллеливание. В этом случае параллельными фрагментами являются отдельные задачи или подзадачи пользователей, информационно несвязанные (слабо связанные) между собой. Такой уровень параллелизма-"каждой задаче-свой процессор"-характерен для обычных операционных систем для мультипроцессорных ЭВМ. Подход не имеет отношения к концепции автоматического динамического распараллеливания программ.
Мелкозернистое (fine grained) распараллеливание. В этом случае параллельными фрагментами являются отдельные элементарные операции (data flow), комбинаторы (элементарные функции, reduction machine). Чрезмерное "измельчение" гранул параллелизма приводит к тому, что накладные расходы на организацию параллельного выполнения фрагментов могут в несколько раз превышать вычислительную сложность этих фрагментов. Тем самым, на накладные расходы может уходить большая часть производительности мультипроцессора.
Средне зернистое (coarse grained) распараллеливание. В этом случае параллельные фрагменты имеют среднюю вычислительную сложность
Фрагменты должны быть:
достаточно крупными, чтобы их вычислительная сложность превышала бы накладные расходы на организацию их выполнения;
достаточно мелкими, чтобы в процессе выполнения можно было бы ожидать возникновения такого количества таких фрагментов, которое будет достаточным для загрузки всех ПЭ мультипроцессора.
Например, гранулой параллелизма в Т-системе является Т-функция. Программист может некоторым образом повлиять на процесс распараллеливания, изменяя размер Т-функции, вернее, объем действий, которые она должна совершить во время исполнения. Таким образом, под размером гранулы параллелизма понимается не количество строк исходного кода, которое содержит тело Т-функции, а объем действий, которые она должна совершить во время исполнения. Например, Т-функция может состоять из одного единственного вызова какой-либо С-функции, и тело ее может состоять из одной-двух строк. Но если при этом вызываемая С-функция выполняет большую работу, то размер гранулы параллелизма будет достаточно большим. От выбора гранулы параллелизма зависит эффективность процесса распараллеливания. Очевидно, что при слишком малом размере гранулы могут возникнуть большие накладные расходы на передачу Т-функций другим вычислительным узлам, при этом полезная работа, выполняемая самой функцией на удаленном процессоре, может быть совсем незначительной. С другой стороны, слишком большой размер гранулы может привести к неравномерной загрузке мультипроцессора, когда количество готовых к выполнению Т-процессов оказывается меньше, чем количество процессоров, и часть процессоров простаивает. Таким образом, если при выполнении программы на мультипроцессоре не возникает ожидаемого ускорения, следует вернуться к исходному коду программы, проанализировать его с учетом всего сказанного, и при необходимости изменить структуру программы.
11. Высокоуровневое распараллеливание. Т-система и ее аналоги
Т-Система — средство автоматического динамического распараллеливания программ, призванное облегчить процесс разработки и использования сложных параллельных программ и их эффективное использование на различном, в том числе и неоднородном оборудовании.
OpenTS (Open T-System, Т-система с открытой архитектурой) — это современная реализация Т-системы. Она обеспечивает автоматическое динамическое распараллеливание программ и предоставляет среду исполнения для языка программирования высокого уровня Т++, который является параллельным диалектом языка Си++[3].
OpenTS использует легковесные потоки и быстрым переключением (несколько наносекунд) и может работать с более чем миллионом легковесных потоков на процессор. На основе этих потоков реализован ряд возможностей, таких как мобильные потоки, объекты и ссылки, распределенная сборка мусора, доска объявлений для обмена данными и заданиями, и т. д.
OpenTS была успешно опробована на широком круге задач, и на вычислительных установках различного масштаба: от многопроцессорных PC до вычислительных комплексов с различной архитектурой и разной мощности (различные многопроцессорные Windows/Linux Intel/AMD-кластеры, терафлопная российская установка МВС-1000М, и др.). OpenTS поддерживает широкий спектр параллельных платформ: многоядерные процессоры, SMP-системы, кластеры, метакластеры и GRID-системы.
12. Статическая и динамическая специализация кода
http://www. *****/papers/2008/prep12/prep2008_12.html
Многие современные компиляторы обладают встроенными оптимизаторами. Они преобразуют программу в машинный код, оптимизируя один или несколько показателей, таких как: размер скомпилированной программы, среднее количество исполняемых инструкций, среднее время выполнения программы, объем используемой оперативной памяти и так далее. В результате таких оптимизаций получаем программу, эквивалентную исходной программе, но в некоторых случаях более оптимальную по этим показателям.
Для более эффективной оптимизации необходимо использовать дополнительную информацию о программе или об исполняемой системе. Например, для эффективной компиляции используется информация об инструкциях, поддерживаемых данным процессором. В результате такой компиляции получается программа, которая может быть исполнена только на конкретном процессоре, но более эффективно, чем программа, которая может исполняться на целом семействе процессоров.
Подход к оптимизации программ, основанный на учете дополнительной информации об условиях, в которых будет эксплуатироваться программа, называется специализацией программ. В частности, ограничения на условия эксплуатации могут заключаться в том, что часть исходных данных известна заранее и не меняется от одного запуска программы к другому. Или, в общем случае, ограничения на исходные данные могут быть заданы в виде каких-то условий. В таких случаях принято говорить, что выполняется специализация программы по отношению к ограничениям на исходные данные.
Мы можем рассматривать компиляцию как специализации текста программы для исполнения в определенном программно-аппаратном окружении. В отличие от классических схем реализации компиляции за счет специализации мы здесь используем то обстоятельство, что, зная вычислительную конфигурацию, можно выбрать
наиболее оптимальные параметры, с которыми и скомпилировать вычислительное ядро; также можно предложить согласованную с этими параметрами эффективную стратегию для распределенного счета: на сколько частей дробить задачу, на какие вычислительные узлы в первую очередь посылать подзадачи и так далее. То есть, вполне содержательную часть работы Т-программы можно проделать заранее, зная лишь вычислительную конфигурацию системы.
Динамическую загрузку кода и инициализацию данных можно формально рассматривать как специализацию среды исполнения по вычислительной задаче
http://metacomputation-ru. /2009/06/meta-ru-pe-vs-scp. html
13 Мемоизация (табулирование) результатов вычислений
Мемоизация — специальная оптимизационная методика, которая позволяет увеличить скорость выполнения компьютерных программ. Данная методика заключается в том, чтобы исключить повторное вычисление результатов предыдущих вызовов.
Мемоизация также используется и для других целей (не обязательно связанных с увеличением скорости работы программы). Например, она используется при простом взаимно-рекурсивном нисходящем разборе («парсинге») в общем/обобщённом алгоритме разбора «сверху-вниз».
Несмотря на связь с кешированием, мемоизация является особым видом оптимизации, отличающимся от таких способов кеширования, как буферизация и подмена страниц.
Кэширование - это мемоизация тождественной функции
Чтобы понять улучшается ли скорость работы программы от мемоизации это отпрофилировать ее. Поэтому варианты с простым добавлением/убиранием мемоизации могут помочь при профилировке. Можно предложить следующую стратегию
1. Выберете класс/функцию для мемоизации
2. Отпрофилируйте класс/функцию (и всю систему в целом)
3. Если производительность применимая то идите к пункту 6, иначе добавьте мемоизацию
4. Отпрофилируйте момоизированную функуцию/класс (и всю систему в целом)
5. Если производительность не изменилась или мало изменилась, то уберите мемоизацию
6. повторите если необходимо
http://ru. wikipedia. org/wiki/%D0%9C%D0%B5%D0%BC%D0%BE%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F
14. Частичные вычисления и глубокая специализация (суперкомпиляция) программ
Оптимизация программ на основе использования априорной информации о значении части переменных называется специализацией.
Рассмотрим программу f(x, y) от двух аргументов x и y и значение одного из ее аргументов x=a. Результатом специализации программы f(x, y) по известному аргументу x=a называется новая программа одного аргумента g(y), обладающая следующим свойством: f(a, y)=g(y) для любого y.
Частичные вычисления (Partial Evaluation, PE) — это такой метод специализации, который заключается в получении более эффективного кода на основе использования априорной информации о части аргументов и однократного выполнения той части кода, которая зависит только от известной части аргументов (и не зависит от неизвестной части).
В процессе частичных вычислений операции над известными данными исполняются, а над неизвестными — переносятся в остаточную программу. Остаточная программа зависит только от неизвестной (на стадии специализации) части аргументов и будет исполняться, только когда значения этих аргументов станут известны. Цель частичных вычислений — генерация остаточной программы.
Операции и элементы данных, которые выполняются и используются на этапе генерации остаточной программы, называются статическими, и будут в дальнейшем обозначаться S, а остальные, оставленные в остаточной программе, — динамическими — D.
Метод частичных вычислений основан на разделении операций и других программных конструкций на статические (S) и динамические (D).
|
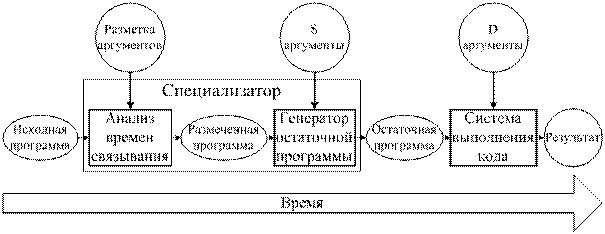
Рис. 1. Общепринятая структура специализатора,
основанного на методе частичных вычислений.
Часть метода специализации, отвечающая за разделение операций и данных, называется анализом времен связывания (Binding Time Analysis, BTA, BT-анализ) (рис. 1). Вторая часть метода специализации, отвечающая за вычисление статической части программы и выделение динамической части в отдельную программу, называется генератором остаточной программы (Residual Program Generator, RPG). В этой части, собственно, и происходят «частичные вычисления».
Суперкомпиляция — специальная техника оптимизации алгоритмов, основанная на знании конкретных входных данных алгоритма. Суперкомпилятор принимает исходный код алгоритма плюс некоторые данные о входных параметрах и возвращает новый исходный код, который исполняет свою задачу на этих данных быстрее или является лучше исходного алгоритма по каким-то другим показателям. Очень часто под суперкомпиляцией неверно понимают глобальную оптимизацию программы, то есть эквивалентные преобразования программы, которые улучшают выбранные показатели исполнения (скорость работы, требуемая память, размер и т. п.), из-за чего технология суперкомпиляции очень мало распространена, а сама идея имеет невысокую оценку в профессиональном сообществе.
Основная идея суперкомпиляции состоит в том, что для любого, даже самого эффективного, общего алгоритма можно построить специальную версию, которая будет работать только для некоторого подмножества входных данных исходного алгоритма, но обладать более высокими показателями, чем исходный алгоритм (те же самые скорость работы, требуемая память, размер и т. п.).
Например, пусть исходный алгоритм — вычисление квадрата числа: square(x) => x * x. Для x = 0 можно получить более короткий и более быстрый вариант алгоритма, который просто возвращает ноль: square(0) => 0.
Равенство аргумента функции константе — только частный и самый простой вариант данных для суперкомпиляции. Другими примерами могут служить четность/нечетность числа, конкретные или четные/нечетные размеры массива, знания о порядке элементов массива или коллекции.
Например, для случая сортировки массива целых чисел можно получить несколько алгоритмов для размеров массива в 0, 1, 2, 3 и т. д. элементов, — результирующие алгоритмы будут работать без циклов, сводиться к нескольким сравнениям и выполняться максимально эффективно.
Процедура суперкомпиляции заключается в следующих шагах:
1. исполнение исходного алгоритма над интересующими данными на некоторой метамашине с запоминанием всех произведенных вычислений;
2. свертка полученного списка вычислений таким образом, чтобы интересующие показатели алгоритма улучшились, а результат вычисления остался верным;
3. обратное преобразование списка вычислений в код нового алгоритма.
Метамашина в данном случае требуется для того, чтобы иметь возможность производить необычные вычисления, в частности вычисления над данными, которые определены только частично. Например известно, что одно из слагаемых четное — тогда результатом «метасложения» будет просто «число», а результатом «метаумножения» — снова «четное число», что может быть использовано далее в оптимизации.
В отличие от классических методов оптимизации, суперкомпиляция может в разы улучшить показатели работы даже простых алгоритмов. Например, для программы консольной игры в крестики-нолики суперкомпилятор может упразднить все массивы и циклы в предположении, что используется игровое поле 3x3, а также все написанные классы и подпрограммы/функции, в результате чего получится одна монолитная функция.
15. В каких областях и для решения каких задач требуются высокопроизводительные вычисления
Все больший объем в высокопроизводительных вычислениях занимает математическое моделирование, когда реальные испытания на физических моделях заменяются расчетами математических моделей. Это возможно только когда физика процесса известна, поэтому математическое моделирование часто используется при расчетах конструкций (проверка зданий на сейсмостойкость, выбор формы кузова автомобиля или планера самолета, краш-тесты автомобилей).
Высокопроизводительные вычисления активно используются в киноиндустрии при создании мультфильмов и прорисовке спецэффектов, без которых невозможно представить себе ни один блокбастер.
Без компьютерного моделирования невозможны прогнозы погоды (один из крупнейших компьютерных центров создан при Росгидромете - 13 место в списке 50 крупнейших центров СНГ).
В СПбГУ наиболее высокопроизводительные вычисления применяются для решения широкого круга вопросов, таких, как определение свойств кристаллов и молекул, расчет ускорителей элементарных частиц, и магнитных головок дисковых накопителей, обработка данных Большого Адронного Коллайдера в ЦЕРНе.
Криптография
http://www. /ru-ru/business/enterprise/industry/oilgas/hpc. aspx
http://www. /editorial/intel_pat_gelsinger_interview_mar2k9.shtml
http://www. apmath. *****/ru/admission/pm_vv. html
16. Определение процесса, назначение. Логическая и физическая параллельность. Диаграмма состояний процесса
Процесс (задача) - программа, находящаяся в режиме выполнения.
С каждым процессом связывается его адресное пространство, из которого он может читать и в которое он может писать данные.
Адресное пространство содержит:
· саму программу
· данные к программе
· стек программы
С каждым процессом связывается набор регистров, например:
· счетчика команд (в процессоре) - регистр в котором содержится адрес следующей, стоящей в очереди на выполнение команды. После того как команда выбрана из памяти, счетчик команд корректируется и указатель переходит к следующей команде.
· указатель стека
· и д. р.
Физическая параллельность: Несколько независимых процессоров (несколько потоков управления) выполняются параллельно.
Логическая параллельность: Видимость физической параллельности достигается использованием одного процессора в режиме разделения времени (программное обеспечение может быть спроектировано в расчете на несколько потоков управления)
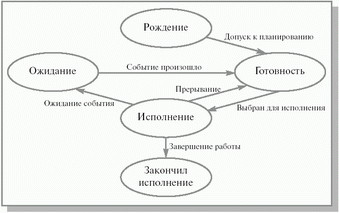
Диаграмма состояний процесса, принятая в курсе
При рождении процесс получает в свое распоряжение адресное пространство, в которое загружается программный код процесса;
ему выделяются стек и системные ресурсы; устанавливается начальное значение программного счетчика этого процесса и т. д. Родившийся процесс переводится в состояние готовность.
Операционная система, пользуясь каким-либо алгоритмом планирования, выбирает один из готовых процессов и переводит его в состояние исполнение. В состоянии исполнение происходит непосредственное выполнение программного кода процесса. Выйти из этого состояния процесс может по трем причинам:
- операционная система прекращает его деятельность; он не может продолжать свою работу, пока не произойдет некоторое событие, и операционная система переводит его в состояние ожидание ; в результате возникновения прерывания в вычислительной системе (например, прерывания от таймера по истечении предусмотренного времени выполнения) его возвращают в состояние готовность.
Из состояния ожидание процесс попадает в состояние готовность после того, как ожидаемое событие произошло, и он снова может быть выбран для исполнения.
При завершении своей деятельности процесс из состояния исполнение попадает в состояние закончил исполнение.
http://www. *****/department/os/osintro/2/2.html
17. Блокировка и реактивация процессов. Процессы и потоки в контексте ОС
Что вы делаете, когда кто-то просит вас о чем-то, а вы не можете сделать это немедленно? Пожалуй единственное, что вы можете ответить: "Пожалуйста, не сейчас, я пока занят.". А что должен делать модуль ядра? У него есть другая возможность. Он можете приостановить работу процесса до тех пор, пока не сможет обслужить его. В конечном итоге, ядро постоянно то приостанавливает, то вновь возобновляет работу процессов. Именно так обеспечивается возможность одновременного исполнения нескольких процессов на единственном процессоре.
Пример ниже демонстрирует такую возможность. Модуль создает файл /proc/sleep, который может быть открыт только одним процессом, в каждый конкретный момент времени. Если файл уже был открыт кем-нибудь, то модуль вызывает wait_event_interruptible. Эта функция изменяет состояние "задачи" (здесь, под термином "задача" понимается структура данных в ядре, которая хранит информацию о процессе), присваивая ему значение TASK_INTERRUPTIBLE, это означает, что задача не будет выполняться до тех пор, пока не будет "разбужена" каким либо образом, и добавляет процесс в очередь ожидания WaitQ, куда помещаются все процессы, желающие открыть файл /proc/sleep. Затем функция передает управление планировщику, который в свою очередь предоставляет возможность поработать другому процессу.
Когда процесс закрывает файл, это приводит к вызову module_close. Она запускает все процессы, которые "сидят" в очереди WaitQ (к сожалению нет механизма, который позволил бы "разбудить" только один процесс). Затем управление возвращается процессу, который только что закрыл файл и он продолжает свою работу. После того, как данный процесс исчерпает свой квант времени, планировщик передаст управление другому процессу. Таким образом, один из процессов, ожидавших своей очереди доступа к файлу, в конечном итоге получит управление и продолжит исполнение с точки, следующей за вызовом wait_event_interruptible. [11] Он установит глобальную переменную, извещающую остальные процессы о том, что файл открыт и займется обработкой открытого файла. Когда другие процессы получат свой квант времени, они обнаружат, что файл все еще открыт и опять приостановят свою работу.
Чтобы как-то оживить повествование замечу, что module_close не обладает монопольным правом на возобновление работы ожидающих процессов. Сигнал Ctrl-C (SIGINT) также может "разбудить" процесс. [12] В этом случае процессу немедленно возвращается -EINTR. Таким образом пользователи могут, например, прервать процесс прежде, чем он получит доступ к файлу.
Тут есть еще один момент, о котором хотелось бы упомянуть. Некоторые процессы не желают быть заблокированными, такие процессы должны либо получить в свое распоряжение открытый файл немедленно, либо извещение о том, что их запрос не может быть удовлетворен в настоящий момент. Такие процессы используют флаг O_NONBLOCK при открытии файла. Если ядро не в состоянии немедленно удовлетворить запрос, оно отвечает кодом ошибки -EAGAIN.
Потоки и процессы — это связанные понятия в вычислительной технике. Оба представляют из себя последовательность инструкций, которые должны выполняться в определенном порядке. Инструкции в отдельных потоках или процессах, однако, могут выполняться параллельно.
Процессы существуют в операционной системе и соответствуют тому, что пользователи видят как программы или приложения. Поток, с другой стороны, существует внутри процесса. По этой причине потоки иногда называются "облегченные процессы". Каждый процесс состоит из одного или более потоков.
Существование нескольких процессов позволяет компьютеру "одновременно" выполнять несколько задач. Существование нескольких потоков позволяет процессу разделять работу для параллельного выполнения. На многопроцессорном компьютере процессы или потоки могут работать на разных процессорах. Это позволяет выполнять реально параллельную работу.
Абсолютно параллельная обработка не всегда возможна. Потоки иногда должны синхронизироваться. Один поток может ожидать результата другого потока, или одному потоку может понадобиться монопольный доступ к ресурсу, который используется другим потоком. Проблемы синхронизации являются распространенной причиной ошибок в многопоточных приложениях. Иногда поток может закончиться, ожидая ресурс, который никогда не будет доступен. Это кончается состоянием, которое называется взаимоблокировка.
http://education. *****/view. php? olif=gl4#33
18. Способы обмена данными между процессами. Общая память. Сообщения.
Межпроцессное взаимодействие (англ. Inter-Process Communication, IPC) — набор способов обмена данными между множеством потоков в одном или более процессах. Процессы могут быть запущены на одном или более компьютерах, связанных между собой сетью. IPC-способы делятся на методы обмена сообщениями, синхронизации, разделяемой памяти и удаленных вызовов(RPC). Методы IPC зависят от пропускной способности и задержки взаимодействия между потоками и типа передаваемых данных.
Разделяемую память (англ. Shared memory) применяют для того, чтобы увеличить скорость прохождения данных между процессами. В обычной ситуации обмен информацией между процессами проходит через ядро. Техника разделяемой памяти позволяет осуществить обмен информацией не через ядро, а используя некоторую часть виртуального адресного пространства, куда помещаются и откуда считываются данные.
После создания разделяемого сегмента памяти любой из пользовательских процессов может подсоединить его к своему собственному виртуальному пространству и работать с ним, как с обычным сегментом памяти. Недостатком такого обмена информацией является отсутствие каких бы то ни было средств синхронизации, однако для преодоления этого недостатка можно использовать технику семафоров.
Примерный сценарий использования разделяемой памяти при реализации технологий «клиент—сервер» имеет вид:
1. сервер получает доступ к разделяемой памяти, используя семафор;
2. сервер производит запись данных в разделяемую память;
3. после завершения записи данных сервер освобождает доступ к разделяемой памяти с помощью семафора;
4. клиент получает доступ к разделяемой памяти, запирая доступ к этой памяти для других процессов с помощью семафора;
5. клиент производит чтение данных из разделяемой памяти, а затем освобождает доступ к памяти с помощью семафора.
Для работы с разделяемой памятью используются системные вызовы:
§ shmget — создание сегмента разделяемой памяти;
§ shmctl — установка параметров;
§ shmat — подсоединение сегмента памяти;
§ shmdt — отсоединение сегмента.
В схеме обмена данными между двумя процессами — (клиентом и сервером), использующими разделяемую память, — должна функционировать группа из двух семафоров. Первый семафор служит для блокирования доступа к разделяемой памяти, его разрешающий сигнал — 1, а запрещающий — 0. Второй семафор служит для сигнализации сервера о том, что клиент начал работу, при этом доступ к разделяемой памяти блокируется, и клиент читает данные из памяти. Теперь при вызове операции сервером его работа будет приостановлена до освобождения памяти клиентом.
Так как очереди сообщений входят в состав средств System V IPC, для них верно все, что говорилось ранее об этих средствах в целом и уже знакомо нам. Очереди сообщений, как и семафоры, и разделяемая память, являются средством связи с непрямой адресацией, требуют инициализации для организации взаимодействия процессов и специальных действий для освобождения системных ресурсов по окончании взаимодействия.
Очереди сообщений располагаются в адресном пространстве ядра операционной системы в виде однонаправленных списков и имеют ограничение по объему информации, хранящейся в каждой очереди. Каждый элемент списка представляет собой отдельное сообщение. Сообщения имеют атрибут, называемый типом сообщения. Выборка сообщений из очереди (выполнение примитива receive) может осуществляться тремя способами:
В порядке FIFO, независимо от типа сообщения. В порядке FIFO для сообщений конкретного типа. Первым выбирается сообщение с минимальным типом, не превышающим некоторого заданного значения, пришедшее раньше других сообщений с тем же типом.Реализация примитивов send и receive обеспечивает скрытое от пользователя взаимоисключение во время помещения сообщения в очередь или его получения из очереди. Также она обеспечивает блокировку процесса при попытке выполнить примитив receive над пустой очередью или очередью, в которой отсутствуют сообщения запрошенного типа, или при попытке выполнить примитив send для очереди, в которой нет свободного места.
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. Разработан Уильямом Гроуппом, Эвином Ласком (англ.) и другими.
MPI является наиболее распространённым стандартом интерфейса обмена данными в параллельном программировании, существуют его реализации для большого числа компьютерных платформ. Используется при разработке программ для кластеров и суперкомпьютеров. Основным средством коммуникации между процессами в MPI является передача сообщений друг другу. Стандартизацией MPI занимается MPI Forum. В стандарте MPI описан интерфейс передачи сообщений, который должен поддерживаться как на платформе, так и в приложениях пользователя. В настоящее время существует большое количество бесплатных и коммерческих реализаций MPI. Существуют реализации для языков Фортран 77/90, Си и Си++.
В первую очередь MPI ориентирован на системы с распределенной памятью, то есть когда затраты на передачу данных велики, в то время как OpenMP ориентирован на системы с общей памятью (многоядерные с общим кэшем). Обе технологии могут использоваться совместно, дабы оптимально использовать в кластере многоядерные системы.
http://articles. *****/cn/showdetail. php? cid=7252
http://www. *****/docs/RUS/os_unix/glava_23.html
19. Синхронизация процессов
Существует достаточно обширный класс средств операционной системы, с помощью которых обеспечивается взаимная синхронизация процессов и потоков. Потребность в синхронизации потоков возникает только в мультипрограммной операционной системе и связана с совместным использованием аппаратных и информационных ресурс об вычислительной системы. Синхронизация необходима для исключения гонок и тупиков при обмене данными между потоками, разделении данных, при доступе к процессору и устройствам ввода-вывода. В данном разделе мы будем говорить о синхронизации потоков, имея в виду, что если операционная система не поддерживает потоки, то все сказанное относится к синхронизации процессов. Во многих операционных системах эти средства называются средствами межпроцессного взаимодействия — Inter Process Communications (IPC), что отражает историческую первичность понятия «процесс» по отношению к понятию «поток». Обычно к средствам IPC относят не только средства межпроцессной синхронизации, но и средства межпроцессного обмена данными. Выполнение потока в мультипрограммной среде всегда имеет асинхронный характер. Очень сложно с полной определенностью сказать, на каком этапе выполнения будет находиться процесс в определенный момент времени. Даже в однопрограммном режиме не всегда можно точно оценить время выполнения задачи. Это время во многих случаях существенно зависит от значения исходных данных, которые влияют на количество циклов, направления разветвления программы, время выполнения операций ввода-вывода и т. п. Так как исходные данные в разные моменты запуска задачи могут быть разными, то и время выполнения отдельных этапов и задачи в целом является весьма неопределенной величиной. Еще более неопределенным является время выполнения программы в мультипрограммной системе. Моменты прерывания потоков, время нахождения их в очередях к разделяемым ресурсам, порядок выбора потоков для выполнения — все эти события являются результатом стечения многих обстоятельств и могут быть интерпретированы как случайные. В лучшем случае можно оценить вероятностные характеристики вычислительного процесса, например вероятность его завершения за данный период времени. Таким образом, потоки в общем случае (когда программист не предпринял специальных мер по их синхронизации) протекают независимо, асинхронно друг другу. Это справедливо как по отношению к потокам одного процесса, выполняющим общий программный код, так и по отношению к потокам разных процессов, каждый из которых выполняет собственную программу. Любое взаимодействие процессов или потоков связано с их синхронизацией, которая заключается в согласовании их скоростей путем приостановки потока до наступления некоторого события и последующей его активизации при наступлении этого события. Синхронизация лежит в основе любого взаимодействия потоков, связано ли это взаимодействие с разделением ресурсов или с обменом данными. Например, поток-получатель должен обращаться за данными только после того, как они помещены в буфер потоком-отправителем. Если же поток-получатель обратился к данным до момента их поступления в буфер, то он должен быть приостановлен. При совместном использовании аппаратных ресурсов синхронизация также совершенно необходима. Когда, например, активному потоку требуется доступ к последовательному порту, а с этим портом в монопольном режиме работает другой поток, находящийся в данный момент в состоянии ожидания, то ОС приостанавливает активный поток и не активизирует его до тех пор, пока нужный ему порт не освободится. Часто нужна также синхронизация с событиями, внешними по отношению к вычислительной системе, например реакции на зажатие комбинации клавиш Ctrl+C. Ежесекундно в системе происходят сотни событий, связанных с распределением и освобождением ресурсов, и ОС должна иметь надежные и производительные средства, которые бы позволяли ей синхронизировать потоки с происходящими в системе событиями. Для синхронизации потоков прикладных программ программист может использовать как собственные средства и приемы синхронизации, так и средства операционной системы. Например, два потока одного прикладного процесса могут координировать свою работу с помощью доступной для них обоих глобальной логической переменной, которая устанавливается в единицу при осуществлении некоторого события, например выработки одним потоком данных, нужных для продолжения работы другого. Однако во многих случаях более эффективными или даже единственно возможными являются средства синхронизации, предоставляемые операционной системой в форме системных вызовов. Так, потоки, принадлежащие разным процессам, не имеют возможности вмешиваться каким-либо образом в работу друг друга. Без посредничества операционной системы они не могут приостановить друг друга или оповестить о произошедшем событии. Средства синхронизации используются операционной системой не только для синхронизации прикладных процессов, но и для ее внутренних нужд. Обычно разработчики операционных систем предоставляют в распоряжение прикладных и системных программистов широкий спектр средств синхронизации. Эти средства могут образовывать иерархию, когда на основе более простых средств строятся более сложные, а также быть функционально специализированными, например средства для синхронизации потоков одного процесса, средства для синхронизации потоков разных процессов при обмене данными и т. д. Часто функциональные возможности разных системных вызовов синхронизации перекрываются, так что для решения одной задачи программист может воспользоваться несколькими вызовами в зависимости от своих личных предпочтений

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
