
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Ежегодный конкурс HPC Challenge Award Competition проходящий на конференции Supercomputing использует 4 наиболее сложных теста из данного пакета:
Глобальный HPL (Highly parallel Linpack, решение плотной СЛАУ методом LUP-разложения), он же используется для составления списка Top500суперкомпьютеров мира
Global RandomAccess — тест на скорость случайного доступа в память
EP STREAM (Triad) запущенный одновременно на всей системе — тест на суммарную пропускную способность в векторной операции a(i) = b(i) + q*c(i), тип данных double (64 bit), q-константа [3]
Global FFT — тест БПФ
Существует 2 типа наград:
Класс 1: Наивысший результат (производительность) на базовом или оптимизированном запуске, присланный на сайт HPC Challenge.
Класс 2: Наиболее «элегантная» реализация четырех или более тестов из пакета HPC Challenge[4].
33. Анализ производительности программного обеспечения путем изучения машинного кода
Один из главных принципов оптимизации, который можно повторять раз за разом – профилирование кода. При отсутствии профилирования программисты часто делают два типа ошибок. Во-первых, они оптимизируют не тот код. Большая часть программы не является критичной в отношении скорости выполнения, и оптимизация таких участков – пустая трата времени. Определять, какие участки являются критичными интуитивно не самый лучший подход – вы сможете обнаружить их только посредством прямых измерений (использования памяти и скорости выполнения). И, во-вторых, программисты иногда производят оптимизацию, которая наоборот замедляет скорость выполнения. Эта проблема очень актуальна в отношении к C++, где простая строка кода может сгенерировать невероятно большой машинный код. Поэтому программисту следует как можно чаще изучать машинный код, генерируемый компилятором и профилировать свои программы.
Для изучения машинного кода можно применить objdump - программу для отображения различной информации об объектных файлах . Например, она может быть использован в качестве дизассемблера , чтобы посмотреть исполняемый в сборке формы. Она является частью GNU Binutils для точного контроля над исполняемыми и другими бинарными файлами.
Чтобы дизассемблировать фаил нужно
objdump - Dslx file
Многие приемы оптимизации программ на языке ассемблера не являются общими и не применимы для любого процессора, однако приемы оптимизации необходимо изучить для того, чтобы на конкретно взятом процессоре попробовать улучшить быстродействие или качество вашей программы. Общие рекомендации:
Используйте по возможности самый современный компилятор, позволяющий максимально учесть особенности архитектуры.
Минимизируйте количество используемых глобальных переменных и запутанное управление выполнением.
Где возможно, используйте const модификатор, избегайте register (компилятор сам сообразит, что можно заменить регистрами)
Избегайте косвенных вызовов.
Улучшайте предсказуемость ветвлений..
Используйте, где это уместно, SIMD расширения архитектуры.
Избегайте задержек при использовании части регистра (при последующем обращении к полному регистру).
Применяйте правильное выравнивание данных.
Переставляйте инструкции в коде так, чтобы минимизировать промахи в кэше, и оптимизируйте предвыборку в кэш.
Избегайте чтения малого количества данных после записи большого количества данных и наоборот.
Избегайте самомодифицирующегося кода (для Windows XP).
Избегайте располагать данные в сегменте кода.
Вычисляйте адрес для записи на возможно более ранней стадии.
Избегайте инструкций, требующих для выполнения более четырех
микроопераций и инструкций, код которых длиннее чем 7 байт.
Старайтесь повышать параллелизм выполнения кода.
34. Структура ассемблерного кода, полученного компиляцией типичной программы на языке "C". Указатель стека и указатель инструкций
Для начала напишите небольшую программу на языке C, которая выводит на экран сообщение hello world и скомпилируйте ее с ключом - S. В результате вы получите файл с ассемблерным кодом, соответствующим исходной программе. По-умолчанию GCC создает файл с ассемблерным кодом с тем же именем, что и исходный файл, заменяя расширение `.c' на `.s’
C
#include <stdio. h>
int main() {
puts("Hello world");
return 0;
}
Assembler
.file "hw. c"
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "Hello world\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
pushl %ebp
movl %esp, %ebp
subl $8, %esp
andl $-16, %esp
movl $0, %eax
addl $15, %eax
addl $15, %eax
shrl $4, %eax
sall $4, %eax
movl %eax, -4(%ebp)
movl -4(%ebp), %eax
call __alloca
call ___main
movl $LC0, (%esp)
call _puts
movl $0, %eax
leave
ret
.def _puts; .scl 2; .type 32; .endef
Стек необходим для запоминания адресов возврата из процедур обработки прерывания и подпрограмм. Его также можно использовать для временного хранения данных. Регистр указателя стека (SP) постоянно указывает на вершину стека. Он реализован в виде двух 8-битных регистров, доступных в пространстве памяти ввода-вывода. Данные помещаются в стек и извлекаются из него посредством инструкций PUSH и POP. Увеличение стека происходит в направлении от старших ячеек памяти к младшим. Таким образом, при помещении данных в стек содержимое регистра SP уменьшается, а при извлечении данных - увеличивается. После сброса, SP автоматически инициализируется значением, которое равно максимальному адресу внутреннего SRAM. При необходимости изменения SP нужно учитывать, что помещаемый в него адрес должен лежать выше 0x2000, а само изменение нужно выполнить перед вызовом каких-либо подпрограмм или разрешением прерываний. При вызове подпрограмм или при переходе по вектору прерываний адрес возврата автоматически помещается в стек. Адрес возврата может быть представлен двумя или тремя байтами, что зависит от размера памяти микроконтроллера. У МК с памятью программ 128 кбайт и менее адрес возврата двухбайтный, поэтому, указатель стека декрементируется/инкрементируется на два. У тех же микроконтроллеров, которые оснащены памятью программ размером более 128 кбайт, адрес возврата трехбайтный, а декрементирование/инкрементирование SP выполняется на три. Адрес возврата извлекается из стека при выходе из прерывания по инструкции RETI, а из подпрограммы по инструкции RET. Если инструкцией PUSH в стек помещаются данные, то SP декрементируется на единицу. Аналогичным образом, при извлечении данных из стека инструкцией POP содержимое SP инкрементируется на единицу. Чтобы предотвратить сбой в выполнении программы при программном обновлении указателя стека, операция записи в SPL приводит к автоматическому отключению прерываний на время выполнения
до четырех инструкций или до следующей операции записи в память ввода-вывода.
Указатель инструкций (регистр IP) всегда содержит смещение в памяти, по которому хранится следующая выполняемая инструкция. Когда выполняется одна инструкция, указатель инструкций перемещается таким образом, чтобы указывать на адрес памяти, где хранится следующая инструкция. Обычно следующей выполняемой инструкцией является инструкция, хранимая по следующему адресу памяти, но некоторые инструкции, такие, как вызовы или переходы, могут привести к тому, что в указатель инструкций будет загружено новое значение. Таким образом, будет выполнен переход на другой участок программы. Значение счетчика инструкций нельзя прочитать или записать непосредственно. Загрузить в указатель инструкций новое значение может только специальная инструкция перехода (аналогичная только что описанным). Указатель инструкций сам по себе не определяет адрес, по которому находится следующая выполняемая инструкция. Картину здесь опять усложняет сегментная организация памяти процессора 8086. Для извлечения инструкции предусмотрен регистр CS, где хранится базовый адрес, при этом указатель инструкций задает смещение относительно этого базового адреса
35. Эффективное использование кэш-памяти. Поддержка кэш-памяти на уровне ядра современных ОС (на примере ОС Linux). Инструкция prefetch
Кэш—промежуточный буфер с быстрым доступом, содержащий копию той информации, которая хранится в памяти с менее быстрым доступом, но с наибольшей вероятностью может быть оттуда запрошена. Доступ к данным в кэше идёт быстрее, чем выборка исходных данных из медленной памяти или их перевычисление, за счёт чего уменьшается среднее время доступа.
Кэш центрального процессора разделён на несколько уровней. Для универсальных процессоров — до 3. Кэш-память уровня N+1 как правило больше по размеру и медленнее по скорости обращения и передаче данных, чем кэш-память уровня N.
Самой быстрой памятью является кэш первого уровня — L1-cache. По сути, она является
неотъемлемой частью процессора, поскольку расположена на одном с ним кристалле и входит в состав функциональных блоков. Состоит из кэша команд и кэша данных. L1 кэш работает на частоте процессора, и, в общем случае, обращение к нему может производиться каждый такт. Латентность доступа обычно равна 2—4 тактам ядра. Объём обычно невелик — не более 128 Кбайт. Вторым по быстродействию является L2-cache — кэш второго уровня. Обычно он расположен либо на кристалле, как и L1, либо в непосредственной близости от ядра, например, в процессорном картридже (только в слотовых процессорах). Объём L2 кэша — от 128 Кбайт до 12 Мбайт.
Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра. Кэш третьего уровня наименее быстродействующий и обычно расположен отдельно от ядра ЦП, но он может быть очень внушительного размера — более 32 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно значительно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании.
Если цикл развернуть, то вроде бы будет экономнее, но повышается объем кода. И если весь внешний цикл не попадает в кэш, то это катастрофа. Все внутренние циклы программ должны попадать в кэш. Иначе производительность упадет.
Если надо обрабатывать данные, то надо их резать. И обрабатывать по кусочкам, чтобы они умещались в КЭШе. Пусть он весит несколько десятков кб и по нему бегать и обрабатывать. А потом переходить к следующему. Аналогично для 2 уровня памяти и т. д.
Гиперлинейное ускорение (для программ на распараллеливание) – дали каждому процессу по кусочку. И на каждый кусочек попал кэш. Ведь каждый узел обрабатывает меньше данных. Учитывая размер КЭШей, можно строить алгоритм и менять его параметры, и подстраивать под определенную архитектуру.
Макрос L1_CACHE_BYTES возвращает размер строки кэша в байтах. Чтобы оптимизировать процент попаданий в кэш, ядро принимает во внимание архитектуру и принимает следующие решения:
- наиболее часто используемые поля структуры данных располагаются внутри этой структуры с меньшими смещениями, чтобы они могли быть кэшированы в одной строке;
- при выделении большого количества структур ядро старается сохранить каждую структуру в памяти так, чтобы все строки кэша заполнялись равномерно.
Синхронизация кэшей выполняется микропроцессорами 80×86 автоматически, и поэтому для этих процессоров ядро Linux не выполняет сброс аппаратных кэшей. Однако оно все-таки предоставляет интерфейс для сброса кэшей процессорам, не синхронизирующим кэши.
Инструкция prefetch. Предвыборка (упреждающая выборка) команд. Выборка в специальный буфер процессора нескольких очередных команд во время выполнения текущей команды. Это минимизирует время ожидания процессором поступления следующей команды, кроме того, поскольку все современные процессоры обладают конвейерной архитектурой, то выбранные команды декодируются и исполняются на разных ступенях конвейера. Упреждающая выборка тесно связана с блоком предсказаний ветвлений программы.
36. Принципы повышения производительности подсистемы виртуальной памяти. Поддержка TLB на уровне ядра ОС Linux
В случае когда управление памятью ведется несвязанным фрагментами речь идет об управлении виртуальной памяти. При этом с точки зрения пользовательского процесса вся выделенная ему память непрерывна. На самом же деле она может быть разделена на несколько несвязанных друг с другом фрагментов, а адреса по которым обращается процесс не является физическим адресами в памяти и преобразуется в физический с помощью специальных алгоритмов. В данном случае адреса по которому обращается процесс называется виртуальными, а архитектура на которой это реализуется должна быть снабжена соответствующим аппаратным механизмом реализующим данное.
Возвращаясь к использованию кэш-памяти в структуре иерархии памяти компьютерной системы можно попробовать встроить кэш в механизм виртуальной памяти, как показано на Рис. 20.
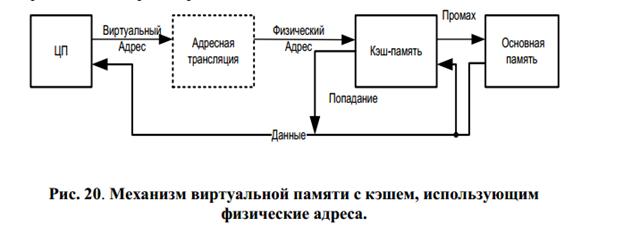
Здесь данные кэша являются подмножеством данных в физической памяти и для доступа к ним необходимо использовать физический адрес. И здесь возникает проблема с быстродействием адресной трансляции. Так как таблица страниц находится в основной памяти, то преимущества использования кэш-памяти для данных и команд полностью исчезают по причине необходимости доступа к основной памяти для получения физического адреса страницы.
Выходом из такой ситуации является введение в структуру еще одного специализированного кэша, в котором будут храниться недавно использованные элементы таблицы страниц, при повторном обрашении к этим страницам доступ к таблице страниц в основной памяти не производится и физический адрес считывается из этого кэша. При этом задержка доступа к такому кэшу многократно меньше задержки доступа к основной памяти. Ввиду специализированности кэша для хранения только элементов таблицы страниц, его принято называть буфером быстрой трансляции (Translation Look-aside Buffer, TLB). Структура механизма виртуальной памяти с буфером быстрой трансляции (далее ББТ) представлена на Рис. 21.
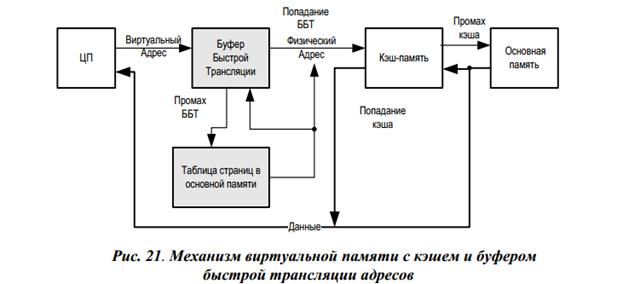
ББТ, как правило, имеет небольшие размеры в пределах от 64 до 256 строк и характеризуется высокой степенью ассоциативности, часто ББТ выполняются как полно-ассоциативные буферы. Каждая строка ББТ содержит виртуальный номер страницы для поиска, физический номер страницы и биты прав доступа из таблицы страниц в основной памяти.
В связи с высокой локальностью обращений к памяти, использование ББТ уменьшает негативное влияние механизма ВП на среднее время доступа в иерархии памяти. Тем не менее, требуются некоторые дополнительные меры для уменьшения времени трансляции и ее совмещения с доступом в кэш данных. Можно перечислить следующие стандартные способы:
ЦП с механизмом ВП и ББТ должны генерировать адрес как можно раньше момента чтения (записи) данных для уменьшения числа тактов задержки при доступе в кэш-память,
Доступ в кэш должен быть по возможности совмещен с доступом в ББТ и это возможно в связи с тем что биты смещения в странице (младшие биты адреса) могут быть использованы в качестве индекса для доступа к кэшу.
Однако это порождает некоторые проблемы, связанные с перекрытием поля индекса кэша и физического адреса. Это приводит к тому, что старшие биты индекса кэша должны быть получены из физического адреса в результате адресной трансляции, и совмещение процесса доступа к ББТ и кэшу становится невозможным. Поэтому это принуждает к использованию в комплексе с механизмом ВП кэшей прямого отображения небольшого объема или кэшей с высокой степенью ассоциативности, если мы хотим увеличить объем кэша.
Процессоры не могут автоматически синхронизировать свои TLB-кэши, потому что ядро, а не аппаратная часть принимает решение о дальнейшей корректности отображения между линейным адресом и физическим.
В Linux 2.6 имеется несколько методов сброса TLB-буферов, которые следует применять аккуратно, в зависимости от вида изменения таблицы страниц.
Несмотря на богатый выбор методов TLB-буфера, предлагаемых типичным ядром Linux, каждый микропроцессор обычно имеет куда более ограниченный набор ассемблерных инструкций для сброса TLB-буферов. В этом смысле одной из самых гибких платформ является UltraSPARC фирмы Sun. В противоположность ей, микропроцессоры Intel предлагают только два способа объявления содержимого TLB-буферов недействительными:
- все модели Pentium автоматически сбрасывают записи TLB-буферов, относящиеся к неглобальным страницам, когда в регистр загружается какое-либо значение;
- в Pentium Pro и более поздних моделях ассемблерная инструкция invipg делает недействительной одну запись TLB-буфера, отображающую заданный линейный адрес.
Макросы операционной системы Linux эксплуатируют данные аппаратные методы. Эти макросы являются основными составляющими архитектурно-независимых методов.
Обратите внимание, что отсутствует метод fiush tib pgtabies. Дело в том, что в архитектуре 80×86 ничего не нужно предпринимать, когда таблица страниц отсоединяется от таблицы-родителя, и поэтому функция, реализующая этот метод, пуста.
Архитектурно-независимые методы объявления TLB-буферов недействительными довольно просто расширяются на многопроцессорные системы. Функция, выполняющаяся на некотором процессоре, посылает другим процессорам межпроцессорное прерывание, которое заставляет их выполнить соответствующую функцию сброса TLB-буфера.
Вообще говоря, любое переключение процессов подразумевает смену набора активных таблиц страниц. Записи локальных TLB-буферов, имеющие отношение к старым таблицам страниц, должны быть сброшены. Это делается автоматически, когда ядро пишет адрес нового глобального каталога страниц в управляющий регистр. Однако ядро успешно избегает сброса TLB-буферов в следующих случаях:
- при переключении между обычными процессами, использующими один набор таблиц страниц;
- при переключении между обычным процессом и потоком ядра. Потоки ядра не имеют собственного набора таблиц страниц. Вместо этого они пользуются таблицами страниц, принадлежащими обычному процессу, который был последним запланирован на выполнение.
Чтобы избежать ненужного сбрасывания TLB-буферов в многопроцессорных системах, ядро прибегает к приему, называемому «ленивым» режимом TLB. В его основе лежит следующая идея: если несколько процессоров используют одни и те же таблицы страниц, и некая запись в TLB-буфере должна быть сброшена у всех процессоров, то сброс в некоторых ситуациях может быть отложен для процессоров, выполняющих потоки ядра.
TLB-буфера, которая ссылается на линейный адрес режима пользователя, потому что никакой поток ядра не обращается к адресному пространству режима пользователя.
Когда какой-нибудь процессор начинает выполнять поток ядра, ядро переводит его в «ленивый» режим TLB. Когда поступают запросы на очистку некоторых записей TLB-буфера, процессор в «ленивом» режиме TLB не сбрасывает эти записи, а запоминает, что его текущий процесс использует набор таблиц страниц, у которых записи TLB-буфера для адресов режима пользователя некорректны. Как только процессор в «ленивом» режиме TLB переключается на обычный процесс с другим набором таблиц страниц, аппаратная часть автоматически сбрасывает записи TLB-буфера, а ядро выводит процессор из «ленивого» режима TLB. Если же процессор в «ленивом» режиме TLB переключается на обычный процесс с тем же набором таблиц страниц, что у потока ядра, работавшего до него, то отложенный сброс TLB-буфера должен быть выполнен ядром. Такой «запоздалый» сброс достигается сбросом всех неглобальных записей TLB-буфера данного процессора.
Для реализации «ленивого» режима TLB требуются дополнительные структуры данных. Переменная cpu tibstate представляет собой статический массив из nr cpus структур (значением этого макроса по умолчанию является 32; он определяет максимальное количество процессоров в системе), состоящих из поля activejnm, указывающего на дескриптор памяти текущего процесса, и из флага state, принимающего значение tlbstate ok («неленивый» режим TLB) или tlbstate lazy («ленивый» режим TLB). Кроме того, каждый дескриптор памяти включает в себя поле cpu vm mask, хранящее индексы процессоров, которым следует принять межпроцессорные прерывания, относящиеся к сбросу TLB-буферов.
Когда процессор начинает выполнять поток ядра, ядро записывает в поле state его элемента cpu_tibstate значение tlbstate_lazy. Кроме того, поле cpu vm mask активного дескриптора памяти хранит индексы всех процессоров в системе, включая индекс того, который перешел в «ленивый» режим TLB. Если другой процессор захочет объявить недействительными записи TLB-буферов у всех процессоров, работающих с данным набором таблиц страниц, он доставит межпроцессорное прерывание всем процессорам, индексы которых содержатся в поле cpu vm mask соответствующего дескриптора памяти.
Когда процессор получает межпроцессорное прерывание, имеющее отношение к сбросу TLB-буфера, и убеждается, что оно затрагивает набор таблиц страниц его текущего процесса, он проверяет поле state элемента cpu tibstate на равенство значению tlbstate lazy. В этом случае ядро отказывается сбросить записи TLB-буфера и удаляет индекс процессора из поля cpu vm mask дескриптора процесса. Последствия этих действий таковы:
- пока процессор остается в «ленивом» режиме TLB, он не получает другие межпроцессорные прерывания, относящиеся к сбросу TLB-буфера;
- если процессор переключается на другой процесс, который пользуется тем же набором таблиц страниц, что и замещаемый поток ядра, то ядро вызывает функцию fiush tibo, чтобы сбросить неглобальные записи TLB-буфера этого процессора.
37. Многозадачность как один из фундаментальных принципов повышения интегральной производительности сложных программных комплексов
Многозада́чность (англ. multitasking) — свойство операционной системы или среды программирования, обеспечивать возможность параллельной (или псевдопараллельной) обработки нескольких процессов. Истинная многозадачность операционной системы возможна только в распределенных вычислительных системах.
Примитивные многозадачные среды обеспечивают чистое ≪разделение ресурсов≫, когда за каждой задачей закрепляется определённый участок памяти, и задача активизируется в строго определённые интервалы времени.
Более развитые многозадачные системы проводят распределение ресурсов динамически, когда задача стартует в памяти или покидает память в зависимости от её приоритета и от стратегии системы. Такая многозадачная среда обладает следующими особенностями:
· Каждая задача имеет свой приоритет, в соответствии с которым получает процессорное время и память
· Система организует очереди задач так, чтобы все задачи получили ресурсы, в зависимости от приоритетов и стратегии системы
· Система организует обработку прерываний, по которым задачи могут активироваться,
деактивироваться и удаляться
· По окончании положенного кванта времени ядро временно переводит задачу из состояния выполнения в состояние готовности, отдавая ресурсы другим задачам. При нехватке памяти страницы невыполняющихся задач могут быть вытеснены на диск (своппинг), а потом через определённое системой время, восстанавливаться в памяти
· Система обеспечивает защиту адресного пространства задачи от несанкционированного
вмешательства других задач
· Система обеспечивает защиту адресного пространства своего ядра от несанкционированного вмешательства задач
· Система распознаёт сбои и зависания отдельных задач и прекращает их
· Система решает конфликты доступа к ресурсам и устройствам, не допуская тупиковых
ситуаций общего зависания от ожидания заблокированных ресурсов
· Система гарантирует каждой задаче, что рано или поздно она будет активирована
· Система обрабатывает запросы реального времени
· Система обеспечивает коммуникацию между процессами
Пример—одна прога что-то пишет в поток, а другая из него считывает. Сокеты.
38. Принципы работы планировщика и быстрое переключение контекста процессов и нитей.
Планирование выполнения задач является одной из ключевых концепций в многозадачности и многопроцессорности как в операционных системах общего назначения, так и в операционных системах реального времени. Планирование заключается в назначении приоритетов процессам в очереди с приоритетами. Программный код, выполняющий эту задачу, называется планировщиком.
Планировщик делит время на эпохи. Эпоха - период времени, за которое каждая задача может использовать своё процессорное время. В начале наступления новой эпохи для каждой задачи планировщик подсчитывает сколько времени она может выполнятся O(n) итераций.
Каждой задачи присваивается базовое значение в течении которого она может использовать ЦПУ. Это значение определяется пользователем с помощью утилиты nice. Установленное значение масштабируется в некое количество тактов микропроцессора. Значение 0 примерно масштабируется в 200 мили секунд.
Когда происходит подсчёт сколько процессорного времени выделить для задачи, это базовое значение может изменится в зависимости является ли задача В/В. Каждая задача имеет переменную counter. Эта переменная содержит количество оставшихся тактов микропроцессора. За всю эпоху, задача могла не использовать все выделенное ей процессорное время, т. е. значение переменной counter > 0. Это могло произойти например если задача спала находилась в ожидании операции В/В. Тогда в конце эпохи задаче будет выделено больше процессорного времени.
Когда задача порождает потомка, то, процессорное время родителя разделяется с потомком, что предотвращает захват ЦПУ размножением.
Эпоха может закончиться:
если ни один процесс не готов
если они выработали всё своё время
Самой важной целью планирования задач является наиболее полная загрузка процессора.
Производительность — количество процессов, которые завершают выполнение за единицу времени. Время ожидания — время, которое процесс ожидает в очереди готовности. Время отклика — время, которое проходит от начала запроса до первого ответа на запрос.
Каждый поток, как и каждый процесс, имеет свой контекст. Контекст — это структура, в которой сохраняются следующие элементы:
· Регистры процессора.
· Указатель на стек потока/процесса.
Также следует отметить, что в случае выполнения системного вызова потоком и перехода из режима пользователя, в режим ядра, происходит смена стека потока на стек ядра. При переключении выполнения потока одного процесса, на поток другого, ОС обновляет некоторые регистры процессора, которые ответственны за механизмы виртуальной памяти (например CR3), так как разные процессы имеют разное виртуальное адресное пространство.
Контекст процесса включает в себя содержимое адресного пространства задачи, выделенного процессу, а также содержимое относящихся к процессу аппаратных регистров и структур данных ядра. С формальной точки зрения, контекст процесса объединяет в себе пользовательский контекст, регистровый контекст и системный контекст. Пользовательский контекст состоит из команд и данных процесса, стека задачи и содержимого совместно используемого пространства памяти в виртуальных адресах процесса. Те части виртуального адресного пространства процесса, которые периодически отсутствуют в оперативной памяти вследствие выгрузки или замещения страниц, также включаются в пользовательский контекст.
Переменные регистры микропроцессора, стеки и локальные области памяти называются контекстом потока.
Переключение контекстов процессов и контекстов нитей в рамках одного процесса различаются по ресурсоемкости. Чтобы переключить контекст процесса, нужно полностью поменять по "меньшей мере" контекст нити, плюс весь контекст процесса: отображение памяти процесса и пр. Для переключения же нити требуется "только" переключить контекст нити на другую нить в том же процессе.
39. С какой целью в современных ОС поддержка нитей (потоков управления) реализуется на уровне ядра
В программе, работа которой полностью основана на потоках, работающих на уровне ядра, все действия по управлению потоками выполняются ядром. В области приложений отсутствует код, предназначенный для управления потоками. Вместо него используется интерфейс прикладного программирования (application programming interface — API) средств ядра, управляющих потоками. Примерами такого подхода являются операционные системы OS/2, Linux и W2K.
На рис. 4.6,6" проиллюстрирована стратегия использования потоков на уровне ядра. Любое приложение при этом можно запрограммировать как многопоточное; все потоки приложения поддерживаются в рамках единого процесса. Ядро поддерживает информацию контекста процесса как единого целого, а также контекстов каждого отдельного потока процесса. Планирование выполняется ядром исходя из состояния потоков. С помощью такого подхода удается избавиться от двух упомянутых ранее основных недостатков потоков пользовательского уровня. Во-первых, ядро может одновременно осуществлять планирование работы нескольких потоков одного и того же процесса на нескольких процессорах. Во-вторых, при блокировке одного из потоков процесса ядро может выбрать для выполнения другой поток этого же процесса. Еще одним преимуществом такого подхода является то, что сами процедуры ядра могут быть многопоточными.
Основным недостатком подхода с использованием потоков на уровне ядра по сравнению с использованием потоков на пользовательском уровне является то, что для передачи управления от одного потока другому в рамках одного и того же процесса приходится переключаться в режим ядра. Результаты исследований, проведенных на однопроцессорной машине VAX под управлением UNIX-подобной операционной системы, представленные в табл. 4.1, иллюстрируют различие между этими двумя подходами. Сравнивалось время выполнения таких двух задач, как (1) нулевое ветвление (Null Fork) — время, затраченное на создание, планирование и выполнение процесса/потока, состоящего только из нулевой процедуры (измеряются только накладные расходы, связанные с ветвлением процесса/потока), и (2) ожидание сигнала (Signal-Wait) — время, затраченное на передачу сигнала от одного процесса/потока другому процессу/потоку, находящемуся в состоянии ожидания (накладные расходы на синхронизацию двух процессов/потоков). Чтобы было легче сравнивать полученные значения, заметим, что вызов процедуры на машине VAX, используемой в этом исследовании, длится 7 us, а системное прерывание — 17 us. Мы видим, что различие во времени выполнения потоков на уровне ядра и потоков на пользовательском уровне более чем на порядок превосходит по величине различие во времени выполнения потоков на уровне ядра и процессов.
Таким образом, создается впечатление, что как применение многопоточности на уровне ядра дает выигрыш по сравнению с процессами, так и многопоточность на пользовательском уровне дает выигрыш по сравнению с многопоточностью на пользовательском уровне. Однако на деле возможность этого дополнительного выигрыша зависит от характера приложений. Если для большинства переключений потоков приложения необходим доступ к ядру, то схема с потоками на пользовательском уровне может работать не намного лучше, чем схема с потоками на уровне ядра.
40. Принципы работы и назначение гипервизора. Что дает гипервизор в плане повышения интегральной производительности компьютерных систем.
Гипервизор --- программный или программно-аппаратный комплекс, позволяющий запускать и одновременно использовать несколько (гостевых) операционных систем, изолированных друг от друга, на одном и том же хост-компьютере. При этом гостевые операционные системы могут совместно или раздельно использовать предоставленые аппаратные ресурсы, не обязательно имея доступ ко всем им.
Гипервизоры бывают нескольких типов:
1. Автономный гипервизор работает непосредственно поверх оборудования и имеет собственные драйверы устройств. Такой тип гипервизора является симметричным: все гостевые ОС равны между собой. Фактически, автономный гипервизор представляет собой отдельную ОС или микроядро, которое управляет распределением ресурсов между несколькими операционными системами и работает уровнем ниже, чем сами операционные системы. Пример такого гипервизора --- VMware ESX/ESXi.
1+. Гибридный гипервизор похож на автономный за той разницей, что входит в состав полноценной, выделенной ОС (на уровне ядра), из под которой уже осуществляется управление остальными гостевыми ОС. При этом гипервизор по прежнему отвечает за контроль над ресурсами, но для доступа к ним используются драйверы базовой ОС. Такой подход является "почти" симметричным. К гибридным гипервизорам можно отнеси XEN, KVM, Lguest.
2. Гипервизор на основе базовой ОС является обычным процессом с точки зрения операционной системы. Весь доступ к ресурсам осуществляется посредствам этой базовой ОС. Такая схема имеет ассиметричный вид, базовая система располагается как бы "вне" гипервизора. В качестве примеров можно привести VirtualBox, QEMU (без KVM).
Существует несколько подходов к реализации функций гипервизора. Существенным является наличие или отсутствие аппаратной поддержки режима гипервизора. При отсутствии аппаратной поддержки гипервизор рискует "потерять" управление, которое перейдет к гостевой ОС и может уже не вернуться. В связи с этим либо весь исполняемый код полностью эмулируется в полностью виртуальном окружении (что крайне неэффективно), либо исполняется некоторая модифицированная версия исполняемого кода. При паравиртуализации ядро гостевой ОС модифицируется таким образом, чтобы "сотрудничать" с гипервизором: инструкции, способные навредить работе гипервизора не используются, вместо них используются их аналоги, адресованные гипервизору, а не железу напрямую. Это достаточно эффективный метод (при отсутствии аппаратной поддержки), очевидный недостаток которого --- необходимость модификации гостевой ОС.
Альтернатива паравиртуализации --- динамическая трансляция кода. Это так же достаточно эффективный метод виртуализации в случае, когда нет необходимости в полной эмуляции; при этом транслируются только "проблемные" с точки зрения гипервизора команды. Использование данного подхода позволяет запускать виртуализируемые ОС без модификации.
Так же возможна защита режима гипервизора на аппаратном уровне. Виртуализированные ОС исполняются в специальном, менее привилегированном режиме (в сравнении с гипервизором), так, что гипервизор имеет возможность перехватывать и по-своему обрабатывать некоторые вызываемые инструкции. Данный подход позволяет сочитать высокую эффективность и простоту использования гипервизора в случае наличия аппаратного обеспечения соответствующего уровня (в настоящее время весьма доступного).
Рассмотрим идею применение гипервизора с точки зрения эффективности. Конечно, виртуализированная ОС будет работать менее эффиктивно, нежели ОС, имеющая доступ к ресурсам без каких-либо прослоек. Это падение эффективности может быть не очень существенным (в случае применения эффективных механизмов виртуализации), но имеет место быть. Важно другое. Известно, что в редких случаях ОС использует предоставленные ей ресурсы на 100% в течении всего времени работы в силу специфики решаемых ею задач. Таким образом, железо "простаивает" и эффективность его использования падает. С этой точки зрения виртуализирование множества ОС, решающих различные задачи, способно более равномерно распределить нагрузку на железо, повысив таким образом интегральную эффективность его использования. Менее эффективным в каждой ОС.
41. Проблемы, связанный с производительностью виртуализованной аппаратуры. Паравиртуализация.
Монитор виртуальных машин (гипервизор) должен связать аппаратный интерфейс с виртуальными машинами, сохранив полный контроль над базовой машиной и процедурами взаимодействия с ее аппаратными средствами. Для достижения этой цели существуют разные методы, основанные на
определенных технических компромиссах.
Паравиртуализация — техника виртуализации, при которой гостевые операционные системы подготавливаются для исполнения в виртуализированной среде, для чего их ядро незначительно модифицируется. Чаще всего этот термин связывают с Xen, однако это не единственная система, где применяется эта техника.
Паравиртуализация позволяет достичь очень высокой производительности даже на таких очень тяжёлых для виртуализации платформах, как x86. Особенностью такого подхода является необходимость адаптации ядра операционной системы перед помещением в Xen. Процесс адаптации к Xen очень похож на портирование для новой платформы, однако значительно проще ввиду похожести виртуального оборудования на реальное. Даже с учетом того, что ядро операционной системы явно должно поддерживать Xen, пользовательские приложения и библиотеки остаются без изменения.
1. Архитектура центрального процессора хорошо поддается виртуализации, если она поддерживает прямое выполнение команд гостевой ОС на реальной машине, сохраняя при этом за гипервизором контроль над процессором. При таком выполнении команды (как привилегированные --- ядра ОС, так и непривилегированные --- приложений) должны выполняться в непривилегированном режиме процессора, в то время как гипервизор выполняется в привилегированном режиме. Когда виртуальная машина пытается выполнить привилегированную команду, процессор перехватывает ее и отсылает гипервизору, который эмулирует ее выполнение в зависимости от состояния виртуальной машины.
При отсутствии аппаратной поддержки виртаулизации приходится искать обходные пути, компромисс между эффективностью работы и сложностью применения гипервизора.
При паравиртуализации разработчик гипервизора переопределяет интерфейс виртуальной машины, заменяя непригодное для виртуализации подмножество исходной системы команды более удобными и эффективными эквивалентами. Хотя ОС нужно портировать для выполнения на таких виртуальных машин, большинство обычных приложений могут выполняться в неизменном виде.
Чтобы добиться высокой производительности одновременно с отсутствием необходимости в портировании, компания VMware разработала новый метод виртуализации, который объединяет традиционное прямое выполнение с быстрой трансляцией двоичного кода "на лету". Транслятор двоичного кода VMware устроен достаточно просто, поскольку исходная и целевая системы команд почти идентичны. Преобразованный код очень похож на результаты паравиртуализации. Обычные команды выполняются в неизменном виде, а команды, нуждающиеся в специальной обработке, транслятор заменяет последовательностями команд, которые подобны требующимся для выполнения на паравиртуализованной виртуальной машине.
2. Традиционный метод виртуализации памяти состоит в том, что гипервизор поддерживает "теневую" копию структуры данных для управления памятью виртуальной машины. Эта структура, называемая "теневой таблицей страниц", позволяет гипервизору точно знать, какие страницы физической памяти доступны виртуальной машине. Гипервизор следит за изменениями, которые ОС на виртуальной машине вносит в свою таблицу страниц, и соответствующим образом изменяет строки теневой таблицы страниц, указывающей фактическое местоположение страниц в физической памяти. При выполнении кода виртуальной машины аппаратные средства используют теневую таблицу страниц для трансляции адресов памяти, и гипервизор всегда может контролировать память, которую использует каждая виртуальная машина. Подсистема виртуальной памяти гипервизора постоянно контролирует, сколько памяти выделено виртуальной машине, и должна периодически забирать часть этой памяти, выгружая некоторые страницы на раздел подкачки. При этом нет гарантии, что гипервизор так же успешно сможет решить, какие именно разделы эффективнее отправить в область подкачки, как и гостевая ОС.
Еще одна проблема виртуализации памяти --- размер современных операционных систем и приложений. Выполнение нескольких виртуальных машин может привести к бесполезной растрате значительных объемов памяти для хранения избыточных копий кода и данных, которые являются идентичными для всех виртуальных машин.
Чтобы справиться с этой проблемой, специалисты VMware разработали для своих серверов контентно-зависимую схему совместного использования страниц. Гипервизор отслеживает содержание физических страниц, проверяя их идентичность. Если страницы одинаковы, гипервизор изменяет теневые таблицы страниц виртуальной машины так, чтобы все они указывали на одну и ту же страницу. Затем гипервизор может уничтожить лишние копии страниц, освободив память для других нужд.
3. Богатство и разнообразие устройств в современных компьютерных средах делает виртуализацию ввода/вывода достаточно сложной задачей. Вычислительные среды на базе процессоров x86 поддерживают множество разнообразных устройств ввода/вывода, изготовленных различными производителями и имеющих разные программные интерфейсы. Следовательно, создание подсистемы ввода/вывода для гипервизора, которая будет общаться со всеми этими устройствами, потребует огромных усилий. К тому же некоторые из современных устройств, например графическая подсистема ПК или сетевой интерфейс сервера, предъявляют чрезвычайно высокие требования к производительности. Одно из решений: на уровене виртуализации задействовать для доступа к устройствам ввода/вывода драйверы устройств базовой ОС Windows или Linux. Поскольку большинство устройств ввода/вывода имеют драйверы для этих операционных систем, уровень виртуализации может поддерживать любое такое устройство. Когда гостевая ОС дает команду на чтение или запись блока на виртуальный диск, уровень виртуализации преобразует эту команду в вызов системной процедуры, которая выполняет файловые операции чтения/записи в файловой системе базовой ОС. Аналогичным путем подсистема ввода/вывода гипервизора отображает картинку с видеокарты виртуальной машины в окне базовой ОС, что позволяет последней управлять видеоустройствами виртуальной машины.
При виртуализации устройств ввода/вывода такой подход сильно снижает их производительность. Каждый запрос ввода/вывода должен передать управление базовой операционной системе, пройти через все уровни ПО, чтобы добраться до устройства. Кроме того, современные ОС Windows и Linux не в полной мере поддерживают управление ресурсами для обеспечения изоляции работы и гарантированного обслуживания виртуальных машин, что необходимо в большинстве серверных сред.
Применение паравиртуализированного подхода способно внести вклад в оптимизацию производительности работы гипервизора. При этом гипервизор предоставляет специальные оптимизированные виртуальные устройств ввода/вывода, не соответствующие реальным устройствам. Как и при паравиртуализации процессора, при таком подходе необходимо, чтобы в среде гостевой ОС использовались специальные драйверы устройств. В результате получается более благоприятный для виртуализации интерфейс с устройствами гостевой ОС и повышенная производительность.
42. Аппаратная поддержка режима гипервизора в новейших процессорах фирмы Intel
Технологии виртуализации от Intel объединены под общем названием Intel VT и подразделяются на: VT-х – оптимизация работы процессора, VT-d – оптимизация ввода/вывода (чипсет), VT-c – повышение эффективности сетевых интерфейсов
Процессор
Многоядерность и многопотоковость. Один из основных способов повысить производительность в многозадачной и многопотоковой среде – увеличение количества физических и логических ядер. В этом контексте нужно упомянуть технологию Intel Hyper-Threading (HT), позволяющую аппаратно задействовать два логических ядра дешифрации команд на одно физическое вычислительное
Также неоднозначно применение в виртуализированных средах Intel Turbo Boost (технология для автоматического увеличения тактовой частоты процессора свыше номинальной). Она эффективно работает, когда средняя нагрузка на CPU не слишком высока и некоторые ядра недостаточно загружены.
Уровни привилегий в CPU. Аппаратная виртуализация, реализуемая в современных CPU, дает возможность работать гипервизору вне стандартных уровней привилегий, как бы на уровне «-1», что позволяет ядру гостевой операционной системы без внутренних изменений работать на уровне «0». Для этого введен специальный «гостевой» режим процессора (guest mode), который используется для выполнения кодов гостевой операционной системы. Такой режим работы в процессорах от Intel называется VMX (Virtual Machine eXtensions) и является частью технологии Intel VT-x. В терминах Intel, в режиме VMX-функционирования процессора гипервизор выполняется в привилегированном режиме VMX root, а гостевая операционная система с меньшими привилегиями – в VMX non-root. Оба режима поддерживаются на всех четырех уровнях. Поддержка «гостевого режима» на аппаратном уровне позволила не использовать депривилегизацию ОС, существенно снизив нагрузку на программную часть – гипервизор.
Миграция при смене архитектуры. За миграцию в Intel VT-х отвечает технология FlexMigration. Это позволяет создавать единый пул виртуализации и предназначается для поддержки онлайн-миграции (Live Migration) работающих VM между серверами на процессорах разных поколений.
Обработка прерываний (APIC). Когда процессор выполняет некую задачу, он часто получает запросы, или «прерывания», от других устройств или приложений. Чтобы свести к минимуму влияние прерываний на производительность, специальный регистр в процессоре (APIC Task Priority Register, TPR) отслеживает приоритеты задач. Он обеспечивает, чтобы только прерывания с более высоким приоритетом, чем выполняемые в данный момент, были обработаны немедленно. А раз доступ к аппаратным ресурсам контролирует гипервизор (VMM), то «по умолчанию» каждое такое прерывание должно было бы приводить к передаче управления от гостевой VM к VMM, его обработке и затем возврату управления в VM. Для 32-разрядных систем технология Intel VT-х FlexPriority создает виртуальную копию TPR, которую может читать, а в ряде случаев и изменить гостевую ОС без вмешательства VMM. Таким образом, Intel VT-х FlexPriority оптимизирует эффективность ПО виртуализации за счет обработки прерываний APIC без вмешательства гипервизора, обеспечивая возможность предоставления гостевым VM функции перестроения очереди задач хост-системы (VMM) без ее участия.
Переключение контекста (или задержки перехода). Для быстрого переключения между задачами различных ОС используется целый ряд механизмов. В терминах Intel VT-х часть технологий объединена под названием Virtual Processor ID (VPID.
Трансляция адресов. Задача трансляции адресов виртуальных машин в реальные адреса физических компонентов сервера достаточно ресурсоемка и важна. В терминах Intel VT-х за эту часть отвечает технология Extended Page Tables (EPT).
Технологии безопасности. В арсенале Intel VT-х есть интересная технология Descriptor-Table Exiting. Суть ее в шифровании таблицы трансляции адресов, что дает возможность VMM защитить гостевую VM от внутренних атак, предотвращая перемещение ключевых структур данных системы. Descriptor-Table Exiting препятствует случайным или злонамеренным обращениям из одной виртуальной машины в области памяти, используемые другой VM. Еще одна технология из арсенала Intel VT-х – Trusted Execution Technology (TXT). Это аппаратное решение, ориентированное на подтверждение поведения ключевых компонентов внутри сервера при запуске. Система проверяет последовательность в поведении и время запуска конфигураций VMM с записанной ранее «удачной» последовательностью. С помощью этого теста можно быстро оценить, были ли попытки вмешиваться в среду запуска.
Ввод/вывод
Операции ввода/вывода, связанные с дисковой подсистемой, также не остались без внимания. Intel обеспечивает повышение эффективности в виртуализированной среде за счет Virtualization Technology for Directed I/O (VT-d), Обе они реализуют виртуализацию на уровне портов чипсета и устройств ввода/вывода, предоставляя возможности непосредственного назначения устройств отдельным гостевым VM. Технологии должны поддерживаться и процессором, и чипсетом.
Сетевой интерфейс
В области современных сетевых интерфейсов Ethernet для работы в виртуализированной среде на массовом рынке у устройств Intel фактически конкурентов нет. Наработки в области аппаратной акселерации задач виртуальных сред в контроллере Ethernet объединены под общим названием Intel Virtualization Technology for Connectivity (Intel VT-c). Этот набор технологий поддерживает виртуализацию сетевых устройств ввода/вывода на аппаратном уровне, повышая общую пропускную способность. К функциональности VT-c относится управление сетевым трафиком и маршрутизацией VM непосредственно силами контроллера Ethernet.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
