
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
1. Ограничения (слабые места) современных компьютеров. 3
2. Какие аппаратные решения используются сегодня в высоко - и сверхвысоко производительных аппаратных комплексах. 4
3. Какие перспективные технологии создания высокопроизводительных вычислительных машин могут прийти на смену сегодняшним.. 6
4. Какова специфика организации высокопроизводительных программ.. 8
5. Высокая производительность как аспект программного кода. 9
6. Основные пути увеличения производительности программ.. 10
7. Графы потоков данных (DataFlow) и управления (ControlFlow) 11
8. Организация высокоскоростного обмена данными между компьютерами. 15
9. Статическое и динамическое распараллеливание программ.. 17
10. Анализ алгоритмов на предмет выделения параллельных гранул. 19
11. Высокоуровневое распараллеливание. Т-система и ее аналоги. 20
12. Статическая и динамическая специализация кода. 21
13 Мемоизация (табулирование) результатов вычислений. 22
14. Частичные вычисления и глубокая специализация (суперкомпиляция) программ.. 23
15. В каких областях и для решения каких задач требуются высокопроизводительные вычисления 25
16. Определение процесса, назначение. Логическая и физическая параллельность. Диаграмма состояний процесса. 26
17. Блокировка и реактивация процессов. Процессы и потоки в контексте ОС.. 28
18. Способы обмена данными между процессами. Общая память. Сообщения. 30
19. Синхронизация процессов. 32
20. Взаимное исключение, назначение, требования к реализации. Методы реализации взаимного исключения. Принцип реализации алгоритмов взаимного исключения. 34
21. Проблемы использования флагов для взаимного исключения. Аппаратные методы организации взаимного исключения. 38
22. Проблемы синхронизации. Гонки и взаимная блокировка. 40
23. Методы работы с общей(разделяемой) памятью.. 44
24. Асинхронный ввод/вывод. 47
25. POSIX API для потоков (Pthreads) 49
26. POSIX API для мутексов. 55
27. Что такое параллельное программирование и суперкомпьютеры. Области в которых может возникать потребность в параллельных вычислениях. Особенности параллельных вычислений. 60
28. Увеличение производительности при параллельных вычислениях. К каким областям задач может быть применено распараллеливание к каким нет. Закон Амдала. 61
29. Общая классификация параллельных компьютеров и систем.. 63
30. Кластерные компьютеры и их особенности. 66
31. Параллельные компьютеры с общей памятью (мультипроцессоры) 68
32. Производительность параллельных компьютеров. 71
33. Анализ производительности программного обеспечения путем изучения машинного кода 73
34. Структура ассемблерного кода, полученного компиляцией типичной программы на языке "C". Указатель стека и указатель инструкций. 74
35. Эффективное использование кэш-памяти. Поддержка кэш-памяти на уровне ядра современных ОС (на примере ОС Linux). Инструкция prefetch. 76
36. Принципы повышения производительности подсистемы виртуальной памяти. Поддержка TLB на уровне ядра ОС Linux. 78
37. Многозадачность как один из фундаментальных принципов повышения интегральной производительности сложных программных комплексов. 82
38. Принципы работы планировщика и быстрое переключение контекста процессов и нитей. 83
39. С какой целью в современных ОС поддержка нитей (потоков управления) реализуется на уровне ядра 85
40. Принципы работы и назначение гипервизора. Что дает гипервизор в плане повышения интегральной производительности компьютерных систем. 86
42. Аппаратная поддержка режима гипервизора в новейших процессорах фирмы Intel 88
1. Ограничения (слабые места) современных компьютеров
1. Ограничения тактовой частоты процессора его тепловыделение. В самом первом приближении тактовая частота характеризует производительность подсистемы (процессора, памяти и пр.), то есть количество выполняемых операций в секунду. Мощность потребляемая процессором - P. в определяемая потерями в структурах процессора пропорциональна: P ~ fп Е^2 Частоте переключения fп транзисторов и квадрату питающего напряжения - Е2. Поэтому рост тактовых частот ядра ограничен его тепловыделением
2. Снижение размера транзистора процессора ограничено:
- технологическими сложностями, влияющими на стабильность и повторяемость структур процессоров.
- физическими закономерностями, ограничивающими минимальные размеры КМОП транзистора
- генерируемыми процессорами. Верхняя граничная частота, которых растет со снижением технологических норм. Что в свою очередь приводит к саморазогреву структуры процессора.
3. Память Процессор достаточно быстрый, а вот шина данных и память достаточно далеки от совершенства: время доступа к ней очень большое
http://www. *****/Processor/lin. htm
2. Какие аппаратные решения используются сегодня в высоко - и сверхвысоко производительных аппаратных комплексах
Blade архитектура
Блейд-серверы, лезвия (англ. blade) — компьютерные серверы с компонентами, вынесенными и обобщёнными в корзине для уменьшения занимаемого пространства. Корзина (англ. enclosure) — шасси для блейд-серверов, предоставляющая им доступ к общим компонентам, например, блокам питания и сетевым контроллерам. Блейд-серверы называют также ультракомпактными серверами В блэйд-сервере отсутствуют или вынесены наружу некоторые типичные компоненты, традиционно присутствующие в компьютере. Функции питания, охлаждения, сетевого подключения, подключения жёстких дисков, межсерверных соединений и управления могут быть возложены на внешние агрегаты. Вместе с ними набор серверов образует т. н. блэйд-системуДля вычислений компьютеру требуются как минимум следующие части (машина Тьюринга):память, содержащая исходные данные, процессор, выполняющий команды, память для записи результатов. Остальные компоненты, типичные для компьютера, выполняют вспомогательные для вычислений функции, такие как ввод и вывод, обеспечение питания. Внутри сервера они представляют собой дополнительные потребители энергии, источники тепла, причины сбоев (особенно компоненты с движущимися частями). Концепция блэйд-сервера предусматривает замену их внешними агрегатами (блоки питания) или виртуализацию (порты ввода-вывода, консоли управления), тем самым значительно упрощая и облегчая сам сервер, а также делая его производство (теоретически) дешевле. Блэйд-системы состоят из набора блэйд-серверов и внешних компонентов, обеспечивающих невычислительные функции. Как правило, за пределы серверной материнской платы выносят компоненты, создающие много тепла, занимающие много места, а также повторяющиеся по функциям между серверами. Их ресурсы могут быть распределены между всем набором серверов. Деление на встроенные и внешние функции варьируется у разных производителей.
Infiniband InfiniBand это архитектура коммутации соединений типа "точка-точка". Каждая линия связи представляет собой четырехпроводное двунаправленное соединение с пропускной способностью 2,5 Гбит/с в каждом направлении и гибким выбором физических линий передачи. В архитектуре InfiniBand определен многоуровневый протокол (физический, канальный, сетевой и транспортный уровни) для реализации аппаратными средствами, а также программный уровень для поддержки управляющих функций и скоростного обмена данными (с малыми задержками) между устройствами. Перечислим основные характеристики технологии InfiniBand: возможность масштабирования пропускной способности линий связи до 30 Гбит/с в дуплексном режиме; поддержка различных физических линий: печатных проводников (на объединительной панели), медных или оптоволоконных кабелей; связь на базе коммутации пакетов с сохранением целостности данных и управлением потоком; качество обслуживания; реализованный аппаратно гибкий транспортный механизм; оптимизированный программный интерфейс и удаленный прямой доступ в память (RDMA); инфраструктура управления, поддерживающая функции отказоустойчивости, аварийного переключения и "горячей" замены. В спецификации InfiniBand определен чрезвычайно гибкий и масштабируемый физический уровень, обеспечивающий возможности дальнейшего наращивания пропускной способности и добавления новых типов поддерживаемых физических линий. Его характеристики: двунаправленный обмен
сигналами со скоростями 2,5 Гбит/с (1Х), 10 Гбит/с (4Х) и 30 Гбит/с (12Х)*; малое число требуемых физических проводников: всего 4, 16 или 48 проводников для линий 1Х, 4Х и 12Х; встроенные тактовые импульсы со схемой кодирования 8В/10В без передачи сигналов по вспомогательному каналу; объединение каналов связи на физическом уровне; поддержка различных типов физических проводников: с медной жилой (для экономии) и с оптоволокном (на большие расстояния); несложный физический уровень с малым потреблением энергии. Пропускная способность указана для 10- разрядных данных. При схеме кодирования 8В/10В к 8 разрядам данных добавляются дополнительные два разряда, необходимые для синхронизации. Таким образом, реальная пропускная способность линий InfiniBand составляет 2, 8 и 24 Гбит/с соответственно.
NUMA (Non-Uniform Memory Access — ≪неравномерный доступ к памяти≫ или Non-Uniform Memory Architecture — ≪Архитектура с неравномерной памятью≫) — схема реализации компьютерной памяти, используемая в мультипроцессорных системах, когда время доступа к памяти определяется её расположением по отношению к процессору. истемы NUMA состоят из однородных базовых узлов, содержащих небольшое число процессоров с модулями основной памяти. Практически все архитектуры ЦПУ используют небольшое количество очень быстрой неразделяемой памяти, известной как кеш, который ускоряет обращение к часто требуемым данным. В NUMA поддержка когерентности через разделяемую память даёт существенное преимущество в производительности. Хотя системы с некогерентным доступом к NUMA проще проектировать и создавать, становится предельно сложно создавать программы в классической модели архитектуры фон Неймана. В результате, все продаваемые NUMA-компьютеры используют специальные аппаратные решения для достижения когерентности кеша, и классифицируются как кеш-когерентные системы с распределенной разделяемой памятью, или ccNUMA. Как правило, существует межпроцессорное взаимодействие между контроллерами кеша для сохранения согласованной картины памяти (когерентность памяти), когда более чем один кеш хранит одну и ту же ячейку памяти. Именно поэтому, ccNUMA платформы теряют в производительности, когда несколько процессоров подряд пытаются получить доступ к одному блоку памяти. Операционная система, поддерживающая NUMA, пытается уменьшить частоту доступа такого типа путем перераспределения процессоров и памяти таким способом, чтобы избежать гонок и блокировки.
СUDA (англ. Compute Unified Device Architecture) — разработанная компанией NVIDIA программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, Quadro и NVidia Tesla.
3. Какие перспективные технологии создания высокопроизводительных вычислительных машин могут прийти на смену сегодняшним
Квантовые компьютеры – будущее.
Сверхъестественный мир квантовой механики не подчиняется законам общей классической физики. Квантовый бит (qubit) не существует в типичных 0 или 1-бинарных формах сегодняшних компьютеров – квантовый бит может существовать в одной из них или же в обеих системах одновременно. Это едва ли заметное различие и есть причина, почему квантовые транзисторы дают возможность компьютеру работать в 1 раз быстрее, чем сегодняшние компьютеры! Если вы думаете, что компьютер, работающий при 4 ГГц, быстр, то опробуйте компьютер будущего, работающий при 40000 ГГц. Одновременно с существованием множества препятствий, которые необходимо преодолеть, каждый день открываются новые методики и совершаются новые открытия. Многие люди думают, что квантовые компьютеры могут стать действительностью в течение всего нескольких 5-10 лет.
Прогресс оптических и фотонных компьютеров.
Оптические компьютеры в работе своей используют скорость света, а не скорость электричества, что делает их наилучшими проводниками данных. Электричество передвигается со скоростью, приблизительно равной 1/10 скорости света, но оптические или фотонные транзисторы смогут работать в тысячи раз быстрее, чем компьютеры сегодняшнего поколения. Уже достаточно распространены оптоволоконные кабеля, но скоро оптика будет использоваться всего лишь в качестве компьютерных выключателей. Отдельные фотоны могут быть направлены на создание выключателя (типа ВКЛ/ВЫКЛ), используемого в транзисторах. Но в отличие от электричества световые лучи могут пересекать друг друга (проходить сквозь друг друга), устраняя необходимость использования больших систем традиционной электропроводки. Это позволит оптическому компьютеру быть такого маленького размера, какой необходим для какой-либо определённой задачи.
Nanodot Storage – новый жёсткий диск
Nanodot может быть в 50 миллимикронов шириной и располагать северным и южным полюсами. Он может реагировать на наружные изменения, что делает его главным кандидатом на роль запоминающего устройства. Сегодняшние исследования показали, что объём nanodot дисков может в100 раз превышать вместимость существующих на сегодняшний день жёстких дисков, при этом занимая намного меньше пространства. Nanodot Storage уже совсем близко, и он точно произведёт революцию в сфере сегодняшнего хранения информации.
Spintronics - другое многообещающее, но до сих пор невероятный тип устройства хранения информации.
Настоящая память компьютеров имеет ограничения в том, что производственные процессы приближаются к пределам размеров транзисторов. Помимо этого, оперативная память компьютера (резерв временной памяти) теряет информацию при выключении компьютера. Сейчас же, когда мы можем рассматривать вещи с квантового уровня, появляются новые возможности. Одна сфера, называемая «Spintronics», измеряет вращение электрона. Что привлекает, это то, что даже когда компьютер выключен, информация, содержащаяся во временной памяти, не теряется. Память Spintronic работает всего с несколькими атомами, находящимися на поверхности, созданной газовой средой (арсенид галлия или индия), которая является на сегодняшний день перспективным новым материалом.
Нано трубки и графин вместо силиконовых чипов
Сегодняшние компьютерные чипы располагаются на силиконовой жидкости, но будущий компьютер будет использовать для этих целей нано трубки. Толщина графиновых листов – всего один атом, а нано трубки – это скатанный в трубочку графиновый лист с диаметром всего в один миллимикрон. Их считают будущим производства транзисторов, потому что эти структуры имеют отличные свойства, такие как электропроводность, отличные силовые и тепловые свойства также они могут использоваться для многих других типов материалов.
Баллистические технологии - отклонение электронов как в игре в пинбол
Баллистический транзистор отклонения преломляет близлежащие атомы и представляет собой новый тип компьютерных транзисторов. Этот атомный транзистор может работать на терагерцовых скоростях, примерно в тысячу раз быстрее любого сегодняшнего компьютера, как было заявлено дизайнерской группой Rochester team, занимающейся технологиями. Компьютерные чипы, сделанные при помощи технологии BDT будут просты в производстве и будут следующей волной компьютерных технологий.
http://computer. *****/hardware/565848.htm
4. Какова специфика организации высокопроизводительных программ
В каком-то смысле можно считать высокопроизводительными такие программы, для выполнения которых не хватает ресурсов обычных персональных компьютеров. Чаще всего такими ресурсами являются процессорное время, объем требуемой оперативной или дисковой памяти. Такое нестрогое определение используется потому, что мощность современных персональных компьютеров постоянно растет (закон Мура гласит, что мощность процессоров примерно удваивается каждые полтора года), и поэтому те задачи, которые еще несколько лет назад можно было считать только на мощных мэйнфреймах, сегодня с легкостью пропускаются на ноутбуке. На настоящий момент условной границей между инженерными и высокопроизводительными расчетами являются:
- время счета на двуядерном 3-ГГц процессоре превышает 24 часа; размер оперативной памяти больше 4-8 ГБ; размер дисковой памяти свыше 0,5 ТБ.
Для решения ресурсоемких задач главным критерием является выбор наиболее оптимального метода решения. Если это возможно, используются специализированные пакеты (MatCad, Gaussian, GAMESS), в противном случае приходится писать собственные программы, используя библиотеки программ.
Высокопроизводительные расчеты практически никогда не ведутся в интерактивном и графическом режиме. Наиболее популярная операционная система для этих вычислений - Linux.
Программы для высокопроизводительных расчетов пишутся тщательно, часто коллективами авторов и, иногда, на протяжении нескольких лет. Это объясняется тем, что экономия даже нескольких процентов процессорного времени в условиях многосуточного счета приносит экономическую выгоду. Основными способами повышения эффективности работы программы являются:
- Выбор оптимального алгоритма. Это наиболее эффективный метод, требующий хорошего знания вычислительных методов и специфики работы программы. Использование эффективных компиляторов и библиотек. Использование специфики конкретного процессора и написание критичных кусков программы на языке Ассемблера.
Однако, самым эффективным способом сокращения времени счета является распараллеливание программы.
5. Высокая производительность как аспект программного кода
Высокая производительность должна быть повсюду!
Что надо знать и уметь, чтобы эффективно применять высокопроизводительные вычисления?
В идеале, желательно знать все ниже перечисленные пункты, или хотя бы иметь о них представление.
- Предметную область исследования; математические методы, используемые для получения нужных характеристик; точности, достаточные для получения достоверного результата. Возможности и ограничения используемого пакета. Численные методы и библиотеки подпрограмм, их реализующие. Графически представлять результаты расчетов. Языки программирования (C, C++, Fortran, Java, Pascal). Средства распараллеливания (MPI, PVM, OpenMP). Особенности работы в ОС Windows и Linux, уметь пользоваться командной строкой. Особенности используемых компиляторов.
6. Основные пути увеличения производительности программ
Специализация
Подход к оптимизации программ, основанный на учете дополнительной информации об условиях, в которых будет эксплуатироваться программа, называется специализацией программ. В частности, ограничения на условия эксплуатации могут заключаться в том, что часть исходных данных известна заранее и не меняется от одного запуска программы к другому. Или, в общем случае, ограничения на исходные данные могут быть заданы в виде каких-то условий. В таких случаях принято говорить, что выполняется специализация программы по отношению к ограничениям на исходные данные.
Распараллеливание
Идея распараллеливания заключается в том, что выделяются ветви программы, которые могут выполняться одновременно на различных процессорах, или, даже, машинах, а результаты расчетов использоваться сообща всеми ветвями. Эту процедуру крайне трудно автоматизировать, поэтому наилучший результат дает ручное программирование. Мало того, эффективность процедуры распараллеливания зависит от времени передачи данных между ветвями программы. Ясно, что время передачи данных минимально для многоядерных систем, а в многомашинных комплексах ограничивается пропускной способностью каналов связи. В любом случае это время ограничено скоростью света, поэтому чаще всего многомашинные комплексы делаются в виде кластеров, т. е. компьютеров с одинаковым аппаратным и программным обеспечением, соединенных минимальными по длине линиями связи. Чаще всего кластеры оформляются в виде стойки, обеспечивающей удобный доступ к каждому узлу. Именно такого рода комплексом является кластер ПМ-ПУ (48 восьмиядерных узлов), являющийся самым мощным кластером в северо-западном регионе. Он находится (к настоящему моменту) на 43 месте в списке высокопроизводительных систем СНГ. Кстати, тест Linpack, по которому оценивается производительность кластеров, представляющий собой процедуру обращения матрицы (в нашем случае 130000x130000), выполнялся на 384 ядрах кластера примерно 11 минут.
Еще более широкие возможности для использования предоставляет реализация т. н. метакомпьютера, когда компьютеры, принадлежащие разным организациям, соединенные сетью ИНТЕРНЕТ разрешают использовать свои ресурсы людям, входящим в состав утвержденных виртуальных организаций. Типичным образчиком такого метакомпьютера является GRID - система, разработанная ЦЕРН для обработки экспериментов на Большом Адронном Коллайдере. С помощью метакомпьютера решаются очень большие задачи типа расшифровки генома человека, поиска внеземных цивилизаций или подбор пароля зашифрованного архива.
Низкоуровневая оптимизация Так как процессоры используют весьма сложный набор команд, большинство операций можно выполнить на низком уровне очень многими способами. При этом иногда оказывается, что наиболее очевидный способ — не самый быстрый или короткий. Часто простыми перестановками команд, зная механизм выполнения команд на современных процессорах, реально заставить ту же процедуру выполняться на 50 – 200% быстрее. Разумеется, переходить к этому уровню оптимизации можно только после того, как текст программы окончательно написан и максимально оптимизирован на среднем уровне.
Тонкое использование аппаратур, специфические инструкции процессора, особенности архитектуры, большие объёмы кэшей.
7. Графы потоков данных (DataFlow) и управления (ControlFlow)
Функциональная модель представляет собой набор диаграмм потоков данных (далее - ДПД), которые описывают смысл операций и ограничений. ДПД отражает функциональные зависимости значений, вычисляемых в системе, включая входные значения, выходные значения и внутренние хранилища данных. ДПД - это граф, на котором показано движение значений данных от их источников через преобразующие их процессы к их потребителям в других объектах.
ДПД содержит процессы, которые преобразуют данные, потоки данных, которые переносят данные, активные объекты, которые производят и потребляют данные, и хранилища данных, которые пассивно хранят данные.
Процессы
Процесс преобразует значения данных. Процессы самого нижнего уровня представляют собой функции без побочных эффектов (примерами таких функций являются вычисление суммы двух чисел, вычисление комиссионного сбора за выполнение проводки с помощью банковской карточки и т. п.). Весь граф потока данных тоже представляет собой процесс (высокого уровня). Процесс может иметь побочные эффекты, если он содержит нефункциональные компоненты, такие как хранилища данных или внешние объекты.
На ДПД процесс изображается в виде эллипса, внутри которого помещается имя процесса; каждый процесс имеет фиксированное число входных и выходных данных, изображаемых стрелками (см. рисунок 2.60).
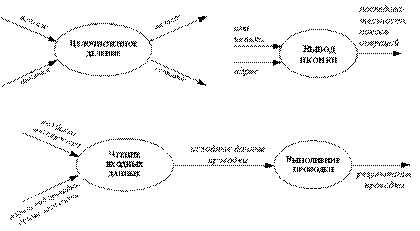
Рис. 2.60. Примеры процессов
Процессы реализуются в виде методов (или их частей) и соответствуют операциям конкретных классов.
Потоки данных
Поток данных соединяет выход объекта (или процесса) со входом другого объекта (или процесса). Он представляет промежуточные данные вычислений. Поток данных изображается в виде стрелки между производителем и потребителем данных, помеченной именами соответствующих данных; примеры стрелок, изображающих потоки данных, представлены на рисунке 2.61. На первом примере изображено копирование данных при передаче одних и тех же значений двум объектам, на втором - расщепление структуры на ее поля при передаче разных полей структуры разным объектам.

Рис. 2.61. Потоки данных
Активные объекты
Активным называется объект, который обеспечивает движение данных, поставляя или потребляя их. Активные объекты обычно бывают присоединены к входам и выходам ДПД. Примеры активных объектов показаны на рисунке 2.62. На ДПД активные объекты обозначаются прямоугольниками.
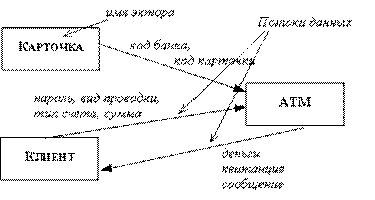
Рис. 2.62. Активные объекты (экторы)
Хранилища данных
Хранилище данных - это пассивный объект в составе ДПД, в котором данные сохраняются для последующего доступа. Хранилище данных допускает доступ к хранимым в нем данным в порядке, отличном от того, в котором они были туда помещены. Агрегатные хранилища данных, как например, списки и таблицы, обеспечивают доступ к данным в порядке их поступления, либо по ключам. Примеры хранилищ данных приведены на рисунке 2.63.
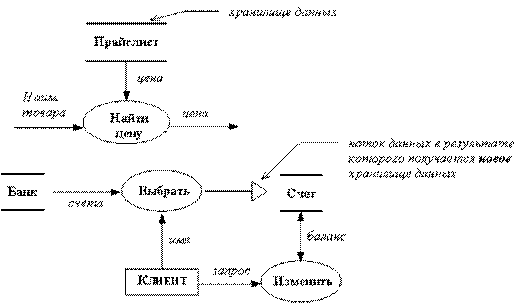
Рис. 2.63. Хранилища данных
Потоки управления
ДПД показывает все пути вычисления значений, но не показывает в каком порядке значения вычисляются. Решения о порядке вычислений связаны с управлением программой, которое отражается в динамической модели. Эти решения, вырабатываемые специальными функциями, или предикатами, определяют, будет ли выполнен тот или иной процесс, но при этом не передают процессу никаких данных, так что их включение в функциональную модель необязательно. Тем не менее иногда бывает полезно включать указанные предикаты в функциональную модель, чтобы в ней были отражены условия выполнения соответствующего процесса. Функция, принимающая решение о запуске процесса, будучи включенной в ДПД, порождает в ДПД поток управления (он изображается пунктирной стрелкой).
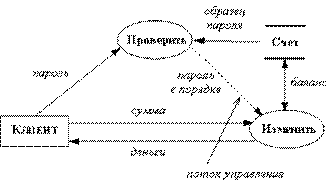
Рис. 2.64. Поток управления
На рисунке 2.64 изображен пример потока управления: клиент, желающий снять часть своих денег со счета в банке, вводит в ATM пароль и требуемую сумму, однако фактическое снятие и выдача денег происходит только в том случае, когда введенный пароль совпадает с его образцом.
Несмотря на то, что потоки управления иногда оказываются весьма полезными, следует иметь в виду, что включение их в ДПД приводит к дублированию информации, входящей в динамическую модель.
Граф потока управления (англ. control flow graph, CFG) — в теории компиляции — множество всех возможных путей исполнения программы, представленное в виде графa.
В графе потока управления каждый узел (вершина) графа соответствует базовому блоку — прямолинейному участку кода, не содержащего в себе ни операций передачи управления, ни точек, на которое управление передается из других частей программы. Имеется лишь 2 исключения: точка, на которую выполняется переход, является первой инструкцией в базовом блоке, и базовый блок завершается инструкцией перехода. Направленные дуги используются в графе для представления инструкций перехода. Также, в большинстве реализаций добавлено два специализированных блока: входной блок, через который управление входит в граф и выходной блок, который завершает все пути в данном графе.
Структура CFG крайне важна для многих оптимизаций компиляторов и для утилит статического анализа кода.
Достижимость — одно из свойств графа, используемое при оптимизациях. Если блок или подграф не имеют путей до них от входного блока, то данная часть графа является недостижимой (мертвый код) при любых вариантах исполнения, и по этой причине он может быть удален из программы. Если же из данного подграфа нет путей до выходного блока, то значит этот подграф содержит бесконечный цикл. Конечно же, не все бесконечные циклы можно обнаружить по такому признаку, см. Проблема останова.
http://*****/programming/oop_rsis/glava2_6_1.shtml
http://ru. wikipedia. org/wiki/%D0%93%D1%80%D0%B0%D1%84_%D0%BF%D0%BE%D1%82%D0%BE%D0%BA%D0%B0_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F
8. Организация высокоскоростного обмена данными между компьютерами
Infiniband InfiniBand это архитектура коммутации соединений типа "точка-точка". Каждая линия связи представляет собой четырехпроводное двунаправленное соединение с пропускной способностью 2,5 Гбит/с в каждом направлении и гибким выбором физических линий передачи. В архитектуре InfiniBand определен многоуровневый протокол (физический, канальный, сетевой и транспортный уровни) для реализации аппаратными средствами, а также программный уровень для поддержки управляющих функций и скоростного обмена данными (с малыми задержками) между устройствами. Перечислим основные характеристики технологии InfiniBand: возможность масштабирования пропускной способности линий связи до 30 Гбит/с в дуплексном режиме; поддержка различных физических линий: печатных проводников (на объединительной панели), медных или оптоволоконных кабелей; связь на базе коммутации пакетов с сохранением целостности данных и управлением потоком; качество обслуживания; реализованный аппаратно гибкий транспортный механизм; оптимизированный программный интерфейс и удаленный прямой доступ в память (RDMA); инфраструктура управления, поддерживающая функции отказоустойчивости, аварийного переключения и "горячей" замены. В спецификации InfiniBand определен чрезвычайно гибкий и масштабируемый физический уровень, обеспечивающий возможности дальнейшего наращивания пропускной способности и добавления новых типов поддерживаемых физических линий. Его характеристики: двунаправленный обмен
сигналами со скоростями 2,5 Гбит/с (1Х), 10 Гбит/с (4Х) и 30 Гбит/с (12Х)*; малое число требуемых физических проводников: всего 4, 16 или 48 проводников для линий 1Х, 4Х и 12Х; встроенные тактовые импульсы со схемой кодирования 8В/10В без передачи сигналов по вспомогательному каналу; объединение каналов связи на физическом уровне; поддержка различных типов физических проводников: с медной жилой (для экономии) и с оптоволокном (на большие расстояния); несложный физический уровень с малым потреблением энергии. Пропускная способность указана для 10- разрядных данных. При схеме кодирования 8В/10В к 8 разрядам данных добавляются дополнительные два разряда, необходимые для синхронизации. Таким образом, реальная пропускная способность линий InfiniBand составляет 2, 8 и 24 Гбит/с соответственно.
Ethernet ([ˈiːθərˌnɛt] от англ. ether [ˈiːθər] «эфир») — пакетная технология передачи данных преимущественно локальных компьютерных сетей.
Стандарты Ethernet определяют проводные соединения и электрические сигналы на изическом уровне, формат кадров и протоколы управления доступом к среде — на канальном уровне модели OSI. Ethernet в основном описывается стандартами IEEE группы 802.3. Ethernet стал самой распространённой технологией ЛВС в середине 90-х годов прошлого века, вытеснив такие устаревшие технологии, как Arcnet, FDDI и Token ring.
В стандарте первых версий (Ethernet v1.0 и Ethernet v2.0) указано, что в качестве передающей среды используется коаксиальный кабель, в дальнейшем появилась возможность использовать витую пару и оптический кабель. При проектировании стандарта Ethernet было предусмотрено, что каждая сетевая карта (равно как и встроенный сетевой интерфейс) должна иметь уникальный шестибайтный номер (MAC-адрес), прошитый в ней при изготовлении. Этот номер используется для идентификации отправителя и получателя кадра, и предполагается, что при появлении в сети нового компьютера (или другого устройства, способного работать в сети) сетевому администратору не придётся настраивать MAC-адрес. Уникальность MAC-адресов достигается тем, что каждый производитель получает в координирующем комитете IEEE Registration Authority диапазон из шестнадцати миллионов (2^24) адресов, и по мере исчерпания выделенных адресов может запросить новый диапазон. Поэтому по трём старшим байтам MAC-адреса можно определить производителя. Существуют таблицы, позволяющие определить производителя по MAC-адресу; в частности, они включены в программы типа arpalert. Некоторое время назад, когда сетевые карты не позволяли изменить свой MAC-адрес, некоторые провайдеры Internet использовали его для идентификации машины в сети при учёте трафика. Но все современные сетевые платы позволяют программно изменить MAC-адрес, однако если плата будет обесточена, то восстановится исходный MAC-адрес.. В зависимости от скорости передачи данных и передающей среды существует несколько вариантов технологии.
Независимо от способа передачи стек сетевого протокола и программы работают одинаково практически во всех нижеперечисленных вариантах. 10 Мбит/с Ethernet, Быстрый Ethernet ( Fas t Etherne t, 100 Мбит/с), 10- гигабитный Ethernet, 40-гигабитный и 100-гигабитный Ethernet Разница между Infiniband и Ethernet в том, что Ethernet протокол с конфликтами не гарантирующий на низком уровне доставку данных, поэтому нужен TCP/IP как переповтор и проверка правильности данных, Infiniband гарантирует правильность пересылки данных.
9. Статическое и динамическое распараллеливание программ
http://www. *****/~t-system/kernel_doc. html
Основной проблемой при создании мультипроцессорной вычислительной техники следует признать проблему распараллеливания программ, что включает в себя:
- организацию процесса вычисления в виде нескольких фрагментов (задач, гранул параллелизма), способных выполняться одновременно;
- распределение задач по различным процессорным элементам (ПЭ) мультипроцессора (внешнее планирование);
- обеспечение передачи данных между параллельными фрагментами и синхронизации параллельных фрагментов.
Существует несколько подходов к решению проблемы распараллеливания программ:
ручное статическое распараллеливание;
автоматическое статическое распараллеливание;
автоматическое динамическое распараллеливание.
Ручное статическое распараллеливание
При ручном статическом распараллеливании программист на некотором языке параллельного программирования в процессе написания программы (в статике) организует:

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
