
Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Идея распараллеливания вычислений базируется на том, что большинство задач может быть разделено на набор меньших задач, которые могут быть решены одновременно. Обычно параллельные вычисления требуют координации действий. Параллельные вычисления существуют в нескольких формах: параллелизм на уровне битов, параллелизм на уровне инструкций, параллелизм данных, параллелизм задач. Параллельные вычисления использовались много лет в основном в высокопроизводительных вычислениях, но в последнее время к ним возрос интерес вследствие существования физических ограничений на рост тактовой частоты процессоров. Параллельные вычисления стали доминирующей парадигмой в архитектуре компьютеров, в основном в форме многоядерных процессоров.
Писать программы для параллельных систем сложнее, чем для последовательных, так как
конкуренция за ресурсы представляет новый класс потенциальных ошибок в программном обеспечении (багов), среди которых состояние гонки является самой распространенной. Взаимодействие и синхронизация между процессами представляют большой барьер для получения высокой производительности параллельных систем. В последние годы также стали рассматривать вопрос о потреблении электроэнергии параллельными компьютерами. Характер увеличения скорости программы в результате распараллеливания объясняется законом Амдала.
Если при вычислении не применяются циклические (повторяющиеся) действия, то N вычислительных модулей никогда не выполнят работу в N раз быстрее, чем один единственный вычислительный модуль. Например, для быстрой сортировки массива на двухпроцессорной машине можно разделить массив пополам и сортировать каждую половину на отдельном процессоре. Сортировка каждой половины может занять разное время, поэтому необходима синхронизация.
В общеупотребительный лексикон термин “суперкомпьютер” вошёл благодаря распространённости компьютерных систем Сеймура Крея, таких как, Control Data 6600, Control Data 7600, Cray-1, Cray-2, Cray-3 и Cray-4. В настоящее время суперкомпьютерами принято называть компьютеры с огромной вычислительной мощностью (“числодробилки”). Такие машины используются для работы с приложениями, требующими наиболее интенсивных вычислений (например, прогнозирование погодно-климатических условий, моделирование ядерных испытаний и т. п.), что в том числе отличает их от серверов и мэйнфреймов — компьютеров с высокой общей производительностью, призванных решать типовые задачи (например, обслуживание больших баз данных или одновременная работа с множеством пользователей).
Иногда суперкомпьютеры используются для работы с одним-единственным приложением,
использующим всю память и все процессоры системы; в других случаях они обеспечивают выполнение большого числа разнообразных приложений.
28. Увеличение производительности при параллельных вычислениях. К каким областям задач может быть применено распараллеливание к каким нет. Закон Амдала
Представляет интерес оценка величины возможного повышения производительности с учетом качественных характеристик самой исходной последовательной программы. Закон Амдала (Gene Amdahl, 1967) связывает потенциальное ускорение вычислений при распараллеливании с долей операций, выполняемых априори последовательно.
Пусть f (0<f<1) – часть операций алгоритма, выполняемая последовательно; тогда распараллеливаемая часть равна (1 - f); при этом затраты времени на передачу сообщений не учитываются, ts - время выполнения алгоритма на одном процессоре (последовательный вариант), n – число процессоров параллельной машины.
При переносе алгоритма на параллельную машину время расчета распределится так:
• f*ts - время выполнения части алгоритма, которую распараллелить невозможно,
• (1− f ) * ts/n - время, затраченное на выполнение распараллеленной части алгоритма.
Время tp, необходимое для расчета на параллельной машине с n процессорами, равно
tp = f × ts + (1− f ) × ts / n,
а ускорение времени расчета S <= ts/tp = ts/( f × ts + (1− f ) × ts / n ) = 1/(f+(1− f ) /n)
Из этого выражения видно, что только при малой доли последовательных операций (f<<1) возможно достичь значительного (естественно, не более чем в n раз) ускорения вычислений. В случае f=0,5 ни при каком (даже бесконечно большом) количестве процессоров невозможно достичь S>2! Заметим, что эти ограничения носят фундаментальный характер (их нельзя обойти для заданного алгоритма), однако практическая оценка доли f последовательных операций априори обычно невозможна.
Таким образом качественные характеристики самого алгоритма накладывают ограничения на возможное ускорение при распараллеливании. Например, характерные для инженерных расчетов алгоритмы счета по последовательным формулам распараллеливаются плохо (часть f значима), в то же время сводимые к задачам линейного программирования (ЛП – операции с матрицами – умножение, обращение, нахождение собственных значений, решение СЛАУ – систем линейных алгебраических
уравнений и т. п.) алгоритмы распараллеливаются удовлетворительно.
Закон Амдала удобен для качественного анализа проблемы распараллеливания, к сожалению, в соотношении Амдала не учитываются потери времени на межпроцессорный обмен сообщениями. Именно поэтому в законе Амдала стоит знак «меньше или равно».
Эти потери могут не только снизить ускорение вычислений впараллельном варианте, но и замедлить вычисления по сравнению с последовательным. Более общим является выражение (сетевой закон Амдала):
S = 1/(f+(1− f ) /n+c)
где c – коэффициент сетевой деградации вычислений,
c=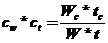
Wс - количество передач данных, W – общее число вычислений в задаче, tс - время одной передачи данных, t – время выполнения одной операции.
Сомножитель сw = W / Wc (повышение коего снижает S) определяет составляющую коэффициента деградации, вызванную свойствами алгоритма распараллеливания,
а сt= t/ tc - зависящую от соотношения производительности процессора и аппаратуры сети (‘техническую’) составляющую; значения сw и сt могут быть оценены заранее.
Удивительно (для столь ограниченной модели!), что в некоторых случаях ускорение времени вычислений на n-процессорной МВС количественно превышает величину числа
процессоров (т. н. 'парадокс параллелизма’)! Объяснения лежат в чисто технической области - например, обработка однопроцессорной системой матриц значительного размера с большой вероятностью приведет к необходимости сброса части элементов матриц на внешнюю (обычно дисковую) память (своппинг, swapping), а длительность этой процедуры на многие порядки превышает время обращения к оперативной памяти (ОП). При разумном программировании для МВС эти матрицы будут распределены между ОП процессоров, причем каждая часть матриц полностью помещается в ОП и своппинга не будет – в этом и объяснение «чудесного» повышения быстродействия.
29. Общая классификация параллельных компьютеров и систем
Основным параметром классификации паралелльных компьютеров является наличие общей (SMP) или распределенной памяти (MPP). Нечто среднее между SMP и MPP представляют собой NUMA-архитектуры, где память физически распределена, но логически общедоступна. Кластерные системы являются более дешевым вариантом MPP. При поддержке команд обработки векторных данных говорят о векторно-конвейерных процессорах, которые, в свою очередь могут объединяться в PVP-системы с использованием общей или распределенной памяти. Все большую популярность приобретают идеи комбинирования различных архитектур в одной системе и построения неоднородных систем.
При организациях распределенных вычислений в глобальных сетях (Интернет) говорят о мета-компьютерах, которые, строго говоря, не представляют из себя параллельных архитектур.
Массивно-параллельные системы (MPP)
Архитектура | Система состоит из однородных вычислительных узлов, включающих: · один или несколько центральных процессоров (обычно RISC), · локальную память (прямой доступ к памяти других узлов невозможен), · коммуникационный процессор или сетевой адаптер · иногда - жесткие диски (как в SP) и/или другие устройства В/В К системе могут быть добавлены специальные узлы ввода-вывода и управляющие узлы. Узлы связаны через некоторую коммуникационную среду (высокоскоростная сеть, коммутатор и т. п.) |
Примеры | IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR8000, транспьютерные системы Parsytec. |
Масштабируемость | Общее число процессоров в реальных системах достигает нескольких тысяч (ASCI Red, Blue Mountain). |
Операционная система | Существуют два основных варианта: 1. Полноценная ОС работает только на управляющей машине (front-end), на каждом узле работает сильно урезанный вариант ОС, обеспечивающие только работу расположенной в нем ветви параллельного приложения. Пример: Cray T3E. 2. На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая отдельно на каждом узле. |
Модель программирования | Программирование в рамках модели передачи сообщений ( MPI, PVM, BSPlib) |
Симметричные мультипроцессорные системы (SMP)
Архитектура | Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из нескольких независимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью. Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера), либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей. |
Примеры | HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.). |
Масштабируемость | Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых систем на базе SMP используются кластерныеили NUMA-архитектуры. |
Операционная система | Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по процессорам (scheduling), но иногда возможна и явная привязка. |
Модель программирования | Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют сравнительно эффективные средства автоматического распараллеливания. |
Системы с неоднородным доступом к памяти (NUMA)
Архитектура | Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т. е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной. В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре cc-NUMA (cache-coherent NUMA) |
Примеры | HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600. |
Масштабируемость | Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000). |
Операционная система | Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT и UNIX в NUMA-Q 2000). |
Модель программирования | Аналогично SMP. |
Параллельные векторные системы (PVP)
Архитектура | Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть объединены с помощью коммутатора (аналогично MPP). |
Примеры | NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY SV1, CRAY X1, серия FujitsuVPP. |
Модель программирования | Эффективное программирование подразумевает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением). |
Кластерные системы
Архитектура | Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого варианта массивно-параллельногокомпьютера. Для связи узлов используется одна из стандартных сетевых технологий (Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора. При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о гетерогенных (неоднородных) кластерах Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку. |
Примеры | NT-кластер в NCSA, Beowulf-кластеры. |
Операционная система | Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые - Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и распределения нагрузки. |
30. Кластерные компьютеры и их особенности
Кластеры являются одним из направлений развития компьютеров с массовым параллелизмом. Кластерные проекты связаны с появлением на рынке недорогих микропроцессоров и коммуникационных решений. В результате появилась реальная возможность создавать установки «суперкомпьютерного» класса из составных частей массового производства.
Кластер — группа компьютеров, объединённых высокоскоростными каналами связи и представляющая с точки зрения пользователя единый аппаратный ресурс. Один из первых
архитекторов кластерной технологии Грегори Пфистер (Gregory F. Pfister) дал кластеру следующее определение: «Кластер — это разновидность параллельной или распределённой системы, которая:
1) состоит из нескольких связанных между собой компьютеров;
2) используется как единый, унифицированный компьютерный ресурс».
Один из первых кластерных проектов – Beowulf-кластеры. Первый кластер был собран в 1994 г. в центре NASA Goddard Space Flight Center (GSFC). Он включал 16 процессоров Intel 486DX4/100 МГц. На каждом узле было установлено по 16 Мбайт оперативной памяти и сетевые карты Ethernet. Чуть позже был собран кластерTheHIVE (Highly-parallrl Integrated Virtual Environment). Этот кластер включал 332 процессора и два выделенных хост-компьютера. Все узлы кластера работали под управлением Red Hat Linux.
Кластеры используются в вычислительных целях, в частности в научных исследованиях. Для вычислительных кластеров существенными показателями являются высокая производительность процессора в операциях над числами с плавающей точкой (flops) и низкая латентность объединяющей сети, и менее существенными — скорость операций ввода-вывода, которая в большей степени важна для баз данных и web-сервисов.
Вычислительные кластеры позволяют уменьшить время расчетов, по сравнению с одиночным компьютером, разбивая задание на параллельно выполняющиеся ветки, которые обмениваются данными по связывающей сети. Одна из типичных конфигураций — набор компьютеров, собранных из общедоступных компонентов, с установленной на них операционной системой Linux, и связанных сетью Ethernet, Myrinet, InfiniBand или другими относительно недорогими сетями. Такую систему принято называть кластером Beowulf. Специально выделяют высокопроизводительные кластеры (Обозначаются англ.
аббревиатурой HPC Cluster — High-performance computing Сluster). Список самых мощных высокопроизводительных компьютеров (также может обозначаться англ. аббревиатурой HPC) можно найти в мировом рейтинге TOP500. В России ведется рейтинг самых мощных компьютеров СНГ. В настоящее время известно огромное количество кластерных решений. Одно из существенных различий состоит в используемой сетевой технологии. При использовании массовых сетевых технологий, обладающих низкой стоимостью, как правило, возникают большие накладные расходы на передачу сообщений. Для характеристики сетей в кластерных системах используют два параметра: латентность и пропускную способность.
Латентность – это время начальной задержки при посылке сообщений. Пропускная способность сети определяется скоростью передачи информации по каналам связи. Если в параллельном алгоритме много коротких сообщений, то критической характеристикой является латентность. Если передача сообщений организована большими порциями, то более важной является пропускная способность каналов связи. Указанные две характеристики могут оказывать огромное влияние на эффективность исполнения кода.
Если в компьютере не поддерживается возможность асинхронной посылки сообщений на фоне вычислений, то возникают неизбежные при этом накладные расходы, связанные с ожиданием полного завершения взаимодействия параллельных процессов. Для повышения эффективности параллельной обработки на кластере необходимо добиваться равномерной загрузки всех процессоров. Если этого нет, то часть процессоров будет простаивать. В случае, когда вычислительная система неоднородна (гетерогенна), балансировка загрузки процессоров становится крайне трудной задачей.
В заключение еще раз зададимся вопросом: «Чем же все-таки кластеры отличаются от других компьютерных систем?» Следуя приведем следующее утверждение «Отличие понятия кластера от сети компьютеров (network of workstations) состоит в том, что для построения локальной компьютерной сети, как правило, используют более простые сети передачи данных, компьютеры сети обычно более рассредоточены, а пользователи могут применять их для выполнения каких-либо дополнительных работ». Впрочем, эта граница все чаще оказывается в значительной степени «размытой», в связи с бурным ростом пропускной способности сетей передачи данных
31. Параллельные компьютеры с общей памятью (мультипроцессоры)
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода-вывода диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры имеют доступ к устройствам ввода-вывода и, следовательно, имеют специальную функцию ввода-вывода. В других мультипроцессорных системах каждый процессор имеет доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода и каждый процессор взаимозаменим с другими процессорами, то такая система называется SMP (Symmetric Multiprocessor — симметричный мультипроцессор).
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу, но обычно практикуется второй вариант. Вычислительные системы с общей памятью, где доступ любого процессора к памяти производится единообразно и занимает одинаковое время, называют системами с однородным доступом к памяти и обозначают аббревиатурой UMA (Uniform Memory Access). Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью.
Технически UMA-системы предполагают наличие узла, соединяющего каждый из n процессоров с каждым изт модулей памяти. Простейший путь построения таких ВС - объединение нескольких процессоров (P) с единой памятью (Mp) посредством общей шины. В этом случае, однако, в каждый момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессор Рi, выбирает из памяти команду, остальные процессоры Pj (i < j) должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать; пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает падать. При наличии на шине десяти процессоров, кривая быстродействия шины становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Если длительность цикла процессора больше по сравнению с циклом памяти, к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.
Можно оптимизировать архитектуру UMA, добавляя локальный кэш и локальную память к каждому из процессоров.
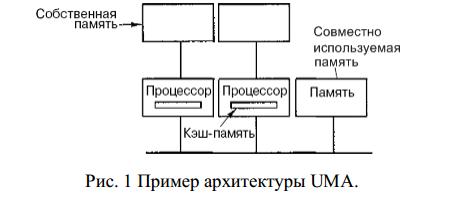
Чтобы оптимально использовать последнюю конфигурацию, компилятор должен поместить в локальные модули памяти весь текст программы, цепочки, константы, другие данные, предназначенные только для чтения, стеки и локальные переменные. Общая разделенная память используется только для общих переменных. В большинстве случаев такое разумное размещение сильно сокращает количество данных, передаваемых по шине, и не требует активного вмешательства со стороны компилятора.
Даже при всех возможных оптимизациях использование только одной шины ограничивает размер мультипроцессора UMA до 16 или 32 процессоров. Организация параллельных вычислений для компьютеров этого класса значительно проще, чем для систем с распределенной памятью. В данном случае не надо думать о распределении массивов. Однако компьютеры этого класса имеют небольшое число процессоров и очень высокую стоимость. Поэтому обычно используются различные решения, позволяющие увеличить число процессоров, но сохранить возможность работы в рамках единого адресного пространства.
В частности общая память может быть физически распределенной, однако все процессоры имеют доступ к памяти любого процессора. Достигается это применением специальных
программно-аппаратных средств. Основная проблема, которую при этом решают – обеспечение когерентности кэш-памяти отдельных процессоров. Реализация мероприятий по обеспечению когерентности кэшей позволяет значительно увеличить число параллельно работающих процессоров по сравнению с SMP-компьютером. Такой подход именуется неоднородным доступом к памяти (non-uniform memory access или NUMA).
Машины NUMA имеют три ключевые характеристики, которыми все они обладают и которые в совокупности отличают их от других мультипроцессоров:
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOAD и STORE.
3. Доступ к удаленной памяти происходит медленнее, чем доступ к локальной памяти. Доступ процессора к собственной Локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть.
В рамках концепции NUMA реализуется несколько различных подходов, обозначаемых аббревиатурами СОМА, СС - NUMA и NC - NUMA.
Особенности COMA
1) Локальная память каждого процессора рассматривается как кэш для доступа «своего» процессора.
2) Кэши всех процессоров рассматриваются как глобальная память системы, а сама глобальная память отсутствует.
3) Данные не привязаны к конкретному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной.
4) Данные переносятся в кэш-память того процессора, который последним их запросил. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью.
Достоинство: Всегда единственная копия данных в быстром локальном кэше.
Недостаток: Если данные требуются нескольким процессорам, то строка кэша с данными должна перемещаться туда и обратно при каждом доступе к данным.
Особенности NC-NUMA (No Caching NUMA — NUMA без кэширования)
1) Отсутствует кэш-память, это значит, что память гарантированно согласованна
2) Каждое слово памяти находится только в одном месте, нет копий.
3) От того, в какой памяти находится слово, зависит производительность.
4) Имеется страничный сканер, который может перемещать страницы памяти между блоками памяти в зависимости от статистики.
Недостаток: Низкая расширяемость.
Особенности CC-NUMA (Cache Coherent Non-Uniform Memory Architecture)
1) Наличие кэша у процессоров.
2) Совместимость кэшей на программном или аппаратном уровне.
Способы обеспечения совместимости кешей:
A. Отслеживание системной шины (низкая масштабируемость, простота технической реализации)
B. Использование каталога (хранение БД кэш-строк в высокоскоростном специализированном аппаратном обеспечении) Использование распределенной общей памяти (distributed shared memory или DSM) упрощает проблемы создания мультипроцессоров (известны примеры систем с несколькими тысячами процессоров). Однако при построении параллельных алгоритмов в данном случае необходимо учитывать, что время доступа к локальной и удаленной памяти может различаться на несколько порядков. Для обеспечения эффективности алгоритма в этом случае следует в явном виде планировать распределение данных и схему обмена данными между процессорами таким образом, чтобы минимизировать обращения к удаленной памяти.
В заключение обратим внимание на существенные различия векторных и массивно-параллельных архитектур. В векторной программе явно выполня-ются операции над всеми элементами регистра, в параллельной программе каждый из процессоров выполняет более или менее синхронно машинные команды, оперируя со своими собственными регистрами. В обоих случаях действия выполняются одновременно, однако каждый из процессоров параллельной ЭВМ может реализовывать свой алгоритм, отличающийся от алгоритмов других процессоров. Указанное отличие является весьма существенным. Справедливо следующее утверждение: алгоритм, который можно векторизовать, можно и распараллелить. Обратное утверждение не всегда верно.
32. Производительность параллельных компьютеров
Параллельный компьютер - это набор процессоров, способных совместно работать при решении вычислительных задач. Такое определение достаточно широко, чтобы включить как параллельные суперкомпьютеры, которые имеют сотни или тысячи процессоров, так и сети рабочих станций.
До настоящего времени эффективность самых быстрых компьютеров возросла почти по экспоненте. Первые компьютеры выполнили несколько десятков операций с плавающей запятой в секунду, а производительность параллельных компьютеров середины девяностых достигает десятков и даже сотен миллиардов операций в секунду, и, скорее всего этот рост будет продолжаться.
Эффективность компьютера зависит непосредственно от времени, требуемого для выполнения базовой операции и числа базовых операции, которые могут быть выполнены одновременно. Время выполнения базовой операции ограничено временем выполнения внутренней элементарной операции процессора (тактом процессора). Уменьшение такта ограничено физическими пределами, такими как скорость света. Чтобы обойти эти ограничения, производители процессоров пытаются реализовать параллельную работу внутри чипа - при выполнении элементарных и базовых операций. Однако теоретически было показано, что стратегия Сверхвысокого Уровня Интеграции (Very Large Scale Integration - VLSI) является дорогостоящей, что время выполнения вычислений сильно зависит от размера микросхемы. Наряду с VLSI для повышения производительности компьютера используются и другие способы: конвейерная обработка (различные стадии отдельных команд выполняется одновременно), многофункциональные модули (отдельные множители, сумматоры, и т. д., управляются одиночным потоком команды).
Виды производительности параллельных компьютеров:
1) пиковая (теоретическая, cсуммарная производительность всех ядер)
Число команд выполняемых компьютером в единицу времени
MIPS (англ. Million Instructions Per Second) — единица измерения быстродействия, равная одному миллиону инструкций в секунду. Если указано быстродействие в MIPS, то, как правило, оно показывает, сколько миллионов инструкций в секунду выполняет процессор в некоторых синтетических тестах.
GIPS — единица измерения быстродействия, равная одному миллиарду инструкций в секунду. Если указано быстродействие в GIPS, то, как правило, оно показывает, сколько миллиардов инструкций в секунду выполняет процессор в некотором синтетическом тесте.
Число вещественных операций выполняемы в единицу времени
FLOPS (также flops, flop/s, флопс или флоп/с) (акроним от англ. Floating point OPerations per Second, произносится как флопс) — внесистемнаяединица, используемая для измерения производительности компьютеров, показывающая, сколько операций с плавающей запятой в секунду выполняет данная вычислительная система
2) реальная (бенчмарки – тесты производительности )
HPC Challenge Benchmark — набор тестов производительности, предназначенный для оценки нескольких атрибутов суперкомпьютеров, которые значительно влияют на производительность реальных высокопроизводительных задач.
На настоящее время пакет состоит из 7 тестов: HPL, STREAM, RandomAccess, PTRANS, FFTE, DGEMM и b_eff Latency/Bandwidth. HPL — это тестLINPACK, направленный на получение наивысшей производительности (TPP, Toward Peak Performance). Тест ограничивается производительностью вычислений с плавающей запятой и межсоединениями между частями суперкомпьютера. STREAM — тест, измеряющий установившуюся пропускную способность памяти при работе с очень большими массивами данных. RandomAccess измеряет наивысший темп обновлений случайных мест в памяти (Случайный доступ), измеряется в единицах GUPS. PTRANS — тест на транспонирование очень больших матриц, измеряет темп пересылок больших массивов между отдельными узлами в составе кластера или NUMA-системы. Latency/Bandwidth замеряет задержки и пропускную способность при различных шаблонах взаимодействия между множеством узлов.[2].

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 |
