

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
Например, рассмотрим компанию, которая регулярно помещает на один из своих товаров в местную газету. Компания ежемесячно ведёт записи о суммах денег, затраченных на рекламу и поступивших от продажи этого товара.
Если реклама эффективна, то можно предположить, что, вероятно, существует какая-то связь между затратами на рекламу и соответствующими ежемесячными объемами продаж. Предположим, что чем больше сумма затрат на рекламу, тем больше объём продаж (по крайней мере, в определённых пределах). Не существует теоретической основы, исходя из которой, мы могли бы написать уравнение, математически устанавливающее связь продаж с расходами на рекламу. Имеется ряд факторов, неразрывно связанных между собой, которые точно определяют ежемесячный объём реализации. Это такие факторы, как цена товара-конкурента, период времени, погодные условия. Тем не менее, если расходы на рекламу являлись бы главным фактором, определяющим продажу, то знание связи между этими двумя переменными было бы очень полезным для оценки объёма продаж и соответствующего планирования финансовой политики компании.
Необходимо знать, например, насколько тесная связь существует между ежемесячными расходами на рекламу и ежемесячным объёмам продаж. Знание этого фактора может обеспечить надёжную оценку продаж. Если связь слабая, то её изучение обеспечивает только описание продаж при весьма низкой надёжности этого описания.
Процедура анализа связи между переменными необходима для установления природы любой связи. Тогда можно разработать математическое уравнение или алгоритм для описания этой связи с математической точки зрения. Модель линейной регрессии используется наиболее часто. Степень пригодности линейной модели к исходным данным является индикатором силы линейной связи между переменными, а, следовательно, и надёжности любых оценок, производимых при помощи этой модели. На этой стадии полезно графическое представление данных.
Различают несколько типов взаимосвязей и одна из них – корреляционная связь – это зависимость среднего значения результативного признака от изменения факторного признака, в то время как каждому отдельному значению факторного признака (X) может соответствовать множество различных значений результативного (Y).
Исследование корреляционных зависимостей включает в себя ряд этапов:
ü Предварительный анализ свойств совокупности;
ü Установление факта наличия связи, определение ее направления и формы;
ü Измерение степени тесноты связи между признаками;
ü Построение регрессионной модели, т. е. нахождение аналитического выражения связи;
ü Прогнозирование по регрессии;
ü Оценка адекватности модели, ее экономическая интерпретация и практическое использование.
Вывод о наличии или отсутствии связи позволяет сделать линейный коэффициент корреляции, вычисленный и оцененный в соответствии со специальным алгоритмом. Близость расчетного коэффициента к –1 свидетельствует о наличии тесной обратной связи между исследуемыми признаками. Коэффициент корреляции, приближающийся по своему значению к +1, говорит о прямой зависимости одного признака от другого, а незначительное отклонение его от нуля означает отсутствие связи. Например, чтобы оценить зависимость объема продукции предприятия Y от стоимости основных фондов X, необходимо, прежде всего, иметь достаточное количество пар наблюденных значений этих признаков за предыдущий период. На основании этих исходных данных и производится расчет коэффициента корреляции
Используя возможности табличного процессора MS EXCEL можно проводить исследование линейной корреляционной зависимости, оценивать её с заданной вероятностью. Рассмотрим один из вариантов решения такой задачи.
Условие задачи
Имеются данные по 10 предприятиям о количестве рабочих с профессиональной подготовкой в процентах и количестве бракованной продукции в процентах.
Количество рабочих в % | 20 | 24 | 28 | 34 | 42 | 52 | 58 | 65 | 68 | 70 |
Выпуск бракованной продукции в % | 28 | 20 | 17 | 14 | 11 | 10 | 11 | 9 | 6 | 6 |
Методом корреляционного анализа исследуйте линейную зависимость между этими признаками, вычислите коэффициент линейной корреляции.
Решим задачу с помощью Microsoft Excel.
Обозначим переменные У - зависимая переменная - количество рабочих с профессиональной подготовкой в процентах;
Х - независимая переменная - количество бракованной продукции в процентах;
· Занесем данные выборочных наблюдений в таблицу MS EXCEL.
· Отсортируем данные по убыванию переменной Х. (рис. 10.7)
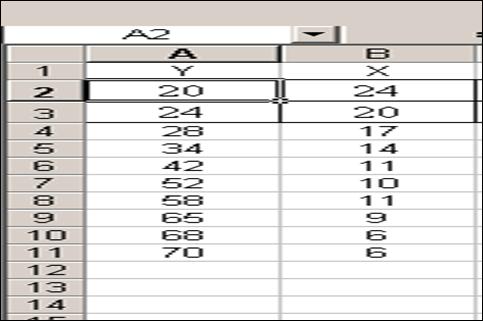
Рисунок 10.7 Исходные данные на листе Microsoft Excel.
Построим поле корреляции, чтобы визуально определить наличие связи между У и Х. Поле корреляции можно построить, используя точечную диаграмму Мастера диаграмм (рис. 1
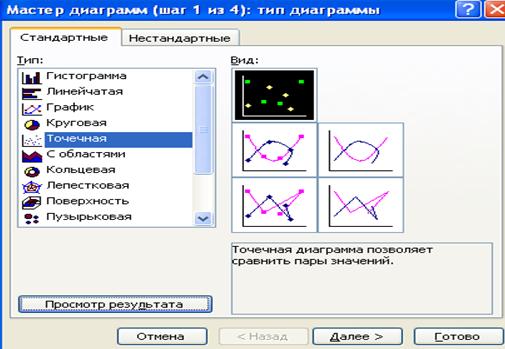
Рисунок 10.8 Точечные диаграммы Мастера диаграмм.
После ввода данных в режиме диалога получим Поле корреляции исходной задачи, на котором видно, что между признаками существует обратная зависимость (рис. ).
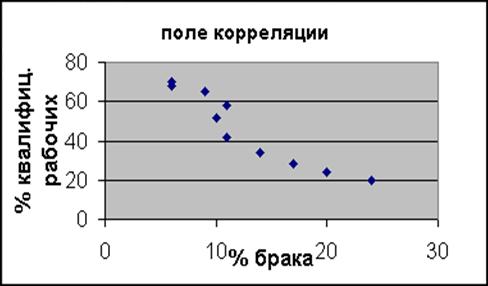
Рисунок 10.9 Поле корреляции.
Рассчитаем коэффициент корреляции по имеющимся данным. Для этого, можно воспользоваться статистической функцией КОРРЕЛ в мастере функций (рис. 10.10).
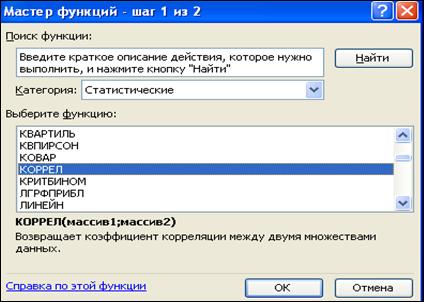
Рисунок 10.10 Мастер функций Microsoft Excel.
Для расчета коэффициента корреляции необходимо указать адреса массивов с данными на листе EXCEL, выделив мышью соответствующие диапазоны ячеек (рис.10.11). Функцию можно набрать в строке формул и вручную.
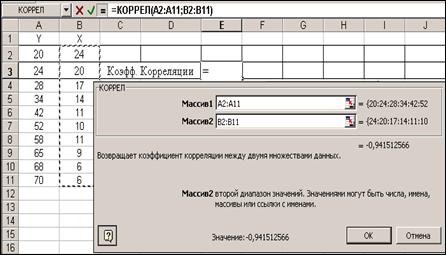
Рисунок 10.11 Расчет коэффициента корреляции в мастере функций.
По данным выборки получен коэффициент корреляции r= -0.. Отрицательное значение коэффициента корреляции и его близость к 1 по абсолютной величине свидетельствуют о наличии обратной связи между У и Х.
Требуется оценить значимость коэффициента корреляции, то есть, определить существует ли, на самом деле, существенная связь между количеством рабочих с профессиональной подготовкой и количеством бракованной продукции.
Ø С целью получения оценки, выдвинем нулевую гипотезу о наличии связи и оценим её значимость.
Ø Альтернативной гипотезой будет гипотеза об отсутствии связи.
Для проверки значимости гипотезы используем t-критерий Стьюдента.
Рассчитаем значение tрасч по формуле:
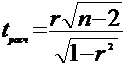
Для этого, можно записать в ячейке таблицы EXCEL формулу, предварительно используя математическую функцию КОРЕНЬ. В результате получим tрасч = -7,.
Сравним расчетное значение tрасч с табличным значением t-критерия Стьюдента для уровня значимости a=1-g, где g=0,95 _ вероятность, с которой оценивается гипотеза. a=0.05.
Определим табличное значение t-критерия Стьюдента для уровня значимости a=0.05 и числа степеней свободы n-2=10-2=8. Для этого используем статистическую функцию СТЬЮДРАСПОБР(0.05;8). Результат t=2, (рис.10.12 ).
|
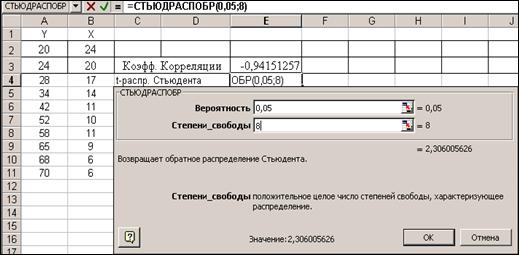
Рисунок 10.12 Определение табличного значения коэффициента Стьюдента.
Учитывая, что tрасч по абсолютной величине больше, чем t- табличное,
ï-7,ï = ï tрасчï > t =2,
можем заключить, что нулевая гипотеза является значимой на уровне значимости 0.05. Итоговая таблица может иметь вид:
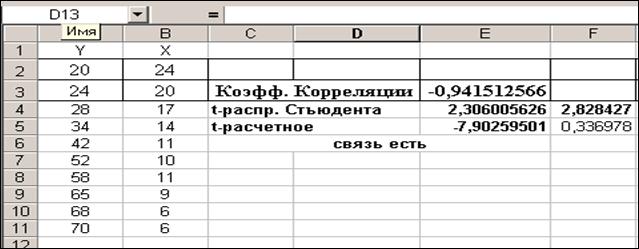
Рисунок 10.13 Расчет и оценка коэффициента корреляции в мастере функций.
В результате проведенных исследований, с вероятностью 0.95, можно сделать вывод о том, что между процентом рабочих с профессиональной подготовкой и процентом бракованной продукции на предприятии существует устойчивая обратная связь.
Если значение коэффициента свидетельствует о наличии связи, можно переходить к построению модели линейной регрессии, устанавливающей функциональную связь между признаками. Для её построения необходимо, на основании имеющейся информации, рассчитать коэффициенты уравнения. Расчет коэффициентов уравнения регрессии может осуществляться различными методами, например, методом наименьших квадратов. Функциональная зависимость позволяет с определенной вероятностью по отдельному значению факторного признака (X) установить значение результативного признака (Y). Получить точечную оценку прогноза можно из уравнения регрессии, однако на практике используются интервальные оценки для неизвестного значения прогнозируемого Y при известном значении фактора X. Доверительный интервал прогноза рассчитывается для заданного уровня значимости. В некоторых статистических или математических программных пакетах (например, в системе STATISTICA) можно построить доверительные интервалы для любого уровня значимости.
Если установить меньшее значение p-уровня, то интервал будет шире, и увеличится уверенность в оценке. И, наоборот; как известно из прогнозов погоды, чем неопределеннее прогноз (т. е. шире доверительный интервал), тем скорее он сбудется. Заметим, что ширина доверительного интервала зависит от размера выборки и дисперсии наблюдений. Вычисление доверительных интервалов основывается на предположении, что переменная в совокупности нормально распределена. Эта оценка может быть неверной, если это предположение не выполнено, и пока размер выборки мал, например, n меньше 100.
Решение задачи можно упростить, если использовать возможности табличного процессора MS Excel. Рассмотрим задачу, которая включает в себя исследование корреляционной и регрессионной зависимости и построение прогноза по регрессии:
На совете директоров рассматривался вопрос о том, что неоправданное повышение цены на продукцию вызвано повышением заработной платы руководящего состава предприятия. С целью выяснения вопроса была произведена выборка по 10-ти предприятиям. В качестве независимого факторного признака x выбрали стоимость единицы однотипной продукции (в долларах). Результирующим фактором y является средняя годовая заработная плата руководства предприятия (в тыс. рублей).
В результате обследования получены следующие данные:
Стоимость единицы однотипной продукции | 30 | 31 | 29 | 14 | 22 | 16 | 25 | 19 | 21 | 23 |
Средняя заработная плата руководства предприятия | 177 | 226 | 203 | 154 | 189 | 154 | 195 | 142 | 161 | 159 |
Необходимо произвести корреляционный и регрессионный анализ полученных данных с целью выявления связи между ценами на продукцию и заработной платой руководства. С вероятностью 0,95 определить прогноз заработной платы руководства фирмы, если стоимость единицы изделия равна 26 рублям.
Решение.
Для облегчения расчетов построим вспомогательную таблицу, формулы для вычисления столбцов которой занесем в ячейки C3:L3. Формулы легко копируются с использованием маркера заполнения. В ячейки C13:L13 поместим формулы автосуммирования и получим таблицу (Таблица 10В остальные ячейки таблицы введем формулы, в соответствии с таблицей 10.1 .
Таблица 10.1.
Номер ячейки | Вычисляемая функция | Формула |
C3 |
| = A3-$A$16 |
D3 |
| = B3-$B$16 |
E3 |
| = C3*C3 |
F3 |
| = D3*D3 |
G3 |
| = C3*D3 |
H3 |
| = $E$19+$E$18*A3 |
I3 |
| = A3*A3 |
H15 |
| = A3*B3 |
H16 |
| = B3-H3 |
H17 |
| = K3*K3 |
F15 |
| = КОРРЕЛ(A3:A12;B3:B12) |
E16 | Табличное значение t-распределения Стьюдента | =СТЬЮДРАСПОБР(0,05;8) |
E18 | Значение коэффициента уравнения регрессии а1 | =(10*J13-A13*B13)/(10*I13-A13*A13) |
E19 | Значение коэффициента уравнения регрессии а1 | =B16-E18*A16 |
H15 | Точечный пргноз y(x0) | =E19+E18*H14 |
H16 | Интервальная оценка ∆ | =E16*КОРЕНЬ(H18*(1+H17)) |
H17 |
| =1/10+(H14-A16)*(H14-A16)/E13 |
J17 | Левая граница интервала доверия | =H15-H16 |
L17 | Правая граница интервала доверия | =H15+H16 |
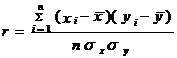
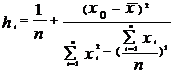
Результаты вычислений можно просмотреть на экране (Таблица 10.2 ), или распечатать.

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 |
