

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
б) суммарное количество характеристик во всех гипотезах,
![]() , (3)
, (3)
где ![]() – количество характеристик гипотезы
– количество характеристик гипотезы ![]() ,
,
в) суммарное количество родителей всех гипотез
![]() , (4)
, (4)
где ![]() – количество родителей гипотезы
– количество родителей гипотезы ![]() ,
,
г) произведение количества характеристик на количество родителей
![]() , (5)
, (5)
д) взвешенное среднее арифметическое числа характеристик, т. е. отношение произведения количества характеристик на количество родителей к общему количеству родителей гипотез одного класса
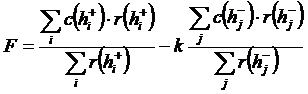 , (6)
, (6)
е) взвешенное среднее арифметическое числа родителей, т. е. отношение произведения количества характеристик на количество родителей к общему количеству характеристик гипотез одного класса
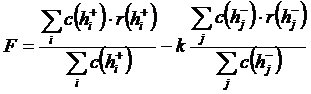 . (7)
. (7)
Значение, возвращаемое данной функцией, определяет категорию обрабатываемого текста.
1.2.3. Алгоритм поиска пересечений
На этапе индукции для того, чтобы установить сходства объектов, осуществляется поиск всех общих фрагментов объектов. Доказано, что для бинарного представления характеристик такая задача является NР-полной [2]. Для поиска всех общих фрагментов мы будем использовать алгоритм Норриса, который имеет линейную сложность от числа общих фрагментов, является инкрементным и одним из самых эффективных среди аналогичных методов [9].
Приведем описание алгоритма Норриса в соответствии с [8]. Пусть у нас имеется набор множеств (объектов). Введем на этом наборе множеств какой-нибудь линейный порядок и зафиксируем его. На ![]() -ном шаге для
-ном шаге для ![]() -ного объекта алгоритм дополняет набор пересечений, построенных для предыдущих
-ного объекта алгоритм дополняет набор пересечений, построенных для предыдущих ![]() множеств, пересечениями каждого множества этого набора с
множеств, пересечениями каждого множества этого набора с ![]() -ным объектом.
-ным объектом.
Обозначим через ![]() номер множества
номер множества ![]() (сами множества и их пересечения будем обозначать маленькими буквами, а подмножество номеров множеств – большими буквами).
(сами множества и их пересечения будем обозначать маленькими буквами, а подмножество номеров множеств – большими буквами).
Пусть ![]() – множество понятий, полученных при обработке первых
– множество понятий, полученных при обработке первых ![]() множеств. Очевидно, что
множеств. Очевидно, что ![]() пусто.
пусто.
Ниже приведен псевдокод алгоритма поиска максимальных пересечений подмножеств.
![]() := пустое множество;
:= пустое множество;
For i := 1 To < количество множеств ![]() > Do Begin
> Do Begin
![]() := <очередное множество
:= <очередное множество ![]() >;
>;
For j := 1 To < размер множества ![]() > Do Begin
> Do Begin
// ![]() – понятие из множества
– понятие из множества
![]() := очередное пересечение из
:= очередное пересечение из ![]() ;
;
![]() := номера множеств
:= номера множеств ![]() , составляющих пересечение
, составляющих пересечение ![]() ;
;
// если ![]() является подмножеством
является подмножеством
If ![]() Then
Then
// добавляем к номерам, входящим в ![]() , номер
, номер
![]()
// иначе, если ![]() не является подмножеством
не является подмножеством
Else Begin
// найдем пересечение множеств ![]() и
и
![]() ;
;
f := false; // флаг совпадения ![]() с одним из множеств в
с одним из множеств в
![]() ; // номер родителя пересечения
; // номер родителя пересечения
k := 1;
While (k <= <размер множества ![]() >) And (not f) Do Begin
>) And (not f) Do Begin
![]() := очередное пересечение из
:= очередное пересечение из ![]() ;
;
![]() := номера множеств
:= номера множеств ![]() , составляющих пересечение
, составляющих пересечение ![]() ;
;
If ![]() Then Begin
Then Begin
![]() ;
;
f := true;
End;
Else Begin
![]() ;
;
Inc(k);
End;
End;
If not f Then
![]() ; // добавляем новое понятие в
; // добавляем новое понятие в
End;
End;
f := false; // флаг, показывающий, является ли ![]() подмножеством
подмножеством
// некоторого множества из
q := 1;
While (q <= ![]() ) And (not f) Do Begin
) And (not f) Do Begin
![]() := очередное множество
:= очередное множество ![]() ;
;
If 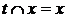 Then
Then
f := true
Else
Inc(q);
End;
If not f Then
![]() ;
;
End;
1.3. N-кратный скользящий контроль
Приведем описание метода перекрестной проверки согласно справочнику [4]. Перекрестная проверка (кросс-валидация) – это статистический метод оценки и сравнения обучающих алгоритмов путем деления данных на два сегмента: один сегмент используется для обучения системы, другой – для ее проверки. Базовой формой перекрестной проверки является N-кратный скользящий контроль (N-fold cross-validation).
При проведении N-кратного скользящего контроля все имеющиеся данные разбивают на N равных (или приблизительно равных) по размеру частей (блоков). Обычно N задают равным 5 или 10. Каждый из N блоков поочерёдно объявляется контрольным (тестовым), остальные N–1 блоков объявляются обучающими (тренировочными). Производится обучение классификатора по обучающим блокам, а затем осуществляется классификация объектов в контрольном блоке. Процедура обучения повторяется N раз, в результате все объекты оказываются классифицированными как контрольные ровно по одному разу, и как обучающие по (N–1) раз.
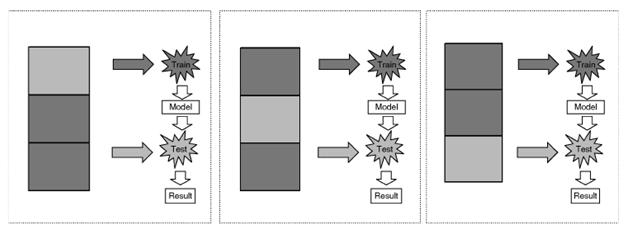
Рис. 2 – Процедура 3-кратной перекрестной проверки
Для оценки качества работы классификатора используют заранее определенную метрику, например, точность (precision). Итоговую оценку точности классификации вычисляют как среднее арифметическое значение точности по всем циклам. Таким образом, процедура перекрестной проверки позволяет максимально полно использовать имеющиеся выборочные данные для оценки качества автоматической классификации.
Обычно перекрестная проверка используется в ситуациях, когда необходимо оценить, насколько предсказывающая модель способна работать на практике. Необходимо отметить, что недостатком процедуры перекрестного контроля являются высокие вычислительные затраты, поскольку в каждом цикле необходимо проводить обучение классификатора.
1.4. Метрики качества
Для оценки эффективности ДСМ-метода будем пользоваться следующими метриками – правильность (accuracy), точность (precision), полнота (recall) и F1-мера (F1-measure).
Эти метрики легко рассчитать на основании таблицы сопряженности, которая составляется для каждого класса отдельно.
Таблица 1 – Таблица сопряженности
Категория | Экспертная оценка | ||
Positive | Negative | ||
Оценка классификатора | Positive | TP | FP |
Negative | FN | TN |
В таблице содержится информация о том, сколько раз система приняла верное и сколько раз неверное решение по объектам заданного класса. Условные обозначения категорий:
TP (true positives) – объекты, которые классификатор отнес к позитивному классу и которые действительно принадлежат позитивному классу;
TN (true negative) – объекты, которые классификатор отнес к негативному классу и которые действительно принадлежат негативному классу;
FP (false positive) – объекты, которые классификатор ошибочно отнес к позитивному классу, хотя на самом деле они относятся к негативному классу;
FN (false negative) – объекты, которые классификатор ошибочно отнес к негативному классу, хотя на самом деле они относятся к позитивному классу.
Описание основных метрик приведем в соответствии с [5].
1.4.1. Правильность и ошибочность
На практике не бывает систем, абсолютно точно определяющих правильные соотношения классов и принадлежащих им объектов. Классификатор будет работать с ошибками относительно тестовой выборки. Для оценки успешности сопоставления классов и объектов используется метрика правильности:
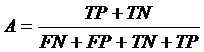 , (8)
, (8)
где в числителе – количество объектов, по которым классификатор принял правильное решение, в знаменателе – размер классифицируемой выборки.
Для оценки процента ошибок используется метрика ошибочности:
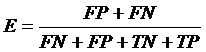 , (9)
, (9)
где в числителе – количество объектов, по которым классификатор принял ошибочное решение. Это метрика используется не так часто в задачах текстовой классификации.
1.4.2. Точность и полнота
Точность P и полнота R являются метриками, которые используются при оценке большей части систем анализа информации. Иногда они используются сами по себе, иногда в качестве базиса для производных метрик, таких как F1-мера.
Точность системы в пределах класса – это доля объектов действительно принадлежащих данному классу относительно всех объектов, которые система отнесла к этому классу. Эта метрику можно представить как степень «разумности» системы. Полнота системы – это доля найденных классификатором объектов, принадлежащих классу, относительно всех объектов этого класса в тестовой выборке. Данную метрику можно представить как степень полноты системы.
Метрика точности определяется формулой
 . (10)
. (10)
Метрика точности характеризует, сколько полученных от классификатора положительных ответов являются правильными. Чем больше точность, тем меньше число ложных попаданий. Но эта метрика не дает представление о том, все ли правильные ответы вернул классификатор. Для этого существует метрика полноты, определяемая формулой
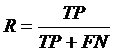 . (11)
. (11)
Метрика полноты характеризует способность классификатора «угадывать» положительные ответы в тестовой выборке. Отметим, что ложно-положительные ответы никак не влияют на эту метрику.
1.4.3. F1-мера
Метрики точности и полноты дают достаточно исчерпывающую характеристику классификатора. Понятно, что чем выше точность и полнота, тем лучше. Если повышать полноту, делая классификатор более «оптимистичным», это приведет к понижению точности из-за увеличения числа ложно-положительных ответов. Если же делать классификатор более «пессимистичным», то при росте точности произойдет одновременное падение полноты из-за отбраковки какого-то числа правильных ответов.
В реальной жизни максимальная точность и полнота не достижимы одновременно, поэтому приходится искать некоторый баланс. С этой целью вводится метрика, которая объединяет в себе информацию о точности и полноте классификатора. Она получила название F1-мера и фактически является средним гармоническим величин P и R:
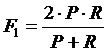 . (12)
. (12)
В данной формуле придается одинаковый вес точности и полноте, поэтому F1-мера будет снижаться одинаково при уменьшении и точности и полноты.
Глава 2. Практическое исследование ДСМ-метода
2.1. Программная реализация
Для написания программы-анализатора был использован язык программирования C#.
2.1.1. Пользовательский интерфейс
Программа реализована в виде консольного приложения. Запуск осуществляется из командной строки Windows. Синтаксис команды запуска исполняемого файла представлен на рис. 3.
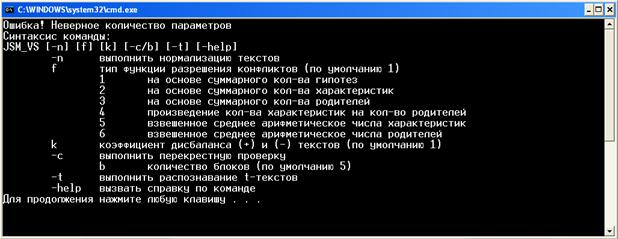
Рис. 3 – Синтаксис команды запуска приложения
По умолчанию коэффициент дисбаланса ![]() , количество блоков для перекрестной проверки
, количество блоков для перекрестной проверки ![]() .
.
2.1.2. Входные данные
Словарь хранится в текстовом файле Dictionary.txt.
Исходные тексты для обучения и классификации располагаются в следующих директориях:
/SourceTexts/MinusSamples – обучающие негативные тексты,
/SourceTexts/PlusSamples – обучающие позитивные тексты,
/SourceTexts/TauSamples – тексты, тональность которых требуется определить.
Тексты после обработки программой Mystem помещаются в директории:
/NormalizedTexts/MinusSamples – нормализованные негативные тексты,
/NormalizedTexts/PlusSamples – нормализованные позитивные тексты,
/NormalizedTexts/TauSamples – нормализованные тексты, тональность которых требуется определить.
2.1.3. Выходные данные
Результаты процедуры кросс-валидации содержатся в текстовом файле ResultsCrossValidation. txt, результаты классификации – в файле ResultsClassification. txt.
2.1.4. Диаграмма классов и структуры данных
Диаграмма классов изображена на рис. 4.


|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
