

Партнерка на США и Канаду по недвижимости, выплаты в крипто
- 30% recurring commission
- Выплаты в USDT
- Вывод каждую неделю
- Комиссия до 5 лет за каждого referral
2.3.2. Оценка времени работы программы
В процессе проведения экспериментов было замерено фактическое время работы программы-анализатора в зависимости от количества обучающих текстов. Оценка временной сложности программы в целом определяется алгоритмом поиска пересечений текстов. Так как задача поиска общих фрагментов текстов является NP-полной, то время работы программы с увеличением числа обучающих текстов растет по экспоненциальной зависимости.
При проведении эксперимента по замеру времени использовался ручной словарь с прилагательными. На рис. 6 изображен график зависимости времени работы программы от количества текстов.
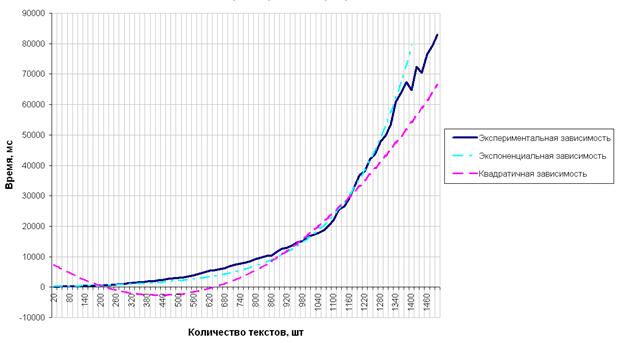
Рис. 6 – Время работы программы-анализатора
При помощи метода наименьших квадратов построено два приближения исследуемой зависимости (рис. 6). Для рассмотренного набора входных данных наиболее точной оказалась экспоненциальная зависимость.
В табл. 9 приведено время работы программы для различных частей речи и словарей, а на рис. 7 и рис. 8 эти данные представлены в виде диаграмм.
Таблица 9 – Время работы программы-анализатора (при использовании функции разрешения конфликтов на основе количества гипотез)
Параметры | Время работы, мин | Параметры | Время работы, мин | ||
Часть речи | Словарь | Часть речи | Словарь | ||
Прил. | Авт. | 0,145 | Прил. + Гл. | Авт. | 1,006 |
Ручной | 0,082 | Ручной | 0,210 | ||
Сущ. | Авт. | 0,705 | Сущ. + Гл. | Авт. | 3,505 |
Ручной | 0,035 | Ручной | 0,104 | ||
Гл. | Авт. | 0,230 | Прил. + Сущ. + Гл. | Авт. | 9,128 |
Ручной | 0,045 | Ручной | 0,396 | ||
Прил. + Сущ. | Авт. | 2,381 | Все части речи | Авт. | 98,880 |
Ручной | 0,159 | Ручной | 0,633 |
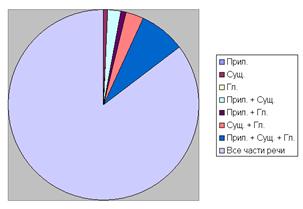
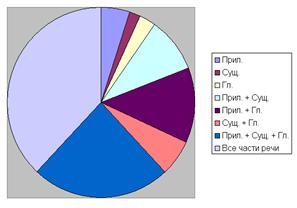
а б
Рис. 7 – Время работы программы-анализатора (в мс):
а – автоматический словарь; б – ручной словарь
На рис. 8 изображена диаграмма времени работы программы с ручным словарем в процентном отношении ко времени работы с автоматическим словарем.
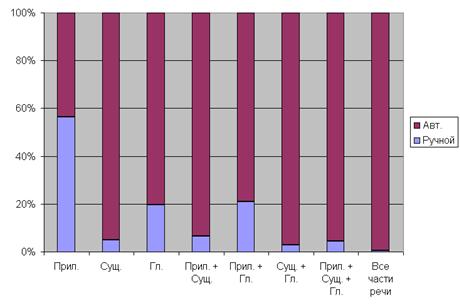
Рис. 8 – Время работы программы с ручным словарем в процентном отношении ко времени работы с автоматическим словарем
Полученные результаты показывают, что при использовании ручного словаря скорость работы программы существенно больше, чем в случае автоматического словаря. При этом качество распознавания тональности выше.
Заключение
В процессе выполнения курсовой работы был изучен ДСМ-метод автоматического порождения гипотез, применяемый для анализа тональности текстов, выполнена программная реализация этого метода и проведен ряд компьютерных экспериментов. Исследование было направлено на выявление влияния компонентов ДСМ-метода на качество распознавания тональности текстов. Изучалось влияние словаря, частей речи и функции разрешения конфликтов. Анализ полученных результатов позволил сделать следующие выводы:
o словарь, составленный вручную, по сравнению с автоматическим словарем дает улучшение значения метрик качества вследствие отсечения множества слов с нейтральной окраской, а также увеличивает скорость работы программы;
o наибольший вклад в качество определения тональности вносят имена прилагательные вследствие частого употребления и содержания ярко выраженной эмоциональной окраски;
o разные функции разрешения конфликтов дают разное качество определения тональности.
Таким образом, ДСМ-метод показал хорошие результаты по определению тональности отзывов о фильмах. На основании экспериментов можно сказать, что одним из путей повышения производительности метода является качественное составление словарей эмоциональной лексики.
Библиографический список
1. Feldman R. Techniques and Applications for Sentiment Analysis // Communications of the ACM. 2013. Vol. 56, №4. P. 82-89.
2. Kuznetsov S. O., Obiedkov S. paring Perfomance of Algorithms for Generating Concept Lattices // Journal of Experimental and Theoretical Artificial Intelligence. 2002. Vol. 14.
3. Liu B. Sentiment Analysis and Opinion Mining. Morgan & Claypool Publishers, 2012.
4. Refaeilzadeh P., Tang L., Liu H. Encyclopedia of Database Systems // Springer, US. 2009.
5. Sebastiani F. Machine learning in Automated Text Categorization // ACM Computing Surveys. 2002. Vol. 34. P. 1-47.
6. Автоматическое порождение гипотез в интеллектуальных системах / под ред. . – М.: Либроком, 2009. – 528 с.
7. ДСМ-метод автоматического порождения гипотез / под ред. . – М.: Либроком, 2009. – 432 с.
8. Кожунова разработки семантического словаря системы информационного мониторинга // Автореферат диссертации на соискание ученой степени кандидата технических наук. – М., 2009. – 21 с.
9. Котельников эмоциональной составляющей в текстах: проблемы и подходы / , , Т. А. Пескишева, ; под. ред. . – Киров: Изд-во ВятГГУ, 2012. – 103 с.
10. , , Пестов выбор параметров классификатора для анализа тональности текстов // Вопросы современной науки и практики. Университет им. . Тамбов: ГОУ ВПО ТГТУ, 2012. С. 67-74.
Приложение
Файл Program. cs
using System;
using System. Collections. Generic;
using System. Linq;
using System. Text;
using System. IO;
using System. Collections;
using System. Diagnostics;
namespace JSM_VS
{
/// <summary>
/// Гипотезы
/// </summary>
public struct Hypothesis
{
/// <summary>
/// Множество признаков
/// </summary>
public HashSet<int> setValues;
/// <summary>
/// Множество родителей
/// </summary>
public HashSet<int> setParents;
/// <summary>
/// Класс гипотезы:
/// '-' - отрицательный,
/// '+' - положительный
/// </summary>
public char type;
}
/// <summary>
/// Описание текстов
/// </summary>
public struct TextInfo
{
/// <summary>
/// Имя файла, содержащего текст
/// </summary>
public string name;
/// <summary>
/// Множество слов из словаря, содержщихся в тексте
/// </summary>
public HashSet<int> setValues;
/// <summary>
/// Класс текста:
/// '-' - отрицательный,
/// '+' - положительный
/// 't' - неопределенной тональности
/// </summary>
public char type;
}
/// <summary>
/// Метрики качества
/// </summary>
public struct EffectMeasure
{
/// <summary>
/// Точность
/// </summary>
public double precission;
/// <summary>
/// Полнота
/// </summary>
public double recall;
/// <summary>
/// F1-мера
/// </summary>
public double f1_measure;
/// <summary>
/// Правильность
/// </summary>
public double accuracy;
//public int countPlusHyp; // Количество положительных гипотез
//public int countMinusHyp; // Количество отрицательных гипотез
}
class Program
{
/// <summary>
/// Загрузка словаря
/// </summary>
/// <param name="words"></param>
static void LoadDictionary(Dictionary<string, int> words)
{
StreamReader sr = new StreamReader("dictionary. txt", Encoding.GetEncoding(1251));
int numWord = 0;
while (!sr. EndOfStream)
{
string str = sr. ReadLine();
numWord++;
words. Add(str, numWord);
}
sr. Close();
}
/// <summary>
/// Сортировка массива примеров в случайном порядке

|
Из за большого объема этот материал размещен на нескольких страницах:
1 2 3 4 5 6 7 8 9 |
